
馮諾伊曼架構:儲存程式概念與現代電腦的藍圖
從「重新接線」到「載入軟體」,理解 CPU、記憶體與匯流排的共用瓶頸,以及快取、管線如何讓它隱身
為什麼你的電腦能「換一個程式」就變身?
想像一台早期的計算機器:要它從「做加法」變成「做減法」,工程師得拿著螺絲起子、重新插拔幾百條電線,花上好幾天。這聽起來荒謬,卻是 1940 年代真實的情況。ENIAC 這台龐然大物,每換一個任務就得重新「接線」。
今天,你打開瀏覽器、關掉它、再啟動一個試算表,硬體一根線都沒動過。是什麼讓這種「軟體換臉」成為可能?答案藏在一個影響至今、幾乎所有電腦都遵循的設計藍圖裡——馮諾伊曼架構(von Neumann architecture)。它的核心洞見只有一句話:把程式當成資料一樣存進記憶體。
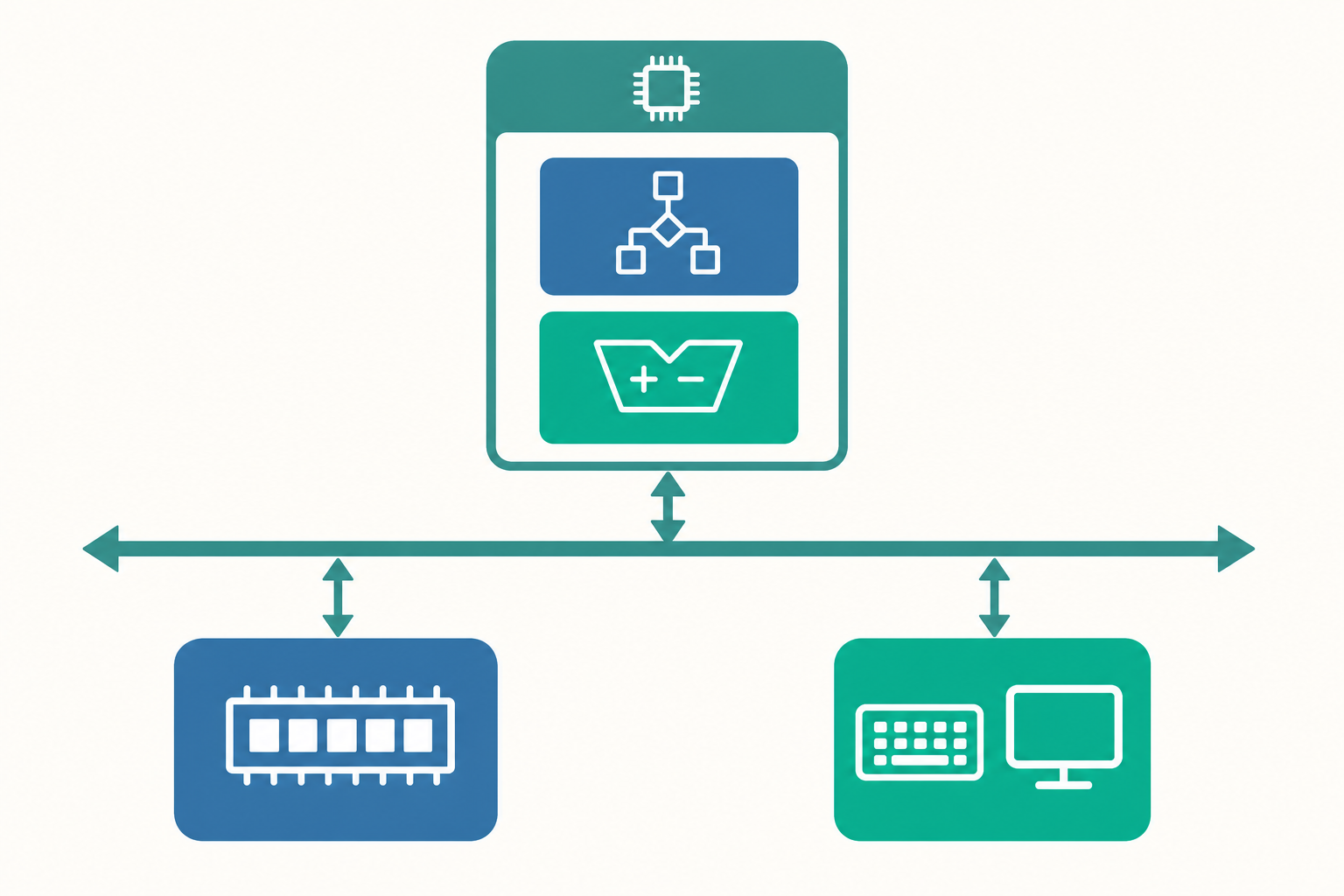
儲存程式概念:把指令當資料看待
在馮諾伊曼之前,許多機器把「程式」與「資料」當成兩種本質不同的東西:資料放在記憶體裡,程式則由實體線路決定。馮諾伊曼(John von Neumann)在 1945 年的《EDVAC 報告草案》中提出了關鍵想法——儲存程式概念(stored-program concept):
指令和資料一樣,都是一串二進位數字,都存在同一塊記憶體裡。
這個看似簡單的轉換帶來深遠的後果:
- 可程式化:要改變電腦的行為,只要把不同的指令載入記憶體,不必動硬體。
- 指令也能被運算:既然指令是資料,程式就可以讀取、修改另一段程式——這是編譯器(compiler)、作業系統載入器(loader)、甚至病毒能存在的基礎。
- 通用性:同一台機器能執行任何可以被表達成指令序列的演算法,這正呼應了圖靈(Turing)提出的通用計算機概念。
換句話說,「軟體」之所以是軟的,正因為它和你的照片、文件一樣,只是記憶體裡可被覆寫的位元。
五大組成:CPU、記憶體、IO 與匯流排
馮諾伊曼架構把一台電腦拆解成幾個分工明確的部件。我們可以用一個比喻來理解:把電腦想成一間辦公室。
| 部件 | 角色 | 辦公室比喻 |
|---|---|---|
| 控制單元(Control Unit) | 解讀指令、指揮其他部件 | 主管,決定下一步做什麼 |
| 算術邏輯單元(ALU) | 執行加減、比較、邏輯運算 | 計算機,實際動手算 |
| 記憶體(Memory) | 存放指令與資料 | 檔案櫃,放著待辦事項與文件 |
| 輸入/輸出(I/O) | 與外界溝通 | 收發室,收信件、寄包裹 |
| 匯流排(Bus) | 部件間傳輸資料的通道 | 走廊,所有東西都得經過它 |
其中,控制單元與 ALU 合起來構成中央處理器(CPU, Central Processing Unit),加上少量高速暫存器(register)。記憶體則以位址(address) 編號,CPU 透過位址讀寫特定格子裡的內容。
CPU 工作的基本節奏是反覆執行取指-解碼-執行循環(fetch-decode-execute cycle):
1. 取指(Fetch) :依程式計數器(PC)的位址,從記憶體讀出一條指令
2. 解碼(Decode) :控制單元解析這條指令要做什麼
3. 執行(Execute) :ALU 運算,或讀寫記憶體,或處理 I/O
4. PC 加一,回到步驟 1
注意第 1 步與第 3 步都可能需要存取同一塊記憶體,而且都得走同一條匯流排。這個細節,正是下一節要談的瓶頸根源。
動手看一個例子
讓我們追蹤一段極簡的虛擬機器碼,計算 3 + 5 並把結果存回記憶體。假設記憶體初始如下(位址 100、101 放資料,0 起放程式):
位址 內容
---- ----------------
0 LOAD R1, [100] ; 把位址 100 的值載入暫存器 R1
1 LOAD R2, [101] ; 把位址 101 的值載入暫存器 R2
2 ADD R1, R2 ; R1 = R1 + R2
3 STORE R1, [102] ; 把 R1 存回位址 102
4 HALT
100 3 ; 資料
101 5 ; 資料
102 ? ; 結果待寫入
逐步追蹤匯流排上發生的事:
週期 1:Fetch 位址0 的 LOAD(走匯流排)→ Execute 讀位址100=3(再走一次匯流排)→ R1=3
週期 2:Fetch 位址1 的 LOAD(走匯流排)→ Execute 讀位址101=5(再走一次匯流排)→ R2=5
週期 3:Fetch 位址2 的 ADD (走匯流排)→ Execute 在 ALU 內 3+5 → R1=8(不必存取記憶體)
週期 4:Fetch 位址3 的 STORE(走匯流排)→ Execute 寫位址102=8(再走一次匯流排)
週期 5:Fetch 位址4 的 HALT → 停止
數一數:光是這 5 條指令,匯流排上就來回奔波了至少 8 次。每一次「取指」和「存取資料」都得排隊使用同一條通道。當程式變成數十億條指令時,這條通道有多忙、多擁擠,就不難想像了。
馮諾伊曼瓶頸:共用匯流排的代價
把指令和資料放在同一塊記憶體、共用同一條匯流排,帶來了優雅的通用性,卻也埋下一個結構性難題:CPU 與記憶體之間,只有一條路。
這條路在任一瞬間,要嘛在搬指令、要嘛在搬資料,不能同時做兩件事。於是再快的 CPU,也得時常停下來「等記憶體把東西送過來」。這個現象就是馮諾伊曼瓶頸(von Neumann bottleneck)。
問題隨時間愈演愈烈。幾十年來,CPU 的運算速度成長遠遠快過記憶體的存取速度——這道日益擴大的鴻溝,業界稱為記憶體牆(memory wall)。打個比方:
- CPU 像是一位每秒能算上百題的數學天才。
- 記憶體像是一位走廊另一端、得起身走過來遞紙條給他的助理。
天才再厲害,每算幾題就得乾等助理慢慢走來遞下一張紙。整體效率不是由天才決定,而是由那條走廊與助理的速度決定。早在 1977 年,Backus 在圖靈獎演講中就以「von Neumann bottleneck」一詞,批評這種「把一個字一個字地搬過匯流排」的計算風格。
那麼,現代電腦如何不被這條走廊拖垮?答案是一整套精妙的緩解策略。
緩解之道一:快取(cache)的記憶體階層
既然每次都跑去遠端記憶體取資料太慢,那就在 CPU 旁邊放一塊小而極快的記憶體,把最近、最常用的指令與資料先複製過來。這就是快取(cache)。
現代 CPU 通常有多層快取,構成記憶體階層(memory hierarchy):
| 層級 | 典型大小 | 相對速度 | 比喻 |
|---|---|---|---|
| 暫存器(register) | 數十個字 | 最快 | 手上正握著的紙條 |
| L1 快取 | 數十 KB | 極快 | 桌面上的便利貼 |
| L2 / L3 快取 | 數 MB | 快 | 抽屜裡的常用檔案 |
| 主記憶體(DRAM) | 數 GB | 慢 | 走廊另一端的檔案櫃 |
| 磁碟/SSD | 數百 GB 以上 | 很慢 | 地下室倉庫 |
快取之所以有效,靠的是程式普遍具有的區域性(locality):
- 時間區域性(temporal locality):剛用過的資料,很可能馬上又要用(如迴圈變數)。
- 空間區域性(spatial locality):用了某個位址,鄰近位址也很可能被用到(如陣列循序走訪)。
當 CPU 要的資料正好在快取裡,稱為命中(hit),幾乎瞬間取得;不在則為未命中(miss),得到較慢的下一層去拿。寫程式時若能照顧區域性(例如循序而非跳躍地存取陣列),命中率提高,程式就能快上數倍。
緩解之道二:管線(pipeline)讓工作重疊
回想取指-解碼-執行循環。若 CPU 老老實實地一條指令完整跑完才開始下一條,那麼當「執行」階段在工作時,「取指」的電路就閒著——這太浪費了。
管線(pipeline) 的點子,和工廠的流水線一模一樣:把指令處理切成數個階段,讓不同指令同時佔用不同階段。
不分管線(逐條完成):
指令1: [取指][解碼][執行][寫回]
指令2: [取指][解碼][執行][寫回]
分管線(階段重疊):
指令1: [取指][解碼][執行][寫回]
指令2: [取指][解碼][執行][寫回]
指令3: [取指][解碼][執行][寫回]
指令4: [取指][解碼][執行][寫回]
理想情況下,管線讓 CPU 平均每個週期完成一條指令,吞吐量大幅提升。但管線也帶來新麻煩——當下一條指令需要上一條的結果,或遇到分支跳躍時,會產生危障(hazard),可能得插入停頓(stall)。現代 CPU 因此再疊上分支預測(branch prediction)、亂序執行(out-of-order execution) 等技術來填滿管線。
值得注意的是:快取與管線都沒有「消除」馮諾伊曼瓶頸,而是設法藏住它——讓 CPU 在等待記憶體的同時,仍有事可做、有資料可用。
馮諾伊曼 vs. 哈佛架構
既然瓶頸來自「指令和資料共用一條匯流排」,最直接的反制思路是:那就給它們各自一條路。這正是哈佛架構(Harvard architecture) 的核心。
| 特性 | 馮諾伊曼架構 | 哈佛架構 |
|---|---|---|
| 指令與資料記憶體 | 同一塊 | 分開兩塊 |
| 匯流排 | 共用一條 | 各自獨立 |
| 可同時取指與取資料 | 否 | 是 |
| 指令能否被當資料修改 | 可以(彈性高) | 較難(需特殊機制) |
| 硬體複雜度與成本 | 較低 | 較高 |
| 典型應用 | 一般電腦、伺服器 | 微控制器(MCU)、DSP 數位訊號處理器 |
哈佛架構因為兩條獨立通道,能在同一週期內同時取指令與取資料,對講求即時、固定任務的嵌入式系統特別有利。但它犧牲了「程式可被輕易讀寫修改」的彈性,也使硬體更複雜。
有趣的是,現代主流 CPU 其實是混血兒:對外(對主記憶體)維持馮諾伊曼的單一位址空間,方便通用程式設計;但在晶片內部的 L1 快取,卻分成指令快取與資料快取兩塊,能同時供應指令與資料。這種設計稱為改良式哈佛架構(modified Harvard architecture),等於是「外表馮諾伊曼、內裡哈佛」,兼得兩者之長。
重點回顧
- 儲存程式概念是馮諾伊曼架構的靈魂:指令與資料一視同仁地存在同一塊記憶體,使電腦從「重新接線」進化為「載入軟體」即可改變行為。
- 馮諾伊曼架構由 CPU(控制單元 + ALU)、記憶體、I/O、匯流排五大部件構成,CPU 反覆執行取指-解碼-執行循環。
- 馮諾伊曼瓶頸源於指令與資料共用單一匯流排,CPU 與記憶體速度差距形成記憶體牆,使 CPU 常需空等。
- 現代主要靠快取(利用區域性藏住延遲) 與 管線(讓指令處理階段重疊) 來緩解瓶頸——是「隱藏」而非「消除」。
- 哈佛架構用分離的指令/資料通道換取頻寬,常見於微控制器;主流 CPU 則採改良式哈佛架構,外馮諾伊曼、內哈佛。
深入探討(研究所視角)
從瓶頸到典範轉移。 馮諾伊曼瓶頸不只是工程細節,它規範了整個運算的「形狀」。Backus 在 1978 年圖靈獎演講中主張,這種「逐字搬運」的循序模型,連帶塑造了我們的程式語言(指令式、以指派敘述為核心),並呼籲轉向函數式(functional)風格以擺脫這種思維桎梏。這提醒我們:硬體架構與軟體典範彼此互相形塑,並非中立。
快取一致性與記憶體模型。 一旦進入多核心(multicore),每個核心都有自己的私有快取,同一個記憶體位址可能在多份快取裡有不同副本。如何保證大家看到一致的值?這催生了快取一致性協定(cache coherence protocol),如 MESI(Modified/Exclusive/Shared/Invalid 四狀態)。再往上,因為亂序執行與快取,硬體實際呈現的記憶體存取順序未必等同程式碼順序,於是有了記憶體一致性模型(memory consistency model) 與 happens-before 關係的形式化——這是並行程式設計正確性的理論基石,也是 C++、Java 記憶體模型規範的來源。
用平行性正面對抗瓶頸。 快取與管線是「藏住」瓶頸,但有些架構選擇從根本繞過它。SIMD(單指令多資料) 用一條指令處理一整批資料,攤平取指成本;GPU 以數千條執行緒掩蓋記憶體延遲(latency hiding);更激進的近資料運算(near-data / in-memory computing) 乾脆把運算單元搬到記憶體旁邊,從物理上縮短那條「走廊」。這些都可視為對單一匯流排假設的鬆綁。
與其他主題的連結。 馮諾伊曼架構是後續多個核心議題的根:作業系統的虛擬記憶體(virtual memory) 與分頁,本質是在馮諾伊曼的線性位址空間上加一層位址轉譯;指令集架構(ISA) 設計(RISC 對 CISC)關乎如何讓取指-解碼-執行更有效率;而資訊安全中經典的緩衝區溢位(buffer overflow) 攻擊之所以可能,恰恰是因為儲存程式概念讓「資料」與「指令」共處一塊記憶體——攻擊者把惡意指令偽裝成資料寫入,再誘使 CPU 去執行它。
正因如此,現代系統用 W⊕X(Write XOR Execute,又稱 DEP/NX 位元) 防禦機制把記憶體頁面標記為「可寫」或「可執行」但不可兩者兼具,等於在馮諾伊曼的彈性上,重新劃出一道哈佛式的界線。研究者與學習者理解這層攻防,目的在於建構更安全的系統與正當的防禦,而非用於攻擊。這也再次說明:架構的每一項優勢,往往同時是它的代價所在——而工程的藝術,正在於如何權衡取捨。