
程式語言演進:從撥開關到一句話
抽象階梯、編譯與直譯、三大典範,以及編譯器內部那條從詞法到產碼的精密流水線
為什麼工程師不直接用 0 和 1 寫程式?
想像你要請一位完全聽不懂中文、只認得電壓高低的機器幫你算帳。最原始的辦法,是把每一個動作都翻成它認得的二進位指令:10110000 01100001。這是一台 1950 年代的程式設計師真實的日常——他們在紙帶上打孔,或在開關面板上一格一格撥動。寫一個迴圈要查表算位址,改一行程式可能整段位移全錯。
今天,我們寫的是 print("Hello, World!")。從撥開關到一句近乎自然語言的指令,這中間發生的事,正是「程式語言演進」的故事。它不只是語法越來越漂亮,而是人類不斷把「對人友善」與「對機器高效」這兩個互相拉扯的目標,往前推進一點點。
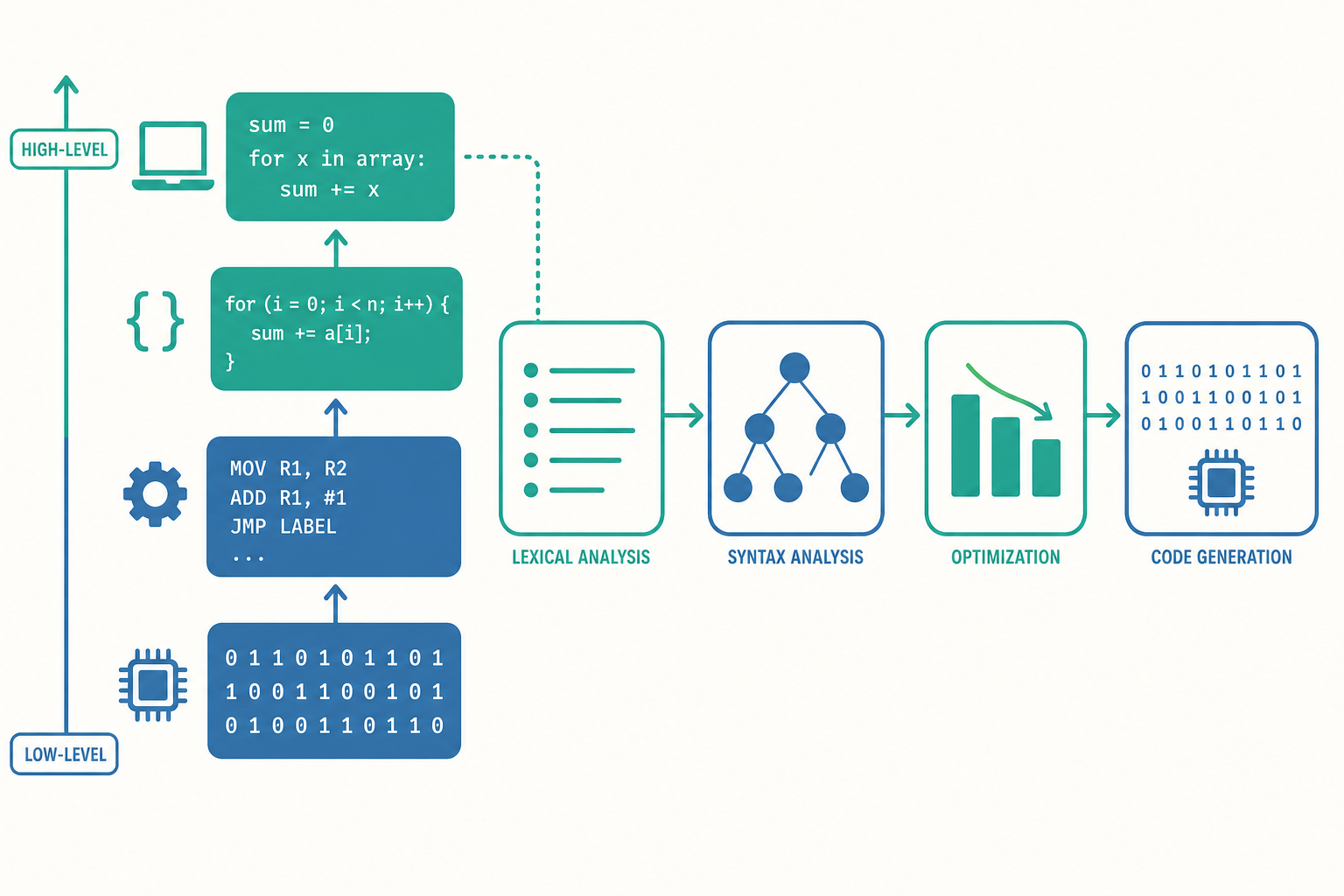
從機器碼到高階語言:抽象階梯
語言的演進,本質是一層層往上疊的抽象(abstraction)。每往上一層,人類就少操心一些機器細節。
- 機器碼(machine code):CPU 直接執行的二進位。完全綁定特定處理器架構,可讀性近乎零。
- 組合語言(assembly):用助記符(mnemonic)取代二進位,例如
MOV、ADD、JMP。它與機器碼幾乎一對一,但人至少看得懂。仍然高度依賴硬體架構。 - 高階語言(high-level language):C、Python、Java 這類,用接近數學與自然語言的方式描述邏輯,不再煩惱暫存器(register)分配與記憶體位址。一行高階程式往往對應數十條機器指令。
我們常說 C 是「低階的高階語言」,因為它一方面有變數、函式、迴圈這些高階結構,另一方面又能直接操作記憶體位址(pointer),貼近硬體。Python 則更「高階」:你幾乎不會碰到記憶體管理,代價是執行速度較慢。
這裡有個關鍵取捨:抽象層級越高,開發效率越高,但通常離硬體越遠、執行成本越高。 沒有哪一層絕對更好,只有適不適合當下的問題。寫作業系統核心你會選 C 或 Rust;做資料分析的原型你會選 Python。
編譯與直譯:程式怎麼變成動作
高階語言終究要變成機器能執行的東西。兩條主要路線是編譯(compilation)與直譯(interpretation)。
| 比較項目 | 編譯式 | 直譯式 |
|---|---|---|
| 代表語言 | C、C++、Rust、Go | Python、Ruby、JavaScript(傳統) |
| 翻譯時機 | 執行前一次翻完整支程式 | 執行時逐行翻譯並執行 |
| 產物 | 可執行檔(executable) | 無獨立產物,靠直譯器 |
| 執行速度 | 快 | 較慢 |
| 跨平台 | 需各平台分別編譯 | 同一份程式碼可跨平台(只要有直譯器) |
| 偵錯回饋 | 編譯期可抓很多錯 | 多數錯誤要執行到才浮現 |
實務上界線是模糊的。Java 是個經典混血:原始碼先被編譯成中介的位元組碼(bytecode),再由 Java 虛擬機(JVM) 在執行時直譯或進一步即時編譯。Python 同樣會先把 .py 編成 .pyc 位元組碼,再交給直譯器跑。所以「編譯 vs 直譯」與其說是語言的固有屬性,不如說是實作(implementation)的選擇。
語言典範:解決問題的不同世界觀
除了「怎麼被執行」,語言還在「怎麼組織思考」上分流,這就是程式設計典範(programming paradigm)。
程序式(procedural):把程式看成一連串步驟與可呼叫的程序(procedure)。C、Pascal 是代表。思維是「先做這個,再做那個」。
物件導向(object-oriented, OO):把資料與操作該資料的方法綁在一起成為「物件」,用封裝(encapsulation)、繼承(inheritance)、多型(polymorphism)管理大型系統的複雜度。Java、C++、Python 都支援。適合模擬現實世界的實體與關係。
函數式(functional):把運算看成數學函式的求值,強調不可變(immutable)資料與純函式(pure function)——同樣輸入永遠得到同樣輸出、沒有副作用(side effect)。Haskell 是純粹代表,而 map、filter、reduce 這些概念如今已滲入幾乎所有主流語言。它在並行(concurrency)場景特別有優勢,因為沒有共享可變狀態就少了很多競爭問題。
現代語言大多是多典範(multi-paradigm)。Python 既能寫程序式腳本,也能物件導向,還能用 lambda 和高階函式做函數式風格。典範不是非此即彼的信仰,而是工具箱裡不同的扳手。
為什麼世界上有這麼多種程式語言?
學習者常問:既然有了 C,為何還要發明 Rust?既然有 Java,為何還要 Kotlin?原因可以歸納為幾股力量:
- 不同問題領域(domain)的需求:統計用 R,系統程式用 C,網頁前端離不開 JavaScript,這些是歷史與生態綁定的結果。
- 取捨點不同:安全 vs 速度、開發效率 vs 執行效率、彈性 vs 嚴格。Rust 想要「C 的速度 + 記憶體安全」,於是設計了所有權(ownership)系統。
- 修正前人的痛點:Kotlin 之於 Java、TypeScript 之於 JavaScript,都是在既有生態上補強型別安全與語法簡潔。
- 硬體與運算模型演進:多核心、GPU、雲端運算催生了對並行與分散式更友善的語言。
換句話說,語言的多樣性不是混亂,而是人類面對不同約束條件下的理性分工。
動手看一個例子:同一件事,三種典範
我們用「把一串數字裡的偶數加總」這件小事,看三種典範怎麼表達。
numbers = [1, 2, 3, 4, 5, 6]
# 程序式:明確描述每一步
total = 0
for n in numbers:
if n % 2 == 0:
total += n
print(total) # 12
# 函數式:用 filter 與 sum 描述「是什麼」而非「怎麼做」
total = sum(filter(lambda n: n % 2 == 0, numbers))
print(total) # 12
# 物件導向:把資料與行為封裝進物件
class NumberBag:
def __init__(self, items):
self.items = items
def sum_even(self):
return sum(n for n in self.items if n % 2 == 0)
bag = NumberBag([1, 2, 3, 4, 5, 6])
print(bag.sum_even()) # 12
三段程式做的事完全相同,但「程序式」告訴電腦怎麼一步步做,「函數式」描述要的結果是什麼,「物件導向」則把資料與操作組織成一個有意義的單位。選哪種,取決於你要解決的問題規模與性質。
編譯流程的內部解剖
前面說編譯器「把高階程式翻成機器碼」,但這句話藏了一個精密的多階段流水線。理解它,你才真正理解語言如何運作。以 total = a + b * 2; 這一行為例,編譯器大致經過以下階段:
1. 詞法分析(lexical analysis)
把字元流切成有意義的詞元(token)。total、=、a、+、b、*、2、; 各成一個 token,並標上類別(識別字、運算子、數字字面量等)。負責這件事的程式叫掃描器(scanner)或 lexer。
2. 語法分析(syntax analysis / parsing) 依照語言的文法規則,把 token 串組裝成抽象語法樹(Abstract Syntax Tree, AST)。乘法優先於加法的規則,會反映在樹的結構上:
=
/ \
total +
/ \
a *
/ \
b 2
若 token 排列違反文法(例如少了分號),就在這裡報語法錯誤。
3. 語意分析(semantic analysis)
檢查「文法對、但意義不通」的問題:變數有沒有宣告?型別相不相容?a + b 中 a 是字串而 b 是整數會在這裡被抓出。這階段會建立並查詢符號表(symbol table)。
4. 中介碼產生與最佳化(optimization)
編譯器先產生與機器無關的中介表示(Intermediate Representation, IR),再在其上做各種最佳化:把 b * 2 在編譯期就算好(常數摺疊 constant folding)、刪掉永遠用不到的程式碼(dead code elimination)、把迴圈內不變的計算移到迴圈外。目標是讓程式更快或更小,同時保證行為等價。
5. 目標碼產生(code generation) 把最佳化後的 IR 翻成特定 CPU 架構的機器碼或組合語言,包含暫存器分配、指令選擇等。
可以把整條流水線想成翻譯一本書:先認字(詞法)、再看懂句子結構(語法)、確認語意通順(語意)、潤飾精煉(最佳化),最後寫成目標語言(產碼)。前端(詞法到語意)與後端(最佳化到產碼)分離的設計,讓同一個前端可以接多個硬體後端——這正是 LLVM 這類現代編譯器框架的核心精神。
即時編譯(JIT):兩條路線的融合
純編譯快但不靈活,純直譯靈活但慢。即時編譯(Just-In-Time compilation, JIT) 試圖兼得兩者之長。
它的做法是:程式先以位元組碼直譯執行,執行期間 JIT 持續觀察哪些程式碼被反覆執行(稱為熱點 hot spot)。一旦某段程式夠「熱」,JIT 就在執行當下把它編譯成原生機器碼,之後再跑到該段就直接執行高速版本。
JIT 的妙處在於它能利用執行期才知道的資訊做最佳化——例如某個多型呼叫實際上幾乎都走同一型別,JIT 可據此做投機最佳化(speculative optimization),這是傳統靜態編譯器做不到的。JVM 的 HotSpot、JavaScript 的 V8 引擎、Python 的 PyPy 都靠 JIT 大幅提速。代價是需要暖機時間(warm-up)與額外記憶體,所以短命的小腳本反而不一定划算。
重點回顧
- 程式語言的演進,核心是不斷提高抽象層級:從機器碼、組合語言到高階語言,讓人少操心硬體、多專注問題本身,代價通常是執行效率。
- 編譯與直譯是「翻譯時機」的差異,而非語言的固有本質;Java、Python 等其實是「先編譯成位元組碼、再直譯/JIT」的混血路線。
- 三大典範——程序式、物件導向、函數式——是組織思考的不同世界觀,現代語言多為多典範,典範是工具而非信仰。
- 語言多樣性源自領域需求、取捨點、修正前人痛點、硬體演進,是理性分工而非混亂。
- 編譯器是一條五階段流水線:詞法→語法→語意→最佳化→產碼;而 JIT 在執行期針對熱點動態編譯,融合了編譯與直譯的優點。
深入探討(研究所視角)
形式語言與可計算性的根基。 詞法分析背後是正規語言(regular language)與有限狀態自動機(finite automaton),語法分析則對應上下文無關文法(context-free grammar, CFG)與下推自動機(pushdown automaton)。這正是 Chomsky 文法層級(Chomsky hierarchy)在編譯器中的具體落實:lexer 用正規表達式可解,parser 需要堆疊(stack)能力。理解這層次,也就理解了「為什麼巢狀括號配對無法只用正規表達式處理」這類經典問題。更上層,所有圖靈完備(Turing-complete)的語言在計算能力上等價——語言之間的差異不在「能算什麼」,而在「表達是否優雅、執行是否高效、錯誤是否易防」。
型別系統與程式正確性。 型別理論(type theory)是程式語言研究最活躍的領域之一。Curry–Howard 同構(Curry–Howard correspondence)揭示了一個深刻對應:型別即命題,程式即證明。一個能通過型別檢查的程式,某種意義上就是一個成立的數學證明。這催生了 Coq、Agda 等依賴型別(dependent type)語言,讓程式正確性可被形式化驗證。Rust 的所有權與借用檢查(borrow checker)則是把線性型別(linear type)的思想工程化,在編譯期消除資料競爭(data race)與懸空指標(dangling pointer),這是把研究成果落地到主流系統語言的範例。
最佳化的理論邊界與 SSA。 現代編譯器最佳化大量建立在靜態單賦值形式(Static Single Assignment, SSA)上:每個變數只被賦值一次,使資料流分析(data-flow analysis)大幅簡化。許多分析本質上是在程式的控制流圖(control-flow graph)上求不動點(fixed point)。然而最佳化有理論天花板——由 Rice 定理(Rice's theorem),程式的多數非平凡語意性質是不可判定(undecidable)的,所以編譯器只能做保守的近似分析,永遠無法「完美最佳化」。
與其他主題的連結。 編譯器將高階語言映射到指令集架構(ISA),是計算機組織與作業系統的橋樑;JIT 的熱點偵測本質上是一種輕量級程式剖析(profiling)與線上決策,與系統效能調校相通;而語言的記憶體模型(memory model)直接決定了並行程式在多核心下的正確性,連向分散式系統與並行理論。把「程式語言」當成獨立科目其實低估了它——它是把抽象數學、硬體現實與工程實踐縫合在一起的接點。當你下一次寫下 print("Hello, World!"),背後是七十年抽象階梯與一整個形式科學的支撐。