
資料的數位表示
從位元與位元組出發,理解整數的二補數、浮點數 IEEE 754 的尾數與指數結構,以及為什麼 0.1 + 0.2 永遠不等於 0.3
為什麼計算機算不出 0.1 + 0.2 = 0.3
打開任何一個程式語言的互動環境,輸入 0.1 + 0.2,你會得到一個令人困惑的答案:
>>> 0.1 + 0.2
0.30000000000000004
這不是程式語言的 bug,也不是你的電腦壞了。世界上幾乎每一台電腦、每一支手機、每一個科學計算器,在這道題目上都會給出同樣「錯誤」的結果。要理解為什麼,我們得回到最根本的問題:當資料進入計算機,它究竟長什麼樣子?文字、整數、小數、圖片、聲音——這些在我們眼中如此不同的東西,最終都要被翻譯成同一種語言:一連串的 0 與 1。這個翻譯的規則,就是「資料的數位表示」。
一切的起點:位元與位元組
計算機的最小資訊單位是位元(bit),它只有兩個可能的狀態:0 或 1。為什麼是二進位而非我們熟悉的十進位?原因很實際:電子電路最容易、最可靠地分辨的就是「有電壓」與「沒電壓」兩種狀態。用兩個離散狀態來編碼資訊,抗雜訊能力遠勝於試圖區分十個不同的電壓位階。
單一位元能表達的資訊太少,因此我們把 8 個位元綁成一組,稱為一個位元組(byte)。一個位元組有 $2^8 = 256$ 種不同的組合,可以表示 0 到 255 的整數,或對應到一個字元(早期 ASCII 編碼正是如此)。
關鍵的觀念是:位元本身沒有意義,意義來自我們約定的「解讀方式」。 同一串位元 01000001,如果約定它是無號整數,就是 65;如果約定它是 ASCII 字元,就是大寫字母 A;如果約定它是某種旗標集合,又是另一回事。資料表示的核心,其實是「人與機器之間的約定」。
動手看一個例子:二進位與十進位的換算
我們用每個位元代表的「權重」來理解二進位數字。以 8 位元的 01000001 為例:
位元位置: 7 6 5 4 3 2 1 0
位元值: 0 1 0 0 0 0 0 1
權重: 128 64 32 16 8 4 2 1
貢獻: 0 +64 + 0 + 0 + 0 + 0 + 0 +1 = 65
每往左一位,權重就乘以 2。這和十進位每往左一位乘以 10 是同樣的道理,只是底數從 10 換成了 2。一個 $n$ 位元的無號整數,能表示的範圍是 $0$ 到 $2^n - 1$。
整數:有號與無號的取捨
如果我們只需要表示非負整數(如年齡、計數),直接用上述方式就好,稱為無號整數(unsigned integer)。但真實世界有負數:溫度、帳戶餘額、座標差。我們需要一種方式在位元裡塞進「正負號」。
最直覺的想法是拿最高位當符號位(0 為正、1 為負),這叫原碼(sign-magnitude)。但它有兩個惱人的問題:第一,會出現 +0 和 -0 兩個零;第二,加法電路必須先判斷符號再決定加還是減,硬體變複雜。
現代計算機普遍採用二補數(two's complement)。它的規則很簡潔:要表示一個負數 $-x$,就取 $x$ 的位元表示後「逐位取反再加 1」。它的精妙之處在於:
- 零只有一種表示(沒有
-0的困擾)。 - 加減法可以用同一套電路完成,不需要特別處理符號。
- 最高位仍可視為符號位,但它的權重是「負的」。
動手看一個例子:用二補數表示 −5
以 8 位元為例,先寫出 5 的二進位,再做二補數運算:
5 的二進位: 0000 0101
逐位取反: 1111 1010
加 1: 1111 1011 ← 這就是 -5
驗證一下:在二補數中,最高位的權重是 $-128$,其餘照常。
$$-128 + 64 + 32 + 16 + 8 + 0 + 2 + 1 = -5$$
確實是 $-5$。一個 $n$ 位元的二補數整數,表示範圍是 $-2^{n-1}$ 到 $2^{n-1} - 1$。注意這個範圍不對稱:負數比正數多一個,因為零佔用了正數那側的一個位置。這也是為什麼 8 位元有號整數的範圍是 $-128$ 到 $+127$,而不是 $-127$ 到 $+127$。
理解二補數還能幫你避開一個常見陷阱:整數溢位(overflow)。當運算結果超出可表示範圍時,數值會「繞回」。例如 8 位元有號整數的 $127 + 1$,在位元層面會變成 1000 0000,也就是 $-128$。許多嚴重的軟體錯誤——從遊戲分數突然變負,到航太系統的災難——都源自未被察覺的整數溢位。
浮點數:在有限位元裡裝下實數
整數很整齊,但世界充滿小數。我們需要一種方法表示 $3.14159$、$6.022 \times 10^{23}$、$0.0000001$ 這類數字。最自然的構想來自科學記號:把任何數寫成「尾數 × 底數的指數次方」。
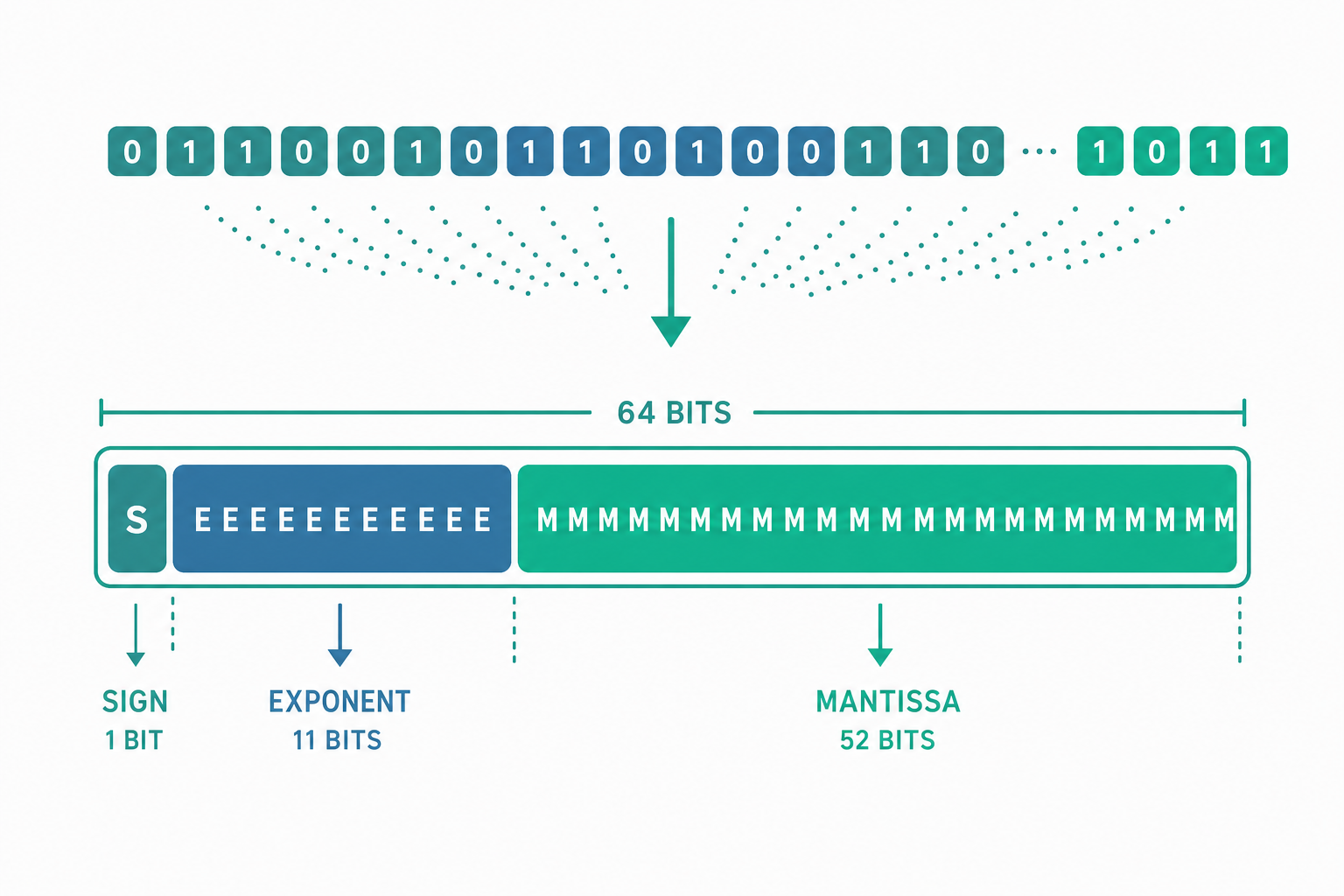
這正是浮點數(floating-point) 的核心思想——之所以叫「浮點」,是因為小數點的位置不固定,而是由指數來決定,像是浮動的。業界統一遵循 IEEE 754 標準。以最常用的雙精度(double, 64 位元)為例,64 個位元被切成三段:
| 欄位 | 位元數 | 作用 |
|---|---|---|
| 符號位 sign | 1 | 0 為正、1 為負 |
| 指數 exponent | 11 | 決定數值的量級(大小) |
| 尾數 mantissa | 52 | 決定數值的精度(有效數字) |
一個正規化的浮點數,其值大致為:
$$(-1)^{\text{sign}} \times 1.\text{mantissa} \times 2^{\text{exponent} - 1023}$$
這裡有兩個值得細看的設計。其一,尾數前面那個 1. 是「隱含位元」——既然正規化後最高位一定是 1,標準就乾脆不存它,省下一個位元換取額外一位精度。其二,指數採「偏移(bias)」表示而非二補數,雙精度的偏移量是 1023,這讓浮點數的位元表示在比大小時可以近似當作整數來比,硬體更好做。
為什麼 0.1 在計算機裡不精確
現在我們可以回答開頭的謎題了。問題的根源在於:二進位的「有限小數」和十進位的「有限小數」並不是同一群數字。
在十進位裡,$0.1$ 是個乾淨俐落的有限小數。但當我們試圖把它寫成二進位的 $\frac{a}{2^k}$ 形式時,會發現辦不到——$0.1$ 在二進位下是個無窮循環小數:
$$0.1_{10} = 0.0001100110011001100110011\ldots_2$$
就像 $\frac{1}{3}$ 在十進位下是無窮的 $0.3333\ldots$ 一樣,$0.1$ 在二進位下也永遠除不盡。由於尾數只有 52 個位元,計算機只能存下這個無窮循環的前一截,然後四捨五入。於是存進去的根本不是 $0.1$,而是一個極度接近、卻略有偏差的數字。
動手看一個例子:看穿被截斷的 0.1
我們可以請 Python 把它「真正存的值」用更多位數印出來:
>>> format(0.1, '.20f')
'0.10000000000000000555'
>>> format(0.2, '.20f')
'0.20000000000000001110'
>>> format(0.3, '.20f')
'0.29999999999999998890'
看出來了嗎?存進去的 0.1 其實是 $0.1000\ldots0555$,比真正的 $0.1$ 大了一點點。當你把這個「略大的 0.1」和「略大的 0.2」相加,誤差累積,結果就成了 $0.30000000000000004$,而它又恰好不等於計算機存的那個「略小的 0.3」。三個微小的捨入誤差湊在一起,造就了那個著名的尾巴。
這給我們一條重要的實務守則:永遠不要用 == 直接比較兩個浮點數是否相等。 正確做法是判斷兩者的差距是否小於一個可接受的微小容差(epsilon):
def almost_equal(a, b, eps=1e-9):
return abs(a - b) < eps
almost_equal(0.1 + 0.2, 0.3) # True
另外,凡是涉及金錢的計算,務必避免用浮點數,改用十進位定點數型別(如 Python 的 decimal.Decimal)或直接以「分」為單位的整數運算,以免微小誤差在大量交易中累積成真金白銀的差錯。
重點回顧
- 位元是最小單位,意義來自約定:同一串 0 與 1,可以是整數、字元或旗標,端看我們如何解讀。8 個位元組成一個位元組。
- 二補數是現代整數表示的主流:它讓零唯一、加減法共用電路,代價是正負範圍不對稱(如 8 位元為 $-128$ 到 $+127$),並需提防整數溢位繞回。
- 浮點數借用科學記號的構想:IEEE 754 把數字拆成符號、指數、尾數三段;指數管量級,尾數管精度,並用隱含位元多賺一位精度。
- 0.1 不精確的本質是進制問題:$0.1$ 在二進位下是無窮循環小數,有限的尾數只能存近似值,捨入誤差累積後造成 $0.1 + 0.2 \neq 0.3$。
- 實務守則:浮點數比較用容差而非
==;金錢計算改用定點數或整數,避免捨入誤差釀成實質損失。
深入探討(研究所視角)
要真正掌握浮點數的精度行為,必須深入 IEEE 754 尾數與指數的交互結構,並引入「機器精度」這個量化工具。
尾數與指數如何共同決定可表示的數。雙精度的尾數有 52 個顯式位元加 1 個隱含位元,共 53 位有效位元。這意味著相鄰兩個可表示浮點數之間的間距,並非固定,而是隨數值量級放大。我們定義機器精度(machine epsilon)為 1 與「大於 1 的下一個可表示數」之間的差距:
$$\varepsilon_{\text{machine}} = 2^{-52} \approx 2.22 \times 10^{-16}$$
對於量級在 $2^e$ 附近的數,相鄰浮點數的間距(稱為 ULP, unit in the last place)約為 $2^{e-52}$。這就是浮點數的精妙與危險所在:它在小數值處密集、大數值處稀疏,能用固定位元覆蓋極寬廣的動態範圍(雙精度約 $10^{-308}$ 到 $10^{308}$),代價是相對精度恆定、絕對精度浮動。
捨入誤差的傳播與災難性抵銷。任何一次浮點運算的相對誤差被界定在 $\frac{1}{2}\varepsilon_{\text{machine}}$ 以內(在「round to nearest, ties to even」模式下),這是 IEEE 754 提供的正確捨入保證。然而誤差會在連續運算中累積。最值得警惕的是災難性抵銷(catastrophic cancellation):當兩個非常接近的數相減,高位有效數字互相抵消,結果的有效位元數驟降,原本被埋在尾數末端的捨入誤差被放大到主導地位。例如求解二次方程式 $ax^2+bx+c=0$ 時,若 $b^2 \gg 4ac$,公式 $\frac{-b+\sqrt{b^2-4ac}}{2a}$ 在 $b>0$ 那一根會發生抵銷,數值分析上需改用有理化後的等價公式來規避。這正是數值分析(numerical analysis)這門學科的核心關懷之一。
特殊值與漸進下溢。IEEE 754 還保留指數欄位的全 0 與全 1 來編碼特殊狀態:指數全 1 配尾數 0 表示無窮大($\pm\infty$),配非零尾數表示 NaN(Not a Number,如 $0/0$ 的結果);指數全 0 則進入非正規化(denormalized/subnormal) 模式,去掉隱含的前導 1,讓浮點數在接近零時能「漸進下溢(gradual underflow)」,填補 0 與最小正規數之間的縫隙,避免精度在零附近突然崩塌。這些設計使浮點運算具備可預測的封閉性——任何運算都有定義良好的結果,不會讓程式陷入未定義行為。
與其他主題的連結。資料表示是計算機科學的地基,它向上連結了多個領域:在計算機結構中,浮點運算單元(FPU)的設計與這套標準緊密耦合;在機器學習中,為了在 GPU 上加速訓練,業界發展出半精度(FP16)乃至 bfloat16、FP8 等更短的格式,刻意犧牲尾數精度換取吞吐量與記憶體頻寬,這背後正是對「指數管範圍、尾數管精度」這條原理的策略性運用——bfloat16 保留與 FP32 相同的 8 位元指數(維持動態範圍以免梯度下溢),卻把尾數砍到 7 位元。理解了本文的尾數/指數結構,你才能讀懂為什麼深度學習工程師願意接受更粗糙的精度,以及他們在何處必須小心捨入誤差的累積。資料如何被表示,從來不只是底層細節,而是貫穿整個計算世界的設計哲學。