
Python 字串處理進階:Unicode、正規表示式與引擎內幕
當「看起來一樣」的字串卻不相等,你需要從碼位、字位到回溯引擎,重新認識文字的真實樣貌
當「3 個字」其實是 5 個碼位:一個讓你重新認識字串的問題
你已經會用 len() 數字串長度了。那麼請先猜一下,下面這段程式會印出什麼?
s1 = 'café' # 看起來 4 個字
s2 = 'café' # 看起來也 4 個字,但是用「e + 重音符」組成
print(len(s1), len(s2))
print(s1 == s2)
直覺上兩者都該是 4,而且應該相等。但實際跑出來很可能是 4 5 與 False。同一個「看起來一模一樣」的詞,Python 卻認為它們長度不同、內容不等。如果你拿這兩個字串去當字典的鍵、去做使用者搜尋比對,就會踩到一個極難 debug 的坑。
入門篇教你把字串當成「字元的序列」來操控;這篇進階篇要拆穿這個方便的謊言。字串底下其實是一連串 Unicode 碼位(code point),而「人眼看到的一個字」(grapheme)、「一個碼位」、「一個位元組」是三件不同的事。理解這個分野,再加上正規表示式(regular expression)與格式化迷你語言(format spec mini-language),你才算真正掌握字串處理。我們假設你已經熟悉切片、split、join、f-string 的基本用法,直接往深處走。
Unicode 正規化:讓「看起來一樣」真的相等
上面那個 bug 的根源是:Unicode 容許同一個字元用不只一種碼位序列表示。café 的 é 可以是單一碼位 U+00E9(預先組合好的,precomposed),也可以是 e(U+0065) 加上一個「結合重音符」U+0301(分解形式,decomposed)。兩者畫出來一樣,但碼位序列不同,所以 == 判定為假。
解法是正規化(normalization)。unicodedata.normalize() 把字串轉成標準形式,常用的有四種:NFC(正規組合,盡量合併成單一碼位)、NFD(正規分解,拆成基底字元加結合符號)、NFKC 與 NFKD(相容形式,連「全形 vs 半形」「² vs 2」這類也統一)。
import unicodedata
s1 = 'café'
s2 = 'café' # e + 結合重音符
print(len(s1), len(s2)) # 4 5
print(s1 == s2) # False
a = unicodedata.normalize('NFC', s1)
b = unicodedata.normalize('NFC', s2)
print(len(a), len(b)) # 4 4
print(a == b) # True
實務上的鐵則:任何要做比對、去重、當作鍵的文字,先正規化再說。 跨平台時尤其重要——macOS 的檔案系統傾向用 NFD 儲存檔名,多數其他系統用 NFC,所以同一個含重音或注音的檔名,在不同系統之間複製後,字面比對可能就對不上。
相容正規化(NFKC/NFKD)更激進,它會把「視覺或語意上等價但碼位不同」的字元也折疊在一起:
import unicodedata
print(unicodedata.normalize('NFKC', 'UEDU')) # 全形轉半形 → UEDU
print(unicodedata.normalize('NFKC', '²')) # 上標 2 → 2
print(unicodedata.normalize('NFKC', 'file')) # 連字 fi → fi
這在清理使用者輸入、做搜尋索引時很有用,但要小心它會破壞原始排版資訊,不可逆。
碼位、字元與字位:len() 到底在數什麼
入門篇說過 Python 3 的 len() 數的是字元數,而中文一個字算 1。更精確的說法是:len() 數的是碼位的數量。對絕大多數常用字而言,一個碼位就是一個字,這個近似很安全。但有兩類情況會破功。
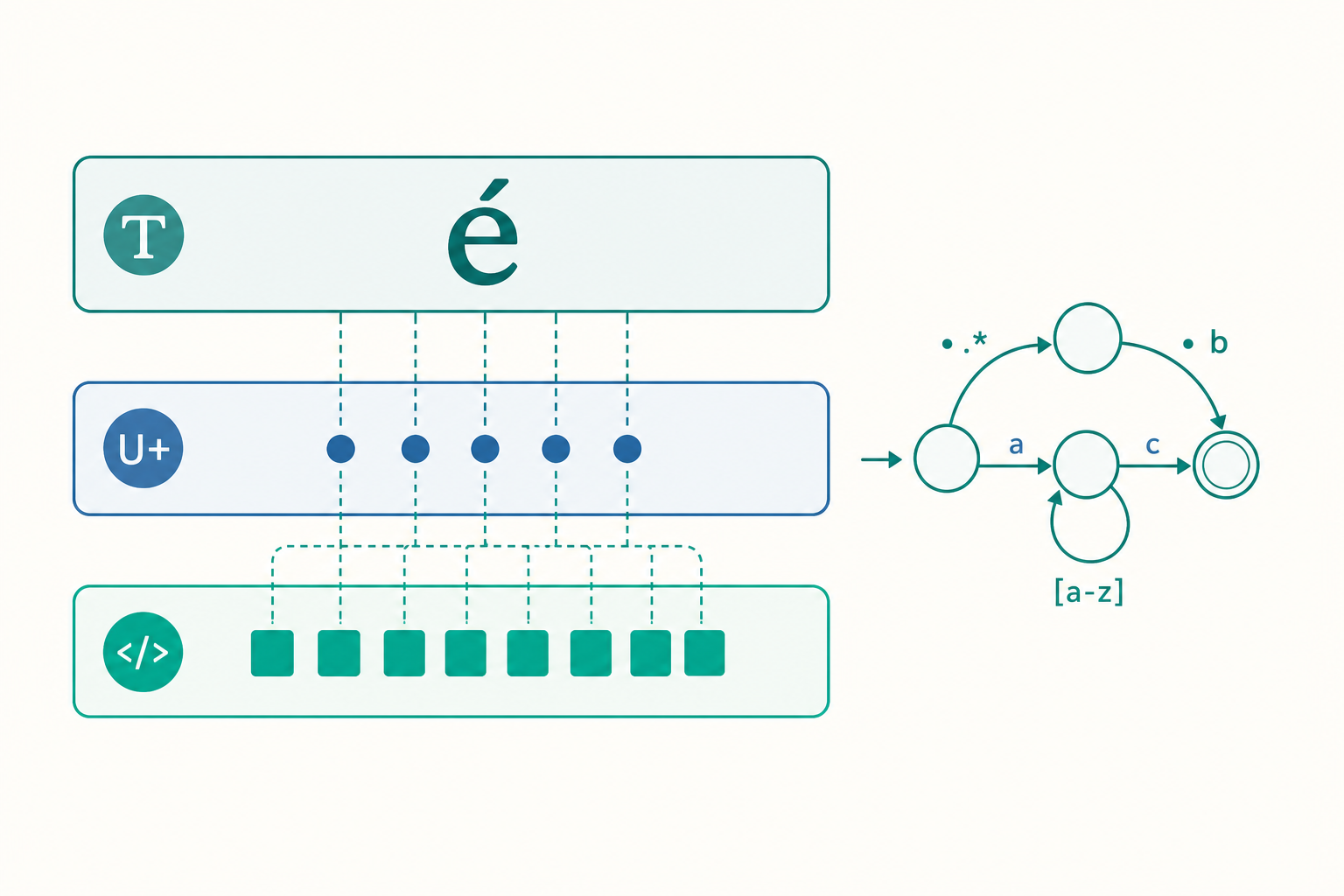
第一類是上面講的結合字元,一個「字位」(grapheme cluster,人眼認知的一個書寫單位)可能由多個碼位疊起來。第二類是星芒平面(astral plane)字元——碼位超過 U+FFFF 的字元,最典型的就是 emoji:
s = '👨👩👧' # 一個「家庭」emoji
print(len(s)) # 不是 1!是 5
for ch in s:
print(f'U+{ord(ch):04X}', unicodedata.name(ch, '?'))
這個家庭 emoji 由「男人 + 零寬度連接符 ZWJ + 女人 + ZWJ + 女孩」5 個碼位組成。Python 的 len() 老老實實回報 5,但使用者只看到一個圖案。所以「字串長度」這個問題在嚴格意義上是模糊的:你要數碼位、字位、還是顯示寬度?標準函式庫不提供字位切分,需要時得靠第三方套件(如 regex 模組的 \X,或 grapheme 套件)。
import regex # 第三方套件,非內建 re
s = '👨👩👧 café'
graphemes = regex.findall(r'\X', s)
print(len(graphemes)) # 以「人眼字位」計數
順帶一提,CJK 字元在等寬字型下佔兩個半形寬度。要對齊終端機輸出時,len() 給的碼位數不等於顯示欄寬,得查 unicodedata.east_asian_width() 來判斷每個字是「寬」(W/F)還是「窄」。
正規表示式:宣告式的模式比對
split、replace、find 處理固定的字串很順手,但碰到「模式」就力不從心。例如「抓出所有看起來像信箱的片段」「把連續多個空白折成一個」——這些規則用方法硬刻會很醜。正規表示式讓你用一個小型語言描述要找的模式,再交給引擎去比對。
import re
text = '聯絡:[email protected] 或 [email protected],謝謝'
pattern = r'[\w.]+@[\w.]+\.\w+'
emails = re.findall(pattern, text)
print(emails)
# ['[email protected]', '[email protected]']
幾個核心觀念。\w 配對「文字字元」(字母、數字、底線,而且 Python 預設連 Unicode 中文也算),. 配對任意字元,+ 表示「前一個東西出現一次以上」,* 是「零次以上」,? 是「零或一次」。把它們組起來就能描述複雜結構。
最容易被忽略、也最重要的是群組(group)與貪婪(greedy)。括號 () 把一段模式圈成一個可擷取的群組,比對成功後可以單獨取出:
import re
log = '[2026-06-14 09:30] 王小明 登入'
m = re.search(r'\[(\d{4})-(\d{2})-(\d{2}) ([\d:]+)\] (\S+)', log)
print(m.group(1), m.group(5)) # 2026 王小明
print(m.groups()) # ('2026', '06', '14', '09:30', '王小明')
量詞預設是貪婪的——盡量多吃。這常常出乎意料:
import re
html = '<b>粗體</b><i>斜體</i>'
print(re.findall(r'<.*>', html)) # ['<b>粗體</b><i>斜體</i>'] 整段吃光
print(re.findall(r'<.*?>', html)) # ['<b>', '</b>', '<i>', '</i>'] 加 ? 變懶惰
.* 會一路吃到最後一個 >;加上 ? 變成懶惰(lazy)量詞,盡量少吃,才得到我們要的四個標籤。這個「貪婪 vs 懶惰」的差別,是正規表示式最常見的 bug 來源之一。
看一個例子:把雜亂日期統一格式
假設一份資料裡日期格式五花八門:2026/6/14、2026-06-14、2026.6.14,你要全部統一成 2026-06-14。用 re.sub() 搭配群組與回呼函式:
import re
raw = '繳交日 2026/6/14,補繳 2026.12.1,公告 2026-3-09'
def normalize_date(m):
y, mo, d = m.group(1), m.group(2), m.group(3)
return f'{y}-{int(mo):02d}-{int(d):02d}'
# 分隔符用字元集合 [-/.],三段數字各自擷取
result = re.sub(r'(\d{4})[-/.](\d{1,2})[-/.](\d{1,2})', normalize_date, raw)
print(result)
# 繳交日 2026-06-14,補繳 2026-12-01,公告 2026-03-09
re.sub(pattern, repl, text) 把每個匹配交給 normalize_date,函式收到 match 物件、取出三段數字、用 f-string 的 :02d 補零後重組。一行樣式 + 一個小函式,就吃下了三種格式。把日期換成更多髒格式試試,體會宣告式描述的威力。
編譯與效能:別在迴圈裡重複解析樣式
每次呼叫 re.findall(pattern, ...),引擎都得先把樣式字串「編譯」成內部的狀態機。若同一個樣式要用很多次,先用 re.compile() 編譯一次、重複使用,能省下大量重複解析:
import re
EMAIL = re.compile(r'[\w.]+@[\w.]+\.\w+') # 編譯一次
for line in big_file: # 假設有大量行
EMAIL.findall(line) # 重複用同一個編譯結果
另外要警惕災難性回溯(catastrophic backtracking)。某些寫法(典型如巢狀量詞 (a+)+)在特定輸入下,回溯路徑會呈指數爆炸,一個短字串就能讓引擎卡死數秒甚至更久。這不只是效能問題,更是一種被稱為 ReDoS 的阻斷服務攻擊面。寫樣式時盡量避免讓多個量詞能匹配同一段文字。
格式化迷你語言:f-string 的另一半
入門篇示範了 {pi:.2f}、{42:05d},但格式規格(format specification mini-language)能做的遠不止這些。完整語法是 {value:[[fill]align][sign][#][0][width][,][.precision][type]},看起來嚇人,逐個拆開卻很實用。
對齊與填充對表格輸出特別關鍵。< 靠左、> 靠右、^ 置中,前面可指定填充字元:
for name, score in [('王小明', 92), ('李華', 7), ('陳大文', 100)]:
print(f'{name: <6}{score:>4}') # 姓名靠左補全形空白,分數靠右
千分位、正負號、百分比、進位制也都內建,不必自己拼:
print(f'{1234567:,}') # 1,234,567(千分位)
print(f'{0.1234:.1%}') # 12.3%(百分比)
print(f'{255:#x}') # 0xff(十六進位,# 加前綴)
print(f'{42:+}') # +42(強制顯示正號)
print(f'{3.14159:>10.2f}') # ' 3.14'(寬度 10、右對齊、兩位小數)
Python 3.8 之後還有一個 debug 神技:{expr=} 會同時印出運算式文字與其值,寫 log 時超省事:
x, y = 3, 4
print(f'{x + y=}') # x + y=7
你也可以動態決定寬度與精度,把它們也放進大括號:
width, prec = 10, 3
print(f'{3.14159:{width}.{prec}f}') # ' 3.142'
底層上,f-string、str.format()、format() 三者共用同一套格式協定——物件透過 __format__ 方法決定自己怎麼被格式化。你自訂的類別只要實作 __format__,就能支援 f'{obj:格式}'。
str.translate 與字元級轉換:批量替換的高速通道
要一次替換很多個字元(而非子字串),連串 replace 既冗長又低效。str.maketrans + translate 用一張查找表(translation table)一次掃過全文,是字元級轉換的正解:
# 全形數字轉半形
table = str.maketrans('0123456789', '0123456789')
print('學號0912'.translate(table)) # 學號0912
# 也能順便刪除字元:第三個參數列出要刪掉的字元
clean = str.maketrans('', '', ' \t\n') # 刪除所有空白類
print('a b\tc\nd'.translate(clean)) # abcd
translate 走的是底層字元映射,比起反覆呼叫 replace,在大量資料上明顯更快,也更不容易出現「替換後又被下一次替換改回去」的順序錯誤。
重點回顧
- 視覺相同 ≠ 碼位相同。
café可能是 4 或 5 個碼位。做比對、去重、當鍵之前,一律先unicodedata.normalize('NFC', s),跨平台檔名問題多半源於此。 len()數的是碼位,不是人眼字位。 Emoji 與結合字元會讓「一個圖案」回報為多個碼位;需要字位計數得靠regex的\X等第三方工具。- 正規表示式的量詞預設貪婪。
.*會盡量多吃,常需加?變懶惰;重複使用的樣式先re.compile,並提防巢狀量詞造成的災難性回溯。 - 格式化迷你語言能對齊、補零、加千分位、轉進位制。
{expr=}是除錯利器,寬度與精度還能動態嵌入。 - 大量字元級替換用
str.translate而非連串replace。 一張映射表一次掃完,更快也更安全。
深入探討(研究所視角)
CPython 的彈性字串表示(PEP 393)
入門篇提到 str 是 Unicode 碼位序列,但 CPython 在記憶體裡究竟怎麼存?早期(Python 3.2 以前)採固定寬度:要嘛每個字元用 2 位元組(UCS-2,存不下星芒平面),要嘛一律 4 位元組(UCS-4,純 ASCII 文字也得付 4 倍記憶體)。兩種都浪費。
PEP 393(Python 3.3 起)引入彈性字串表示(flexible string representation):直譯器掃描字串內容,選出能容納最大碼位的最小寬度——全是 Latin-1 範圍(≤ U+00FF)就每字元 1 位元組,最大碼位 ≤ U+FFFF 用 2 位元組,否則才用 4 位元組。於是純 ASCII 的英文文字只佔 1 位元組/字元,又能無損表示任何 Unicode。代價是:插入一個高碼位字元,可能讓整個字串「升級」到更寬的表示而需重新配置。這也是為什麼 len()、索引都是 $O(1)$——因為內部是定寬陣列(同一字串內所有字元等寬),第 $i$ 個字元的位址可直接算出,不必逐字掃描。UTF-8 那種變長編碼若拿來當內部表示,索引就會退化成 $O(n)$,這正是 Python 不用 UTF-8 當記憶體模型的原因。
import sys
print(sys.getsizeof('A')) # 純 ASCII,1 位元組/字元 + 表頭
print(sys.getsizeof('Ä')) # Latin-1,仍 1 位元組/字元
print(sys.getsizeof('學')) # 需 2 位元組/字元,表頭也更大
print(sys.getsizeof('𝕌')) # 星芒平面,4 位元組/字元
你會看到同樣「一個字」,記憶體開銷因碼位範圍而異。理解這層,你才懂為什麼某些「無害」的字串操作會悄悄改變記憶體佔用。
不可變性、字串拼接與 rope 的取捨
入門篇證明了迴圈內 += 拼接是 $O(n^2)$、join 是 $O(n)$。值得補充的是 CPython 對 s += x 偷偷做的最佳化:當該字串物件的參考計數為 1(沒有別人共享它)時,直譯器會嘗試原地擴充(in-place resize)而非每次重配置,使某些情況的拼接接近線性。但這是實作細節、不保證、也不可移植到 PyPy 等其他直譯器,所以慣例仍是 join。
更廣的視角是:當文字需要頻繁中段插入、刪除、串接時,「連續記憶體的不可變字串」並非最佳資料結構。文字編輯器、版本控制底層常用 rope(以平衡二元樹串起一段段小字串)或 gap buffer。rope 把串接做成 $O(1)$ 的接點、把任意位置插入降到 $O(\log n)$,代價是隨機索引從 $O(1)$ 變 $O(\log n)$。這正是「不可變、定寬、$O(1)$ 索引」與「可變、易插入」之間的經典取捨——Python 的 str 站在前者,因為它服務的是「以整體為單位處理文字」的常見情境,而非逐字元編輯。
正規表示式引擎:NFA 回溯 vs DFA 的工程選擇
Python 的 re 模組是回溯式 NFA(backtracking nondeterministic finite automaton)引擎。它之所以能支援反向參照(backreference)、前後查看(lookaround)這些超越正規語言的特性,正是靠回溯搜尋——但代價就是前面提到的災難性回溯,最壞情況時間複雜度是指數級。
理論上,純正規表示式可以編譯成DFA(deterministic finite automaton),對長度 $n$ 的輸入保證 $O(n)$ 線性掃描,永不回溯——這是 Thompson NFA 模擬法(Russ Cox 系列文章與 Go 的 RE2、Rust 的 regex crate 採用的路線)。為什麼 Python 不走這條路?因為 DFA 方案無法支援反向參照與某些 lookaround(那些特性使語言不再是正規語言),且建構完整 DFA 在狀態爆炸時記憶體吃緊。這是一個典型的工程權衡:re 選擇了表達力與回溯引擎,把「避免病態樣式」的責任交給開發者;RE2 選擇了線性時間保證,放棄部分特性以換取對抗惡意輸入的安全性。當你的服務要處理使用者提供的樣式或在不可信輸入上跑正規表示式時,這個區別會直接決定系統會不會被一行字串打垮。值得花時間讀 Russ Cox 的 “Regular Expression Matching Can Be Simple And Fast” 一文,它會徹底改變你看待正規表示式的方式。