
Java 集合框架:從點名冊到 ArrayList、HashMap、HashSet
用一份會長大的修課名單,動手學會 Java 的 List、Map、Set 與泛型集合,並看清楚靜態強型別與 OOP-first 的設計取捨。
從「一份點名冊」開始:當你的資料多到不想再寫 String[] names = new String[40]
想像你正在寫一支管理通識課修課名單的小程式。第一週,你信心滿滿地宣告了一個陣列:String[] names = new String[40]。第二週,加退選結束,來了第 41 個同學——陣列爆了。你只好複製一個更大的陣列、把舊資料搬過去。第三週,老師要你「依學號查座號」,你又得手寫一個雙層迴圈逐一比對。第四週,老師說「去掉重複報名的人」,你的迴圈開始長得像義大利麵。
這些需求——會長大的清單、用鍵找值、自動去重——幾乎是每一支程式都會遇到的。Java 的設計者很早就明白這件事,於是在標準函式庫裡內建了一整套集合框架(Collections Framework),把這些常見的資料結構一次幫你寫好、測好、最佳化好。你只要學會挑對工具,就不必再重造輪子。
相較於 Python 把 list、dict、set 做成語言內建的字面語法([]、{}),Java 把它們設計成標準函式庫裡的一組介面與類別。這個差異不是「Java 比較囉嗦」那麼簡單,而是反映了 Java 的核心性格:靜態強型別、OOP 優先、面向大型企業系統。這篇文章就帶你動手把這套框架用熟,並且看清楚它背後的設計取捨。
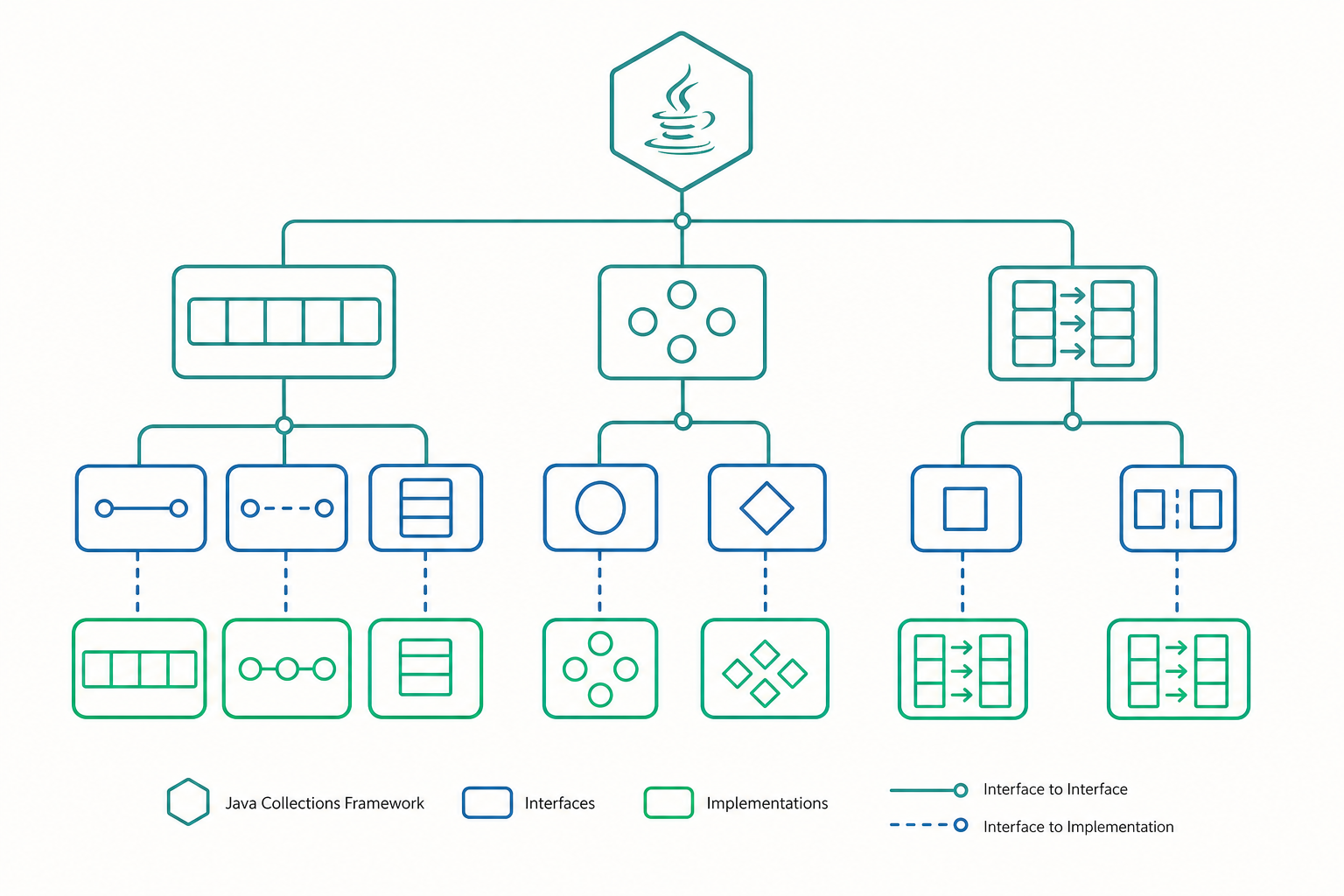
Collection 體系:一張「介面繼承圖」勝過一千個類別
Java 集合框架最核心的觀念是:先有介面(interface),才有實作(implementation)。整張圖大致長這樣:
Iterable
│
Collection ────────────┐
│ │ │
List Set Queue
│ │
ArrayList HashSet
LinkedList TreeSet
Map(注意:Map 不屬於 Collection)
│
HashMap / TreeMap / LinkedHashMap
幾個關鍵概念:
Collection是「一群元素」的總稱,底下分成List(有順序、可重複)、Set(不重複)、Queue(佇列)。Map是「鍵 → 值」的對應,它不繼承Collection,自成一系。這是初學者最常搞混的地方。ArrayList、HashMap這些是實作類別;List、Map是介面。
這帶出 Java 的一個重要慣例——面向介面寫程式(program to the interface):
// 推薦:宣告型別用介面,建立物件用實作類別
List<String> names = new ArrayList<>();
Map<String, Integer> seatOf = new HashMap<>();
// 不推薦:型別寫死成實作類別
ArrayList<String> names2 = new ArrayList<>();
為什麼?因為哪天你發現 ArrayList 不適合、想換成 LinkedList,只要改 new 的那一邊,宣告型別 List<String> 完全不用動,呼叫端的程式碼也不受影響。這種「把使用方式和具體實作分離」的思維,正是 Java OOP-first 性格的縮影。相較之下,Python 是動態型別,變數本身沒有宣告型別,這種「面向介面」的紀律就比較靠約定而非語言強制。
泛型集合:讓編譯器在「執行前」就抓出型別錯誤
你大概注意到上面每個集合後面都跟著角括號:List<String>、Map<String, Integer>。這就是 泛型(Generics)。
List<String> names = new ArrayList<>();
names.add("林同學");
names.add("陳同學");
// 下面這行根本無法通過編譯
names.add(42); // ❌ 編譯錯誤:int 不是 String
<String> 告訴編譯器「這個清單裡只能放 String」。任何試圖放進別種型別的程式碼,會在編譯階段就被擋下來,根本跑不起來。這是 Java「靜態強型別」的核心優勢:錯誤越早被發現越便宜。
相較於 Python 的 list 可以同時塞數字、字串、字典,Java 故意讓集合是同質(homogeneous)的。你或許覺得這很死板,但在動輒數十萬行、多人協作的企業系統裡,「這個清單一定只裝得下 User」這種編譯期保證,能省下大量執行期才會炸開的低級錯誤。
取出元素時也不必再手動轉型:
String first = names.get(0); // 直接就是 String,不用 (String) 強制轉型
小提醒:右邊的
new ArrayList<>()角括號裡是空的,這叫 菱形運算子(diamond operator)。Java 7 之後編譯器會自動從左邊的宣告推論出型別,你不必把<String>寫兩遍。
List 與 ArrayList:會自己長大的陣列
ArrayList 是最常用的 List 實作,把它想成「會自動擴充的陣列」。回到開頭那個點名冊的痛點,現在它消失了:
import java.util.ArrayList;
import java.util.List;
List<String> roster = new ArrayList<>();
roster.add("林同學"); // 加到尾端
roster.add("陳同學");
roster.add("黃同學");
System.out.println(roster.size()); // 3,永遠不會「陣列爆掉」
System.out.println(roster.get(1)); // 陳同學(索引從 0 開始)
roster.set(1, "陳大文"); // 改第 1 個
roster.remove("黃同學"); // 依內容刪除
roster.add(0, "插隊同學"); // 插到最前面
System.out.println(roster.contains("林同學")); // true
System.out.println(roster.isEmpty()); // false
常用方法整理:add、get、set、remove、size、contains、indexOf、isEmpty、clear。和 Python 的 list 概念幾乎一一對應,差別只是方法名稱(Java 用 add/size/get,Python 用 append/len()/[])。
Map 與 HashMap:用鍵找值,不用再寫雙層迴圈
開頭那個「依學號查座號」的需求,正是 Map 的主場。HashMap 讓你用一個鍵(key)瞬間找到對應的值(value):
import java.util.HashMap;
import java.util.Map;
Map<String, Integer> seatOf = new HashMap<>();
seatOf.put("B12345", 7); // 學號 → 座號
seatOf.put("B12346", 12);
seatOf.put("B12347", 3);
System.out.println(seatOf.get("B12346")); // 12
System.out.println(seatOf.containsKey("B99999")); // false
// 查不到鍵時,給一個預設值,避免 null
int seat = seatOf.getOrDefault("B99999", -1); // -1
seatOf.put("B12345", 8); // 同一個鍵再 put,會「覆蓋」舊值
System.out.println(seatOf.get("B12345")); // 8
System.out.println(seatOf.size()); // 3(鍵不重複)
注意幾個重點:
- 鍵不可重複,重複
put同一個鍵會覆蓋舊值。 get一個不存在的鍵會回傳null——這是NullPointerException的常見來源,所以慣例上多用getOrDefault。HashMap不保證順序。若你需要「依插入順序」走訪,改用LinkedHashMap;需要「依鍵排序」,改用TreeMap。三者方法完全相同,只要換new的那一邊。
這又呼應了「面向介面」的好處:Map<String, Integer> 這個宣告型別撐得起三種不同實作。
Set 與 HashSet:自動去重的集合
開頭第四週那個「去掉重複報名的人」的需求,交給 HashSet 一行解決——它自動拒絕重複元素:
import java.util.HashSet;
import java.util.Set;
Set<String> signups = new HashSet<>();
signups.add("林同學");
signups.add("陳同學");
signups.add("林同學"); // 重複,會被默默忽略
System.out.println(signups.size()); // 2,不是 3
System.out.println(signups.contains("陳同學")); // true
Set 最常見的用途就是去重,以及「快速判斷某元素是否存在」。它和 List 的關鍵差別是:Set 不允許重複、且(HashSet)不保證順序。
一個非常實用的慣用法是用 Set 一行去掉 List 裡的重複:
List<String> withDup = new ArrayList<>(List.of("A", "B", "A", "C", "B"));
Set<String> unique = new HashSet<>(withDup); // 直接把 List 倒進 Set
System.out.println(unique.size()); // 3
走訪集合:三種寫法,挑順手的用
「走訪(iterate)」就是把集合裡的元素逐一拿出來處理。Java 提供幾種寫法,由舊到新:
List<String> roster = new ArrayList<>(List.of("林", "陳", "黃"));
// 寫法一:增強型 for 迴圈(for-each),最常用、最易讀
for (String name : roster) {
System.out.println(name);
}
// 寫法二:傳統索引 for(需要索引時才用)
for (int i = 0; i < roster.size(); i++) {
System.out.println(i + ": " + roster.get(i));
}
// 寫法三:forEach + Lambda(Java 8 之後的函數式風格)
roster.forEach(name -> System.out.println(name));
走訪 Map 時,記得它是「鍵值對」,要用 entrySet():
Map<String, Integer> seatOf = new HashMap<>();
seatOf.put("B12345", 7);
seatOf.put("B12346", 12);
for (Map.Entry<String, Integer> e : seatOf.entrySet()) {
System.out.println(e.getKey() + " 坐 " + e.getValue() + " 號");
}
// 只要鍵 → keySet();只要值 → values()
for (String id : seatOf.keySet()) { /* ... */ }
⚠️ 走訪時不要修改集合本身。在 for-each 迴圈裡呼叫
roster.remove(...)會丟出ConcurrentModificationException。要邊走訪邊刪除,請改用Iterator的remove(),或在 Java 8+ 直接用roster.removeIf(name -> name.equals("黃"))。
動手寫一段:用三種集合做一份「投票統計」
我們把 List、Map、Set 串起來,做一個完整可執行的小程式:統計一輪投票結果,並列出有哪些不重複的候選人。
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class VoteCounter {
public static void main(String[] args) {
// 1. 用 List 收集每一票(允許重複,有先後順序)
List<String> votes = new ArrayList<>(
List.of("貓", "狗", "貓", "鳥", "狗", "貓")
);
// 2. 用 Map 統計每個選項的票數(鍵 → 累計)
Map<String, Integer> tally = new HashMap<>();
for (String v : votes) {
tally.put(v, tally.getOrDefault(v, 0) + 1);
}
// 3. 用 Set 取得「有哪些不重複的候選人」
Set<String> candidates = new HashSet<>(votes);
System.out.println("總票數:" + votes.size());
System.out.println("候選人數:" + candidates.size());
for (Map.Entry<String, Integer> e : tally.entrySet()) {
System.out.println(e.getKey() + ":" + e.getValue() + " 票");
}
}
}
// 輸出(HashMap 不保證順序,每行先後可能不同):
// 總票數:6
// 候選人數:3
// 貓:3 票
// 狗:2 票
// 鳥:1 票
這段 tally.put(v, tally.getOrDefault(v, 0) + 1) 是 Java 統計次數的經典慣用法,請務必記熟。它的意思是「拿出 v 目前的票數(沒有就當 0),加一,再放回去」。
常見錯誤:初學者最容易踩的五個雷
-
用
==比較字串或物件相等。==比的是「是不是同一個物件參考」,不是內容。要比內容請用.equals()。HashMap、HashSet判斷鍵/元素是否重複,靠的正是equals()與hashCode(),不是==。 -
把自訂類別當
HashMap的鍵或HashSet的元素,卻沒覆寫equals()和hashCode()。沒覆寫的話,兩個「內容相同」的物件會被當成不同的鍵,去重和查找全部失效。記住:這兩個方法要嘛都覆寫、要嘛都不覆寫,且邏輯要一致。 -
對
get回傳的null直接操作。map.get("不存在的鍵")回傳null,接著呼叫它的方法就會NullPointerException。養成用getOrDefault或先containsKey的習慣。 -
在 for-each 走訪過程中增刪集合元素,導致
ConcurrentModificationException。改用removeIf或Iterator。 -
把宣告型別寫死成實作類別(
ArrayList<String> x = ...)。慣例上左邊用介面List、Map、Set,保留日後抽換實作的彈性。
重點回顧
Collection底下有List(有序可重複)、Set(不重複)、Queue;Map(鍵值對)自成一系、不屬於Collection。- 泛型
<T>讓集合同質化,型別錯誤在編譯期就被擋下——這是 Java 靜態強型別的核心價值。 - 宣告用介面、建立用實作類別(
List<String> x = new ArrayList<>()),方便日後抽換。 - 走訪首選 for-each;走訪
Map用entrySet();走訪中要刪除用removeIf。
深入探討(研究所視角)
到這裡你已經會用了。但要選對工具、寫出高效能程式,得理解它們底層怎麼實作。
ArrayList vs LinkedList:同樣是 List,複雜度天差地遠
兩者都實作 List 介面,呼叫方式一模一樣,但內部結構完全不同:
ArrayList底層是一個連續的陣列(Object[] elementData)。LinkedList底層是雙向鏈結串列,每個節點存著「前一個」和「後一個」的參考。
這個差異直接決定了各操作的時間複雜度:
| 操作 | ArrayList |
LinkedList |
|---|---|---|
依索引存取 get(i) |
$O(1)$ | $O(n)$ |
尾端新增 add(e) |
攤銷 $O(1)$ | $O(1)$ |
| 中間插入/刪除 | $O(n)$ | $O(1)$(已定位節點時) |
依內容搜尋 contains |
$O(n)$ | $O(n)$ |
ArrayList 的 get(i) 是 $O(1)$,因為陣列可以用「起始位址 + i × 元素大小」直接算出記憶體位置。但中間插入要把後面所有元素往後搬,是 $O(n)$。
LinkedList 反過來:它沒有索引,get(i) 得從頭沿著鏈結走 $i$ 步,是 $O(n)$;但若你手上已經握著某個節點,插入/刪除只要改幾個參考,是 $O(1)$。
那「攤銷 $O(1)$」是什麼意思? ArrayList 的底層陣列有固定容量,塞滿時得「擴容」:配置一個更大的新陣列(通常是 1.5 倍),把舊資料整批複製過去——這次 add 是 $O(n)$。但因為容量翻倍式成長,這種昂貴的擴容很罕見,把總成本平均(攤銷,amortized)到每次 add,仍是 $O(1)$。這就是攤銷分析(amortized analysis)。
實務結論:絕大多數情況用 ArrayList。它記憶體連續、對 CPU 快取友善,即使理論上某些操作較慢,實測往往還是贏。只有在「頻繁從頭尾增刪、且幾乎不做隨機索引存取」的佇列/雙端佇列場景,LinkedList(或更該用 ArrayDeque)才有意義。
HashMap 的雜湊桶:$O(1)$ 查找是怎麼做到的
HashMap 號稱平均 $O(1)$ 的存取,魔法藏在雜湊桶(hash bucket)裡。
底層是一個陣列 Node<K,V>[] table,每一格叫一個「桶」。當你 put(key, value):
- 對
key呼叫hashCode()取得雜湊值,再經過擾動(Java 8 用h ^ (h >>> 16),讓高位也參與運算、減少碰撞)。 - 用
(table.length - 1) & hash算出該放進哪個桶的索引(因為容量恆為 2 的次方,這個位元運算等價於取餘數,但更快)。 - 把鍵值對放進那個桶。
查找時重複同樣計算,一步就定位到桶——這就是 $O(1)$ 的來源。
但兩個不同的鍵可能算出同一個桶索引,這叫雜湊碰撞(collision)。Java 的處理方式:
- 鏈結法(chaining):同一個桶裡的元素串成一條鏈結串列。查找時在這條短鏈上逐一用
equals()比對。 - Java 8 的優化:當單一桶的鏈結長度超過門檻(預設 8)且總容量夠大時,會把該桶的鏈結轉成紅黑樹(red-black tree),把最壞情況的查找從 $O(n)$ 降到 $O(\log n)$,防止惡意碰撞攻擊把效能拖垮。
此外,當已存元素數量超過 容量 × 載入因子(load factor,預設 0.75),HashMap 會擴容(resize):容量翻倍,並把所有元素重新分配到新桶(rehash)。這是一次 $O(n)$ 的昂貴操作,所以若你預先知道大概要存多少筆,用 new HashMap<>(預期容量) 指定初始容量,能省下多次擴容。
這也解釋了前面「常見錯誤」第 2 點為什麼那麼重要:整個機制建立在 hashCode() 和 equals() 之上。hashCode() 決定丟進哪個桶,equals() 決定桶內是不是同一個鍵。若你的自訂類別兩者不一致(例如 equals 相等但 hashCode 不同),物件會被丟到不同的桶,HashMap 永遠找不到它。
最後值得一提:相較於 Python 的 dict 用開放定址法(open addressing)處理碰撞,Java 的 HashMap 選了鏈結法 + 樹化。沒有哪種絕對較好,這是不同團隊在「記憶體佈局、快取友善度、最壞情況保證」之間做的不同工程取捨——而能看懂這些取捨,正是從「會用」邁向「懂原理」的分水嶺。動手把上面的程式跑跑看,試著故意製造碰撞、印出 HashMap 在不同插入順序下的走訪結果,你會對這套框架有更立體的理解。