
Java 例外處理進階:抑制例外、堆疊回溯與 lambda 的世紀衝突
讀懂 try-with-resources 的內部展開、stack unwinding 的零成本機制,以及為什麼 checked 例外與函數式設計在型別系統層級水火不容
當 close() 和 try 裡的程式碼「同時」出錯,哪一個例外會贏?
你已經知道 try-with-resources 會自動幫你關閉資源。但這裡藏著一個入門篇沒問的尖銳問題:假設 try 區塊本身丟了一個 IOException,而 JVM 在離場時呼叫 close(),close() 自己也丟了一個例外——現在你有兩個例外同時想往外冒,到底哪一個會傳到呼叫端?另一個去哪了?
try (var r = new NoisyResource()) { // close() 會丟 IllegalStateException
throw new IOException("讀取失敗"); // try 主體先丟出
}
直覺上你可能猜「後丟的蓋掉先丟的」,那正是 Java 7 之前手寫 finally { close(); } 的悲劇:close() 的例外會靜默吃掉原本真正的根因,讓你 debug 到天亮。Java 7 為了解決這件事,引進了一個入門課很少細講、卻是現代 Java 例外處理基石的機制——被抑制的例外(suppressed exception)。這篇進階文章就從這裡出發,一路深入到 stack unwinding 的底層機制、checked 例外與 lambda 的世紀衝突、以及函數式錯誤處理的當代趨勢。
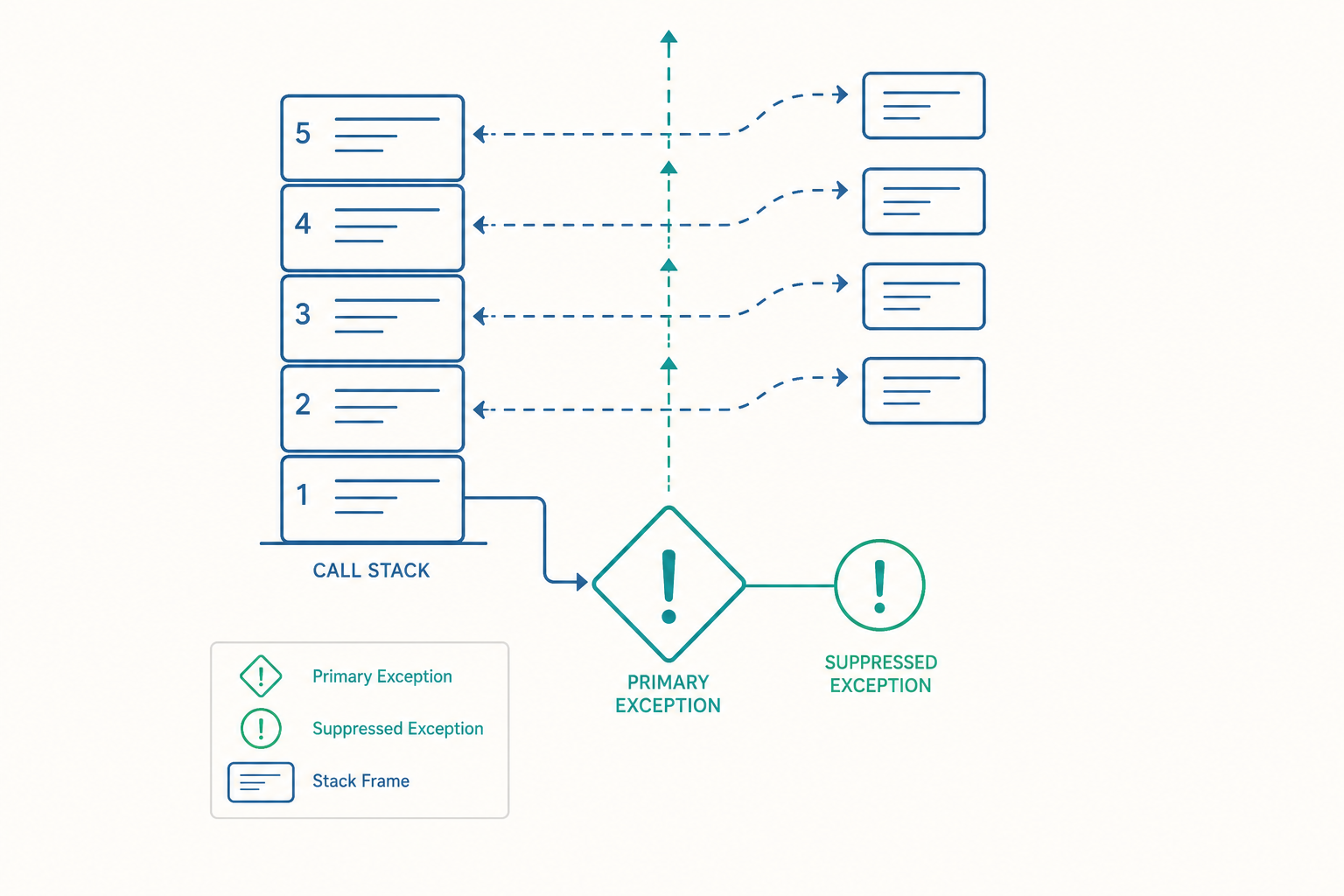
被抑制的例外:try-with-resources 真正的內部運作
入門篇把 try-with-resources 講成「自動呼叫 close()」,但它其實是編譯器幫你展開的一段相當精細的程式碼。當主體與 close() 都出錯時,主體的例外是主角,close() 的例外被「附掛」到主角身上,成為它的 suppressed exception。
我們先親手驗證這個行為:
public class SuppressedDemo {
static class NoisyResource implements AutoCloseable {
@Override public void close() {
throw new IllegalStateException("關閉時也爆了");
}
}
public static void main(String[] args) {
try {
try (NoisyResource r = new NoisyResource()) {
throw new RuntimeException("主體爆了(真正的根因)");
}
} catch (Exception primary) {
System.out.println("主要例外:" + primary.getMessage());
for (Throwable s : primary.getSuppressed()) {
System.out.println(" └ 被抑制:" + s.getMessage());
}
}
}
}
// 輸出:
// 主要例外:主體爆了(真正的根因)
// └ 被抑制:關閉時也爆了
關鍵在於:你不會丟失任何一個例外。主體的 RuntimeException 照常往外傳,而 close() 的 IllegalStateException 不會消失,它被掛在主例外的 suppressed 清單裡,可以用 getSuppressed() 取回。列印堆疊軌跡時,它會以 Suppressed: 標籤出現。這跟入門篇提過的 Caused by:(因果鏈)是兩條不同的軸,初學者極易混淆:
Caused by:(cause / 因果鏈):縱向的「為什麼」。A 例外因為 B 例外而被丟出(例外轉譯)。用initCause()或建構子的Throwable cause參數設定。Suppressed:(抑制):橫向的「同時」。在處理 A 例外的過程中,清理動作又丟出了 B,B 被「讓位」給 A。用addSuppressed()設定。
如果把 try-with-resources 手動展開,編譯器產生的程式碼邏輯大致是這樣(簡化版,幫助你理解它替你做了什麼):
NoisyResource r = new NoisyResource();
Throwable primaryExc = null;
try {
throw new RuntimeException("主體爆了");
} catch (Throwable t) {
primaryExc = t; // 記住主體的例外
throw t;
} finally {
if (r != null) {
if (primaryExc != null) {
try {
r.close();
} catch (Throwable closeExc) {
primaryExc.addSuppressed(closeExc); // ★ 關鍵:附掛而非覆蓋
}
} else {
r.close(); // 主體正常,close() 的例外正常往外丟
}
}
}
看懂這段,你就理解了一個重要設計原則:清理動作(close)的失敗,永遠不該掩蓋業務動作(try 主體)的失敗,因為前者通常只是後者的連鎖反應。手寫 finally 做不到這件事,這正是「永遠優先用 try-with-resources」最深刻的理由——它不只是少打幾個字,而是語意上更正確。
動手算一下:close 順序與抑制的交互作用
多資源時情況更微妙。假設宣告三個資源、主體又出錯,會發生什麼?
try (A a = new A(); // close 丟 ExA
B b = new B(); // close 丟 ExB
C c = new C()) { // close 丟 ExC
throw new RuntimeException("主體");
}
回憶入門篇講的「後開先關」:關閉順序是 c → b → a。主體的 RuntimeException 是主角,三個 close 例外依關閉順序依次被 addSuppressed。所以最終主例外的 suppressed 清單是 [ExC, ExB, ExA]。你拿到的會是一個完整的「事故現場」:根因加上三份清理失敗報告,一個都不少。這種「資訊無損」的設計,是工業級錯誤診斷的基礎。
finally 的危險:為什麼它能「吃掉」例外與 return
入門篇提醒過「別在 finally 裡 return 或丟例外」,但沒解釋為什麼這件事如此致命。理解它需要看 finally 的本質:它是一段「不論 try 區塊以何種方式離開,都會在離開前被執行」的程式碼。問題就出在「離開前」——如果 finally 自己也決定要離開(return 或 throw),它的決定會覆蓋原本那個正在進行的離開。
static int trap() {
try {
return 1; // 想回傳 1
} finally {
return 2; // ★ 但 finally 也 return,覆蓋了 1
}
}
// trap() 回傳 2,不是 1。那個 return 1 形同蒸發。
更陰險的是吞例外:
static void swallow() {
try {
throw new IOException("磁碟滿了"); // 真正的根因
} finally {
throw new RuntimeException("清理失敗"); // ★ 蓋掉 IOException,根因消失
}
}
// 呼叫端只會看到「清理失敗」,永遠不知道根本問題是磁碟滿了。
注意對比:try-with-resources 用 addSuppressed 保留了清理時的例外;而手寫 finally 裡丟例外則是徹底覆蓋根因。這正是兩者的本質差異。從 bytecode 角度看,finally 並不是一個獨立的區塊——早期 JVM 用一個叫 jsr/ret(jump-to-subroutine)的指令對來實作它,但因為驗證困難、容易產生不可驗證的位元組碼,從 Java 6 起編譯器改採程式碼複製(code duplication):把 finally 的內容複製貼到每一個可能的離場點(正常結束、每個 catch、每個 return、例外傳播路徑)之前。所以你寫一次 finally,bytecode 裡可能有好幾份副本。理解這點就能明白:finally 是「在每個出口都插一段程式碼」,自然能覆蓋任何想從那個出口離開的值或例外。
Stack Unwinding:例外往上傳時,到底發生了什麼
入門篇說「例外會往上拋到能處理它的那一層」,但「往上拋」這個動作的底層機制叫堆疊回溯(stack unwinding),值得拆開來看,因為它解釋了例外的效能特性與 finally 的執行時機。
當 throw 執行時,JVM 拿著這個例外物件,開始從當前方法往呼叫者方向回溯呼叫堆疊,逐層詢問:「這一層的當前位置,有沒有一個能接住這個型別的 handler?」這個查詢靠的是每個方法都附帶的例外表(exception table)——一張記錄「位元組碼範圍 → handler 位置 → 可處理型別」的對照表。
方法 main() ── 呼叫 ──▶ 方法 a() ── 呼叫 ──▶ 方法 b() ── throw!
│
◀──────────── 回溯 unwinding ───────────────┘
① b() 有 catch 嗎?沒有 → 彈出 b 的堆疊框,先跑 b 的 finally
② a() 有 catch 嗎?沒有 → 彈出 a 的堆疊框,先跑 a 的 finally
③ main() 有 catch 嗎?有!→ 控制權交給該 catch
幾個從這張圖能讀出的深刻結論:
- 每彈出一層堆疊框,該層的
finally與 try-with-resources 的close()都會在彈出前被觸發。這就是「為什麼 finally 保證執行」的機制層解釋——它被縫進了 unwinding 的路徑上。 - 回溯成本與堆疊深度成正比。例外從
b一路傳到main,每層都要查表。再加上入門篇提過的fillInStackTrace()也是 $O(d)$($d$ 為堆疊深度),所以丟例外的總成本大約是 $O(d)$,深堆疊下相當可觀。 - 例外表讓「沒出錯」時零開銷。正常執行路徑根本不碰例外表,所以包一層
try不拖慢正常流程——只有真的throw時才付費。
看一個例子:用 suppressed 與 cause 打造完整事故報告
把上面的機制串起來,我們寫一個會同時觸發「因果鏈」與「抑制」的實際場景:一個資料庫批次寫入器,主體寫入失敗(根因),rollback 又失敗(被抑制),最後轉譯成業務例外往上拋(因果鏈)。
public class BatchWriter {
static class DbException extends Exception {
DbException(String m, Throwable c) { super(m, c); }
}
static class Connection implements AutoCloseable {
void write(String row) { throw new RuntimeException("約束違反:" + row); }
void rollback() { throw new IllegalStateException("rollback 連線已斷"); }
@Override public void close() { System.out.println("連線已關閉"); }
}
static void writeBatch(java.util.List<String> rows) throws DbException {
try (Connection conn = new Connection()) {
try {
for (String r : rows) conn.write(r);
} catch (RuntimeException writeErr) { // 主體失敗 = 根因
try {
conn.rollback(); // 清理動作又失敗
} catch (RuntimeException rbErr) {
writeErr.addSuppressed(rbErr); // ★ 橫向:抑制
}
throw new DbException("批次寫入失敗", writeErr); // ★ 縱向:因果鏈
}
}
}
public static void main(String[] args) {
try {
writeBatch(java.util.List.of("Alice", "Bob"));
} catch (DbException e) {
System.out.println("頂層攔截:" + e.getMessage());
System.out.println(" 根因:" + e.getCause().getMessage());
for (Throwable s : e.getCause().getSuppressed())
System.out.println(" 抑制:" + s.getMessage());
}
}
}
// 輸出:
// 連線已關閉
// 頂層攔截:批次寫入失敗
// 根因:約束違反:Alice
// 抑制:rollback 連線已斷
一次事故,三層資訊全部保留:頂層的業務語意(DbException)、真正的根因(約束違反)、以及清理時的二次故障(rollback 失敗)。這就是工業級例外處理該有的樣子——永不丟失資訊。
Checked 例外 vs Lambda:Java 函數式風格的最大痛點
入門篇提到 checked 例外與 Stream 衝突,這裡我們把它徹底講透,因為這是現代 Java 程式設計最常卡關的地方之一。
問題的根源:Java 8 的標準函數式介面(Function、Supplier、Consumer…)的抽象方法都沒有宣告 throws。所以你無法在 lambda 裡直接呼叫一個會丟 checked 例外的方法:
// 假設 readFile 宣告 throws IOException
List<String> paths = List.of("a.txt", "b.txt");
// ❌ 編譯失敗:Function.apply 不允許丟 checked 例外
paths.stream().map(p -> readFile(p)).forEach(System.out::println);
業界發展出幾種應對策略,各有取捨。策略一:就地 try/catch 並包成 unchecked——最直接,但很囉嗦:
paths.stream()
.map(p -> {
try { return readFile(p); }
catch (IOException e) { throw new UncheckedIOException(e); } // JDK 內建的包裝
})
.forEach(System.out::println);
注意 UncheckedIOException 是 JDK 8 為此特地新增的類別——官方等於承認「checked 例外在函數式情境下需要一個逃生門」。策略二:自訂一個「會丟例外的函數式介面」,集中包裝:
@FunctionalInterface
interface ThrowingFunction<T, R> {
R apply(T t) throws Exception; // ★ 這裡允許 throws
}
// 一個 adapter:把 ThrowingFunction 轉成標準 Function,自動包成 unchecked
static <T, R> Function<T, R> unchecked(ThrowingFunction<T, R> f) {
return t -> {
try { return f.apply(t); }
catch (Exception e) { throw new RuntimeException(e); }
};
}
// 使用:乾淨多了
paths.stream().map(unchecked(p -> readFile(p))).forEach(System.out::println);
策略三:sneaky throws(偷渡式拋出)——一個利用泛型型別抹除(type erasure)的著名 hack,能讓你「丟出 checked 例外,卻騙過編譯器讓它以為是 unchecked」:
@SuppressWarnings("unchecked")
static <E extends Throwable> void sneakyThrow(Throwable e) throws E {
throw (E) e; // 編譯期 E 被推導成 RuntimeException,執行期型別抹除後直接丟原例外
}
它能用,是因為checked / unchecked 的區分只存在於編譯期——到了 bytecode 與執行期,Throwable 就是 Throwable,JVM 從不檢查一個方法丟出的例外有沒有在 throws 宣告過。Project Lombok 的 @SneakyThrows 正是這個原理。但要鄭重警告:sneaky throws 破壞了 checked 例外的契約——呼叫端不會被編譯器提醒去處理,卻可能在執行期收到一個它完全沒預期的 checked 例外。它是「看懂 Java 型別系統運作的證明」,但在正式專案應極度節制使用。
這三種策略的存在本身就說明了:checked 例外與函數式設計在型別系統層級是不相容的。Kotlin、Scala 直接取消 checked 例外,部分原因就是要讓 lambda 無痛。
重點回顧
- 被抑制例外(suppressed) 是 try-with-resources 的內部基石:
close()失敗時用addSuppressed附掛,永不覆蓋主體的根因。用getSuppressed()取回。 Caused by:(因果,縱向) 與Suppressed:(抑制,橫向) 是兩條不同的軸,別混淆。finally裡return/throw會覆蓋正在進行的離場(根因蒸發);它在 bytecode 中以「複製到每個出口」實作。- 例外傳播 = stack unwinding:逐層彈出堆疊框、查例外表、沿途觸發
finally/close,成本約 $O(d)$。 - checked 例外與 lambda/Stream 型別不相容;應對策略有就地包裝、
ThrowingFunctionadapter、以及利用型別抹除的 sneaky throws(慎用)。
深入探討(研究所視角)
例外表的形式化:為什麼「正常路徑零成本」是可證明的
從 JVM 規範角度,每個方法的 Code 屬性裡有一個 exception_table,每筆是一個四元組 $(start\_pc,\ end\_pc,\ handler\_pc,\ catch\_type)$。語意是:若在位元組碼偏移落在 $[start\_pc, end\_pc)$ 範圍內丟出型別相容於 $catch\_type$ 的例外,就把控制權轉到 $handler\_pc$。
關鍵洞見在於這張表是離線資料結構(out-of-line metadata):正常執行時 JVM 只是依序執行指令,完全不查詢例外表;只有當 athrow 指令執行、或 JVM 內部觸發例外(如 null 解參考)時,才啟動「在當前方法的例外表中由上而下線性搜尋第一筆匹配項」的流程。這在形式上保證了「沒有例外的執行路徑」與「沒有 try 的程式碼」效能完全等價——這是 Java/C++ 等語言採用「table-driven exception」相對於早期 C 用 setjmp/longjmp(每進一個保護區就要付出設定成本)的根本優勢。代價是「丟例外」變慢,但這符合「例外應屬罕見」的設計假設。
堆疊軌跡的成本與「無堆疊例外」的工程權衡
入門篇提到可覆寫 fillInStackTrace() 省成本,研究所視角值得補充其量化結構。建立一個例外的總成本可拆成兩部分:
$$ C_{throw} = C_{alloc} + C_{stacktrace},\quad C_{stacktrace} = \Theta(d) $$
其中 $d$ 是當下呼叫堆疊深度。在現代框架(Spring、Hibernate)裡,業務方法的呼叫堆疊輕易達到數十到上百層,因此在熱路徑(hot path)上頻繁丟例外,$C_{stacktrace}$ 會主宰效能。實務上有三條優化路線:
- 無堆疊例外(stackless exception):以 JDK 7+ 的「四參數建構子」
Throwable(msg, cause, enableSuppression, writableStackTrace),把writableStackTrace設為false,等於停用堆疊軌跡填充。許多控制流式例外(如 Netty 的某些 signal 例外)就是這樣做的。 - 預先配置的單例例外(preallocated singleton):對於頻繁觸發且不需要堆疊軌跡的「控制信號」,直接重用一個靜態實例,連 $C_{alloc}$ 都省掉。但這只有在堆疊軌跡無意義時才安全。
- JIT 去最佳化的隱性陷阱:HotSpot 在某些情況下會把「頻繁丟出的隱式例外」(如熱迴圈中重複的
ArrayIndexOutOfBoundsException)優化成不帶訊息的快取例外,這正是為什麼你有時在生產日誌看到一個沒有任何堆疊軌跡的例外——它被 JIT 優化掉了,需要靠-XX:-OmitStackTraceInFastThrow還原。
Loom 與結構化並行:例外傳播的下一個範式
例外處理在傳統單執行緒裡的「往上拋」語意很清楚,但在並行情境下會崩潰:傳統 ExecutorService.submit 回傳的 Future,子任務丟出的例外被封印在 Future 裡,只有當你呼叫 get() 時才以 ExecutionException(一層包裝)冒出來——如果你忘了 get(),例外就永遠靜默消失。這與「結構化」的程式設計直覺背道而馳。
Java 21 正式化的虛擬執行緒(virtual thread) 與 結構化並行(structured concurrency,JEP 預覽中) 重新設計了這件事。StructuredTaskScope 把「一組子任務」當成一個有明確生命週期的單元:
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Subtask<String> user = scope.fork(() -> fetchUser());
Subtask<Integer> order = scope.fork(() -> fetchOrder());
scope.join().throwIfFailed(); // 任一子任務失敗 → 在這裡重新拋出
return new Result(user.get(), order.get());
} // 離開 scope 時,未完成的子任務自動被取消
語意上的革命在於:子任務的例外會沿著「語法上的巢狀結構」回傳到父範圍,就像同步呼叫一樣,而非困在某個遺忘的 Future 裡。這把例外傳播從「執行緒拓撲」重新綁回「程式碼的詞法結構」,呼應了結構化程式設計(structured programming)當年用 if/while 取代 goto 的同一種精神——讓控制流(包含錯誤的控制流)與程式碼的縮排結構一致。
跳出 try/catch:以型別承載錯誤的函數式進路
最後一個前沿視角:許多現代語言(Rust 的 Result<T, E>、Haskell 的 Either、Scala 的 Try/Either)根本不用例外作為主要錯誤處理機制,而是把「成功或失敗」編碼進回傳型別。這條路線的核心主張是:錯誤是普通的值,應該用普通的型別系統與資料流去處理,而非用一套獨立的、會打斷正常控制流的 throw/catch 機制。
Java 雖無原生 Result,但可以用 sealed interface(Java 17+)模擬,這也是觀察 Java 型別系統表達力的好練習:
sealed interface Result<T> permits Ok, Err {}
record Ok<T>(T value) implements Result<T> {}
record Err<T>(Exception error) implements Result<T> {}
// 呼叫端用 pattern matching 處理,編譯器強制窮盡所有分支
static String describe(Result<Integer> r) {
return switch (r) {
case Ok<Integer> ok -> "成功:" + ok.value();
case Err<Integer> err -> "失敗:" + err.error().getMessage();
};
}
這種寫法的好處與 checked 例外其實是同一個目標的不同手段:都想讓「可能失敗」這件事在型別層級可見、無法被忽略。差別在於 checked 例外把它放在「副通道(side channel,throws 子句)」,而 Result 把它放回「主通道(回傳值)」,因此能與 Stream、map/flatMap 等函數式組合子無縫銜接——這正好治好了我們前面看到的 lambda 衝突。理解這層對應關係,你就能站在「型別理論」的高度俯瞰整個錯誤處理光譜:從 C 的回傳碼、到 Java 的 checked 例外、到 Rust 的 Result,人類一直在回答同一個問題——如何讓編譯器幫我們記住「這裡可能會出錯」。Java 的 checked 例外是這條路上一次大膽、爭議、但深具啟發性的嘗試。