
深入 std::vector:攤銷複雜度、迭代器失效與移動語意
為什麼 push_back 攤銷 O(1)、擴容何時用移動而非複製,以及 std::string 的小字串優化
當 push_back 一次只加一個元素,為什麼整體還是 $O(n)$?
你已經會用 std::vector 了:宣告、push_back、[] 存取、size()。但這裡有一個看似矛盾的事實值得停下來想想。
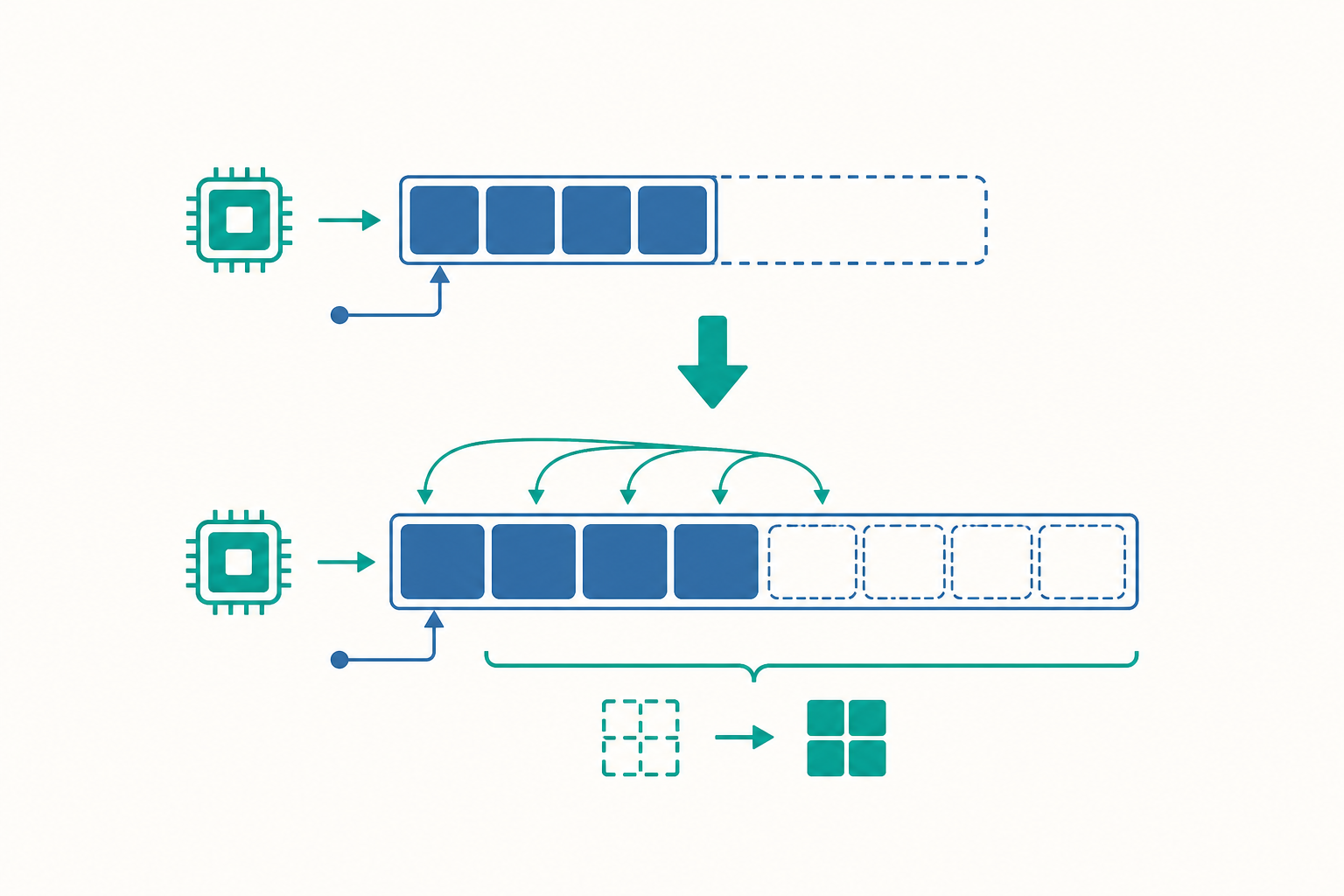
vector 的底層是一塊連續記憶體。當這塊記憶體塞滿、你又呼叫 push_back 時,它必須「搬家」:配置一塊更大的新記憶體、把舊元素全部複製過去、再釋放舊空間。搬一次家的代價是 $O(n)$。那麼,連續呼叫 $n$ 次 push_back,會不會就是 $n$ 次搬家、總共 $O(n^2)$?
如果真是 $O(n^2)$,那 vector 就不堪用了——把一百萬個元素塞進去要做一兆次操作。但實際上,從空 vector 連續 push_back $n$ 次,總成本是 $O(n)$,平均每次只有 $O(1)$。這個「平均」不是運氣好,而是一種可以嚴格證明的保證,叫做攤銷複雜度(amortized complexity)。
這篇文章不再重複「vector 是動態陣列」這種入門結論。我們要鑽進它的內部:成長策略為什麼選 2 倍而不是固定增量、攤銷分析怎麼算、迭代器失效(iterator invalidation)的精確規則、reserve 與 shrink_to_fit 的真實行為,以及移動語意(move semantics)如何讓容器操作從「複製」變成「轉移」。理解這些,你才算真的掌握了現代 C++ 容器。
成長策略:為什麼是「乘以一個倍數」而不是「加一個常數」
vector 滿載時要擴容,關鍵問題是:新容量要設多大?有兩種直覺:
- 固定增量:每次容量 $+k$(例如每次多 10 格)。
- 幾何成長:每次容量 $\times g$(例如每次變 2 倍)。
我們來算固定增量的代價。假設每次擴容 $+k$,從 0 成長到 $n$ 個元素,總共要擴容約 $n/k$ 次。第 $i$ 次擴容時要複製約 $i \cdot k$ 個既有元素。總複製成本是:
$$ \sum_{i=1}^{n/k} i \cdot k = k \cdot \frac{(n/k)(n/k+1)}{2} \approx \frac{n^2}{2k} = O(n^2) $$
無論 $k$ 多大,固定增量都逃不掉 $O(n^2)$。這就是為什麼幾乎所有實作都選擇幾何成長。
幾何成長為什麼快?假設倍率是 2。容量序列是 $1, 2, 4, 8, \dots, n$。每次擴容複製的元素數等於當下容量,總複製成本是:
$$ 1 + 2 + 4 + \dots + n = 2n - 1 = O(n) $$
關鍵在於這是一個等比級數,被最後一項主導。把 $O(n)$ 的總成本攤到 $n$ 次 push_back 上,每次平均 $O(1)$——這就是攤銷 $O(1)$。
#include <vector>
#include <iostream>
int main() {
std::vector<int> v;
size_t last_cap = 0;
for (int i = 0; i < 32; ++i) {
if (v.capacity() != last_cap) {
std::cout << "size=" << v.size()
<< " 觸發擴容, capacity -> " << v.capacity() << "\n";
last_cap = v.capacity();
}
v.push_back(i);
}
}
在 libstdc++(GCC)上你會看到 capacity 走 1, 2, 4, 8, 16, 32 的 2 倍序列;在 libc++(Clang/macOS)也是 2 倍。有趣的是 MSVC 用 1.5 倍。這個差異不是隨意的,背後有記憶體重用的考量,我們留到最後一節談。
動手算一下:攤銷分析的會計法
攤銷 $O(1)$ 可以用更嚴謹的方式證明,這裡介紹直觀的「會計法(accounting method)」。
我們給每次 push_back 收取固定 3 元的「攤銷費用」,看看這筆錢夠不夠用。一次 push_back 的真實工作有兩種:
- 不擴容:只是把元素寫進空格,真實成本 1 元。
- 擴容:要複製當前所有元素,真實成本是當下的 size。
收費 3 元的分配方式是這樣的:
- 1 元付給「把自己寫進新格子」的當下動作。
- 1 元存起來,準備將來「複製自己」時用。
- 1 元存起來,準備將來「複製某個沒存夠錢的舊鄰居」時用。
用 2 倍成長時,每次擴容後,新容量的後半段(也就是新加入的那一半元素)每個都帶著 2 元存款進來。當下一次擴容發生,需要複製的元素數量恰好等於上次擴容後新增的元素數量——而這些元素正好每個都存了夠用的錢。所以帳永遠是平的:每次 push_back 只要付 3 元(常數),$n$ 次總共 $3n = O(n)$。
擴容到容量 4,已有 2 個元素 [a, b](複製成本由它們先前的存款支付)
push c -> [a,b,c] c 存 2 元(共 2 元)
push d -> [a,b,c,d] d 存 2 元(共 4 元) <- 滿了
push e -> 擴容!複製 a,b,c,d 共 4 次,剛好花掉 c,d 存的 4 元
新容量 8,e 進來 [a,b,c,d,e],e 存 2 元
這個會計法的美妙之處:它把「偶爾很貴的擴容」的成本,預先分攤給「便宜的普通插入」,證明了最壞情況的單次操作雖然是 $O(n)$,但任何一連串操作的平均都是 $O(1)$。注意攤銷 $O(1)$ 不等於「每次都 $O(1)$」——某一次 push_back 仍可能因擴容而卡頓 $O(n)$,這在即時系統(real-time system)裡是要小心的。
迭代器失效:那個指向元素的指標,什麼時候會變成廢墟
入門時你大概被告知「擴容後舊迭代器會失效」。但精確的規則比這句話豐富,搞錯會寫出存取已釋放記憶體(use-after-free)的 bug。
#include <vector>
#include <iostream>
int main() {
std::vector<int> v = {10, 20, 30};
int* p = &v[0]; // 指向第一個元素的裸指標
auto it = v.begin(); // 迭代器
v.push_back(40); // 若觸發擴容,整塊記憶體搬家
// 危險!p 與 it 可能指向已被釋放的舊記憶體
// std::cout << *p; // 未定義行為(undefined behavior)
std::cout << v[0]; // 安全:用索引重新存取永遠正確
}
vector 的迭代器失效規則:
push_back/insert/emplace_back:若造成擴容(新 size > 舊 capacity),所有迭代器、指標、參考全部失效。若沒擴容,insert點之後的全部失效,之前的仍有效。erase:被刪除點及其之後的全部失效。reserve/resize變大造成重配置:全部失效。clear:所有迭代器失效,但 capacity 不變(記憶體不歸還)。
對比之下,std::list(雙向鏈結串列)的節點各自獨立配置,刪除某節點只讓指向那一個節點的迭代器失效,其餘安然無恙。這是 vector「連續記憶體」帶來的代價——快取友善(cache-friendly)但結構脆弱。
一個經典陷阱是在迴圈中邊走邊刪:
// ❌ 錯誤:erase 後 it 失效,++it 是未定義行為
for (auto it = v.begin(); it != v.end(); ++it) {
if (*it % 2 == 0) v.erase(it);
}
// ✅ 正確:erase 回傳「被刪元素的下一個」的有效迭代器
for (auto it = v.begin(); it != v.end(); ) {
if (*it % 2 == 0) it = v.erase(it);
else ++it;
}
// ✅ 更好(C++20):用 std::erase 一行解決
std::erase_if(v, [](int x){ return x % 2 == 0; });
reserve、shrink_to_fit 與 size vs capacity 的精確語意
size() 是「目前有幾個元素」,capacity() 是「不重新配置就能容納幾個元素」。兩者分離,正是控制效能的著力點。
如果你事先知道要放多少元素,用 reserve 一次配足,能消除所有中間擴容:
std::vector<int> v;
v.reserve(1'000'000); // 一次配置好,capacity >= 1000000,size 仍為 0
for (int i = 0; i < 1'000'000; ++i)
v.push_back(i); // 全程零擴容,零複製
這把 $O(n)$ 次潛在搬家壓成 1 次配置。在效能敏感的程式碼裡,reserve 是最便宜的優化之一。
反方向的問題是:vector 縮小(erase、clear、pop_back)時,capacity 不會自動下降——記憶體被保留以備重用。要主動歸還記憶體得用 shrink_to_fit,但它只是「請求」,標準不保證實作一定照辦:
std::vector<int> v(1000);
v.clear(); // size=0,但 capacity 仍 1000
v.shrink_to_fit(); // 請求把 capacity 降到貼近 size
// 保證歸還記憶體的慣用法:swap 技巧(C++11 前的經典手法)
std::vector<int>().swap(v); // 與一個空的臨時 vector 交換,舊記憶體隨臨時物件析構
特別提醒一個 reserve 的反模式:不要在迴圈裡反覆呼叫 reserve 來「逐步」擴容。reserve(n) 只在 $n >$ 當前 capacity 時才重配置,所以 reserve(size()+1) 每次都可能觸發重配置,反而退化成 $O(n^2)$。要嘛一次 reserve 到位,要嘛就放手讓 push_back 用它的幾何成長策略。
移動語意:當「搬家」從複製變成轉移
回到開頭的擴容。擴容要把舊元素搬到新記憶體——但「搬」到底是複製還是移動,對效能影響巨大。考慮 std::vector<std::string>,每個 string 內部又是一塊堆積(heap)記憶體:
#include <vector>
#include <string>
std::vector<std::string> names;
names.push_back("一段很長很長的字串,內部有自己的堆積記憶體配置...");
// ... 觸發擴容時,這個 string 要被搬到新位置
若用複製搬家,每個 string 都要重新配置堆積、逐字元複製,代價昂貴。若用移動搬家,只需把舊 string 的內部指標「偷」給新位置、把舊的設為空殼——$O(1)$ 的指標轉移,不碰字元資料。
C++11 的移動語意讓這成為可能,但有一個反直覺的條件:擴容時,只有當元素型別的移動建構子(move constructor)標記為 noexcept,vector 才會用移動;否則為了異常安全(exception safety)退回用複製。
原因是「強異常保證(strong exception guarantee)」:擴容過程中若搬到一半某個元素的移動丟出例外,已被搬走(掏空)的舊元素無法復原,vector 會處於壞掉的中間狀態。複製則不同——複製失敗時舊元素原封不動,可以安全回滾。所以標準函式庫保守地規定:移動可能丟例外時,寧可慢一點用複製,也要保住資料完整。
#include <vector>
#include <iostream>
struct Widget {
Widget() = default;
Widget(const Widget&) { std::cout << "複製\n"; }
// 關鍵:標記 noexcept,vector 擴容才會選用移動
Widget(Widget&&) noexcept { std::cout << "移動\n"; }
};
int main() {
std::vector<Widget> v;
v.reserve(1);
v.emplace_back(); // 第一個元素
std::cout << "--- 觸發擴容 ---\n";
v.emplace_back(); // 擴容,搬移已有元素:印出「移動」
}
把 move constructor 的 noexcept 拿掉,重新編譯,輸出會變成「複製」。這是一個常被忽略卻影響深遠的細節:為你的類別正確標記 noexcept 移動,是讓它在 vector 中高效運作的前提。 好消息是,編譯器自動生成的移動建構子,在所有成員都 noexcept-movable 時會自動帶上 noexcept,所以多數情況你不必手動操心。
std::string 的小字串優化(SSO):不是每個字串都住在堆積
std::string 常被當成「字元的 vector」,但它有一個 vector 沒有的招數:小字串優化(Small String Optimization, SSO)。
短字串(通常 15 個字元以內,依實作而定)會直接存在 string 物件本身的堆疊(stack)空間裡,完全不配置堆積記憶體。只有超過門檻才退回到動態配置。
#include <string>
#include <iostream>
int main() {
std::string s = "hi"; // 短,存在物件內部,無堆積配置
std::cout << s.capacity() << "\n"; // libstdc++ 通常印 15
std::string big(100, 'x'); // 長,配置堆積
std::cout << big.capacity() << "\n"; // >= 100
}
SSO 的意義是:建立大量短字串(網路封包欄位、解析出的 token、map 的 key)幾乎零堆積配置成本,避免了 malloc/free 的開銷與記憶體碎片。代價是 sizeof(std::string) 比想像中大(典型 32 bytes),因為要預留內嵌緩衝區。這是「用空間換配置次數」的經典取捨,也解釋了為什麼 string 不能簡單地用 vector<char> 取代。
重點回顧
- 幾何成長(2 倍)讓
push_back攤銷 $O(1)$:總複製成本是等比級數 $O(n)$;固定增量則退化為 $O(n^2)$。攤銷 $O(1)$ 不代表每次都快,擴容那一次仍是 $O(n)$。 - 迭代器失效有精確規則:
push_back擴容時全部失效;不擴容時 insert 點之後失效;erase回傳下一個有效迭代器。用索引重新存取永遠安全。 size與capacity分離是優化的著力點:已知數量就reserve一次到位;縮小不自動還記憶體,要shrink_to_fit或 swap 技巧。別在迴圈裡逐步reserve。- 擴容用移動還是複製,取決於
noexcept:移動建構子標noexcept才會被 vector 採用,否則為異常安全退回複製。為自訂類別正確標記是高效的前提。 std::string有 SSO:短字串內嵌於物件、零堆積配置;這是 string 與vector<char>的本質差異之一。
深入探討(研究所視角)
成長倍率與記憶體重用:為什麼有些實作選 1.5 而非 2。 倍率 2 有一個理論上的缺陷:歷次配置的區塊大小是 $1, 2, 4, 8, \dots$,任何一次新配置所需的空間,都嚴格大於先前所有已釋放區塊的總和($2^k > 2^{k-1} + \dots + 1$)。這意味著在簡單的順序配置器下,vector 永遠無法重用之前釋放的記憶體,只能不斷往位址高處延伸。若倍率取黃金比例 $\varphi \approx 1.618$ 以下(如 MSVC 的 1.5),則經過若干次成長後,累積釋放的空間總和會超過下一次所需,配置器有機會重用舊空間,降低記憶體峰值與碎片。這是個經典的工程取捨:成長越快,重配置次數越少(複製成本低)但記憶體峰值高且難重用;成長越慢則相反。實務上 1.5 與 2 的差異在多數工作負載中不顯著,但它揭示了「攤銷分析只看時間、不看空間局部性」的盲點。
勢能法(potential method)與更嚴格的攤銷證明。 會計法直觀但不夠形式化。研究所層級會用勢能函數(potential function) $\Phi$:定義 $\Phi = 2 \cdot \text{size} - \text{capacity}$,攤銷成本定義為 $\hat{c}_i = c_i + \Phi_i - \Phi_{i-1}$。可證明無論是否擴容,每次 push_back 的攤銷成本都恆為常數。勢能法的威力在於它能處理 push_back 與 pop_back 交錯、甚至帶縮容(shrink)的混合序列——只要勢能函數設計得當,就能證明整串操作的攤銷界限,這在分析 deque、splay tree、Fibonacci heap 等資料結構時是核心工具。
vector<bool> 的特化爭議。 標準函式庫對 std::vector<bool> 做了特化:它不是真正存 bool,而是用位元壓縮(bit-packing),每個元素只佔 1 bit。代價是 operator[] 不回傳 bool&,而是回傳一個代理物件(proxy),導致 auto x = v[i] 的型別不是 bool 而是代理,&v[i] 也無法取得真正的指標。這個「為了省空間而破壞容器一致語意」的設計被廣泛視為標準的歷史性失誤,C++ 委員會至今未能移除它(向後相容包袱)。需要位元集合時,固定大小用 std::bitset、動態用 std::vector<char> 或 boost::dynamic_bitset 通常是更乾淨的選擇。理解這個案例,能幫你體會「過早優化進標準介面」的長期代價。
從 vector 到 std::span(C++20)與資料導向設計。 現代高效能 C++(遊戲引擎、HPC)強調資料導向設計(data-oriented design):把同型別資料連續排列以最大化快取命中。vector 的連續記憶體正是基礎,而 C++20 的 std::span 提供一個不擁有記憶體的「視窗」,讓函式能無痕接收 vector、C 陣列、std::array 的連續區段而不複製。延伸閱讀方向包括:SoA(Structure of Arrays)vs AoS(Array of Structures)的快取行為、std::pmr(polymorphic memory resource)讓你替容器換上 arena/stack 配置器以控制配置策略、以及 false sharing 在多執行緒共寫連續陣列時的效能陷阱。這些主題把「容器」從語法層級提升到系統效能工程的層級,是計算密集領域研究的起點。