
全球資訊網與 HTTP(進階):多工、隊頭阻塞與 QUIC 的演化之路
從 HTTP/1.1 的序列化瓶頸,到 HTTP/2 多工、TCP 隊頭阻塞,再到 HTTP/3(QUIC)如何把並行搬進傳輸層
為什麼同樣一個網頁,換了 HTTP 版本就快了三倍?
你在入門篇已經跟著一個請求走完「輸入網址 → DNS → 建立連線 → 伺服器回應 → 瀏覽器渲染」的完整旅程。那是一條乾淨的單線道。但真實世界的網頁不是一個請求,而是幾十甚至上百個請求:HTML、CSS、JavaScript、字型、圖片、API 呼叫……它們全部要透過同一條(或數條)連線擠過去。
於是真正的問題浮現了:當這麼多請求要共用有限的連線時,協定本身如何安排它們的先後與並行? 一個設計不良的排隊規則,會讓整個頁面卡在某一張載入緩慢的圖片後面。這正是 HTTP 從 1.1 演進到 2,再到 3(QUIC)背後的核心動機。入門篇談的是「一次請求怎麼走」,這篇要談的是「很多請求如何同時走,而不互相絆倒」——隊頭阻塞(head-of-line blocking)、多工(multiplexing)、TLS 交握與快取語意。
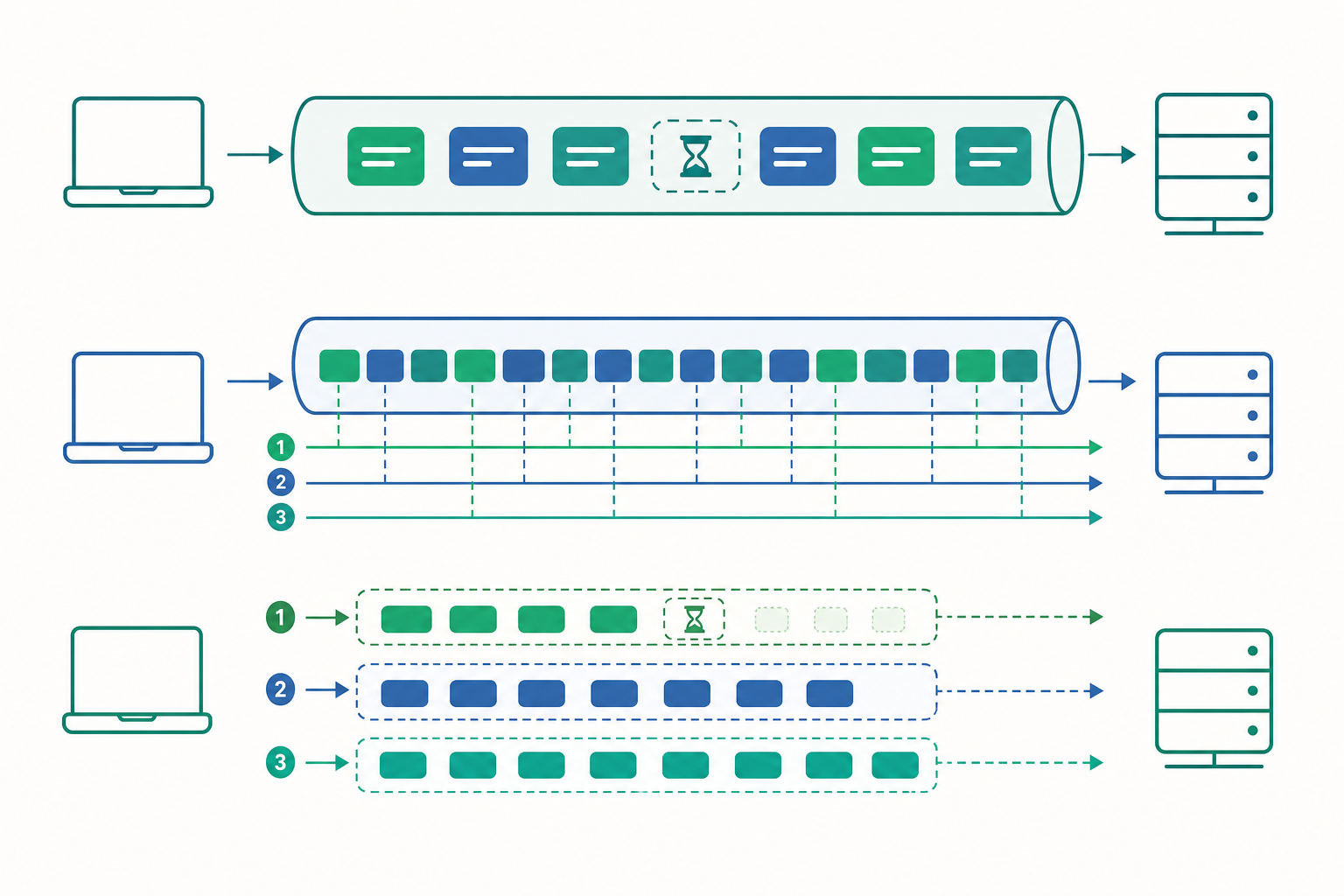
HTTP/1.1 的根本瓶頸:一條連線一次只能跑一件事
HTTP/1.1 的連線模型很直觀:在一條 TCP 連線上,請求與回應嚴格依序。你送出請求 A,必須等 A 的回應完整回來,才能送請求 B。這叫做請求的序列化。
HTTP/1.1 確實提供了一個叫 pipelining(管線化) 的選項,允許你連續送出 A、B、C 不等回應。但致命的是:伺服器必須按照收到的順序回應。如果 A 是一個要查資料庫的慢請求,B、C 早就準備好了,也得乖乖排在 A 後面。這就是隊頭阻塞——隊伍最前面那個人卡住,後面所有人陪葬。因為這個問題,幾乎所有瀏覽器都默默關閉了 pipelining。
瀏覽器的妥協辦法是:開好幾條 TCP 連線(通常對同一個網域開 6 條),讓 6 個請求真正並行。但這治標不治本:
HTTP/1.1 對單一網域的並行模型:
連線1: [請求 main.css ]----[ 回應 ]
連線2: [請求 app.js ]----[ 回應 ]
連線3: [請求 logo.png ]----[ 回應 ]
連線4: [請求 hero.jpg ]------------[ 慢,整條卡住 ]
連線5: [請求 font.woff]----[ 回應 ]
連線6: [請求 api/user ]----[ 回應 ]
第 7 個請求? 必須等上面某條連線空出來
開 6 條連線代價昂貴:每條都要獨立的 TCP 三次交握、獨立的 TLS 交握、各自的壅塞控制(congestion control)視窗要從頭慢慢成長。對一個有 100 個資源的頁面,6 條連線遠遠不夠。當年前端工程師被迫發明各種人為最佳化來繞過這個限制:把多張小圖拼成一張大圖(CSS sprites)、把多個 JS 檔合併成一個(bundling)、用 data URI 把圖片內嵌進 CSS。這些技巧本質上都是在「對抗協定的缺陷」。
HTTP/2:一條連線,多路同時跑
HTTP/2 的核心洞見是:問題不在連線太少,而在一條連線只能跑一件事。 於是它引入了多工(multiplexing)——在單一一條 TCP 連線上,同時並行傳送任意多個請求與回應。
實現的關鍵是把資料切成訊框(frame)。HTTP/2 不再以「整個請求/回應」為傳輸單位,而是把每個請求或回應拆成許多小的二進位訊框,每個訊框標記它屬於哪一個串流(stream)。串流就是一個雙向的訊息通道,每個請求-回應配對佔一個串流,有唯一的串流 ID。
HTTP/2 單一連線上的訊框交錯(interleaving):
時間軸 →
[S1-hdr][S3-hdr][S1-data][S3-data][S1-data][S5-hdr][S3-data]...
↑ ↑ ↑ ↑
串流1 串流3 串流1 的資料 串流5 的資料
接收端依 stream ID 把訊框重新組裝回各自的完整訊息
因為訊框可以交錯(interleave),慢請求 S3 在等資料庫時,S1 和 S5 的訊框可以照樣往前送。HTTP/1.1 的隊頭阻塞——在應用層——就此消失。
HTTP/2 還帶來兩個重要機制:
標頭壓縮(HPACK):HTTP 標頭非常囉嗦,同一個頁面的幾十個請求帶著幾乎一樣的 User-Agent、Cookie、Accept。HPACK 用一張雙方共享的動態表,把重複出現的標頭欄位編碼成一個索引號,大幅減少冗餘位元組。
串流優先級(stream prioritization):客戶端可以告訴伺服器「CSS 比輪播大圖重要」,讓關鍵渲染資源優先傳。
看一個例子:用 curl 看出協定版本
你可以親手觀察一個網站談判出哪個 HTTP 版本:
# -I 只要標頭,--http2 嘗試協商 HTTP/2
curl -I --http2 https://www.cloudflare.com
# 輸出第一行會告訴你實際使用的版本:
# HTTP/2 200
# server: cloudflare
# ...
# 強制走 HTTP/1.1 來對比
curl -I --http1.1 https://www.cloudflare.com
# HTTP/1.1 200 OK
注意一個關鍵事實:HTTP/2 幾乎總是跑在 TLS(HTTPS) 之上。版本協商透過 TLS 交握中的 ALPN(Application-Layer Protocol Negotiation) 擴充完成——客戶端在交握時就附上「我支援 h2、http/1.1」,伺服器回「我們用 h2」。一次交握就同時搞定加密與協定選擇,不需要額外往返。
但 HTTP/2 還有一個沒解決的怪物:TCP 層的隊頭阻塞
HTTP/2 在應用層消滅了隊頭阻塞,卻沒辦法碰到底下的 TCP。這是一個微妙但致命的問題。
TCP 提供的是一條可靠、有序的位元組串流。它向上層保證:交付的位元組順序,和送出的順序一模一樣。為了做到這點,當某個 TCP 封包在網路上遺失,TCP 必須等它重傳並到達,才能把後面已經收到的封包交給應用層——即使後面那些封包屬於完全不同的串流。
HTTP/2 over TCP,封包遺失時:
送出: [S1封包a][S2封包b][S1封包c][S2封包d]
✗ b 遺失
接收: [S1封包a][ ? ][S1封包c][S2封包d]
└─ c、d 都已到達,但 TCP 不交付!
因為它要維持「有序」,必須先等 b 重傳
結果:S2 的遺失,連累了 S1 的 c 一起卡住
也就是說,HTTP/2 把所有串流塞進同一條 TCP 連線後,一個封包遺失就會凍結所有串流。在網路穩定時 HTTP/2 海放 HTTP/1.1,但在高丟包的行動網路下,HTTP/2 有時反而可能比「多條 TCP 連線的 HTTP/1.1」更慘——因為多條連線時,一條卡住至少不連累另外五條。
根源在於:TCP 是在作業系統核心裡的協定,它不知道上面跑的是 HTTP/2,更不知道串流的存在。 要解決這個問題,唯一的辦法是換掉傳輸層。
HTTP/3 與 QUIC:把多工搬進傳輸層
HTTP/3 的做法很激進:拋棄 TCP,改用一個建立在 UDP 之上、全新的傳輸協定 QUIC。
QUIC 把「串流」這個概念直接做進傳輸層。它在 UDP 上自己實作了可靠傳輸、壅塞控制、加密——但關鍵差異是:QUIC 的串流彼此獨立。每個串流有自己的順序保證,一個串流的封包遺失,只阻塞那一個串流,其他串流繼續流動。傳輸層的隊頭阻塞至此被根除。
HTTP/3 over QUIC,封包遺失時:
QUIC 串流1: [a][b][c] ← 全部到達,正常交付
QUIC 串流2: [d][ ✗ ][f] ← 只有串流2 卡住等重傳
其他串流完全不受影響
QUIC 還順手解決了幾個老問題:
0-RTT 與 1-RTT 連線建立:傳統「TCP 三次交握 + TLS 交握」要花 2 到 3 個來回(round trip)才能送出第一個位元組。QUIC 把傳輸交握和 TLS 1.3 加密交握合併,全新連線只要 1 個來回;對曾經連過的伺服器甚至能 0-RTT——第一個封包就帶著加密的請求資料。
連線遷移(connection migration):TCP 連線用「來源 IP + 來源埠 + 目的 IP + 目的埠」這個四元組來識別。你從 Wi-Fi 切到行動網路,IP 一變,TCP 連線就斷了。QUIC 改用一個與 IP 無關的 連線 ID(Connection ID) 來識別連線,所以你邊走邊切換網路,連線可以無縫存活,影片不會卡。
動手算一下:連線建立要幾個來回?
假設你和伺服器之間的單程延遲(one-way latency)是 50 毫秒,所以一個來回(RTT)是 100 毫秒。我們算「從什麼都沒有,到能送出第一個 HTTP 請求並收到第一個位元組」要多久。
HTTP/1.1 over TLS 1.2(全新連線):
TCP 三次交握 : 1 RTT
TLS 1.2 交握 : 2 RTT
送出請求 + 等回應 : 1 RTT
合計 : 4 RTT = 400 ms
HTTP/2 over TLS 1.3(全新連線):
TCP 三次交握 : 1 RTT
TLS 1.3 交握 : 1 RTT
送出請求 + 等回應 : 1 RTT
合計 : 3 RTT = 300 ms
HTTP/3 over QUIC(全新連線,1-RTT):
QUIC 交握(含 TLS 1.3,合併): 1 RTT
送出請求 + 等回應 : 1 RTT
合計 : 2 RTT = 200 ms
HTTP/3 over QUIC(重訪,0-RTT):
第一個封包就帶請求資料 : 0 額外交握
等回應 : 1 RTT
合計 : 1 RTT = 100 ms
從 400 ms 到 100 ms,光是「連線建立」這一段就省下四分之三。對一個需要連向多個網域、發出上百個請求的現代頁面,這個差距會被放大成肉眼可見的速度感。這就是開頭那個「換版本快三倍」現象的數學來源。
別忘了快取:最快的請求是不送出的請求
協定再怎麼快,都比不上根本不發請求。HTTP 的快取語意(cache semantics)是進階效能的另一根支柱,而它常被誤解。
伺服器透過回應標頭告訴瀏覽器「這個資源可以快取多久、怎麼驗證」:
HTTP/2 200
content-type: text/css
cache-control: max-age=31536000, immutable
etag: "a3f9c2e1"
Cache-Control: max-age=31536000表示這份資源在本地可新鮮保存一年(31536000 秒)。在這段期間,瀏覽器直接用本地副本,完全不連伺服器——這是最理想的狀況。immutable進一步承諾「這個 URL 的內容永不改變」,連使用者按重新整理都不必去問伺服器。ETag是內容的指紋。當資源過期,瀏覽器不會盲目重抓,而是送一個條件請求:
GET /style.css HTTP/2
if-none-match: "a3f9c2e1"
如果內容沒變,伺服器回 304 Not Modified——一個沒有 body 的極小回應,省下了重傳整個檔案的頻寬。
這帶出一個現代前端的核心策略:內容雜湊命名(content hashing)。把檔名取成 app.a3f9c2e1.js,內容一旦改變,雜湊就變,URL 就變,瀏覽器自然抓新檔;內容沒變時,URL 不變,永久快取生效。這讓你可以對靜態資源放心地設定 max-age 一年,同時又能即時部署更新——魚與熊掌兼得。
重點回顧
- HTTP/1.1 的痛點是序列化:一條連線一次只跑一個請求,pipelining 又因伺服器須按序回應而帶來應用層隊頭阻塞,逼瀏覽器開 6 條連線硬撐。
- HTTP/2 用訊框與串流實現多工:在單一連線上交錯傳送多個請求的訊框,消滅了應用層隊頭阻塞,並加上 HPACK 標頭壓縮與串流優先級。
- HTTP/2 仍受困於 TCP 層隊頭阻塞:所有串流共用一條 TCP 連線,一個封包遺失就凍結全部串流,因為 TCP 在核心裡不認識串流。
- HTTP/3 改用 QUIC(建在 UDP 上):串流獨立、根除傳輸層隊頭阻塞,並提供 1-RTT/0-RTT 交握與連線遷移。
- 快取是最強的最佳化:
Cache-Control+ETag+ 內容雜湊命名,讓最理想的請求變成「根本不送出」或「只回 304」。
深入探討(研究所視角)
QUIC 的壅塞控制與「公平性」難題。 QUIC 在使用者空間(user space)實作壅塞控制,這給了它極大的演算法彈性——可以快速迭代如 BBR(Bottleneck Bandwidth and RTT)這類以頻寬-延遲乘積建模的演算法,而不必等作業系統核心更新。但這也帶來研究上的張力:當 QUIC 流與傳統 TCP(Cubic)流共享同一條瓶頸鏈路時,兩者對「公平共享」的隱含假設不同,可能導致一方系統性地搶走更多頻寬。網路量測社群至今仍在實證 QUIC 部署對既有 TCP 流量的影響,這是傳輸協定演化中「相容性 vs. 創新」的經典權衡。
為什麼 QUIC 把加密做成「強制且不可分離」? TCP 的標頭在網路上是明文的,導致中間設備(middlebox,如防火牆、NAT、ISP 的最佳化盒子)會去窺探甚至改寫 TCP 行為,造成所謂的協定僵化(protocol ossification)——任何對 TCP 的擴充都可能被舊設備擋下而無法部署。QUIC 的設計哲學是把幾乎所有控制資訊(包含封包號碼)都加密,只留極少數欄位明文,讓 middlebox 無從窺探也無從介入。這是一個刻意的架構決策:用加密來保護協定未來的可演化性,而不只是保護資料隱私。這也解釋了為何 QUIC 沒有「不加密」的版本——加密是協定演化策略的一部分。
HTTP/3 的標頭壓縮為什麼不能直接沿用 HPACK? HPACK 的動態表依賴標頭依嚴格順序處理——但這正好和 QUIC「串流獨立、可亂序到達」的特性衝突:若某串流的標頭更新還沒到,另一個串流就無法解碼。HTTP/3 因此設計了 QPACK,把動態表的「插入指令」和「引用」拆到不同的串流上,並引入阻塞/解除阻塞機制,在「壓縮率」與「避免因依賴而再次卡住」之間取得平衡。這是一個漂亮的案例,說明底層傳輸模型的改變,會一路向上倒逼應用層的每一個機制重新設計——多工不是免費的午餐,它要求整個協定堆疊協同演化。
延伸閱讀方向。 若你想深入,可循三條線索:(1) RFC 9000(QUIC 傳輸)、RFC 9114(HTTP/3)、RFC 9204(QPACK)的原始規格;(2) 壅塞控制理論,從 AIMD、Cubic 到 BBR 的延遲-頻寬建模;(3) TLS 1.3 的 0-RTT 為何會帶來重放攻擊(replay attack) 風險,以及為何 0-RTT 資料只建議用於冪等(idempotent)請求。這三條線索交織起來,就是現代 Web 傳輸效能與安全的完整地圖。