
馮諾伊曼架構進階:把瓶頸算出來,並從微架構看現代 CPU 如何「優雅地等待記憶體」
從 CPI 效能方程式、三個 C 的快取未命中、TLB 與虛擬記憶體,到分支預測、亂序執行與屋頂線模型——量化並對抗馮諾伊曼瓶頸
如果 CPU 快 100 倍,你的程式會快 100 倍嗎?
你已經知道馮諾伊曼瓶頸(von Neumann bottleneck)的存在,也知道快取(cache)與管線(pipeline)能「藏住」它。但這裡有一個更尖銳的問題:假設明天有人給你一顆時脈快 100 倍的 CPU,把它裝進你的電腦,你那支跑大型矩陣運算的程式,真的會快 100 倍嗎?
答案幾乎總是「不會」。多數情況下,你可能只快了 1.5 倍,甚至毫無感覺。原因不在 CPU,而在 CPU 與記憶體之間那條我們已經認識的走廊——只是這一次,我們要把它算出來。入門篇告訴你瓶頸「在哪裡」;這一篇要教你量化它、預測它、並從架構層面理解工程師如何與它正面交鋒。我們會用具體數字推導出一台機器真正的效能極限,並拆解現代 CPU 在「看不見的地方」到底玩了哪些把戲。
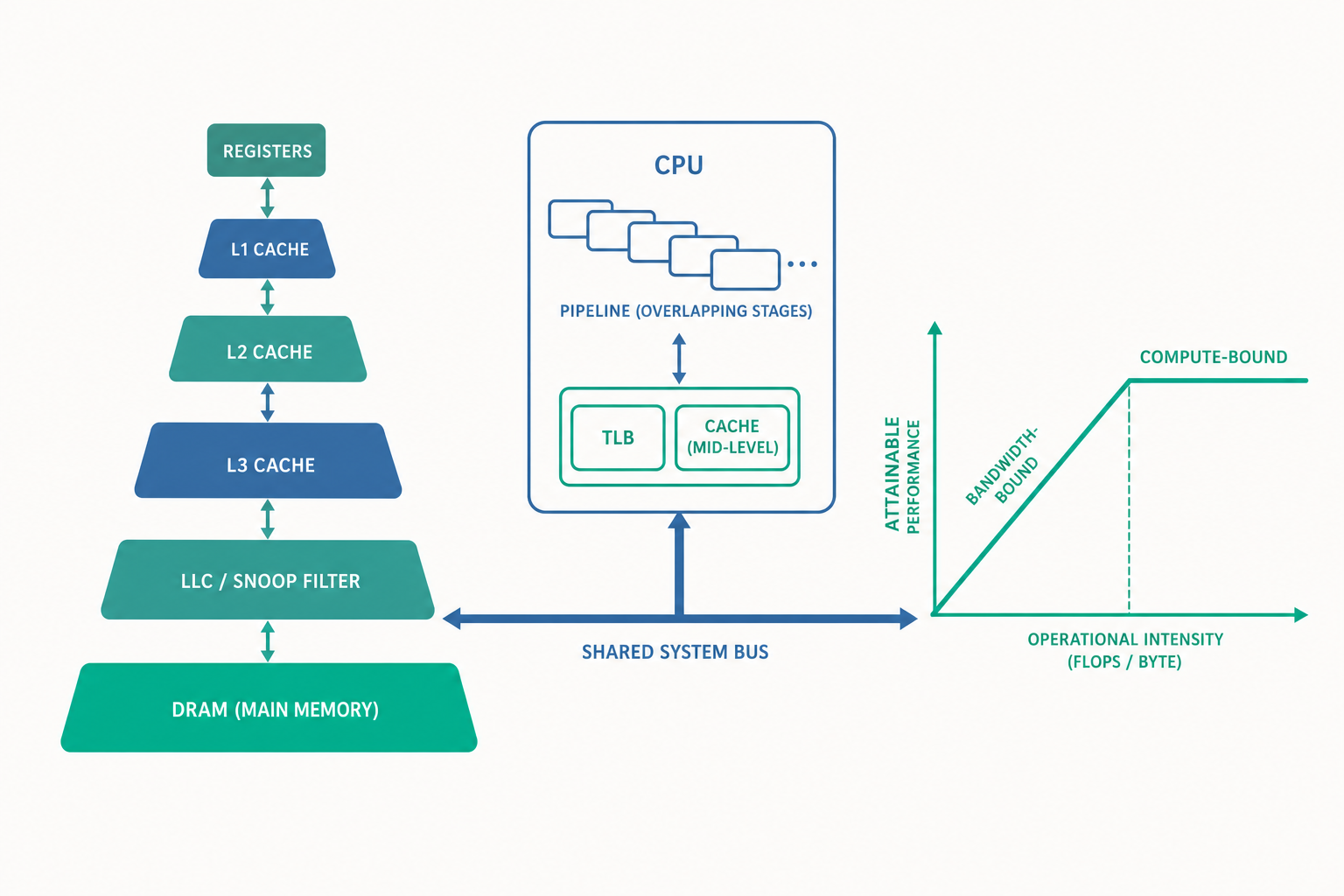
效能的真相方程式:CPI、時脈與記憶體延遲
要量化效能,我們需要一條核心公式。一個程式的執行時間可以拆解成三個因子:
$$\text{執行時間} = \text{指令數}(IC) \times \text{每指令週期數}(CPI) \times \text{時脈週期時間}(T_c)$$
其中 $CPI$(Cycles Per Instruction)是關鍵。在理想的管線中,$CPI$ 趨近於 1(每週期完成一條指令)。但記憶體存取會狠狠地把它拉高。我們可以把實際 $CPI$ 寫成:
$$CPI_{\text{實際}} = CPI_{\text{理想}} + (\text{每指令的記憶體存取次數} \times \text{未命中率} \times \text{未命中代價})$$
這條公式把抽象的「瓶頸」變成可計算的數字。最後一項就是馮諾伊曼瓶頸的量化身影——它不會出現在指令數裡,卻悄悄地吃掉你的週期。
動手算一下:記憶體牆有多高?
假設一台機器的參數如下:
CPI 理想值 = 1.0
時脈 = 4 GHz → 每週期 0.25 奈秒(ns)
L1 未命中代價 = 100 週期(要跑去主記憶體 DRAM 拿)
每條指令平均
發出記憶體存取 = 1.3 次(含取指本身 + 部分指令存取資料)
L1 未命中率 = 2%
代入公式:
記憶體造成的額外 CPI = 1.3 × 0.02 × 100
= 2.6 週期
CPI 實際 = 1.0 + 2.6 = 3.6
看清楚這件事的嚴重性了嗎?理想 $CPI$ 是 1.0,但光是 2% 的未命中率,就讓實際 $CPI$ 暴增到 3.6——也就是說,這顆 CPU 有將近 $\frac{2.6}{3.6} \approx 72\%$ 的時間,是在乾等記憶體。
現在回到開頭的問題。如果我們把 CPU 時脈加快 100 倍($T_c$ 縮小 100 倍),但記憶體速度不變,那 100 週期的未命中代價會變成 10000 個「新的、更短的」週期。瓶頸的相對佔比不減反增。這正是記憶體牆(memory wall) 在數學上的真面目:單純加快 CPU,只會讓它有更多時間發呆。
這也帶出一個貫穿整篇的設計哲學——與其追求更快的核心,不如想方設法降低未命中率或隱藏未命中代價。接下來幾節,就是這場戰爭的兵法。
把快取拆開看:關聯度與「三種未命中」
入門篇把快取當成一個會「命中」或「未命中」的黑盒子。進階的關鍵,是理解快取內部如何決定一筆資料放在哪裡,以及未命中為什麼會發生。
快取以快取行(cache line,通常 64 位元組) 為單位搬運資料——這就是空間區域性能奏效的硬體原因:你只想要 1 個位元組,硬體卻一次搬來鄰近的 64 個。而一筆記憶體位址該對應到快取中的哪一格,由關聯度(associativity) 決定:
| 配置 | 一筆資料能放的位置 | 取捨 |
|---|---|---|
| 直接對映(direct-mapped) | 只有 1 個固定位置 | 查找快、但容易互相踢出 |
| 全關聯(fully associative) | 任何位置 | 命中率高、但查找硬體昂貴 |
| N 路組關聯(N-way set associative) | 一個組內的 N 個位置 | 折衷,現代主流(常見 8 路) |
理解了結構,就能解釋未命中的來源。經典的分析把快取未命中分成 「三個 C」(the three Cs):
- 強制未命中(Compulsory):資料第一次被存取,快取裡本來就不可能有。又稱冷啟動未命中。
- 容量未命中(Capacity):工作集(working set)比整個快取還大,舊資料被擠出去後又要用。
- 衝突未命中(Conflict):因為關聯度不足,多筆資料搶同一組位置而互相踢出——即使快取整體還有空間。
這個分類不是學術裝飾,它直接指導你怎麼最佳化程式:強制未命中靠預取(prefetch) 減輕;容量未命中靠縮小工作集(例如分塊運算);衝突未命中則對資料的記憶體佈局極度敏感。下面這個例子會讓你親眼看到衝突未命中如何毀掉一支「演算法完全正確」的程式。
看一個例子:同樣的迴圈,10 倍的速度差
考慮一個再普通不過的二維陣列加總,比較「逐列(row-major)」與「逐行(column-major)」兩種走訪順序:
// 版本 A:逐列存取(順著記憶體擺放方向)
long sum = 0;
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
sum += a[i][j]; // 記憶體位址連續遞增
// 版本 B:逐行存取(垂直跳躍)
long sum = 0;
for (int j = 0; j < N; j++)
for (int i = 0; i < N; i++)
sum += a[i][j]; // 每次跳 N 個元素
兩個版本計算結果完全相同、指令數也幾乎一樣。但在 C 語言這類 row-major(橫列優先)儲存的語言中,版本 A 順著記憶體連續前進,每搬一條 64 位元組的快取行,就能餵飽接下來好幾次存取(高空間區域性)。版本 B 每一步跳躍 $N$ 個元素,當 $N$ 夠大時,每一次存取都落在不同的快取行上,幾乎次次未命中。
我們套用上一節的公式估算(假設每元素 8 位元組、快取行 64 位元組,故一行裝 8 個元素):
版本 A 未命中率 ≈ 1/8 = 12.5%(每 8 次存取才換一行)
版本 B 未命中率 ≈ 100%(每次都換行)
若未命中代價 100 週期、命中 1 週期:
版本 A 平均存取週期 ≈ 0.875×1 + 0.125×100 ≈ 13.4 週期
版本 B 平均存取週期 ≈ 0.0 ×1 + 1.0 ×100 ≈ 100 週期
理論上約 7 倍差距,實測常因 TLB 未命中(後面會談)與預取失效而放大到 10 倍以上。這就是著名的快取記憶體(cache-aware) 程式設計:演算法的時間複雜度 $O(N^2)$ 沒變,但常數因子被記憶體階層放大了一個數量級。馮諾伊曼瓶頸從不在你的大 O 分析裡,卻活生生決定你的程式跑得多快。
寫入這條路:為什麼「存資料」比你想的複雜
讀取的快取邏輯相對直覺,寫入(write) 卻藏著馮諾伊曼架構一個微妙的設計分岔。當 CPU 要改寫一個值,這個新值該何時、如何傳回主記憶體?有兩種策略:
寫穿(write-through):
每次寫入,同時更新快取與主記憶體。
→ 簡單、記憶體永遠最新;但每次寫都吃匯流排頻寬。
寫回(write-back):
只先更新快取,並把該行標記為「髒(dirty)」。
等這行要被踢出時,才一次寫回主記憶體。
→ 大幅減少匯流排流量;但記憶體會暫時「過期」。
現代 CPU 幾乎都用寫回,因為它直接攻擊馮諾伊曼瓶頸的痛點:減少對共用匯流排的存取次數。為了讓寫回不至於卡住 CPU,硬體還會加上寫入緩衝區(write buffer)——CPU 把要寫的資料丟進緩衝區就繼續跑,不必等真正寫完。
但這裡埋著一個深水炸彈:一旦進入多核心、且採用寫回 + 寫入緩衝,記憶體裡的值就可能「暫時是舊的」,而不同核心對「事情發生的順序」可能看法不一。這正是記憶體一致性(memory consistency) 問題的物理起源,我們留到最後的研究所視角細談。先記住一個重要觀念:寫回快取讓馮諾伊曼那塊「單一、權威的記憶體」變成了一種假象——真相分散在各層快取與緩衝區裡。
虛擬記憶體:在馮諾伊曼位址空間上再疊一層
馮諾伊曼模型假設有一塊以位址編號的線性記憶體。但你寫程式時用的位址(虛擬位址,virtual address),其實不是真正的實體記憶體位址(實體位址,physical address)。中間隔著作業系統與硬體合作的虛擬記憶體(virtual memory) 機制,它做了兩件對馮諾伊曼架構至關重要的事:
- 保護與隔離:每個程序有自己的虛擬位址空間,彼此踩不到對方的記憶體——這修補了「指令與資料同處一塊記憶體」帶來的安全風險。
- 以分頁表(page table) 把虛擬位址翻譯成實體位址,讓記憶體看起來比實體更大。
問題是:每存取一個位址,都得先查分頁表做翻譯——而分頁表本身也在記憶體裡。這等於每次存取記憶體前,要先多一次(甚至多次)存取記憶體,馮諾伊曼瓶頸被乘上了好幾倍!
硬體的解法是一塊專門快取「位址翻譯結果」的小快取:TLB(Translation Lookaside Buffer,轉譯後備緩衝區)。
CPU 發出虛擬位址
│
▼
查 TLB ──命中──▶ 立刻得到實體位址(快)
│
未命中
│
▼
走分頁表(page walk):可能存取記憶體數次才翻譯出來(慢)
│
▼
把結果填回 TLB,下次就快了
這就解釋了上一節版本 B 的額外懲罰:大跨步的跳躍存取不只打爆資料快取,連 TLB 也跟著未命中,因為每跳一步可能就跨到另一個記憶體分頁。現代效能分析必須把資料快取與 TLB 兩個層次一起看,它們是疊在同一條馮諾伊曼匯流排上的兩道關卡。
管線深處:當 CPU 開始「賭」與「並行」
入門篇提到管線會遇到危障(hazard),現代 CPU 用分支預測與亂序執行來填滿管線。進階的重點是理解這些技術為什麼本質上是在對抗馮諾伊曼瓶頸——它們的共同目標,是讓 CPU 在等待記憶體或前一條指令結果的同時,找別的事做。
分支預測(branch prediction):管線需要連續餵入指令,但遇到 if 分支時,CPU 還不知道該走哪條路(因為條件可能要等記憶體把資料送來才知道)。與其空等,CPU 乾脆賭一把,猜一個方向先做下去。猜對了,零成本賺到;猜錯了,把錯誤路徑上做的工作全部丟棄(稱為flush),代價是十幾個週期。現代預測器準確率可超過 95%。
亂序執行(out-of-order execution):考慮這段程式:
指令1: LOAD R1, [X] ; 假設 X 不在快取,要等 100 週期
指令2: ADD R2, R3, R4 ; 跟 R1 完全無關
指令3: MUL R5, R1, R6 ; 需要 R1,必須等指令1
循序執行的 CPU 會卡在指令 1,連帶讓無辜的指令 2 一起空等。亂序 CPU 則會說:「指令 2 跟誰都沒衝突,那我趁等待 R1 的空檔,先把指令 2 做了。」這就是用指令層級平行(Instruction-Level Parallelism, ILP) 來隱藏記憶體延遲。
而當單一執行緒的 ILP 也被榨乾、CPU 還是在等記憶體時,同步多執行緒(SMT,Intel 稱 Hyper-Threading) 上場:一個核心同時餵入兩個執行緒的指令,A 執行緒卡在記憶體未命中時,B 執行緒的指令正好補上空檔。
請看出貫穿這一切的同一個主旋律:快取減少要走匯流排的次數;亂序、SMT、預取則在不得不走匯流排時,盡量讓 CPU 別閒著。整部現代微架構史,就是一部「如何優雅地等待記憶體」的歷史。
屋頂線模型:你的程式被誰綁住了?
最後,我們用一個能把「馮諾伊曼瓶頸」具象化的分析工具收尾:屋頂線模型(Roofline Model)。它回答一個工程上極實用的問題——你的程式效能上限,是被 CPU 算力綁住,還是被記憶體頻寬綁住?
關鍵指標是運算強度(arithmetic intensity):
$$I = \frac{\text{浮點運算次數(FLOPs)}}{\text{從記憶體搬運的位元組數(Bytes)}}$$
直白地說,$I$ 衡量「每從記憶體搬來 1 個位元組,你能榨出多少運算」。$I$ 低,代表你搬一堆資料卻只算一點點——典型的記憶體頻寬受限(memory-bound),馮諾伊曼瓶頸全面主宰。$I$ 高,代表資料搬來後被反覆運算,CPU 算力才是瓶頸——運算受限(compute-bound)。
可達到的效能上限是兩條線取較低者:
$$\text{效能} = \min(\ \text{峰值算力},\ \ I \times \text{記憶體頻寬}\ )$$
效能(GFLOP/s)
▲
峰值│ ┌──────────── 算力上限(屋頂的平頂)
算力│ ╱
│ ╱ ← 斜坡:頻寬上限 = I × 記憶體頻寬
│ ╱
│ ╱
└───────┴──────────────▶ 運算強度 I
轉折點
◀記憶體受限┊運算受限▶
斜坡區(左側)的程式,再快的 CPU 也救不了,唯一出路是提高 $I$——例如用分塊(blocking/tiling)讓搬進快取的資料被多次重用,把點落到圖的右邊。這就把前面所有概念串了起來:降低未命中、提升運算強度、本質上都是在減少對那條共用匯流排的依賴。屋頂線模型,等於是馮諾伊曼瓶頸的「健檢報告」。
重點回顧
- 效能由 $\text{執行時間} = IC \times CPI \times T_c$ 決定,而記憶體未命中會悄悄推高 $CPI$;只加快 CPU 時脈,反而讓記憶體延遲的相對佔比更大——這是記憶體牆的數學本質。
- 快取未命中分為強制、容量、衝突三個 C,分別對應預取、縮小工作集、調整記憶體佈局等不同最佳化手段。
- 寫回快取 + 寫入緩衝為了減少匯流排流量,讓「單一權威記憶體」成為假象,並埋下多核一致性問題。
- 虛擬記憶體在馮諾伊曼位址空間上疊加位址翻譯,靠 TLB 緩解;效能分析必須同時看資料快取與 TLB。
- 分支預測、亂序執行、SMT、屋頂線模型的共同主軸,都是「如何在等待記憶體時讓 CPU 不閒著」與「如何減少對共用匯流排的依賴」。
深入探討(研究所視角)
記憶體一致性模型的形式化。 前面提到寫回快取讓記憶體值「暫時過期」。在多核系統中,這引出一個深刻問題:當多個核心並行讀寫共享變數時,硬體保證它們看到怎樣的存取順序?最直覺的循序一致性(Sequential Consistency, SC) 要求所有核心看到的全域順序一致,但代價高昂。實務上 x86 採用較寬鬆的 TSO(Total Store Order),允許「寫入緩衝區」造成 store 延後可見;ARM、RISC-V 則更寬鬆。這意味著沒有 memory barrier(記憶體屏障)或 atomic 操作時,一段在你腦中「顯然正確」的並行程式,可能因硬體重排而出錯。C++11、Java 的記憶體模型,正是為了讓程式設計師能在這些寬鬆硬體上,以 happens-before 關係推理正確性——這是並行程式設計的理論基石,建議延伸閱讀 Adve 與 Gharachorloo 的經典綜述。
快取與時序側通道(side channel)。 馮諾伊曼架構為了效能引入的快取,無意間洩漏了資訊:存取一筆資料的「時間長短」會暴露它是否在快取裡。Spectre 與 Meltdown(2018) 攻擊正是利用「推測執行(speculative execution)」——CPU 賭錯分支後,雖然丟棄了架構狀態,卻在快取裡留下了痕跡,攻擊者用計時測量這些痕跡,竊取了本不該存取的記憶體。這揭示一個深刻的教訓:微架構的最佳化(推測、亂序、快取)並非對軟體完全透明,效能與安全在馮諾伊曼模型的底層緊密糾纏。理解這層機制,目的在於設計具備隔離保證的安全系統與正確的緩解措施。
對馮諾伊曼典範的根本性挑戰。 當資料量遠超運算量(如大型語言模型推論、圖計算),把資料「一個字一個字搬過匯流排」的成本主導一切。這催生了繞過馮諾伊曼瓶頸的架構研究:近記憶體運算(near-memory computing) 與記憶體內運算(processing-in-memory, PIM) 把運算單元搬進記憶體晶片,從物理上消滅那條走廊;資料流架構(dataflow architecture) 與張量處理器(如 TPU 的脈動陣列 systolic array)則讓資料在運算單元間直接流動、最大化重用,盡量不回主記憶體。這些方向都可視為對「儲存程式 + 單一匯流排」這組八十年前假設的鬆綁。值得思考的開放問題是:當運算的形狀由 AI 工作負載重新定義,馮諾伊曼這張藍圖會被取代,還是會再一次以「改良式」之姿存活下來?歷史上它每次被宣告過時,都以更精巧的混血形式回歸——這本身,或許就是它最深刻的設計遺產。