
協定層與 TCP/IP:一封訊息如何穿過半個地球
從分層模型、IP 路由到 TCP 可靠傳輸與壅塞控制,看懂網際網路如何在不可靠的底層上建立可靠的溝通
一封訊息如何穿過半個地球
你在台北用手機按下「傳送」,一張照片在不到一秒鐘內出現在東京朋友的螢幕上。這段旅程中,照片被切成數百個小封包(packet),分別擠進無數條光纖與基地台,可能各走不同路線,甚至有些半路遺失,最後卻能拼回一張完整無缺的圖。沒有任何單一機器知道「整條路」長什麼樣子,卻能準確送達——這不是魔法,而是一套精心設計的協定(protocol)分層在默默運作。
協定就是「溝通的規矩」。兩台素未謀面、作業系統可能完全不同的電腦,之所以能對話,是因為它們都同意遵守同一套規則:什麼時候該說話、訊息怎麼包裝、收到了要怎麼回應。而 TCP/IP 正是支撐整個網際網路(Internet)的這套規矩。
為什麼要分層?
如果讓一台電腦同時操心「電壓訊號怎麼編碼」「資料怎麼不遺失」「網頁內容怎麼呈現」,程式會複雜到無法維護。網路設計者採用了一個經典的工程策略:分層(layering)。每一層只負責一件事,並且只跟上下相鄰的層對話,把細節藏起來只對外提供乾淨的服務。這種「關注點分離(separation of concerns)」讓不同廠商可以各自實作不同層,只要介面一致就能互通。
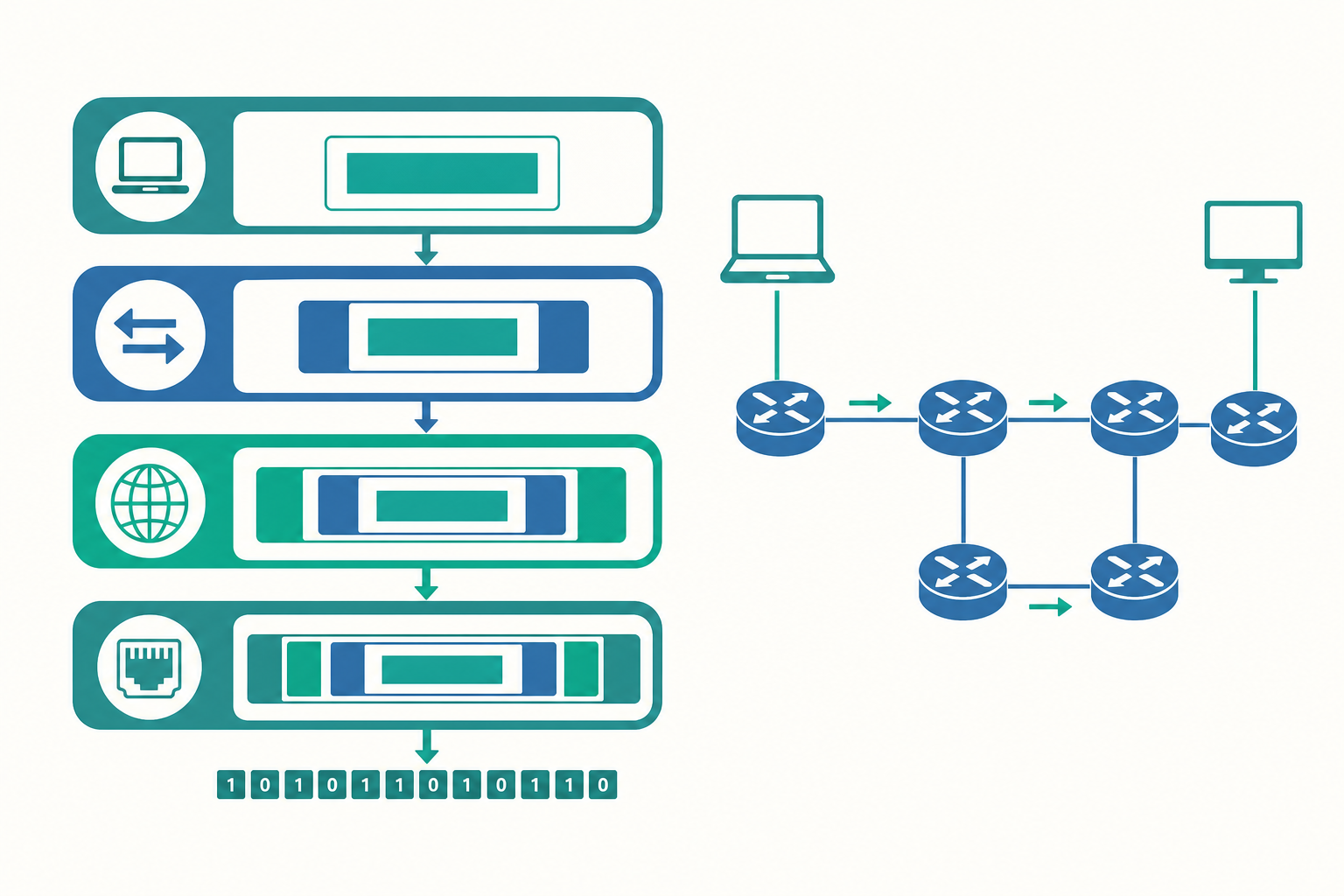
最有名的兩套分層模型是 OSI 七層模型與 TCP/IP 四層模型。OSI 是學術上的參考框架,TCP/IP 則是實際在運作的工程實作。兩者的對應大致如下:
| TCP/IP 四層 | 對應 OSI 層 | 代表協定 | 處理的單位 |
|---|---|---|---|
| 應用層(Application) | 應用/表現/會議層 | HTTP、DNS、SMTP | 訊息(message) |
| 傳輸層(Transport) | 傳輸層 | TCP、UDP | 區段(segment) |
| 網路層(Internet) | 網路層 | IP、ICMP | 封包(packet) |
| 連結層(Link) | 資料連結/實體層 | Ethernet、Wi-Fi | 訊框(frame) |
可以把它想成寄一封國際信件:你寫信(應用層),裝進信封寫上收件人地址(傳輸層與網路層),交給郵局,郵局再決定用卡車還是飛機運送(連結層)。你不需要知道飛機怎麼飛,飛機駕駛也不需要讀你的信。
IP 位址與路由:網路世界的門牌
網路層的核心是 IP(Internet Protocol),它負責「定址」與「路由」。每一台連上網路的裝置都有一個 IP 位址(IP address),就像門牌號碼。IPv4 位址是 32 位元,寫成四段十進位數字,如 140.115.103.70;由於 IPv4 位址不到 43 億個早已不夠用,IPv6 把位址擴展到 128 位元,寫成 2001:0db8:85a3::8a2e:0370:7334 這種十六進位形式。
IP 位址通常分成兩部分:網路前綴(network prefix)與主機部分(host part)。以 CIDR 標記法 140.115.0.0/16 為例,斜線後的 16 代表前 16 位元是網路前綴,剩下的 16 位元用來區分這個網路內的主機。路由器(router)就是靠比對前綴來決定封包該往哪個方向轉送。
路由(routing) 是一個逐跳(hop-by-hop)的接力過程。你的封包不會一口氣抵達終點,而是被一台又一台路由器轉送。每台路由器查自己的路由表(routing table),找出「往這個目的地,下一步該交給誰」,然後把封包丟出去。沒有任何一台路由器掌握全貌——它只需要知道「下一跳(next hop)」是誰。這種去中心化設計正是網際網路能擴展到全球規模的關鍵。
值得注意的是,IP 本身是盡力而為(best-effort)的:它不保證封包一定送達、不保證順序、不保證不重複。它只負責「盡力把封包丟向正確方向」。可靠性的責任,交給了上面的傳輸層。
TCP vs UDP:兩種傳輸哲學
傳輸層有兩個主角,代表兩種截然不同的設計哲學。
UDP(User Datagram Protocol) 像寄明信片:寫上地址直接丟進郵筒,不確認對方收到、不管順序、不重寄。它的標頭只有 8 位元組,極度輕量,速度快、延遲低。代價是不可靠——封包可能遺失或亂序,由應用層自行處理。
TCP(Transmission Control Protocol) 像掛號信加上電話確認:建立連線、逐一確認、保證順序、遺失重寄。它提供可靠的、有序的、雙向的位元組串流(byte stream),代價是較高的開銷與延遲。
| 特性 | TCP | UDP |
|---|---|---|
| 連線導向 | 是(先握手) | 否 |
| 可靠性 | 保證送達、重傳 | 不保證 |
| 順序 | 保證有序 | 不保證 |
| 速度/延遲 | 較高開銷 | 輕量快速 |
| 典型應用 | 網頁、檔案傳輸、Email | 視訊串流、線上遊戲、DNS 查詢 |
選擇哪一個取決於需求:你下載一個檔案,少一個位元組就壞了,必須用 TCP;你在看直播,偶爾掉一格畫面無所謂,但卡頓不能忍,那就用 UDP。
三次握手:建立連線的禮貌
TCP 在傳資料前,必須先「打招呼」建立連線,這個過程稱為三次握手(three-way handshake):
客戶端 伺服器
| |
| ──── SYN (seq=x) ────────────► | 「我想連線,我的起始序號是 x」
| |
| ◄─── SYN-ACK (seq=y, ack=x+1) ─ | 「好,我的序號是 y,已收到你的 x」
| |
| ──── ACK (ack=y+1) ──────────► | 「收到你的 y,開始傳資料吧」
| |
| ═══════ 連線建立完成 ═══════════ |
為什麼是三次而非兩次?因為雙方都必須確認「我能傳給你」且「你能傳給我」這兩件事各一次,三次握手剛好讓雙方都確認彼此的收發能力,並交換各自的初始序號(initial sequence number)。對應地,結束連線需要四次揮手(four-way handshake),因為雙向的串流需要各自獨立關閉。
DNS:把名字翻成位址
人類記得住 uedu.tw,卻記不住 140.115.103.70。DNS(Domain Name System) 就是網際網路的「電話簿」,負責把好記的網域名稱翻譯成 IP 位址。
DNS 採用階層式的分散架構:當你的電腦想查 www.uedu.tw,它會先問本地的解析器(resolver),解析器再依序詢問根伺服器(知道 .tw 在哪)、頂級網域伺服器(知道 uedu.tw 在哪)、最後是 uedu.tw 的權威伺服器(authoritative server,給出實際 IP)。為了避免每次都跑這一圈,各層都會做快取(cache),所以你第二次造訪同一網站通常會快很多。
DNS 查詢大多走 UDP(因為又小又快),這也呼應了前面 UDP 的應用情境。
封裝:層層包裝的旅程
當資料從應用層往下走,每一層都會在前面加上自己的標頭(header),這個過程稱為封裝(encapsulation);資料抵達對方後再層層拆開,稱為解封裝(decapsulation)。
應用層: [ HTTP 資料 ]
傳輸層: [ TCP標頭 | HTTP 資料 ]
網路層: [ IP標頭 | TCP標頭 | HTTP 資料 ]
連結層: [訊框標頭| IP標頭 | TCP標頭 | HTTP 資料 |訊框尾]
像一個一個套上去的信封:最內層是你要說的話,每往外一層就多一層收件資訊。對方收到後從最外層開始拆,每一層讀完屬於自己的標頭就交給上一層。每一層只看自己的標頭,不去動內層的內容——這正是分層設計的優雅之處。
動手看一個例子
讓我們用 Python 觀察一次最樸素的傳輸層通訊。下面用 socket 建立一個 TCP 連線並送出 HTTP 請求,看看「位元組串流」實際長什麼樣:
import socket
# 建立 TCP socket:AF_INET 表示 IPv4,SOCK_STREAM 表示 TCP
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# connect 這一步在底層就觸發了三次握手
s.connect(("example.com", 80))
# 送出一段最簡單的 HTTP 請求(應用層訊息)
request = "GET / HTTP/1.1\r\nHost: example.com\r\nConnection: close\r\n\r\n"
s.sendall(request.encode("utf-8"))
# 接收回應:TCP 是串流,可能要多次 recv 才收完
response = b""
while True:
chunk = s.recv(4096)
if not chunk: # 收到空字串代表對方關閉連線
break
response += chunk
s.close()
print(response.decode("utf-8", errors="ignore")[:200])
幾個關鍵觀察:第一,SOCK_STREAM 就是在選擇 TCP(若改成 SOCK_DGRAM 就是 UDP)。第二,connect() 背後自動完成了三次握手,我們完全不用手動處理序號。第三,那個 while 迴圈很重要——因為 TCP 是串流而非「一封一封的訊息」,作業系統可能把資料分好幾次交給我們,必須持續讀到對方關閉為止。這正體現了 TCP「位元組串流」的本質:它保證所有位元組依序到齊,但不替你劃分訊息邊界,那是應用層的責任。
重點回顧
- 網路用分層化解複雜度:應用層管內容、傳輸層管可靠、網路層管定址路由、連結層管實體傳送,每層只跟相鄰層對話。
- IP 提供盡力而為的定址與逐跳路由;位址分為網路前綴與主機部分,路由器靠比對前綴決定下一跳。
- TCP 可靠有序但開銷大,UDP 輕量快速但不保證;選擇取決於「正確性」與「即時性」孰輕孰重。
- 三次握手讓雙方互相確認收發能力並交換初始序號,才開始傳資料。
- DNS 把網域名稱翻成 IP,採階層式架構並大量使用快取;封裝讓資料層層加上標頭再層層拆解。
深入探討(研究所視角)
前面說 TCP「可靠」,但 IP 底層明明是不可靠的——TCP 究竟如何在沙地上蓋出穩固的高樓?答案藏在四個彼此交織的機制裡。
序號(sequence number)與 ACK。 TCP 替送出的每一個位元組編號。接收端透過累積確認(cumulative ACK) 回報「我已連續收到第 N 號之前的所有位元組,請從 N 開始給我」。這個設計讓接收端能重組亂序到達的封包,並偵測缺漏。現代 TCP 多半還支援選擇性確認(SACK, Selective ACK),能告知「我收到了 1–100 與 200–300,但中間 101–199 不見了」,避免重傳已收到的區段。
重傳(retransmission)。 偵測遺失有兩條路。其一是逾時重傳(RTO, Retransmission Timeout):送出後啟動計時器,逾時未收到 ACK 就重送。RTO 由動態估計的往返時間(RTT)推算,常用 Jacobson 演算法以平滑 RTT 與其變異量計算:
$$\text{RTO} = \text{SRTT} + 4 \times \text{RTTVAR}$$
其二是快速重傳(fast retransmit):當送端連續收到 3 個重複 ACK(duplicate ACK),不必等計時器逾時就立刻重送該區段,反應更快。
壅塞控制(congestion control)。 這是 TCP 最精妙之處。它要解決一個全域協調問題:無數連線共享有限頻寬,若大家都猛灌資料,網路會壅塞崩潰(congestion collapse)。TCP 維護一個壅塞視窗(cwnd, congestion window),限制尚未被確認的在途資料量,並透過經典的兩階段策略動態調整:
- 慢啟動(slow start):cwnd 從一個很小的值開始,每收到一個 ACK 就指數成長(每個 RTT 大約加倍),快速探測可用頻寬。
- 壅塞避免(congestion avoidance):當 cwnd 達到門檻(ssthresh)後改為線性成長(每 RTT 約加一),謹慎逼近極限。
一旦偵測到遺失(視為壅塞訊號),就大幅縮減視窗——這就是著名的 AIMD(Additive Increase, Multiplicative Decrease,加法增大、乘法減小) 原則。實際送出速率還受限於兩個視窗的較小者:
$$\text{有效視窗} = \min(\text{cwnd}, \text{rwnd})$$
其中 rwnd 是接收端宣告的接收視窗(receive window),用於流量控制(flow control)——確保不會把接收方緩衝區灌爆。流量控制(保護接收端)與壅塞控制(保護網路)是兩件不同的事,常被混淆,務必區分。
這些機制連結到更廣的議題。AIMD 之所以被選用,是因為理論上能讓多條競爭連線收斂到公平(fairness) 的頻寬分配,這可用「公平性圖」幾何地證明。而現代的壅塞控制已從以「遺失」為訊號(如 Reno、CUBIC)演進到以「延遲與頻寬量測」為訊號(如 Google 的 BBR),試圖在高頻寬高延遲的網路中取得更好的吞吐與更低的排隊延遲。再往上看,QUIC 協定把可靠傳輸與壅塞控制搬到 UDP 之上、整合 TLS 加密,並在使用者空間實作,正是為了擺脫 TCP 在作業系統核心中難以演進、以及隊頭阻塞(head-of-line blocking)的桎梏——這也說明,即便是看似穩固的基礎協定,網路的演化也從未停歇。