
變數與資料型別(進階):名字、繫結與型別系統的真相
從 a is b 的謎題出發,深入名字繫結、可變性、靜態與動態型別、浮點精度與整數溢位
當 a is b 有時為真、有時為假:變數背後的真相
讀過入門篇後,你已經知道變數可以裝整數、浮點數、字串與布林值,也知道怎麼指派與轉型。現在請看一段 Python:
a = 256
b = 256
print(a is b) # True
c = 257
d = 257
print(c is d) # False
兩段程式碼長得幾乎一樣,行為卻不同。明明 c 和 d 都是 257,為什麼 is 卻說它們「不是同一個東西」?要回答這個問題,我們得撕開「變數裝著一個值」這層直覺包裝,看清楚變數真正的身分:它不是一個盒子,而是一個名字(name),指向記憶體裡的某個物件(object)。這篇進階篇要談的,正是這層機制——變數的繫結語義、型別系統的設計權衡,以及數值型別在二進位世界裡的真實邊界。
變數是名字,不是盒子
入門時我們常用「盒子」來比喻變數:x = 5 就像把 5 放進名叫 x 的盒子。這個比喻對 C 這類語言還算貼切,但對 Python、Java、JavaScript 等語言會誤導你。
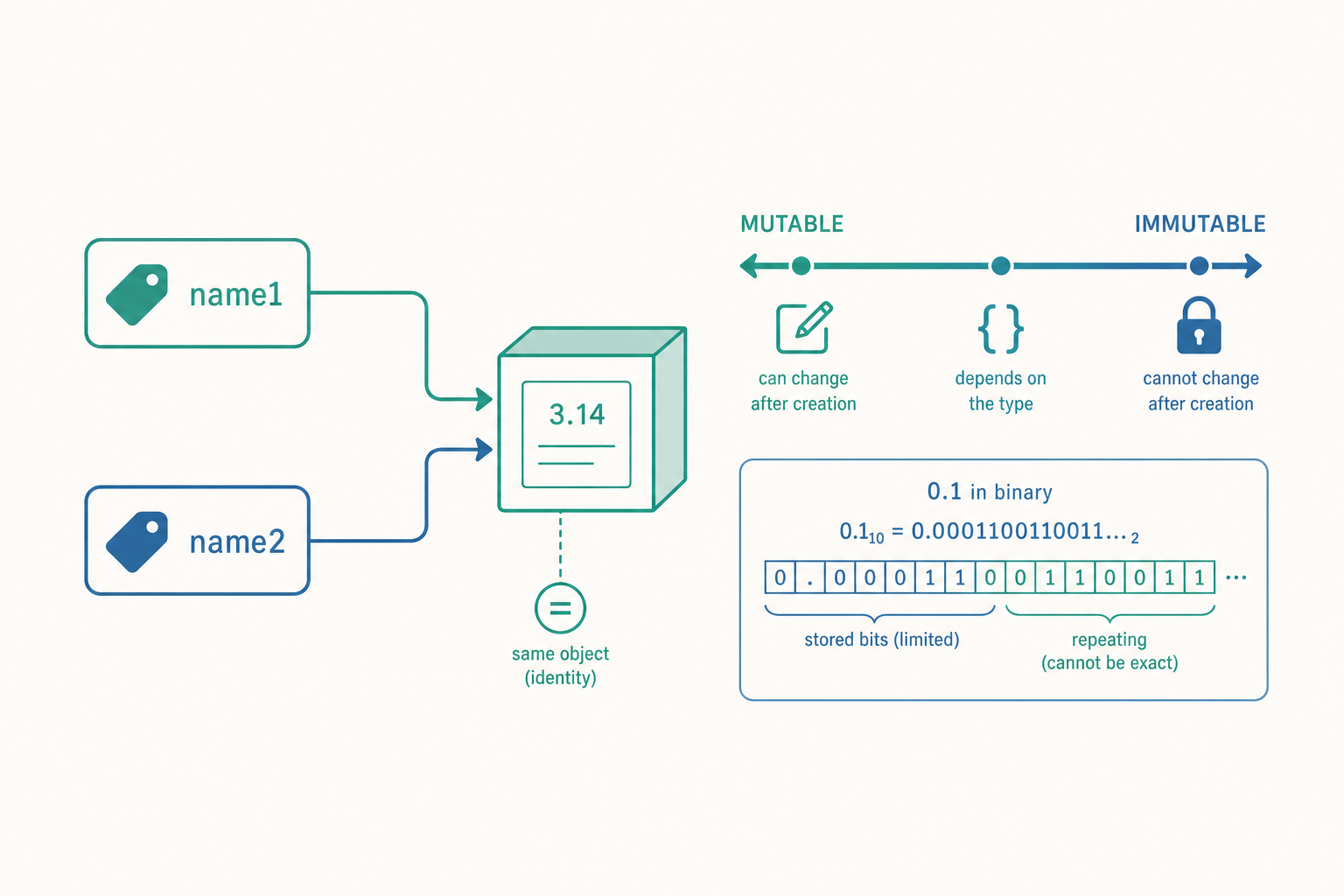
更精確的模型是名字繫結(name binding):x = 5 做的是「讓名字 x 指向一個值為 5 的整數物件」。名字與物件之間是「參照(reference)」關係,多個名字可以指向同一個物件。
x = [1, 2, 3]
y = x # y 與 x 指向「同一個」list 物件,不是複製
y.append(4)
print(x) # [1, 2, 3, 4] ← x 也變了!
這就是初學者最常踩的雷:以為 y = x 複製了一份資料,結果改 y 連 x 一起改。理解這點的關鍵,是區分三個概念:
- identity(身分):物件在記憶體中的唯一識別,Python 用
id()查,is比較。 - type(型別):物件屬於哪一類,用
type()查。 - value(值):物件目前承載的內容,
==比較。
x = [1, 2, 3]
y = x
z = [1, 2, 3] # 另外建立一個內容相同的 list
print(x is y) # True ← 同一個物件
print(x is z) # False ← 不同物件
print(x == z) # True ← 但內容相等
回到開頭的謎題:CPython 為了效能,把小整數(−5 到 256)預先建立成單例快取(small integer cache),所以 a = 256 與 b = 256 拿到的是同一個快取物件,is 為真;而 257 超出快取範圍,每次都新建物件,is 就為假。這是實作細節而非語言保證——所以正式程式碼永遠不要用 is 比較數值或字串,只用 is 來比 None、True、False 這些真正的單例。
可變與不可變:型別系統的隱形分界線
物件分成可變(mutable)與不可變(immutable)兩類,這條線決定了賦值、傳參與比較的行為。
| 類別 | 代表型別 | 改變內容會怎樣 |
|---|---|---|
| 不可變 | int、float、str、tuple、frozenset |
不能就地修改,「修改」其實是建立新物件 |
| 可變 | list、dict、set、多數自訂類別 |
可就地修改,名字仍指向同一物件 |
s = "hello"
print(id(s))
s += " world" # 看起來是「append」,其實是新建字串
print(id(s)) # id 變了 ← s 指向一個全新物件
lst = [1, 2]
print(id(lst))
lst += [3] # list 就地擴充
print(id(lst)) # id 不變 ← 還是同一個物件
不可變的好處是安全與可雜湊(hashable):因為內容不會偷偷改變,這類物件可以當 dict 的鍵或放進 set。可變物件因為內容會變,雜湊值也會跟著變,所以不能當鍵。
d = {(1, 2): "tuple 可當鍵"} # OK,tuple 不可變
d = {[1, 2]: "x"} # TypeError: unhashable type: 'list'
看一個例子:可變預設參數的經典陷阱
這條分界線會在函式預設參數上製造一個著名的坑:
def add_item(item, bucket=[]): # ⚠️ 預設值是「同一個」list
bucket.append(item)
return bucket
print(add_item("a")) # ['a']
print(add_item("b")) # ['a', 'b'] ← 竟然累積了!
預設參數只在函式定義時求值一次,這個 [] 物件被所有呼叫共用。正確寫法是用不可變的哨兵值:
def add_item(item, bucket=None):
if bucket is None:
bucket = [] # 每次呼叫建立新 list
bucket.append(item)
return bucket
注意這裡用 is None 而非 == None——因為我們比的是身分,而且 None 是貨真價實的單例。
靜態型別 vs 動態型別:兩種世界觀
入門篇可能沒細談「型別到底何時被檢查」。這牽涉到型別系統的兩個正交維度:
- 靜態(static)vs 動態(dynamic):型別檢查發生在編譯期還是執行期?
- 強(strong)vs 弱(weak):語言允不允許隱式、不安全的型別混用?
這兩個維度常被混為一談,但它們各自獨立:
| 語言 | 靜/動態 | 強/弱 | 說明 |
|---|---|---|---|
| Python | 動態 | 強 | 執行期才知型別,但 1 + "x" 直接報錯 |
| C | 靜態 | 弱 | 編譯期檢查,但指標可隨意轉型 |
| Java | 靜態 | 強 | 編譯期檢查且不容隱式不安全轉型 |
| JavaScript | 動態 | 弱 | 1 + "1" 得到 "11",隱式轉型 |
# Python:動態強型別
x = 5
x = "now a string" # OK,變數本身沒型別,物件才有
result = 1 + "x" # TypeError ← 強型別不幫你瞎猜
// JavaScript:動態弱型別
console.log(1 + "1"); // "11" ← 數字被悄悄轉成字串
console.log(1 - "1"); // 0 ← 字串又被轉回數字
console.log([] + {}); // "[object Object]" ← 混亂的隱式轉型
值得注意的是「變數有沒有型別」這個問題的答案,取決於語言。在 C 裡 int x; 的型別綁在變數上;在 Python 裡型別綁在物件上,變數(名字)本身無型別,所以同一個名字前一秒是 int、後一秒是 str 完全合法。
漸進式型別:動態語言補上靜態的護欄
純動態語言的彈性是雙面刃:寫得快,但大型專案容易因型別錯誤在執行期才爆炸。現代解法是漸進式型別(gradual typing)——在動態語言上「選擇性」加註型別提示,讓工具在執行前就抓錯,但執行期不強制。
def greet(name: str, times: int = 1) -> str:
return (f"Hi {name}! " * times).strip()
# 型別提示不會在執行期被檢查,但 mypy / Pyright 等工具會靜態分析
wrong: int = greet("Lee") # mypy 報錯:str 不能指派給 int
關鍵觀念:Python 的型別提示(type hints,PEP 484)執行期完全不檢查,它只是給靜態分析工具與 IDE 看的「文件」。它讓你在動態語言裡享受靜態語言的早期錯誤偵測,又不犧牲彈性。TypeScript 對 JavaScript 做的也是同一件事——編譯成 JS 後型別資訊全部抹除(type erasure)。
這種「設計時靜態、執行時動態」的折衷,正好命中大型軟體開發的痛點。當專案從一個人的腳本長成數十萬行、多人協作的系統,沒有型別護欄的動態語言會讓重構變成一場惡夢:你改了某個函式的回傳型別,卻不知道哪些呼叫端會壞掉,只能祈禱測試覆蓋率夠高。漸進式型別讓你逐步為關鍵模組加上註記,工具就能在你按下儲存的瞬間標出所有受影響的地方。這也是為什麼大型 Python 專案(如 Dropbox、Instagram)都大規模採用 type hints,而 JavaScript 生態幾乎全面轉向 TypeScript。
不過要小心一個迷思:型別提示不是萬靈丹。因為執行期不檢查,外部資料(API 回應、使用者輸入、JSON 解析)即使標了型別,實際進來的也可能是別的東西。對這些「信任邊界」上的資料,你仍需要 pydantic 這類執行期驗證工具,把靜態註記與動態檢查結合起來。
動手算一下:浮點數為什麼 0.1 + 0.2 ≠ 0.3
入門篇告訴你 float 裝小數,但沒告訴你它其實常常「裝不準」。這是進階篇必須補上的真相。
print(0.1 + 0.2) # 0.30000000000000004
print(0.1 + 0.2 == 0.3) # False
這不是 bug,是 IEEE 754 雙精度浮點數的本質。電腦用二進位科學記號表示實數:
$$x = (-1)^{s} \times 1.f \times 2^{e}$$
雙精度用 64 位元:1 位符號 $s$、11 位指數 $e$、52 位尾數 $f$。問題在於:十進位的 0.1 換成二進位是無限循環小數 $0.0001100110011\ldots_2$,就像十進位無法精確表示 $1/3$ 一樣。52 位尾數只能存近似值,誤差於是產生。
我們可以親手看到這個近似值:
from decimal import Decimal
print(Decimal(0.1))
# 0.1000000000000000055511151231257827021181583404541015625
所以正確的浮點數比較不是用 ==,而是判斷「誤差是否夠小」:
import math
print(math.isclose(0.1 + 0.2, 0.3)) # True ← 容許微小誤差
需要絕對精確(如金額計算)時,改用十進位定點型別:
from decimal import Decimal
price = Decimal("0.1") + Decimal("0.2")
print(price) # 0.3 ← 精確
print(price == Decimal("0.3")) # True
注意 Decimal("0.1") 用字串初始化才精確;若寫 Decimal(0.1) 是先讓 0.1 變成不精確的 float 再轉,誤差已經混進去了。
順帶一提,並非所有十進位小數都不精確——能寫成 $k / 2^n$ 形式(分母是 2 的次方)的數,例如 0.5、0.25、0.125,在二進位裡都是有限位數,可以被浮點數精確表示。所以 0.5 + 0.25 == 0.75 為真。會出問題的是那些換算成二進位後變成無限循環的數,0.1、0.2、0.3 都屬於這一類。判斷一個小數是否「浮點友善」,就看它能不能被表示成有限的二進位分數。
這也解釋了一個常見困惑:為什麼有時候 0.1 + 0.2 印出來就是 0.3、有時候卻是 0.30000000000000004?差別在於「儲存的近似值」與「印出來的字串」是兩回事。Python 的 print 用「能唯一還原該浮點數的最短十進位字串」來顯示,所以某些情況下近似誤差剛好被四捨五入隱藏,但底層的位元仍然不精確——只要做相等比較就會現形。
整數溢位:邊界在哪裡
不同語言對整數上限的處理天差地別,這直接影響你的程式會不會在某個值悄悄出錯。
# Python:整數任意精度(arbitrary precision),不會溢位
big = 2 ** 200
print(big) # 完整印出 1606938044258990275541962092341162602522202993782792835301376
Python 的 int 會自動擴展位元數,代價是大數運算較慢。但 C、Java 的固定寬度整數有硬邊界:
// C:32 位元 int,上限 2147483647
int x = 2147483647;
x = x + 1; // 溢位!結果繞回 -2147483648(undefined behavior in signed)
這種整數溢位(integer overflow)曾造成真實災難:Boeing 787 的發電機控制單元若連續運轉 248 天,內部計數器溢位會導致全機斷電,FAA 在 2015 年發布適航指令要求定期重啟。1996 年歐洲亞利安 5 號火箭首飛爆炸,根因之一也是把 64 位元浮點數的水平速度值塞進 16 位元整數而溢位。理解你用的型別「能裝多大」,不只是學術問題,而是工程責任。
這裡也藏著一個 Python 學習者容易誤解的點:Python 的 int 不會溢位,並不代表「位元寬度」這個概念在 Python 裡消失了。當你呼叫作業系統 API、處理二進位檔案格式、或與 C 函式庫互動時,對方仍是固定寬度,你必須自己負責把 Python 的任意精度整數正確截斷到目標寬度,否則資料會在邊界悄悄損壞。下面這個 helper 就是在做這件事——它先用位元遮罩取低 32 位,再依最高位判斷正負,模擬有號整數的二補數繞回行為。
# 想在 Python 模擬 C 的 32 位元溢位行為:
def to_int32(n):
n &= 0xFFFFFFFF # 只保留低 32 位
return n - 0x100000000 if n >= 0x80000000 else n
print(to_int32(2147483647 + 1)) # -2147483648
重點回顧
- 變數是名字不是盒子,
y = x讓兩個名字指向同一物件而非複製;用id()、is看身分,==看值,type()看型別。 - 可變(list/dict/set)與不可變(int/str/tuple)的分界決定了賦值、傳參與可否當字典鍵;可變預設參數會在多次呼叫間共用,用
None哨兵避開。 - 靜態/動態(何時檢查型別)與強/弱(容不容隱式轉型)是兩個獨立維度;Python 是動態強型別,JavaScript 是動態弱型別。
- 型別提示與漸進式型別讓動態語言補上靜態護欄,但 Python 的 hints 執行期不檢查,純為工具與可讀性服務。
- 浮點數因 IEEE 754 二進位表示而有精度極限,比較用
math.isclose,需精確用Decimal;固定寬度整數有溢位風險,Python 的int則任意精度。
深入探討(研究所視角)
往研究所層次走,「型別」會從工程慣例升格為形式系統。型別論(type theory)把型別視為命題、程式視為證明——這就是 Curry–Howard 對應(Curry–Howard correspondence):一個 A → B 型別的函式,對應到邏輯中「A 蘊涵 B」的證明。這座橋讓型別檢查等價於證明檢查,是 Coq、Agda、Lean 等證明輔助工具的理論地基,也讓「型別正確的程式不會卡住(well-typed programs don't get stuck)」這個性質得以被嚴格證明(progress 與 preservation 兩個定理)。
在語言設計層面,幾個值得追的主題:
- 型別推斷(type inference):ML 系語言(OCaml、Haskell)用 Hindley–Milner 演算法,不必寫型別註記也能在編譯期推導出最一般型別(principal type),其核心是 Robinson 的合一演算法(unification)。理解它能解釋為何 Haskell 寫起來像動態語言卻有靜態保證。
- 子型別與變異(subtyping & variance):當
Cat <: Animal,List<Cat>是否為List<Animal>的子型別?答案牽涉協變(covariance)、逆變(contravariance)與不變(invariance)。Java 的? extends/? super萬用字元、Scala 的+T/-T都在處理這個問題,搞錯會破壞型別安全。 - 代數資料型別與所有權(algebraic data types & ownership):Rust 把「可變/不可變」這條線提升為借用檢查器(borrow checker)強制執行的所有權規則,在編譯期消滅資料競爭與懸空指標,等於把本文談的可變性陷阱用型別系統根除。
- 裝箱與記憶體佈局(boxing & memory layout):Python 的「萬物皆物件」意味每個整數都是堆積(heap)上的物件,帶物件標頭與參照計數,所以一個
int在 CPython 裡實際佔 28 位元組而非 8。研究 NumPy 為何快、Java 的Integer與int為何不同,本質都是在問「型別資訊存在哪、要不要裝箱」這個系統設計權衡。
從這個高度回望開頭的 a is b 之謎,你會發現它其實是一連串設計決策的縮影:身分語義、不可變物件的快取最佳化、以及「實作細節不該寫進程式邏輯」的工程原則。變數與型別看似是第一週的內容,卻一路通往語言設計與形式驗證的最前沿。