
C++ 函數進階:多載決議、SFINAE 與靜態 vs 動態分派
當你寫下一次函數呼叫,編譯器到底如何在編譯期、連結期與執行期決定它的真正含意
當「呼叫一個函數」不再只是跳一個位址
你已經會宣告函數、做多載(overloading)、把宣告放進 .h、把定義放進 .cpp。但請先想一個看似簡單的問題:當你寫下 max(a, b) 時,編譯器到底「選」了哪一個函數?如果 a 是 int、b 是 double,會發生什麼?如果你同時有一個 template 版本和一個普通版本,誰勝出?再進一步:為什麼有些函數呼叫在執行期幾乎沒有成本,有些卻必須查一張表才知道要跳到哪裡?
入門篇告訴你「函數是什麼、怎麼分離編譯」。這一篇要回答的是更深一層的問題:編譯器如何決定一次呼叫的真正含意,以及這個決定發生在哪個階段——編譯期、連結期,還是執行期。理解這套機制,你才能解釋為什麼某些程式碼能跑、某些卻給出令人費解的錯誤訊息,也才能在效能與抽象之間做出有依據的取捨。
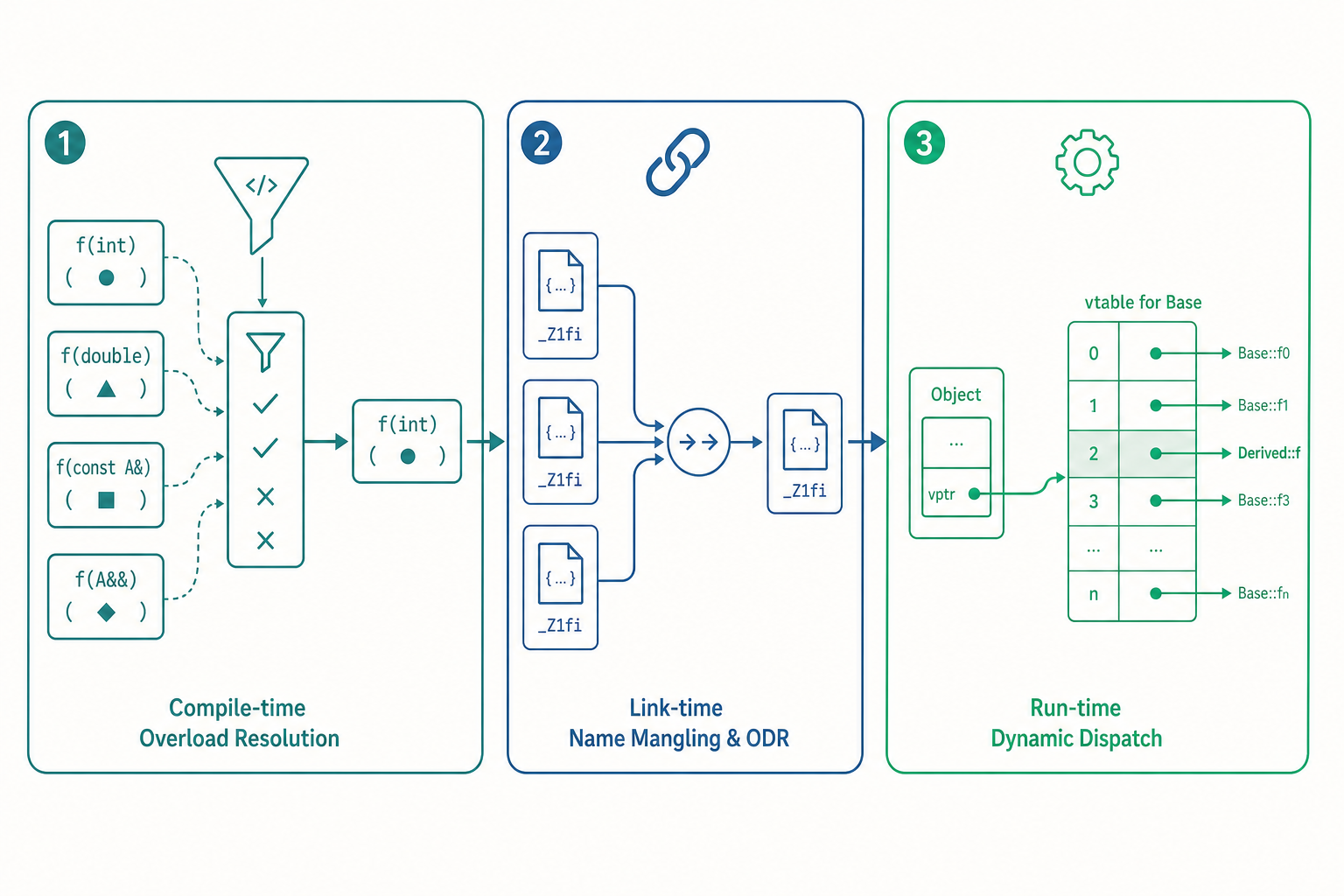
多載決議:一場編譯期的選秀
當一個名字對應多個函數時,C++ 用一套稱為多載決議(overload resolution)的演算法挑出唯一的勝者。這不是「差不多就好」的模糊比對,而是有嚴格規則的三階段過程:
- 名稱查找(name lookup):找出所有「可見」且同名的候選函數,組成候選集合。
- 可行性篩選(viable functions):剔除參數個數不符、或任一引數無法轉換成對應參數型別的候選。
- 最佳匹配(best viable function):在可行候選中,依「轉換成本」排序,挑出嚴格優於其他所有候選的那一個。
關鍵在第三步的「轉換成本」有明確的優先序(由好到差):
- 完全匹配(exact match):型別相同,或只差一個
const/lvalue-to-rvalue 之類的無痛轉換。 - 提升(promotion):如
char→int、float→double。 - 標準轉換(standard conversion):如
int→double、double→int、指標轉void*。 - 使用者定義轉換(user-defined conversion):透過建構子或轉換運算子。
如果沒有任何一個候選嚴格優於其餘所有候選,編譯器就報 ambiguous call(呼叫有歧義)——這不是 bug,而是語言在拒絕替你猜。
看一個例子
#include <iostream>
void f(int) { std::cout << "f(int)\n"; }
void f(double) { std::cout << "f(double)\n"; }
int main() {
f(42); // exact match → f(int)
f(3.14); // exact match → f(double)
f('A'); // 'A' 是 char,promotion 到 int → f(int)
f(3.14f); // float promotion 到 double → f(double)
// f(42L); // long → int 與 long → double 都是 standard conversion
// 兩者「同樣差」,無人勝出 → ambiguous,編譯失敗
}
最後一行被註解掉的 f(42L) 是經典陷阱:long 既不能無痛變 int 也不能無痛變 double,兩條路都是「標準轉換」等級,成本相同,於是沒有最佳匹配。新增一個 f(long) 或在呼叫端明確轉型,才能解決。
這也解釋了一個常見迷思:「多載是看回傳型別嗎?」不是。 多載決議完全不考慮回傳型別,因為決議發生在「知道引數」的當下,而回傳值要怎麼用是之後的事。下面這組無法編譯:
int g(int);
double g(int); // 錯誤:只有回傳型別不同,不構成合法多載
模板、普通函數與 SFINAE:候選集合如何被擴張
當候選集合裡同時有 function template 和普通函數(non-template)時,規則再加一層:若兩者都是完全匹配,普通函數優先。模板是「萬一沒有更具體的就用我」的後備。
template <typename T>
void h(T) { std::cout << "template\n"; }
void h(int) { std::cout << "non-template\n"; }
h(42); // non-template 勝出(同為 exact match 時普通函數優先)
h(3.14); // 沒有 h(double) 普通版,模板以 T=double 實例化
更精妙的是模板在型別推導(type deduction)階段就可能被淘汰。如果把某個引數型別代入模板會產生「不合法的型別」,這個模板候選會被安靜地移除,而不是觸發編譯錯誤——這就是著名的 SFINAE(Substitution Failure Is Not An Error,替換失敗不算錯誤)。
#include <type_traits>
// 只對整數型別開放這個多載
template <typename T,
typename = std::enable_if_t<std::is_integral_v<T>>>
void only_int(T value) {
std::cout << "整數版:" << value << "\n";
}
only_int(10); // OK,is_integral<int> 為真
// only_int(3.14); // 編譯失敗:替換 enable_if 後此候選被移除,且無其他候選
SFINAE 是 C++ 在沒有 concepts 的年代用來「按型別條件挑選多載」的工具。在 C++20 之後,concepts 讓同樣的事更可讀:
#include <concepts>
void only_int(std::integral auto value) { // C++20 寫法
std::cout << "整數版:" << value << "\n";
}
兩者的本質一致:在候選集合層面做篩選,而非在函數體內 if 判斷。差別在 concepts 把意圖寫在介面上,錯誤訊息也短得多。
連結與 ODR:函數的「身分證」為什麼會打架
入門篇講過宣告與定義分離。進階問題是:同一個函數在多個翻譯單元(translation unit)裡會不會衝突? 這牽涉到兩條規則——name mangling(名稱修飾)與 ODR(One Definition Rule,單一定義原則)。
C++ 為了支援多載,連結器看到的不是 f,而是把參數型別編碼進去後的「修飾名」,例如 f(int) 可能變成 _Z1fi、f(double) 變成 _Z1fd。這正是多載能在連結期不打架的底層機制,也是為什麼從 C 呼叫 C++ 函數要加 extern "C"——它要求編譯器不要修飾這個名字:
extern "C" void log_message(const char* msg); // 連結器看到的就是 log_message
ODR 則規定:一個非 inline 的函數,在整個程式裡只能有一個定義。如果你把函數定義(不只是宣告)放進 .h,而這個 .h 被兩個 .cpp 各 include 一次,連結時就會出現「multiple definition」錯誤。解法有三:
// 解法 1:header 只放宣告,定義留在單一 .cpp
// math_utils.h
int square(int x); // 宣告
// math_utils.cpp
int square(int x) { return x * x; } // 唯一定義
// 解法 2:定義在 header,但標 inline(允許跨單元重複,連結器去重)
// math_utils.h
inline int square(int x) { return x * x; }
// 解法 3:模板與 constexpr 隱含 inline,本來就能放 header
// math_utils.h
template <typename T>
T square(T x) { return x * x; } // 模板:每個翻譯單元各自實例化、連結期合併
這裡要破除一個迷思:inline 的主要意義早已不是「叫編譯器把函數展開」。 現代編譯器的內聯(inlining)決策幾乎不看 inline 關鍵字,而是看最佳化分析。inline 在語意上真正保證的是「這個定義允許出現在多個翻譯單元,且它們必須完全相同」——它放寬的是 ODR,不是強制展開。
動手算一下:為什麼 header-only 函式庫存在
假設你寫一個只有 header 的小工具,全部用 inline 或 template。當 5 個 .cpp 都 include 它時,編譯器會在每個翻譯單元各產生一份定義(共 5 份),連結器再依 ODR 規則「保留一份、丟掉其餘 4 份」。代價是編譯期變慢(同樣的程式碼被解析 5 次),好處是散布簡單(使用者只要一個 .h)。這就是 header-only library 的工程取捨:用編譯時間換散布便利。理解 ODR,你才知道這份「重複」為什麼合法、又為什麼有成本。
靜態 vs 動態分派:呼叫在哪個階段被決定
到目前為止,所有決議都發生在編譯期——這稱為靜態分派(static dispatch)。但一旦牽涉繼承與 virtual,呼叫的目標可能要到執行期才知道,這是動態分派(dynamic dispatch)。
struct Shape {
virtual double area() const { return 0; } // virtual
virtual ~Shape() = default;
};
struct Circle : Shape {
double r;
explicit Circle(double r) : r(r) {}
double area() const override { return 3.14159 * r * r; }
};
double total(const Shape& s) {
return s.area(); // 哪個 area()?編譯期不知道,看執行期 s 的真正型別
}
機制上,每個有 virtual 函數的類別有一張 vtable(虛擬函數表),每個物件多帶一個指向該表的 vptr。呼叫 s.area() 時實際做的是:讀 vptr → 查 vtable 對應槽位 → 跳到函數位址。多了一次間接記憶體存取,且因為目標不固定,編譯器通常無法內聯這次呼叫。這就是「為什麼有些呼叫幾乎免費、有些要查表」的答案。
| 維度 | 靜態分派(多載/模板) | 動態分派(virtual) |
|---|---|---|
| 決議時機 | 編譯期 | 執行期 |
| 成本 | 直接呼叫,可內聯 | vtable 間接,難內聯 |
| 多型形式 | 編譯期多型(compile-time polymorphism) | 執行期多型(runtime polymorphism) |
| 取捨 | 速度快,但型別在編譯期就固定 | 彈性高,可跑時換實作 |
兩者沒有絕對優劣:模板給你零成本抽象但二進位膨脹、錯誤訊息冗長;virtual 給你跑時彈性但每次呼叫有間接成本。成熟的程式設計者會依「型別集合在編譯期是否已知」來選擇。
重點回顧
- 多載決議是嚴格的三階段演算法(名稱查找 → 可行性篩選 → 最佳匹配),只看引數不看回傳型別;沒有唯一勝者就報歧義,這是語言在拒絕替你猜。
- 轉換成本有明確優先序:完全匹配 > 提升 > 標準轉換 > 使用者定義轉換;理解這個排序能解釋大多數「為什麼選了這個多載」的疑惑。
- 模板與普通函數同台時普通函數優先;模板還能透過 SFINAE/concepts 在候選層面被條件性篩選,而非在函數體內判斷。
inline的現代意義是放寬 ODR(允許跨翻譯單元重複定義),而非強制內聯展開;這也是 header-only 函式庫合法存在的基礎。- 靜態分派在編譯期定案、可內聯;動態分派(virtual)靠 vtable 在執行期查表,多一次間接存取且通常無法內聯——這是抽象彈性的執行期代價。
深入探討(研究所視角)
從型別理論與編譯器實作的角度,本文的核心其實是一個更普遍的命題:多型的成本可以被「移動」到不同的計算階段。模板對應的是參數化多型(parametric polymorphism)的一種特化策略——單型化(monomorphization):編譯器替每個用到的型別生成一份專屬程式碼。Rust 的泛型與 C++ 模板都採此路,代價是程式碼膨脹(code bloat)與編譯時間爆炸;相對地,Java 泛型走的是型別擦除(type erasure),跑時只有一份程式碼,代價是裝箱與動態檢查。C++ 的 virtual 機制則是子型別多型(subtype polymorphism)的具現,等價於把一張函數指標表(vtable)嵌進物件——這在本質上和 OCaml 的物件、Go 的 interface「胖指標(fat pointer,資料指標+方法表指標)」是同構的設計。
更前沿地,多載決議與 concepts 約束的可滿足性檢查,可以形式化為一個約束求解(constraint satisfaction)問題。C++20 的 concepts 引入了原子約束(atomic constraints)的偏序與包含關係(subsumption),使「哪個約束更特化」成為可判定的邏輯蘊涵問題——這把原本靠 SFINAE 隱式表達、難以推理的特化偏好,提升為可被編譯器明確排序的格(lattice)結構。值得研究的開放問題包括:concepts 的包含判定在病態情形下的複雜度(涉及命題邏輯蘊涵,最壞情況非平凡)、以及模板實例化的圖靈完備性——C++ 模板元程式設計(template metaprogramming)已被證明在編譯期圖靈完備,這意味著「函數選擇」這件事在 C++ 裡並非單純查表,而是一個可能不停機的計算過程。當你下次看到一頁長的模板錯誤訊息時,不妨把它理解為:編譯器正在替你執行一段你寫在型別層的程式。