
堆疊與佇列(進階):攤還的魔法、單調結構與併發惡夢
用兩個 LIFO 堆疊拼出 FIFO 佇列,以勢能法證明攤還 O(1),再看單調堆疊/佇列如何壓垮 O(n²),最後走進無鎖佇列與 CAS 的併發深水區。
如果只准你用兩個堆疊,你能拼出一個佇列嗎?
這是一道看似刁鑽的面試題,卻藏著資料結構最迷人的祕密:用後進先出(LIFO)的零件,組裝出先進先出(FIFO)的行為。直覺上這像是要求你用兩面只能反射的鏡子拼出一台正立成像的相機——明明每一片都「反向」,組合起來卻能「正向」。
更耐人尋味的是,這個拼裝出來的佇列,單次操作在最壞情況下可能是 $O(n)$,但如果你把一長串操作攤平來算,平均每次仍然只要 $O(1)$。這個「最壞很慢、平均卻很快」的張力,正是攤還分析(amortized analysis)要回答的核心問題。
入門篇談過 push/pop、enqueue/dequeue 的基本規則,也提過環狀佇列與單調堆疊的名字。這一篇我們不再重述那些定義,而是直接走進三個更深的房間:兩個堆疊組裝佇列的攤還魔法、單調堆疊與單調佇列如何把暴力 $O(n^2)$ 壓到 $O(n)$,以及併發環境下佇列為什麼是工程惡夢。
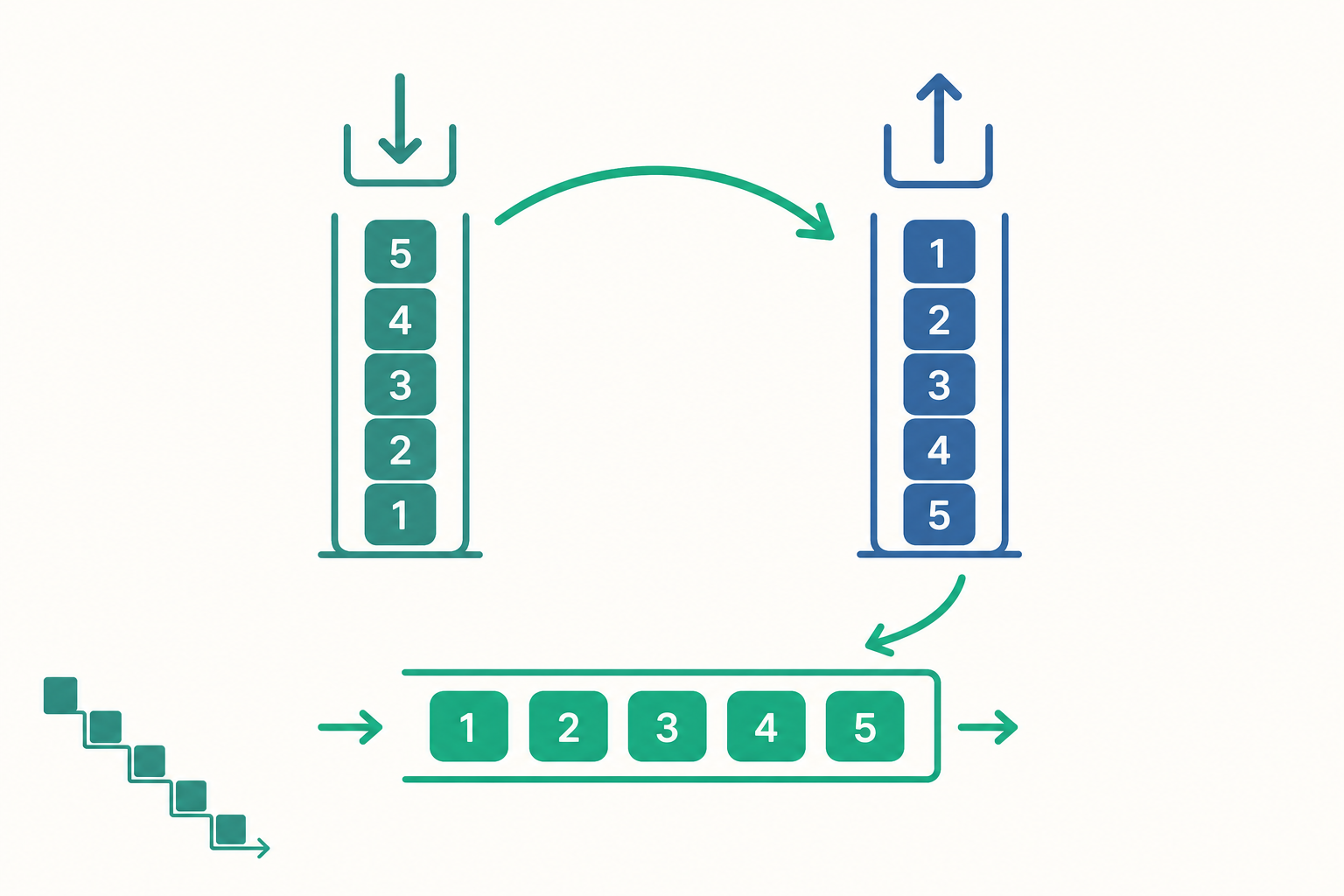
兩個堆疊拼出一個佇列:攤還的魔法
想法其實樸素得驚人。準備兩個堆疊,一個叫 in(負責收件),一個叫 out(負責出貨)。
- enqueue:一律 push 到
in。 - dequeue:如果
out是空的,就把in裡的所有元素整批倒進out;倒完之後,從out的頂端 pop。
關鍵在那個「整批倒」的動作。把 in 從頂端一個個 pop 出來、再 push 進 out,恰好把順序反轉了一次。in 是 LIFO,倒進 out 又被 LIFO 反轉一次——反轉兩次等於不變,於是最早進來的元素,反而跑到了 out 的頂端,先被取出。兩個 LIFO 串接,神奇地合成了一個 FIFO。
class QueueFromStacks:
"""用兩個堆疊實作的佇列"""
def __init__(self):
self._in = [] # 收件堆疊
self._out = [] # 出貨堆疊
def enqueue(self, x):
self._in.append(x) # 一律推入 in
def _transfer(self):
if not self._out: # 只在 out 空時才整批搬移
while self._in:
self._out.append(self._in.pop())
def dequeue(self):
self._transfer()
if not self._out:
raise IndexError("dequeue from empty queue")
return self._out.pop() # 從 out 頂端取出 = 最早進來的
動手算一下:為什麼平均是 $O(1)$?
乍看之下 _transfer 很可怕:如果 in 裡堆了 $n$ 個元素,那一次 dequeue 就要做 $n$ 次搬移,是 $O(n)$。如果有人惡意地「先塞滿、再一個個取」,是不是會慢得要命?
答案是不會,而且我們可以用勢能法(potential method) 嚴格證明。定義系統的「勢能」為 in 堆疊目前的元素個數:
$$\Phi = |\text{in}|$$
攤還成本的定義是:
$$\hat{c}_i = c_i + \Phi_i - \Phi_{i-1}$$
其中 $c_i$ 是第 $i$ 個操作的實際成本,$\Phi_i$ 是操作後的勢能。我們逐一檢查:
- enqueue:實際做 1 次 push($c_i = 1$),同時
in多了一個元素,勢能上升 1。攤還成本 $\hat{c}_i = 1 + 1 = 2 = O(1)$。 - dequeue(out 非空):直接 pop,$c_i = 1$,勢能不變。攤還成本 $\hat{c}_i = 1 = O(1)$。
- dequeue(out 為空,需搬 $k$ 個):實際成本是 $k$ 次 pop 加 $k$ 次 push 再加最後 1 次 pop,約 $2k + 1$。但搬移把
in清空,勢能從 $k$ 降到 $0$,變化量是 $-k$。攤還成本 $\hat{c}_i = (2k+1) + (0 - k) = k + 1$。
最後那個還是 $O(k)$?別急。注意:那 $k$ 個元素當初每一個 enqueue 時,我們都「預付」了 2 單位(一單位給當下的 push,一單位存進勢能銀行)。搬移時花掉的,正是它們先前存進去的存款。把整串操作攤平來看,每個元素一生中最多被 push 兩次、pop 兩次(一次進 in、一次倒進 out),總共 4 次操作,與它被搬移幾次無關。所以 $m$ 次操作的總成本是 $O(m)$,每次操作攤還 $O(1)$。
這就是攤還分析的精髓:不看單次最壞,而看一整串操作的平均。記帳法(accounting method)的直覺更生動——enqueue 時多收一點「手續費」存起來,等到 expensive 的搬移發生時,帳上早有餘額可付。
單調堆疊:把 $O(n^2)$ 壓成 $O(n)$
入門篇提過「單調堆疊」這個名字,但它真正的威力要看一個具體問題才感受得到。
問題(每日溫度):給一串每日氣溫 [73, 74, 75, 71, 69, 72, 76, 73],對每一天,求出「還要等幾天才會遇到更高的溫度」。沒有更高溫的那天答案是 0。
暴力解是對每一天往後掃,最壞 $O(n^2)$。單調堆疊能在 $O(n)$ 解決,核心洞見是:當第 $j$ 天的溫度,足以當成某些較早日子的「答案」時,那些日子就再也用不到了,可以一次清掉。
我們維護一個堆疊,存的是「還在等待更高溫」的日子索引,而且堆疊由底到頂對應的溫度遞減(這就是「單調」)。每來新的一天,就把堆疊頂端所有「比今天低」的日子彈出——對它們而言,今天就是答案。
def daily_temperatures(temps):
"""回傳每天還要等幾天才會更暖;單調遞減堆疊"""
n = len(temps)
answer = [0] * n
stack = [] # 存索引,對應溫度由底到頂遞減
for i, t in enumerate(temps):
while stack and temps[stack[-1]] < t:
j = stack.pop() # 第 j 天的答案找到了
answer[j] = i - j # 等了 i - j 天
stack.append(i)
return answer
看一個例子:逐步追蹤堆疊
用 [73, 74, 75, 71, 69, 72, 76, 73] 走一遍(索引由 0 起算):
| i | 溫度 | 進迴圈前堆疊(索引) | 動作 | 填入的答案 |
|---|---|---|---|---|
| 0 | 73 | [] |
push 0 | — |
| 1 | 74 | [0] |
74>73 彈出 0(ans[0]=1),push 1 | ans[0]=1 |
| 2 | 75 | [1] |
75>74 彈出 1(ans[1]=1),push 2 | ans[1]=1 |
| 3 | 71 | [2] |
71<75,直接 push 3 | — |
| 4 | 69 | [2,3] |
69<71,直接 push 4 | — |
| 5 | 72 | [2,3,4] |
72>69 彈 4(ans[4]=1)、72>71 彈 3(ans[3]=2),push 5 | ans[4]=1, ans[3]=2 |
| 6 | 76 | [2,5] |
76>72 彈 5(ans[5]=1)、76>75 彈 2(ans[2]=4),push 6 | ans[5]=1, ans[2]=4 |
| 7 | 73 | [6] |
73<76,直接 push 7 | — |
結果:[1, 1, 4, 2, 1, 1, 0, 0]。第 6 天溫度最高,沒有更暖的後續,答案是 0;最後一天也是 0。
為什麼是 $O(n)$?關鍵在於:每個索引一生只會被 push 一次、pop 至多一次。雖然內層 while 看起來像第二層迴圈,但所有 while 迴圈的彈出次數加總起來,最多就是 $n$ 次(因為總共只有 $n$ 個元素可以被彈)。內外迴圈的總工作量是 $2n$,因此整體 $O(n)$。這種「內層迴圈總次數受全域上限約束」的論證,本身就是攤還分析的另一個面孔。
單調佇列:滑動視窗最大值
把單調性放到「佇列」上,能解另一類經典問題。
問題(滑動視窗最大值):給陣列與視窗大小 $k$,視窗從左滑到右,每個位置輸出視窗內的最大值。
暴力對每個視窗重新掃描是 $O(nk)$。我們改用一個雙端佇列(deque),但裡面存的不是所有元素,而是「有可能在未來成為最大值的候選人索引」,並維持它們對應的值由前到後遞減。
兩個淘汰規則:
- 過期淘汰:佇列前端的索引若已滑出視窗左界,從前端踢掉。
- 被壓制淘汰:新元素若比佇列尾端的候選人大,那些較小的候選人永遠不可能再當最大值(新人又大又年輕),從尾端一路踢掉。
於是佇列前端永遠是當前視窗的最大值。
from collections import deque
def max_sliding_window(nums, k):
"""單調遞減雙端佇列;每個元素進出各一次,O(n)"""
dq = deque() # 存索引,對應值由前到後遞減
result = []
for i, x in enumerate(nums):
if dq and dq[0] <= i - k: # 規則1:前端過期
dq.popleft()
while dq and nums[dq[-1]] <= x: # 規則2:尾端被壓制
dq.pop()
dq.append(i)
if i >= k - 1: # 視窗成形後開始輸出
result.append(nums[dq[0]]) # 前端即最大值
return result
每個索引最多入列一次、出列一次,所以仍是 $O(n)$。注意這裡同時用到了「從前端踢過期」與「從尾端踢被壓制」——這正是雙端佇列(deque)身為「堆疊與佇列超集」的價值:它能同時扮演兩種角色。
併發的佇列:當多個執行緒同時搶著出列
到目前為止我們都假設只有一條執行緒在操作。一旦進入多核心、多執行緒的世界,佇列就從一個甜美的練習題,變成系統工程裡最棘手的問題之一。
想像生產者—消費者(producer–consumer)模型:若干執行緒往佇列塞資料,若干執行緒搶著取資料。如果兩個消費者同時讀到「前端是 X」、又同時各自把它 dequeue,就會發生競爭條件(race condition)——同一筆資料被消費兩次,或佇列指標被改壞。
最直接的解法是上一把鎖(lock):任何操作前先取得鎖,操作完釋放。簡單,但鎖會成為瓶頸——所有執行緒被迫排隊等鎖,併發優勢蕩然無存。
import threading
from collections import deque
class LockedQueue:
"""以互斥鎖保護的執行緒安全佇列"""
def __init__(self):
self._dq = deque()
self._lock = threading.Lock()
def enqueue(self, x):
with self._lock: # 同一時間只有一個執行緒能進入
self._dq.append(x)
def dequeue(self):
with self._lock:
return self._dq.popleft() if self._dq else None
更進階的目標是無鎖佇列(lock-free queue),它不使用作業系統的鎖,而是靠一個硬體原子指令——比較並交換(Compare-And-Swap, CAS)。CAS 的語意是:「只有當這個記憶體位置現在還等於我預期的舊值,才把它換成新值,並回報成功;否則什麼都不做,回報失敗。」這是一個不可被打斷的原子動作。
著名的 Michael–Scott 佇列就用 CAS 來更新 tail 與 head 指標:執行緒先讀目前指標,算好新指標,再用 CAS 嘗試寫入;若失敗代表有別人搶先改動,就重讀重試。沒有人會被「鎖」住,整體吞吐量在高併發下遠勝鎖式佇列。
代價是巨大的複雜度。無鎖演算法要面對惡名昭彰的 ABA 問題:執行緒讀到指標值是 A,正準備 CAS,期間別的執行緒把它改成 B 又改回 A——CAS 看到「還是 A」便誤判沒人動過,實則底層結構早已改變。解法通常是替指標附加一個版本號(version tag),讓 CAS 連版本一起比對,A 與「改回來的 A」因版本不同而被識破。
這裡要傳達的觀念是:在單執行緒下,佇列是 $O(1)$ 的優雅小品;在併發下,正確性、無鎖、無飢餓(starvation)、ABA、記憶體回收彼此糾纏,是整個研究領域。 我們日常用的訊息佇列(message queue)、執行緒池的工作佇列、GPU 的指令佇列,背後都站著這些艱深的併發演算法。
重點回顧
- 兩個堆疊可以組裝出一個佇列:
in收件、out出貨,倒一次反轉、被取時再反轉,雙重反轉合成 FIFO。 - 它的單次 dequeue 最壞 $O(n)$,但用勢能法(勢能 =
in大小)可證每次操作攤還 $O(1)$——每個元素一生只被搬移常數次。 - 單調堆疊把「下一個更大元素/每日溫度」類問題從 $O(n^2)$ 壓到 $O(n)$,靠的是「每個元素只進出堆疊一次」的攤還上限。
- 單調佇列(雙端佇列)用「過期淘汰 + 被壓制淘汰」解滑動視窗最大值,仍是 $O(n)$,展現 deque 同時當堆疊與佇列的彈性。
- 併發佇列從鎖式走到無鎖(CAS),要對付競爭條件與 ABA 問題,是系統工程的硬核議題,不再是純粹的 $O(1)$ 練習。
深入探討(研究所視角)
攤還的三種記帳法與其等價性
攤還分析有三套方法:聚合法(aggregate)、記帳法(accounting)、勢能法(potential)。聚合法直接算「$m$ 次操作總成本除以 $m$」;記帳法給每個操作分配一個攤還費用,多收的存起來、不足的提領;勢能法引入一個定義在資料結構狀態上的勢能函數 $\Phi$,把「儲蓄」隱含進結構的當前形態。三者在數學上可證等價,但勢能法最適合複雜結構——只要找到一個合適的 $\Phi$,就能把「未來會省下的工作」量化成當下的位能。動態陣列擴容、斐波那契堆(Fibonacci heap)、splay tree 的分析都倚賴它。值得強調的是:攤還 $O(1)$ 是對「操作序列」的保證,不是對「單次操作」的保證——這對即時系統(real-time system)很要命,因為某一次操作仍可能突然 $O(n)$,造成不可接受的延遲尖峰。
即時佇列與持久化:函數式世界的優雅解
前述兩堆疊佇列在純函數式(purely functional)語言裡有個著名變體。函數式資料結構強調持久性(persistence):修改後舊版本仍然存在、可被存取,這讓樸素的攤還論證失效——因為攻擊者可以反覆對「同一個 expensive 的版本」操作,把預付的存款重複提領,攤還保證就崩潰了。
解法是 Chris Okasaki 在《Purely Functional Data Structures》中提出的惰性求值(lazy evaluation) + memoization:用 Stream 取代堆疊,把昂貴的反轉拆成一連串被延遲的計算,並透過 memo 確保「同一份昂貴計算只會真正執行一次」,即使被多個版本共享。進一步用排程(scheduling) 強制每步操作只推進固定份量的惰性計算,就能把攤還 $O(1)$ 升級為最壞情況 $O(1)$ 的即時佇列(real-time queue)——既持久、又對單次操作有硬性時間保證。這是資料結構理論裡極漂亮的一塊:透過惰性與排程,把「平均很快」鍛造成「每次都很快」。
從堆疊到計算模型的深層連結
最後回到理論的高度。堆疊不只是工具,它定義了一整層計算能力:下推自動機(pushdown automaton) = 有限狀態機 + 一個堆疊,其辨識能力恰好等於上下文無關語言(context-free language);若給它兩個堆疊,計算能力立刻躍升到與圖靈機(Turing machine) 等價——因為兩個堆疊頂對頂,正好能模擬一條可雙向讀寫的紙帶。這與我們開頭「兩個堆疊拼一個佇列」遙相呼應:堆疊的數量,竟直接決定了一個抽象機器站在喬姆斯基層級(Chomsky hierarchy)的哪一階。從一疊盤子的後進先出,一路通向可計算性的邊界——這正是基礎資料結構最深邃的浪漫。