
加密與雜湊(進階)
正確的演算法為何仍會被攻破——從操作模式、認證加密到可證明安全與旁路攻擊
為什麼「正確的演算法」還是會被攻破?
你已經知道 AES-256 是業界公認極為安全的對稱加密,金鑰空間 $2^{256}$ 大到暴力破解毫無希望。可是請看下面這段真實世界曾反覆發生的災難:兩位工程師都正確地呼叫了 AES,金鑰也沒外洩,系統卻被攻破了。
# 兩段「都用了 AES-256」的程式碼,安全性卻天差地遠
from Crypto.Cipher import AES
key = b"0123456789abcdef0123456789abcdef" # 32 bytes = AES-256
# 寫法 A:ECB 模式
cipher_a = AES.new(key, AES.MODE_ECB)
# 寫法 B:CTR 模式,但每次都用同一個 nonce
cipher_b = AES.new(key, AES.MODE_CTR, nonce=b"\x00" * 8)
這兩段程式碼的金鑰都無懈可擊,卻都會洩漏明文資訊。入門篇告訴你「用 AES 就對了」,但真正的資安事故,九成不是演算法被數學破解,而是演算法被『錯誤地組裝』。這篇進階文章不再重複對稱/非對稱/雜湊的基礎,而是帶你進入密碼學工程的核心難題:模式(mode)、認證(authentication)、與可證明安全(provable security)。
區塊密碼的真相:AES 只是一個 16 位元組的置換
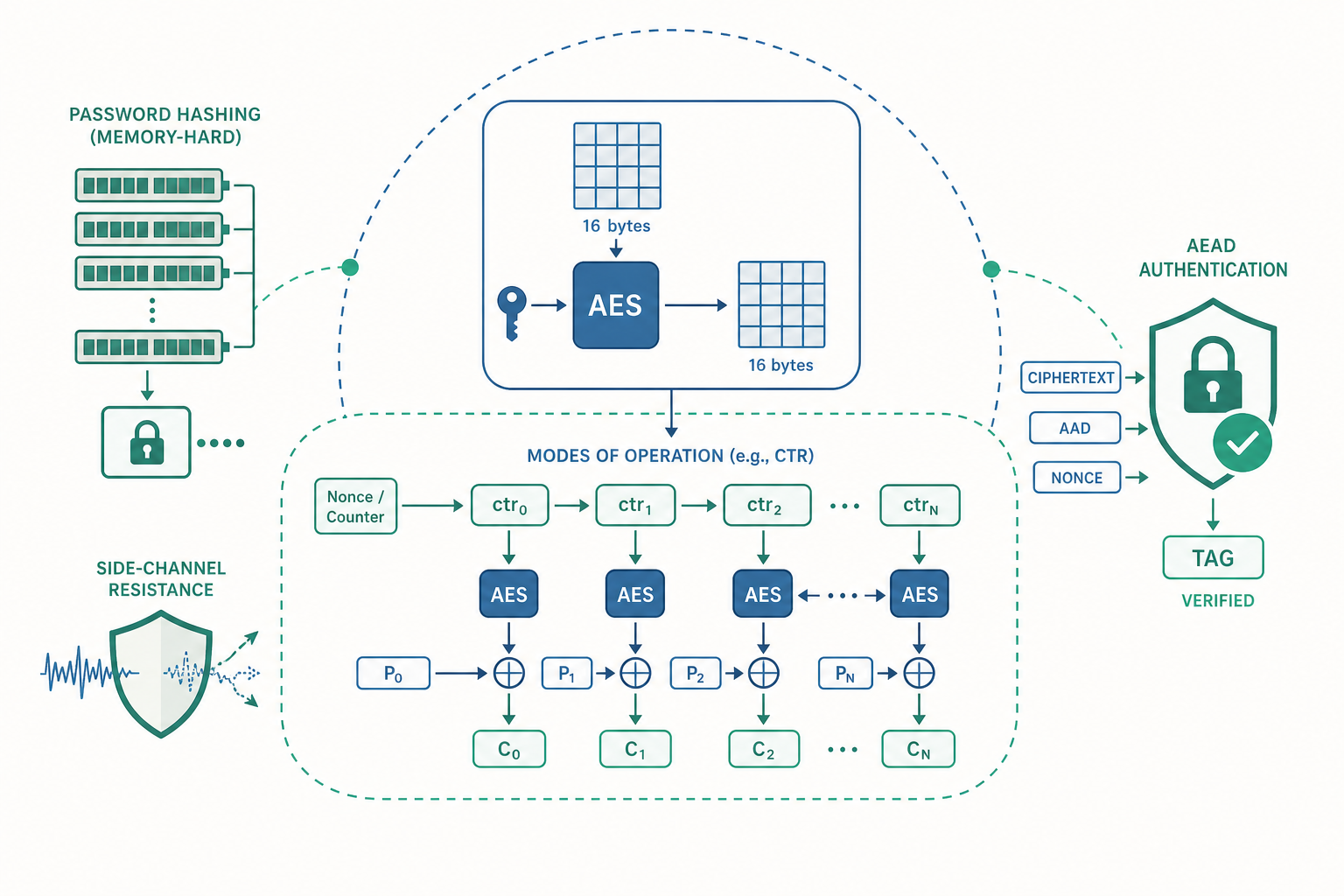
入門篇把 AES 當成一個「加密整份檔案」的黑盒子,但這其實是誤解。AES 本身是一個區塊密碼(block cipher):它一次只處理固定 128 位元(16 位元組)的資料區塊,把一個 16 位元組的明文區塊,在金鑰控制下,雙射(bijective) 地映射成一個 16 位元組的密文區塊。
換句話說,對一把固定的金鑰 $K$,AES 定義的是一個從 $\{0,1\}^{128}$ 到 $\{0,1\}^{128}$ 的置換(permutation):
$$ E_K : \{0,1\}^{128} \to \{0,1\}^{128} $$
問題來了:真實檔案動輒幾 MB,遠超過 16 位元組。要怎麼用「只能吃 16 位元組」的 AES 去加密任意長度的資料?答案就是操作模式(mode of operation)——它決定了區塊與區塊之間如何串接。而所有的安全差異,都發生在這一層。
ECB 為什麼是教科書級的反面教材
最天真的做法叫 ECB(Electronic Codebook):把明文切成 16 位元組區塊,每塊獨立用同一把金鑰加密。
明文: [P1][P2][P3][P4] ...
↓Eₖ ↓Eₖ ↓Eₖ ↓Eₖ
密文: [C1][C2][C3][C4] ...
致命缺陷在「確定性」:因為 $E_K$ 是固定置換,相同的明文區塊一定產生相同的密文區塊。如果你的資料裡有重複的 pattern(圖片的大片同色、結構化文件的固定欄位),這些 pattern 會原封不動地保留在密文裡。
最有名的示範是「ECB 企鵝」:把一張 Linux 吉祥物 Tux 圖片用 ECB 加密,企鵝的輪廓依然清晰可辨——因為大片相同顏色的區塊都被加密成相同的密文。我們用程式碼量化這個洩漏:
from Crypto.Cipher import AES
key = b"0123456789abcdef" # AES-128
cipher = AES.new(key, AES.MODE_ECB)
# 兩個一模一樣的 16-byte 區塊
plaintext = b"SAME_BLOCK_16BYT" * 2 # 32 bytes
ct = cipher.encrypt(plaintext)
print(ct[:16] == ct[16:32]) # True ← 災難!密文洩漏了「這兩塊相同」
攻擊者不需要解密,光是觀察「哪些密文區塊相同」,就能推斷明文結構。這就是為什麼 ECB 在任何嚴肅場景都是禁用的。
從 IV 到 nonce:用隨機性打破確定性
修正方向很清楚:讓相同的明文每次加密都產生不同的密文。做法是引入一個額外的隨機輸入——初始向量(IV, Initialization Vector) 或 nonce(number used once)。
以 CTR(Counter) 模式為例,它把區塊密碼變成串流密碼(stream cipher):不直接加密明文,而是用 AES 加密「nonce + 遞增計數器」產生一段金鑰流(keystream),再把金鑰流和明文 XOR。
$$ C_i = P_i \oplus E_K(\text{nonce} \,\|\, i) $$
from Crypto.Cipher import AES
from Crypto.Util import Counter
import os
key = b"0123456789abcdef"
nonce = os.urandom(8) # 每次加密都要全新隨機 nonce
ctr = Counter.new(64, prefix=nonce, initial_value=0)
cipher = AES.new(key, AES.MODE_CTR, counter=ctr)
ct = cipher.encrypt(b"SAME_BLOCK_16BYT" * 2)
print(ct[:16] == ct[16:32]) # False ← 同樣明文,密文不同了
但這裡藏著一個比 ECB 更隱蔽、也更常見的陷阱——nonce 絕對不能重複使用。回顧開頭寫法 B 的災難:若兩段不同明文 $P$、$P'$ 用了相同的金鑰與相同的 nonce,金鑰流 $K_s = E_K(\text{nonce}\|i)$ 就完全一樣,於是:
$$ C \oplus C' = (P \oplus K_s) \oplus (P' \oplus K_s) = P \oplus P' $$
金鑰流被消掉了!攻擊者不需要金鑰,光把兩段密文 XOR,就得到兩段明文的 XOR。對自然語言或結構化資料,$P \oplus P'$ 往往足以還原原文。這正是二戰時蘇聯的 VENONA 計畫破譯「一次性密碼本」的原理——重複使用密碼本(等同 nonce reuse)讓本應完美的加密功虧一簣。現代的 WEP Wi-Fi 加密、以及多起雲端儲存事故,根因都是 nonce/IV 重用。
工程鐵律:CTR、GCM 這類模式裡,「金鑰 + nonce」的組合一生只能用一次。常見做法是用隨機 nonce(搭配足夠長度避免生日碰撞)或嚴格遞增的計數器。
加密 ≠ 安全:認證加密(AEAD)的崛起
到目前為止我們只解決了「保密(confidentiality)」——讓攻擊者讀不懂。但有一個入門篇容易忽略的致命盲點:CTR 模式的密文是可以被任意竄改的。
因為 $C_i = P_i \oplus K_s$,攻擊者即使不知道金鑰,只要翻轉密文裡的某個位元,解密後對應位置的明文位元就會跟著翻轉。這叫位元翻轉攻擊(bit-flipping attack):
# 攻擊者攔截到一筆 CTR 密文,想把 "PAY 0100" 改成 "PAY 9100"
# 他不需要金鑰,只要知道明文格式,XOR 對應位置即可
delta = ord('0') ^ ord('9') # 想改的位元差
forged = bytearray(ct)
forged[pos] ^= delta # 翻轉第 pos 個 byte
# 解密後明文就從 0 變成 9,金額被竄改,且解密端毫無察覺
光加密無法察覺竄改。所以現代密碼學的標準答案是 AEAD(Authenticated Encryption with Associated Data):在加密的同時,附帶一個密碼學「驗證標籤(authentication tag)」,解密前先驗證標籤;標籤對不上就直接拒絕解密,連密文都不碰。
主流選擇是 AES-GCM(Galois/Counter Mode) 與 ChaCha20-Poly1305。它們同時提供:
- 機密性:底層用 CTR 式的串流加密。
- 完整性 + 真實性:用一個 MAC(GCM 用 GHASH,基於有限體 $GF(2^{128})$ 上的多項式運算)產生標籤。
- AAD(Associated Data):可以「驗證但不加密」的欄位,例如封包標頭、路由資訊——需要被防竄改,但本身不是祕密。
from Crypto.Cipher import AES
import os
key = os.urandom(32)
nonce = os.urandom(12) # GCM 標準 nonce 長度 96 bits
cipher = AES.new(key, AES.MODE_GCM, nonce=nonce)
cipher.update(b"header:transfer") # AAD:驗證但不加密
ct, tag = cipher.encrypt_and_digest(b"PAY 0100 to Bob")
# === 解密端 ===
dec = AES.new(key, AES.MODE_GCM, nonce=nonce)
dec.update(b"header:transfer")
try:
pt = dec.decrypt_and_verify(ct, tag) # tag 不符會丟 ValueError
print("驗證通過:", pt)
except ValueError:
print("竄改偵測!拒絕解密") # 位元翻轉攻擊在此被擋下
這也是為什麼 TLS 1.3 把所有非 AEAD 的密碼套件全部移除——「先加密、再另外算 MAC」這種拼裝法歷史上踩過太多坑(如 MAC-then-Encrypt 的順序錯誤導致 padding oracle 攻擊,著名的 POODLE、Lucky 13)。AEAD 把加密與認證綁成一個不可分割的原語,從設計層面消滅了這類組合錯誤。
動手算一下:為什麼「先 MAC 還是先加密」很重要
密碼學界有個經典結論:組合加密與 MAC 有三種順序,安全性截然不同。
| 組合方式 | 代表協定 | 安全性 |
|---|---|---|
| Encrypt-then-MAC(先加密,對密文算 MAC) | IPsec | ✅ 可證明安全(推薦) |
| MAC-then-Encrypt(先對明文算 MAC,再一起加密) | 舊版 TLS | ⚠️ 視情況,易出 padding oracle |
| Encrypt-and-MAC(各自獨立) | 舊版 SSH | ⚠️ MAC 可能洩漏明文資訊 |
關鍵直覺:Encrypt-then-MAC 讓接收方能在解密前就驗證密文真偽。標籤一對不上立刻丟棄,攻擊者送來的任何竄改密文根本沒機會進到解密邏輯,也就無從利用解密過程的時間差或錯誤訊息(這正是 padding oracle 攻擊的養分)。記住這個順序,是密碼工程的基本功。
密碼儲存的軍備競賽:為什麼 SHA-256 不夠
入門篇提到「密碼要加鹽雜湊,別用 MD5」。進階一層的問題是:為什麼連又快又安全的 SHA-256 都不適合存密碼?
答案恰恰是「快」。SHA-256 設計目標是高速處理大量資料——現代 GPU 一秒能算上百億次 SHA-256。對驗證檔案完整性,快是優點;對抵禦密碼破解,快是致命傷。攻擊者拿到資料庫後,可以每秒嘗試幾十億個候選密碼做暴力/字典攻擊。
加鹽(salt)只解決了一個問題——讓彩虹表(rainbow table)失效,並讓相同密碼的不同使用者有不同雜湊。但加鹽完全不會減慢單一密碼的猜測速度。
真正的解法是刻意放慢、且難以平行化的密碼雜湊函數。它們的設計哲學是「對防守方慢一點點沒差,對攻擊方的成本卻成倍放大」:
- bcrypt:可調整 work factor(迭代次數指數成長)。
- scrypt:引入記憶體困難(memory-hard)——強迫演算法佔用大量 RAM,讓專用硬體(ASIC/GPU)難以靠堆疊算力佔便宜,因為記憶體比算力貴。
- Argon2:2015 年密碼雜湊競賽(PHC)冠軍,目前的首選。同時可調時間成本、記憶體成本、平行度三個維度。
# 推薦做法:用 Argon2 存密碼
from argon2 import PasswordHasher
ph = PasswordHasher(
time_cost=3, # 迭代次數
memory_cost=65536, # 佔用 64 MB 記憶體 ← memory-hard 的關鍵
parallelism=4
)
hashed = ph.hash("user_password") # 內含演算法、參數、salt,全包在輸出字串裡
print(hashed)
# $argon2id$v=19$m=65536,t=3,p=4$<salt>$<digest>
# 驗證
try:
ph.verify(hashed, "user_password") # 正確
print("登入成功")
except Exception:
print("密碼錯誤")
注意 Argon2 的輸出自帶 salt 與參數,未來想調高成本只要改參數重新雜湊即可。設計密碼系統時,請務必使用這類函數,而非裸 SHA-256——這是現代後端的基本義務。
HMAC:別自己拿雜湊湊 MAC
順帶釐清一個常見的危險迷思。很多人想做「訊息認證」時,會天真地寫 SHA256(key || message),以為把金鑰接在前面就能防偽。但這對 MD5/SHA-1/SHA-256 這類 Merkle–Damgård 結構的雜湊不安全,會遭受長度延伸攻擊(length-extension attack):攻擊者不需金鑰,就能在已知的 (message, tag) 後面追加內容並算出有效的新 tag。
正確做法是 HMAC(Hash-based MAC),它用巢狀的雙重雜湊結構從數學上封死這個漏洞:
$$ \text{HMAC}(K, m) = H\big((K \oplus opad) \,\|\, H((K \oplus ipad) \,\|\, m)\big) $$
import hmac, hashlib
key = b"secret_key"
msg = b"transfer 1000 to Bob"
tag = hmac.new(key, msg, hashlib.sha256).hexdigest()
# 驗證務必用 compare_digest(常數時間比對,防 timing 攻擊)
ok = hmac.compare_digest(tag, received_tag)
特別留意最後一行的 compare_digest:比對 MAC 時絕不能用普通的 ==。普通字串比對發現第一個不同位元就提前返回,攻擊者能透過測量回應時間,一個位元組一個位元組地猜出正確標籤——這叫時序攻擊(timing attack)。compare_digest 保證常數時間比對,無論差在哪都跑完全程。
重點回顧
- AES 本身只是一個 16 位元組區塊的置換,安全性取決於操作模式;ECB 因確定性洩漏明文結構,任何場景皆禁用。
- nonce/IV 提供必要的隨機性,但在 CTR/GCM 中「金鑰 + nonce」重用會讓金鑰流相消($C \oplus C' = P \oplus P'$),是比 ECB 更隱蔽的致命錯誤。
- 加密 ≠ 安全:純加密無法防竄改(位元翻轉攻擊)。現代標準是 AEAD(AES-GCM、ChaCha20-Poly1305),加密與認證綁成一體,且 Encrypt-then-MAC 是唯一穩妥的組合順序。
- 存密碼要用 Argon2/bcrypt/scrypt 這類刻意放慢、記憶體困難的函數,裸 SHA-256 太快不適合;加鹽只擋彩虹表,不減慢猜測。
- MAC 要用 HMAC(防長度延伸攻擊),且比對標籤必須用常數時間比對防時序攻擊。
深入探討(研究所視角)
可證明安全:IND-CPA 與 IND-CCA
前面我們靠「攻擊舉例」說明哪些做法不安全,但這在學術上不夠嚴謹——沒被攻破不代表安全。現代密碼學的基石是可證明安全(provable security):把「安全」定義成一個攻擊者與挑戰者之間的遊戲(security game),再證明任何多項式時間攻擊者贏的機率,最多只比亂猜($1/2$)多出一個可忽略(negligible) 的優勢。
最基本的目標是 IND-CPA(Indistinguishability under Chosen-Plaintext Attack),選擇明文攻擊下的不可區分性:
IND-CPA 遊戲:
1. 挑戰者產生金鑰 K(攻擊者不知道)
2. 攻擊者可任意挑選明文,請挑戰者加密(oracle access)
3. 攻擊者交出兩段等長明文 m₀, m₁
4. 挑戰者隨機選 b ∈ {0,1},回傳 Enc(K, m_b)
5. 攻擊者猜 b。若優勢 |Pr[猜對] − 1/2| 可忽略,則方案達 IND-CPA
這個定義立刻解釋了為何 ECB 不安全:因為它是確定性的,攻擊者只要在步驟 2 預先問過 $m_0$、$m_1$ 的加密,步驟 4 一比對就 100% 知道 $b$。確定性加密永遠無法達到 IND-CPA——這就是為什麼隨機 IV/nonce 不是選配,而是達標的數學必要條件。
更強的目標是 IND-CCA2(Chosen-Ciphertext Attack):攻擊者連「挑選密文請挑戰者解密」的能力都有(除了挑戰密文本身)。AEAD 之所以重要,正是因為它能達到 IND-CCA2——位元翻轉攻擊在這個框架下,對應的就是「攻擊者送竄改密文去問解密 oracle」,而 AEAD 的標籤驗證讓 oracle 對所有非法密文一律回「拒絕」,攻擊者什麼資訊都套不出來。
隨機諭示模型與安全歸約
雜湊函數在許多安全證明裡被理想化成隨機諭示(Random Oracle, RO):一個對每個新輸入都回傳真正均勻隨機輸出的黑盒。RSA-OAEP、許多簽章方案的安全性都是在 RO 模型下證明的。
證明的核心技巧是歸約(reduction):假設存在一個能破解我方案的攻擊者 $\mathcal{A}$,就用 $\mathcal{A}$ 當子程式,建構出一個能解某個公認困難問題(如大整數分解、離散對數)的演算法。由於那個問題被假設為難解,矛盾,故 $\mathcal{A}$ 不存在。形式上,破解我方案的優勢被「歸約」到困難問題的優勢:
$$ \mathbf{Adv}^{\text{scheme}}(\mathcal{A}) \le \mathbf{Adv}^{\text{hard-problem}}(\mathcal{B}) + \text{negligible} $$
但 RO 模型有個著名的理論裂縫:Canetti–Goldreich–Halevi(2004) 證明存在某些方案,在 RO 模型下可證安全,但用任何真實雜湊函數實例化後都不安全。這提醒我們,「在 RO 下安全」是有用但非萬無一失的啟發式保證。這也是為什麼近年密碼學界更青睞標準模型(standard model) 下的證明,以及為什麼後量子時代的格密碼(lattice-based)方案,會盡量把安全性歸約到 LWE(Learning With Errors) 這類有 worst-case 到 average-case 歸約保證的問題上。
旁路攻擊:當數學完美但實作會「漏電」
最後一個研究生必須建立的世界觀:即使演算法在數學上可證明安全、實作也完全正確,物理世界仍可能洩密。這類旁路攻擊(side-channel attack) 不攻擊數學,而是攻擊運算過程在現實中留下的痕跡:
- 時序(timing):運算時間隨祕密資料變化(前面
compare_digest防的就是這個;RSA 的模冪運算若不做防護也會洩漏私鑰位元)。 - 功耗(power analysis):用示波器量晶片耗電,差分功耗分析(DPA)曾從智慧卡萃取出完整 AES 金鑰。
- 快取(cache-timing):透過 CPU 快取命中與否的時間差,跨虛擬機竊取共用主機上他人的金鑰。
- 故障注入(fault injection):刻意用電壓毛刺或雷射讓晶片算錯,從錯誤輸出反推私鑰(對 RSA-CRT 特別致命)。
防禦之道是常數時間程式設計(constant-time programming)——確保執行路徑、記憶體存取模式、運算時間都與祕密資料無關。這也是 cryptography、libsodium 這類函式庫存在的根本理由:它們把這些極易出錯、與直覺相違的工程細節封裝好。給未來工程師的最後一句箴言依然是密碼學界的鐵律——Don't roll your own crypto(別自己造密碼學輪子)。不是因為你不懂數學,而是因為從可證明安全的紙面,到不洩漏旁路的矽晶片之間,隔著無數個能讓整套系統崩潰的工程陷阱。