
儲存與輸入輸出
從 HDD 的旋轉磁碟到 SSD 的電子閘,再到中斷與 DMA 如何把 CPU 從緩慢的 I/O 中解放出來
為什麼關機後檔案還在,遊戲卻要「讀取中」?
想像你正在玩一款大型遊戲。按下開機鍵的瞬間,硬碟裡的作業系統被搬進記憶體,遊戲存檔安然無恙地躺在那裡——即使昨晚你直接拔掉電源也一樣。可是當你走進新地圖,畫面卻卡在「Loading...」的進度條前,CPU 明明強得能每秒算上百億次,卻只能乾等資料從儲存裝置慢慢爬過來。
這兩個現象——「斷電後資料還在」與「讀取資料很慢」——背後是計算機系統最核心的一道鴻溝:記憶體階層(memory hierarchy) 與 輸入輸出(I/O) 的世界。本文要談的,正是這個離 CPU 較遠、卻決定整台電腦使用體驗的領域:資料如何被儲存、如何在裝置與處理器之間流動,以及系統如何聰明地避免讓昂貴的 CPU 白白空等。
揮發與非揮發:資料為什麼「記得住」
要理解儲存,先要分清兩種記憶體性質。
揮發性記憶體(volatile memory) 一旦斷電,內容立刻消失。主記憶體 DRAM(動態隨機存取記憶體)就是典型——它靠電容儲存電荷,電荷會持續漏掉,必須不斷「更新(refresh)」才能維持。斷電就等於停止更新,資料瞬間蒸發。CPU 內的暫存器(register)與快取(cache)更是如此。
非揮發性記憶體(non-volatile memory) 則在斷電後仍保留資料。硬碟(HDD)、固態硬碟(SSD)、USB 隨身碟都屬此類。你的遊戲存檔、作業系統、照片之所以關機後還在,正因為它們住在非揮發性的儲存裝置裡。
這個分野解釋了電腦的基本工作流程:程式與資料平時「冷藏」在非揮發的儲存裝置,執行時才被搬進揮發但快速的主記憶體,CPU 再從記憶體(透過快取)取用。整個系統可以畫成一座金字塔:
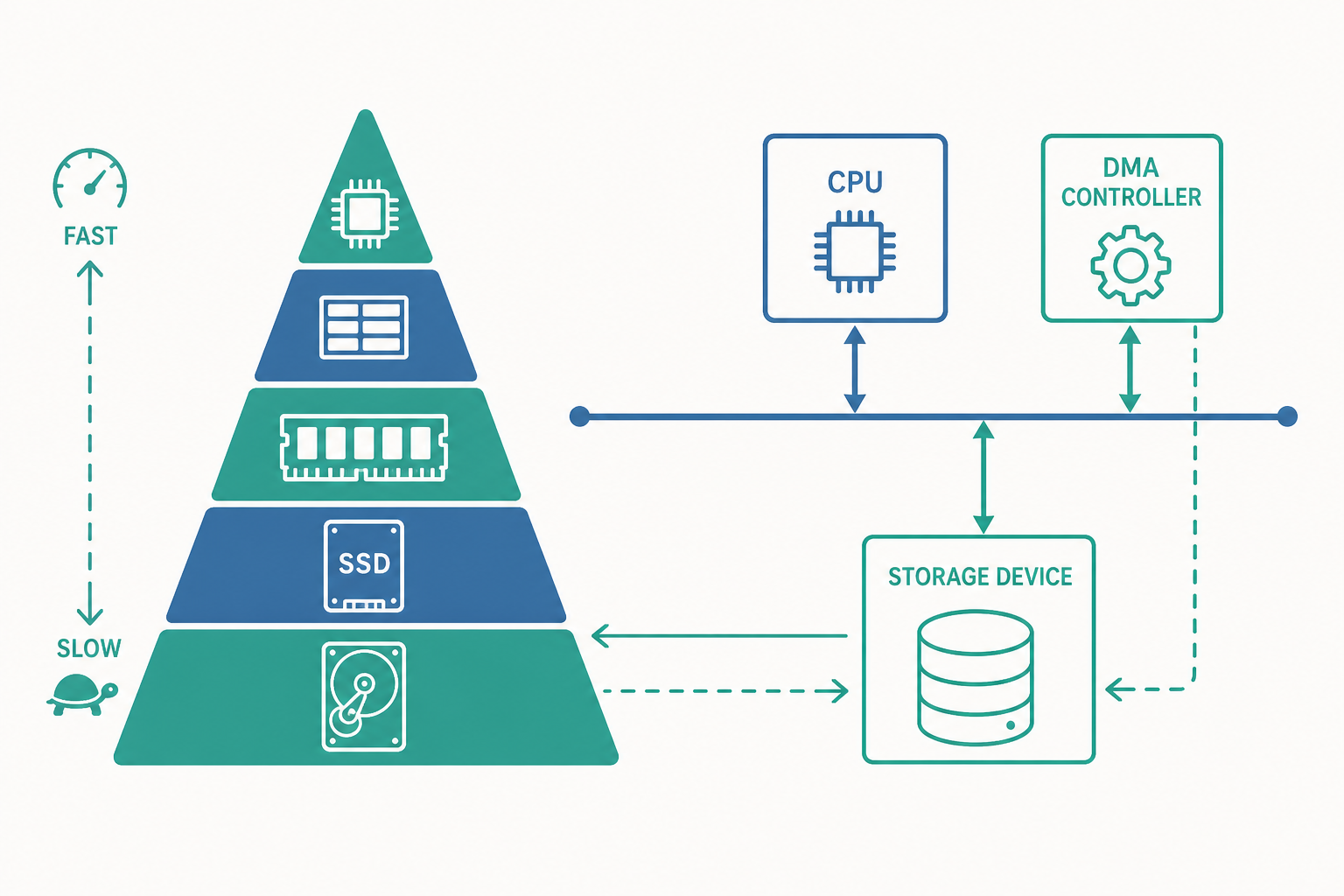
越往上越快、越貴、容量越小(暫存器、快取、DRAM);越往下越慢、越便宜、容量越大(SSD、HDD、磁帶)。設計的藝術,就在於讓常用資料盡量待在上層。
HDD 與 SSD:機械臂與電子閘的對決
非揮發儲存的兩大主角,運作原理天差地別。
機械硬碟(HDD):旋轉的磁碟與飛行的磁頭
HDD 內部是一疊高速旋轉的磁碟片(platter),表面塗有磁性材料。資料以磁化方向(0 或 1)記錄在同心圓的磁軌(track) 上,每條磁軌再切成數個磁區(sector)。一支裝著讀寫頭的磁臂(actuator arm) 在碟片上方數奈米處「飛行」,靠移動到正確磁軌、等待目標磁區轉到磁頭下方來存取資料。
因此 HDD 的存取時間由三部分組成:
- 尋道時間(seek time):磁臂移到目標磁軌的時間,數毫秒。
- 旋轉延遲(rotational latency):等待磁區轉到磁頭下方,與轉速(如 7200 RPM)相關。
- 傳輸時間(transfer time):實際讀寫資料的時間。
關鍵在於:因為牽涉機械移動,HDD 對「隨機存取」特別不友善。讀分散在各處的小檔案,磁臂得來回奔波;而連續讀大檔案則快得多。這就是為什麼磁碟「重組(defragmentation)」對 HDD 有意義。
固態硬碟(SSD):沒有任何活動零件
SSD 用 NAND 快閃記憶體(flash memory) 儲存資料,內部沒有任何機械結構。資料存在由浮閘電晶體(floating-gate transistor)組成的記憶胞中,靠困住電子的有無來表示 0 與 1。沒有磁臂、沒有旋轉,存取任何位置幾乎一樣快,所以 SSD 的隨機存取效能遠勝 HDD。
但 SSD 有其獨特性質:
- 讀寫不對稱:可以對單一頁(page) 讀寫,但抹除(erase) 必須以更大的區塊(block) 為單位進行。要改寫一頁,往往得先搬走整塊資料、抹除、再寫回。
- 寫入次數有限:每個記憶胞能承受的抹寫次數有上限,因此 SSD 控制器會做 磨損平均(wear leveling),把寫入分散到各處,避免某些胞提早報廢。
下表整理兩者差異:
| 特性 | HDD(機械硬碟) | SSD(固態硬碟) |
|---|---|---|
| 儲存原理 | 磁化方向 | 浮閘電晶體電荷 |
| 活動零件 | 有(碟片、磁臂) | 無 |
| 隨機存取 | 慢(受機械限制) | 快 |
| 抗震動 | 弱 | 強 |
| 單位容量成本 | 低 | 較高 |
| 典型延遲 | 毫秒級(ms) | 微秒級(μs) |
| 揮發性 | 非揮發 | 非揮發 |
兩者都是非揮發儲存,但 SSD 的速度讓它成為現代主流,HDD 則因為便宜大容量,仍活躍在資料倉儲與備份場景。
匯流排與週邊:資料的高速公路
裝置之間靠什麼連接?答案是匯流排(bus)——一組共享的傳輸線路,負責在 CPU、記憶體與週邊裝置間搬運資料、位址與控制訊號。
常見的匯流排與介面包括:
- PCIe(PCI Express):連接顯示卡、NVMe SSD 等高速裝置的點對點通道。
- SATA:傳統 HDD 與一般 SSD 的介面。
- USB:通用的外接週邊匯流排(隨身碟、鍵盤、滑鼠)。
- 記憶體匯流排:CPU 與 DRAM 之間的專屬通道。
週邊裝置(peripheral)透過裝置控制器(device controller) 接上匯流排。控制器內含暫存器與緩衝區,作業系統的裝置驅動程式(device driver) 透過讀寫這些暫存器來下達指令、查詢狀態。CPU 不直接和磁碟「對話」,而是透過控制器這個中介。
CPU 如何知道 I/O 做完了?輪詢 vs 中斷
這裡進入本文的核心問題。CPU 速度以奈秒計,而磁碟存取以毫秒計——兩者相差百萬倍。當 CPU 對磁碟發出「讀取」指令後,它要如何得知資料已經備妥?有兩種策略。
輪詢(polling):一直問「好了沒?」
最直接的辦法是讓 CPU 不斷讀取裝置控制器的狀態暫存器,反覆檢查「忙碌中」的旗標是否清除:
loop:
讀取裝置狀態暫存器
若 仍為「忙碌」 → 跳回 loop
否則 → 讀取資料
這就是忙碌等待(busy-waiting)。問題顯而易見:CPU 把寶貴的運算週期全花在「問問題」上,明明可以去執行別的程式,卻被綁在這個迴圈裡空轉。對慢速裝置而言,這是巨大的浪費。
中斷(interrupt):「好了我再叫你」
更聰明的做法是中斷驅動 I/O(interrupt-driven I/O)。CPU 對裝置下達指令後,不再等待,而是繼續執行其他工作。當裝置完成任務時,主動透過一條中斷請求線(IRQ) 通知 CPU。CPU 收到中斷後,暫停手邊工作、保存現場、跳去執行對應的中斷服務常式(ISR, Interrupt Service Routine) 處理結果,處理完再回到原本的工作。
這就像你把衣服丟進洗衣機後不站在旁邊盯著,而是去做別的事,等洗衣機「嗶」一聲再回來收。CPU 因此能在等待 I/O 的漫長時間裡服務其他程式,大幅提升整體吞吐量。這正是多工作業系統能流暢運作的基礎。
動手看一個例子:對比兩種策略的 CPU 浪費
假設一次磁碟讀取需要 10 毫秒(ms),而 CPU 每奈秒(ns)可執行一道指令。
輪詢版本——CPU 在這 10 ms 內全程空轉:
def read_block_polling(controller):
controller.write_command("READ")
while controller.status() == "BUSY": # 忙碌等待
pass # CPU 在此空轉約 10 ms
return controller.read_data()
10 ms = $10 \times 10^6$ ns,意味著 CPU 白白浪費了約一千萬道指令的運算能力。
中斷版本——CPU 發出指令後立刻離開:
def read_block_interrupt(controller):
controller.write_command("READ")
controller.enable_interrupt()
scheduler.switch_to_other_task() # CPU 去做別的事
# 裝置完成後觸發此常式
def disk_isr(controller):
data = controller.read_data()
scheduler.wake_up(waiting_task) # 喚醒原本等待的程式
在這 10 ms 裡,CPU 可以執行其他程式約一千萬道指令,而不是空等。兩種方式的差距,就是現代電腦能同時開瀏覽器、播音樂、下載檔案而不卡頓的原因之一。
那大量資料搬移呢?DMA 登場
中斷解決了「等待」的浪費,但還有一個問題:搬資料這件事本身。
若每讀一個位元組都要 CPU 親自從控制器搬到記憶體,那麼讀一個幾 MB 的檔案,CPU 就得執行數百萬次「搬一格」的動作,依然被綁死。直接記憶體存取(DMA, Direct Memory Access) 正是為此而生。
DMA 是一個獨立的硬體控制器。CPU 只需告訴它三件事:從哪個裝置讀、搬到記憶體哪個位址、搬多少,接著 CPU 就完全放手。DMA 控制器自行接管匯流排,把整批資料直接在裝置與記憶體之間搬運,完全不經過 CPU。整批搬完後,DMA 才發出一次中斷通知 CPU「全部搞定」。
於是,原本可能需要數百萬次中斷與搬移的工作,被壓縮成「下指令 → DMA 自己搬 → 一次中斷收尾」。CPU 在這段期間幾乎完全自由,可以全速執行其他運算。中斷驅動 I/O 讓 CPU 不必空等,DMA 則更進一步讓 CPU 連搬運都不必親自動手——這兩項機制共同把昂貴的處理器從緩慢的 I/O 中徹底解放出來。
重點回顧
- 揮發 vs 非揮發:DRAM、快取斷電即失(揮發);HDD、SSD 斷電仍存(非揮發)。記憶體階層讓資料在快而貴、慢而便宜的層級間流動。
- HDD vs SSD:HDD 靠機械式磁碟與磁臂,隨機存取慢、有尋道與旋轉延遲;SSD 用 NAND 快閃,無活動零件、隨機存取快,但有抹寫單位不對稱與壽命限制。
- 匯流排與週邊:PCIe、SATA、USB 等匯流排連接裝置;CPU 透過裝置控制器與驅動程式間接操控週邊。
- 輪詢 vs 中斷:輪詢讓 CPU 忙碌等待、浪費運算;中斷讓裝置完成後主動通知,CPU 得以去做別的事。
- DMA:把整批資料搬運交給專屬控制器,CPU 只下指令、收一次中斷,徹底從資料搬移中解放。
深入探討(研究所視角)
中斷與 DMA 的代價:cache 一致性與中斷風暴。 DMA 雖然解放了 CPU,卻引入新的一致性問題。當 DMA 直接把新資料寫入主記憶體,CPU 的快取(cache) 中可能仍保留該位址的舊副本,造成 cache 與記憶體不一致。現代系統靠 cache 一致性協定或在 DMA 完成後使快取失效(cache invalidation) 來解決;具備 I/O coherency 的架構則讓 DMA 引擎參與一致性協定。另一方面,在高速網路或高 IOPS 的 NVMe SSD 上,若每個封包或請求都觸發一次中斷,中斷負荷(interrupt overhead) 本身會壓垮 CPU——這稱為 interrupt storm。對策包括 中斷合併(interrupt coalescing),累積數個事件才發一次中斷;以及如 Linux NAPI 的混合策略:高負載時暫時關閉中斷、改用輪詢批次處理封包,低負載時再回到中斷模式,在延遲與吞吐量間取得平衡。
儲存堆疊與作業系統的連結。 從這裡可以延伸到多個研究所層級的主題。檔案系統如何把連續的邏輯區塊對應到實體磁區,直接影響 I/O 效能;針對 SSD 的 FTL(Flash Translation Layer) 與 TRIM 指令,讓作業系統能告知 SSD 哪些區塊已不再使用,配合垃圾回收與磨損平均維持效能與壽命。I/O 排程演算法(如電梯演算法 SCAN、針對 SSD 的 noop/mq-deadline)試圖最佳化請求順序。再往上,虛擬記憶體的分頁(paging)機制把磁碟當成記憶體的延伸,缺頁中斷(page fault)正是一種由 MMU 觸發、依賴 DMA 把頁面從儲存裝置載入的 I/O 事件。
效能模型與 Amdahl 定律的延伸。 當 CPU 被 I/O 解放後,系統瓶頸往往轉移到儲存與匯流排頻寬。以 Little's Law $L = \lambda W$(系統中平均請求數等於到達率乘以平均停留時間)可分析 I/O 佇列行為;而從整體加速比的角度,若 I/O 佔總執行時間比例為 $f$,再快的 CPU 也受限於 Amdahl 定律:
$$S = \frac{1}{(1-f) + \frac{f}{s}}$$
當 $f$ 偏大,提升 CPU 速度($s \to \infty$)的效益會迅速飽和。這正說明了為何現代系統設計把大量心力投注在縮短 I/O 路徑——非揮發記憶體(NVM)、記憶體級儲存(如 NVDIMM)、以及讓裝置直接存取使用者空間的 kernel bypass(如 SPDK、io_uring)——目標都是把資料離 CPU 更近、把中斷與系統呼叫的開銷壓到最低。儲存與 I/O 看似是計算機系統最「邊陲」的一環,卻恰恰是決定整體效能上限的關鍵戰場。