
資安威脅與防護(進階):記憶體、協定與信任邊界
從一段「正常」的 C 程式如何被當成武器出發,深入緩衝區溢位與 ROP、ASLR 與 Stack Canary 的機率防禦、STRIDE 威脅建模,以及 Diffie-Hellman 中間人攻擊——理解「資料被當成程式碼」如何貫穿所有嚴重漏洞,並一窺側通道攻擊與可證明安全的前沿。
當「合法的程式」被當成武器:攻擊者眼中的記憶體與信任
入門篇我們把資安拆成幾道防線:CIA 三要素、防禦縱深、最小權限、零信任。那是一張很好的地圖,但地圖不會告訴你「敵人怎麼翻牆」。這一篇我們換位思考——站在攻擊者的肩膀上,看一個沒有任何病毒檔案、沒有任何明顯惡意程式碼的攻擊如何發生。
考慮一個很具體的問題:一段以 C 語言寫的、開發者自認「正常」的程式,為什麼能讓攻擊者在你的伺服器上執行任意指令?答案不在於某個檔案被植入,而在於攻擊者讓 CPU 誤把資料當成程式碼。資安進階的核心,不是背更多攻擊名稱,而是理解一件事:安全是「信任邊界(trust boundary)」的管理,而每一次資料跨越邊界,都是一次可能被濫用的機會。 入門篇談的注入攻擊(SQL injection、XSS)其實只是這個原則在資料庫與瀏覽器層的特例。現在我們往下挖到記憶體、密碼學協定與形式化威脅建模。
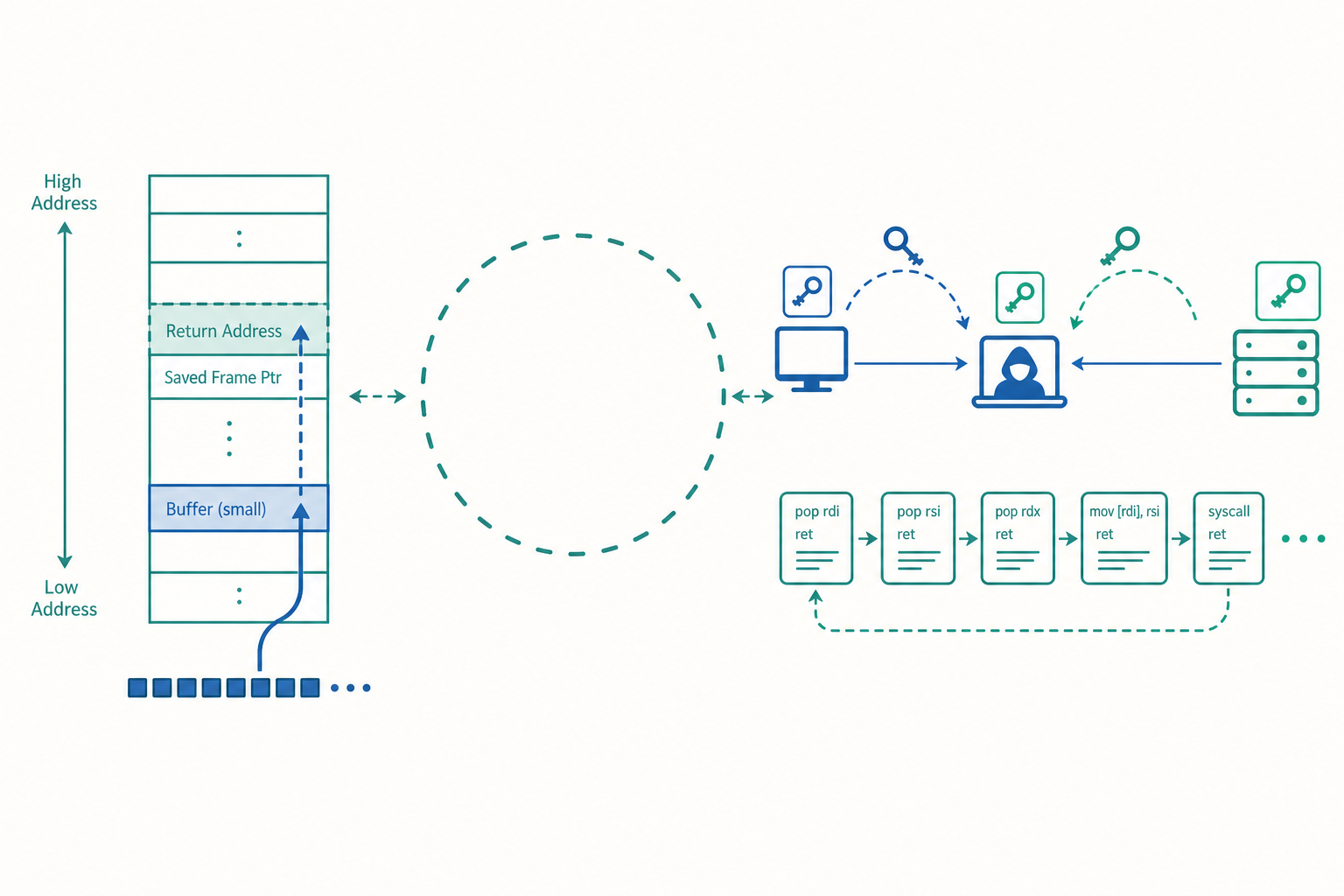
記憶體安全:緩衝區溢位與控制流劫持
最經典的「資料變程式碼」攻擊,是緩衝區溢位(buffer overflow)。它的根源在於 C/C++ 這類語言不檢查陣列邊界。看一段教科書級的脆弱程式:
#include <string.h>
#include <stdio.h>
void greet(char *user_input) {
char name[16]; // 只配置 16 bytes
strcpy(name, user_input); // 不檢查長度,直接複製
printf("Hello, %s\n", name);
}
int main(int argc, char **argv) {
greet(argv[1]); // 攻擊者完全控制 argv[1]
return 0;
}
問題出在 strcpy 把來源字串一路複製到 name,直到遇到結尾的 \0。如果 user_input 超過 16 bytes 會怎樣?要回答這個問題,得先理解呼叫堆疊(call stack)的記憶體佈局。在常見的 x86-64 架構上,當 greet 被呼叫時,堆疊由高位址往低位址成長,大致長這樣:
高位址
┌─────────────────────────┐
│ 返回位址 (return address)│ ← greet 執行完要跳回的地方
├─────────────────────────┤
│ 儲存的 rbp (saved frame) │
├─────────────────────────┤
│ char name[16] │ ← strcpy 從這裡開始往「高位址」寫
└─────────────────────────┘
低位址
關鍵在於:name 在低位址,而返回位址在高位址。strcpy 往高位址方向寫,一旦超過 16 bytes,就會覆蓋掉 saved rbp,再多就覆蓋返回位址。返回位址是 ret 指令要跳去執行的地方。攻擊者只要精心構造輸入,把返回位址改寫成自己想跳去的位址,就劫持了控制流(control flow)。
看一個例子:算出溢位需要多少 bytes
假設我們要覆蓋返回位址。需要的填充長度是:
$$\text{padding} = \underbrace{16}_{name} + \underbrace{8}_{saved\ rbp} = 24 \text{ bytes}$$
也就是說,前 24 bytes 是「墊片」,第 25 個 byte 起才開始覆蓋返回位址(8 bytes)。攻擊者可以用 Python 產生這樣的 payload:
import struct
# 假設我們想把控制流導向某個位址(例如系統內既有的函式)
target_addr = 0x0000000000401136
padding = b"A" * 24 # 填滿 name + saved rbp
new_return = struct.pack("<Q", target_addr) # 小端序 8-byte 位址
payload = padding + new_return
# 把 payload 餵給脆弱程式的 argv[1],即可改寫返回位址
print(payload)
注意 struct.pack("<Q", ...) 的 < 代表小端序(little-endian)——x86-64 把多位元組數值的低位元組存在低位址。這是新手最常踩的坑:位址必須按小端序反向排列。
歷史上更狠的版本是程式碼注入(shellcode injection):早期堆疊是可執行的,攻擊者把機器碼塞進緩衝區,再把返回位址指向那段機器碼。現代系統用 NX(No-eXecute)位元 / W^X(Write XOR Execute) 防止這招——一塊記憶體不能同時可寫又可執行。
於是攻擊者進化出 返回導向程式設計(Return-Oriented Programming, ROP):不注入新程式碼,而是把程式裡既有的小片段(以 ret 結尾的指令序列,稱為 gadget)像積木一樣串接,靠堆疊上一連串返回位址驅動,拼出任意行為。ROP 是「資料當程式碼」最精緻的形式——連一個 byte 的新程式碼都不需要。
為什麼有些語言天生免疫
值得強調的觀念:緩衝區溢位不是 bug,是語言設計選擇的後果。Python、Java、Go、Rust 在執行期(或編譯期)做邊界檢查,越界存取會拋出例外或編譯失敗,根本碰不到返回位址。Rust 更進一步用所有權系統在編譯期消除大多數記憶體錯誤而不付出執行期開銷。微軟與 Google 的統計都指出,他們產品中約 70% 的高危漏洞源於記憶體安全問題——這正是近年「用 Rust 重寫關鍵元件」浪潮的根本原因。
緩解機制是機率遊戲:ASLR 與 Canary
現代系統不只靠 NX。理解這些緩解(mitigation)機制如何把「確定性攻擊」變成「機率性攻擊」很重要。
堆疊金絲雀(Stack Canary):編譯器在返回位址前插入一個隨機值(金絲雀,典故來自礦坑示警的金絲雀)。函式返回前先檢查這個值有沒有被改動;溢位若想覆蓋返回位址,必勢必先踩壞金絲雀,於是被偵測並終止程式。
// 編譯器自動插入的概念(簡化版)
void greet(char *user_input) {
long __canary = __stack_chk_guard; // 進入時放入隨機值
char name[16];
strcpy(name, user_input);
if (__canary != __stack_chk_guard) // 返回前檢查
__stack_chk_fail(); // 被竄改 → 中止
}
位址空間佈局隨機化(ASLR, Address Space Layout Randomization):每次程式載入時,把堆疊、堆積、共享函式庫的基底位址隨機化。攻擊者不再知道 target_addr 該填什麼。
ASLR 的強度取決於熵(entropy)——可隨機的位元數。若位址有 $b$ 個隨機位元,攻擊者盲猜成功機率約 $1/2^b$。32 位元系統往往只有 8~16 bits 熵,可被暴力嘗試(每次猜錯程式崩潰重啟,幾萬次內就中),這是 ASLR 在 32 位元時代被詬病的原因;64 位元系統可達 28~30+ bits,暴力成本陡增。
動手算一下:ASLR 的暴力破解期望次數
假設某 32 位元服務在崩潰後會自動重啟,且 ASLR 提供 16 bits 熵。攻擊者每次嘗試獨立、成功機率 $p = 1/2^{16}$。這是幾何分布,期望嘗試次數為:
$$E[N] = \frac{1}{p} = 2^{16} = 65536 \text{ 次}$$
若每次嘗試(連線、崩潰、重啟)耗時 0.1 秒:
$$T \approx 65536 \times 0.1\,\text{s} \approx 6554\,\text{s} \approx 1.8\,\text{小時}$$
不到兩小時就能破解。對比 64 位元、28 bits 熵:
$$E[N] = 2^{28} \approx 2.68 \times 10^{8}, \quad T \approx 2.68\times10^{7}\,\text{s} \approx 310\,\text{天}$$
同樣的攻擊,在 64 位元上從「一個下午」變成「將近一年」。這就是為什麼緩解機制是疊加的、是機率的:每一層不必百分百攔截,只要把攻擊成本推高到不划算,整體就守住了——這正是入門篇「防禦縱深」原則在數學上的具體展現。
把信任邊界形式化:威脅建模與 STRIDE
進階資安的另一個轉折,是從「列舉攻擊」走向「系統性推導攻擊面」。光憑經驗想攻擊,總會漏。威脅建模(threat modeling)提供結構化方法。最常用的框架是微軟的 STRIDE,它把威脅對應到要被破壞的安全屬性:
| 威脅類別 | 英文 | 破壞的屬性 | 典型例子 |
|---|---|---|---|
| 偽冒 | Spoofing | 認證(Authentication) | 偽造身分登入 |
| 竄改 | Tampering | 完整性(Integrity) | 改寫傳輸中的資料 |
| 否認 | Repudiation | 不可否認性 | 事後否認做過某操作 |
| 資訊洩漏 | Information Disclosure | 機密性(Confidentiality) | 讀到不該讀的資料 |
| 阻斷服務 | Denial of Service | 可用性(Availability) | 癱瘓服務 |
| 權限提升 | Elevation of Privilege | 授權(Authorization) | 一般使用者變管理員 |
實務做法是先畫資料流圖(Data Flow Diagram),標出每條資料流跨越的信任邊界,再對每個元件逐一套 STRIDE 六問。以本平台一個檔案上傳端點為例:
# 攻擊者控制 -> 信任邊界 -> 後端處理
# STRIDE 逐項檢視:
#
# Tampering (完整性):使用者把 mal.php 改名 mal.png 上傳 —— 只看副檔名會中招
# 防線:magic bytes + Pillow 二次驗證內容(utils/file_validation.py)
#
# Information Disclosure (機密性):把檔案存進公開的 static/ 目錄 —— 任何人猜到 URL 即可下載
# 防線:上傳檔案不放 static/,改走有權限檢查的 route
#
# Elevation of Privilege (授權):上傳後若伺服器執行該檔
# 防線:W^X 思維——上傳目錄絕不可執行
from utils.file_validation import verify_file_content
is_valid, err = verify_file_content(uploaded_file, ext) # 雙層內容驗證
if not is_valid:
return jsonify({"success": False, "error": err}), 400
威脅建模的價值,在於它把「安全」從靈感變成可重複的工程流程:每條跨越信任邊界的資料流,都被強迫回答六個問題。這和入門篇的零信任精神一脈相承——零信任就是「假設每條邊界都會被攻擊」的營運化身。
密碼學協定的真正難點:不是演算法,是中間人
入門篇與「加密與雜湊」一文談過對稱/非對稱加密。但實務上 TLS 被攻破,幾乎從不是 AES 或 RSA 演算法被破解,而是金鑰交換時的身分認證出問題。
設想 Alice 想和銀行建立加密連線。她們用 Diffie-Hellman 交換金鑰:
# Diffie-Hellman 金鑰交換(教學用小數字,實務用 2048+ bits)
p = 23 # 公開的大質數
g = 5 # 公開的生成元
a = 6 # Alice 的私鑰(保密)
A = pow(g, a, p) # Alice 送出 A = g^a mod p = 8
b = 15 # 銀行的私鑰(保密)
B = pow(g, b, p) # 銀行送出 B = g^b mod p = 19
# 雙方各自算出共享金鑰
s_alice = pow(B, a, p) # B^a mod p = 19^6 mod 23 = 2
s_bank = pow(A, b, p) # A^b mod p = 8^15 mod 23 = 2
assert s_alice == s_bank # 共享祕密 = 2,竊聽者只看到 8 和 19,算不出來
DH 的安全性建立在離散對數問題(discrete logarithm problem)的困難上:知道 $g$、$p$、$A = g^a \bmod p$,要反推 $a$ 在計算上不可行。看起來很安全——但 DH 本身完全不驗證對方是誰。
於是有了中間人攻擊(Man-in-the-Middle, MitM):攻擊者 Mallory 卡在中間,分別與 Alice、銀行各做一次 DH。Alice 以為在和銀行加密通訊,其實 Mallory 能解密、讀取、再加密轉發每一則訊息。加密強度再高都沒用,因為金鑰是和錯誤的對象協商的。
Alice <--DH--> Mallory <--DH--> Bank
(金鑰 s1) (金鑰 s2)
Mallory 用 s1 解 Alice、用 s2 加密給 Bank,雙向透明竊聽
破解之道不是更強的數學,而是身分綁定:銀行用憑證授權單位(CA)簽發的數位憑證證明「持有這把公鑰的確實是 bank.com」,瀏覽器驗證憑證鏈。這也說明了為什麼「網址列有鎖頭」只代表連線被加密,不保證對方是好人——若使用者點進釣魚網站 bank-secure.com 並接受了它合法申請的憑證,加密反而保護了攻擊者的竊取行為。這是入門篇社交工程與本篇協定安全的交會點:密碼學能保證「和誰說話的內容沒被偷看」,卻無法替你判斷「該不該和這個人說話」。
重點回顧
- 「資料被當成程式碼執行」是多數嚴重漏洞的共同骨架:緩衝區溢位、ROP、SQL injection、XSS 全是同一原則在不同層的展現,核心都是信任邊界失守。
- 記憶體安全是語言設計的後果:C/C++ 不檢查邊界才有溢位;Rust/Java/Python 在編譯或執行期檢查,從根本免疫,這也是約 70% 高危漏洞集中於記憶體問題、業界轉向 Rust 的原因。
- 緩解機制是疊加的機率遊戲:NX、Stack Canary、ASLR 各自不必百分百攔截,靠把攻擊成本(暴力期望次數 $E[N]=1/p$)推高到不划算來守住整體。
- 威脅建模(STRIDE)把安全從靈感變工程:對每條跨越信任邊界的資料流系統性套用六類威脅,是零信任的可操作版本。
- TLS 被破常源於身分認證而非演算法:DH 不驗身分 → 中間人攻擊;加密只保證「內容不外洩」,憑證才回答「對方是誰」。
深入探討(研究所視角)
側通道攻擊與微架構安全。 前述攻擊都假設攻擊者透過正規輸入介面。但近年最深刻的威脅來自側通道(side channel):即使演算法在數學上無懈可擊,其物理或微架構行為仍會洩漏祕密。經典如時序攻擊(timing attack)——若字串比對在第一個不符字元就提前返回,回應時間就洩漏了「猜對幾個字元」,能在線性次數內還原密碼。因此密碼學實作必須採常數時間(constant-time)比對,與秘密值無關地走完所有分支。2018 年的 Spectre 與 Meltdown 更把戰場推進到 CPU 的推測執行(speculative execution):處理器為效能「先猜先做」,即使猜錯會回滾架構狀態,卻在快取留下可被測量的痕跡,使攻擊者跨越行程甚至特權邊界讀取記憶體。這從根本上動搖了「程序隔離」這個作業系統的核心假設,也說明資安已下沉到微架構與形式驗證層次。
從「打補丁」到「可證明安全」。 研究所層級的資安正從經驗性防禦走向形式化方法(formal methods)。一個方向是可證明安全(provable security):把密碼協定的安全性歸約(reduction)到某個公認困難的數學問題——「若能攻破此協定,就能解離散對數」,於是協定安全性有了數學保證而非僅憑沒人攻破。另一個方向是形式驗證的系統軟體:如 seL4 微核心用機器檢查的證明,確立其實作符合規格、不存在整類漏洞;又如 HACL* 提供經形式驗證的密碼學原語,已被 Firefox、Linux 採用。延伸閱讀可循三條線索:(1) 控制流完整性(Control-Flow Integrity, CFI)如何在編譯期約束間接跳轉以封死 ROP;(2) 能力型安全(capability-based security,如 CHERI 硬體)如何用硬體強制最小權限;(3) 機密運算(confidential computing,如 Intel SGX、AMD SEV)如何用硬體飛地(enclave)在不信任作業系統的前提下保護運算——而這些飛地本身又如何反覆被新的側通道攻破。資安的終局或許不是「絕對安全」,而是把信任邊界一次次推到更小、更可被數學刻畫的核心。