
為什麼 0.1 + 0.2 不等於 0.3?Python 數值與變數的底層真相
從 IEEE 754 浮點近似、任意精度整數、dunder 方法到作用域綁定與可變預設參數,看穿型別與運算子背後的物件模型
為什麼 0.1 + 0.2 不等於 0.3?
打開 Python 直譯器,敲下這一行,你會看到一個令人困惑的結果:
print(0.1 + 0.2) # 輸出:0.30000000000000004
print(0.1 + 0.2 == 0.3) # 輸出:False
這不是 Python 的 bug,也不是你的電腦壞了。這是幾乎所有現代程式語言共有的現象,根源在於電腦如何用有限的位元去「逼近」一個無限的小數。入門篇我們學會了 int、float、str、bool 怎麼用;這一篇要往下挖一層,看清這些型別在記憶體裡到底長什麼樣、運算子背後其實是哪個方法在運作,以及「名字綁到值」這句話在函式與作用域裡會生出哪些精緻而危險的細節。讀完之後,你對 Python 數值與變數的理解,會從「會寫」進化到「知道為什麼這樣寫」。
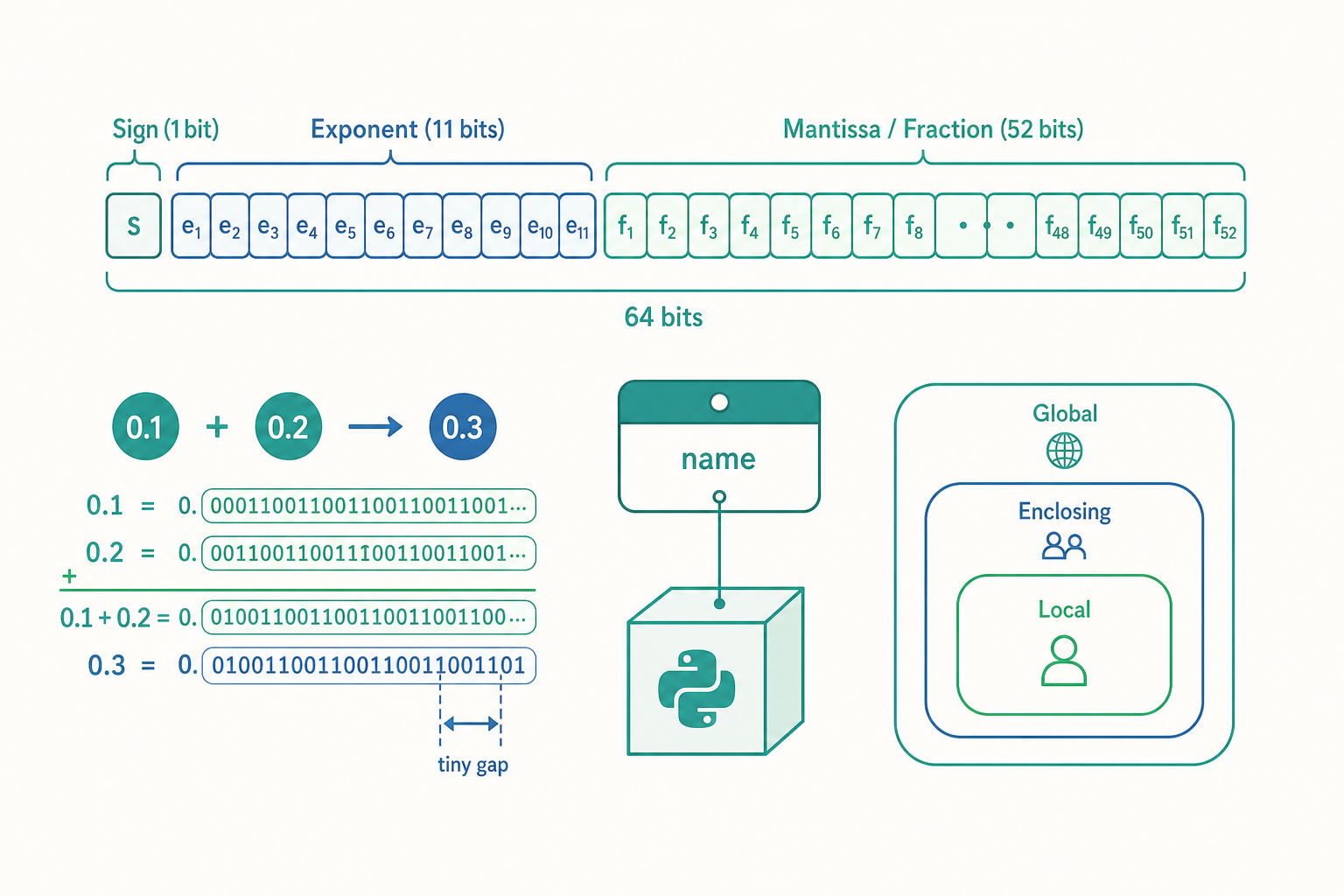
浮點數的真相:IEEE 754 與二進位分數
float 在絕大多數平台上是 64 位元的 IEEE 754 雙精度浮點數(double-precision floating point)。這 64 個位元被切成三段:1 個符號位元(sign)、11 個指數位元(exponent)、52 個尾數位元(mantissa / fraction)。它表示的數值大致是:
$$ (-1)^{\text{sign}} \times 1.\text{mantissa} \times 2^{\text{exponent} - 1023} $$
關鍵在於「尾數是二進位分數」。十進位裡的 $0.1$ 換成二進位,是一個無限循環小數:$0.0001100110011\ldots_2$,就像十進位無法精確寫出 $1/3 = 0.333\ldots$ 一樣。電腦只有 52 個尾數位元,只能在某處截斷,於是存進去的 0.1 其實是一個非常接近、但不完全等於 $0.1$ 的值。
要看清這件事,可以請 Python 印出更多位數:
from decimal import Decimal
print(Decimal(0.1))
# 輸出:0.1000000000000000055511151231257827021181583404541015625
那一長串就是 0.1 這個 float 在記憶體中「真正」代表的值。0.1、0.2、0.3 各自都有微小誤差,相加之後誤差累積,於是 0.1 + 0.2 落在比 0.3 大一點點的位置。
動手算一下:誤差從哪裡冒出來
print(0.1.hex()) # 輸出:0x1.999999999999ap-4
print(0.3.hex()) # 輸出:0x1.3333333333333p-2
print((0.1 + 0.2).hex()) # 輸出:0x1.3333333333334p-2
注意最後一位:0.3 本身結尾是 ...333,而 0.1 + 0.2 結尾是 ...334,差了一個最小單位(ULP, unit in the last place)。這個 1 ULP 的差距,就是 == 判定為 False 的全部原因。
正確的浮點數比較不該用 ==,而要看「差距是否夠小」。Python 標準函式庫提供了現成工具:
import math
print(math.isclose(0.1 + 0.2, 0.3)) # 輸出:True
# 它預設用相對誤差 1e-9 判斷兩數是否「足夠接近」
如果你的應用真的需要十進位精確(例如金錢計算、財務報表、計費系統),就不要用 float,改用 decimal.Decimal:
from decimal import Decimal
print(Decimal("0.1") + Decimal("0.2")) # 輸出:0.3 完全精確
注意要傳字串 "0.1" 而非 0.1——如果傳浮點數,誤差在進到 Decimal 之前就已經產生了。這也是一個重要的工程教訓:選型別不是隨便挑一個能裝下數字的就好,而要先問「這個情境能不能容忍微小誤差」。科學計算追求速度,浮點誤差通常可接受;金融與計費追求精確,一分錢都不能錯,這時 float 反而是錯誤的選擇。同一筆「金額」,在不同情境下該用不同型別承載——這正是把型別當成「設計決策」而非「語法細節」的成熟視角。
整數沒有上限:Python 大整數的祕密
入門篇提過 Python 整數「可以無限大」。這在 C、Java 裡是不可思議的——那些語言的 int 通常是 32 或 64 位元,超過上限會溢位(overflow),悄悄變成錯誤的負數。Python 怎麼辦到的?
答案是:Python 的 int 不是固定寬度的硬體整數,而是一種任意精度整數(arbitrary-precision integer / bignum)。當數值小時,它存在固定大小的欄位裡;一旦超過機器字長,CPython 會自動改用一個「digit 陣列」來存,需要多少位數就配多少記憶體。代價是大整數的運算比硬體整數慢,但好處是你永遠不必擔心溢位。
x = 2 ** 1000
print(x.bit_length()) # 輸出:1001(這個數要 1001 個位元才裝得下)
print(len(str(x))) # 輸出:302(十進位有 302 位數)
這也解釋了為什麼 int 與 float 行為差這麼多:float 受 IEEE 754 的 64 位元限制,超過約 $1.8 \times 10^{308}$ 就變成 inf,而且精度只有約 15–17 位有效數字;int 則精確到最後一位、要多大有多大。
print(2.0 ** 1000) # 輸出:1.0715086071862673e+301(float,已失去精度)
print(10 ** 400 > 0) # 輸出:True(int,毫無問題)
print(1e400) # 輸出:inf(float 溢位)
所以涉及大數或需要精確整數時,務必待在 int 的世界裡,別讓中途某個 / 或小數把它「降格」成 float。
數值塔:int、float、complex 的層級
Python 的數值型別不是各自為政,而是組成一座數值塔(numeric tower),由窄到寬依序是:int ⊂ float ⊂ complex(標準函式庫的 Fraction 和 Decimal 另成體系)。當不同型別一起運算時,Python 會自動把「窄」的往「寬」的方向轉,這叫型別升級(type coercion / promotion):
print(type(3 + 4.0)) # 輸出:<class 'float'> int 升級成 float
print(type(3 + 2j)) # 輸出:<class 'complex'> 出現複數就升到 complex
print(3 + 2j) # 輸出:(3+2j)
complex 是 Python 內建的複數型別,j 代表虛數單位。這在訊號處理、電路分析、量子計算等領域非常實用:
z = 3 + 4j
print(z.real, z.imag) # 輸出:3.0 4.0
print(abs(z)) # 輸出:5.0(複數的模 = sqrt(3^2 + 4^2))
如果你需要的是「精確的分數」而不是浮點近似,fractions.Fraction 會幫你保留有理數的精確性:
from fractions import Fraction
print(Fraction(1, 3) + Fraction(1, 6)) # 輸出:1/2 完全精確,沒有浮點誤差
理解這座塔,你就能預測任何混合運算的結果型別,也能在「速度」(float)、「精確」(Decimal/Fraction)、「範圍」(int)之間做出有意識的選擇。
運算子的真面目:每個符號背後都是一個方法
入門篇把 +、-、* 當成理所當然的符號。但在 Python 裡,運算子其實是方法呼叫的語法糖(syntactic sugar)。當你寫 a + b,Python 實際上是去呼叫 a.__add__(b),這些以雙底線包夾的方法叫做特殊方法 / dunder 方法(dunder methods,"double underscore")。
print((3).__add__(4)) # 輸出:7 等同 3 + 4
print("ab".__mul__(3)) # 輸出:ababab 等同 "ab" * 3
print([1, 2].__len__()) # 輸出:2 等同 len([1, 2])
這套機制就是為什麼「同一個 +」對數字是加法、對字串是串接、對串列是拼接——因為每種型別各自定義了自己的 __add__。Python 把比較、長度、索引、迭代等幾乎所有「看起來像內建語法」的動作,都對應到一個 dunder 方法:== 是 __eq__、< 是 __lt__、len(x) 是 __len__、x[i] 是 __getitem__、for ... in x 背後是 __iter__。換句話說,Python 的語法是一層薄薄的外殼,底下全是方法呼叫。
更妙的是,你可以為自己的類別定義這些方法,讓自訂物件也能用 +、<、== 等運算子,這稱為運算子多載(operator overloading):
class Money:
def __init__(self, dollars):
self.dollars = dollars
def __add__(self, other):
return Money(self.dollars + other.dollars)
def __repr__(self):
return f"${self.dollars}"
a = Money(100)
b = Money(250)
print(a + b) # 輸出:$350 你自訂的 + 被呼叫了
當左運算元不知道怎麼處理右運算元時(例如 1 + Money(...),int.__add__ 不認得 Money),Python 會反過來嘗試右運算元的 __radd__(reflected add)。理解了這層機制,你就會明白「型別」在 Python 裡的真正定義:一個型別 = 它支援哪些 dunder 方法的集合。這正是「鴨子型別(duck typing)」的根基——只要一個物件實作了 __add__,它對 + 而言就「是」一個可加的東西,無關它的類別名稱。
名字綁定的精緻細節:作用域與閉包
入門篇說「賦值是把名字綁到值」。當程式只有一層時這很單純,但一旦進入函式,「名字屬於哪個作用域」就變成關鍵問題。Python 用 LEGB 規則決定一個名字該去哪裡找:Local(區域)→ Enclosing(外層函式)→ Global(模組層)→ Built-in(內建)。
最常見的陷阱是:在函式裡賦值一個名字,會讓它變成該函式的區域變數,即使外面有同名的全域變數:
counter = 0
def increment():
counter = counter + 1 # UnboundLocalError!
return counter
# increment() # 報錯:local variable 'counter' referenced before assignment
為什麼出錯?因為函式裡有 counter = ... 這個賦值,Python 在「編譯」這個函式時就判定 counter 是區域變數;於是等號右邊讀取 counter 時,它去找區域的 counter,但那時還沒被賦值——矛盾。要明確告訴 Python「我指的是全域那個」,得用 global;若是要改外層函式的變數,則用 nonlocal:
def make_counter():
count = 0
def tick():
nonlocal count # 我要改的是外層的 count,不是新建區域變數
count += 1
return count
return tick
c = make_counter()
print(c(), c(), c()) # 輸出:1 2 3
make_counter 回傳的 tick 函式,「記住」了它出生時所在環境裡的 count,這個現象叫閉包(closure)。count 明明在 make_counter 執行完後就該消失了,卻因為被 tick 引用而續命——這再次印證入門篇的核心觀念:變數是貼在物件上的標籤,只要還有人引用該物件,它就不會被回收。
擴增賦值的雙面性:+= 在可變與不可變物件上不一樣
x += 1 看起來只是 x = x + 1 的縮寫,但對可變物件,兩者有微妙差別。擴增賦值會優先嘗試呼叫原地版本的 dunder 方法(如 __iadd__,i 代表 in-place),對串列而言,+= 是原地修改,等同於 extend:
a = [1, 2, 3]
b = a
a += [4] # 原地修改 a 指向的串列
print(b) # 輸出:[1, 2, 3, 4] b 也看到了變化(共享同一物件)
a = [1, 2, 3]
b = a
a = a + [4] # 建立一個全新串列,再綁給 a
print(b) # 輸出:[1, 2, 3] b 沒變(a 已改指別處)
對不可變的 int、str、tuple,因為沒有原地修改的可能,+= 永遠是「建新物件再重新綁定」,所以不會有上面的共享陷阱。這個差異是無數真實 bug 的源頭,看懂它,你就掌握了「可變性 × 名字綁定」交織出的最容易踩的地雷。
海象運算子:在表達式裡順手綁定
Python 3.8 引入了海象運算子(walrus operator) :=,它讓你在一個「表達式」中順便完成賦值——這是入門篇沒提的新工具。傳統 = 是語句(statement),不能放在 if、while 的條件裡;:= 則是表達式,可以:
# 傳統寫法:要先算、再判斷,n 算了兩次概念
data = [1, 2, 3, 4, 5]
if (total := sum(data)) > 10:
print(f"總和 {total} 超標") # 輸出:總和 15 超標
# 在迴圈裡避免重複呼叫
import random
while (roll := random.randint(1, 6)) != 6:
print(f"擲出 {roll},再來一次")
print("擲出 6,結束")
海象運算子能讓程式更精簡,但濫用會降低可讀性。原則是:當你「需要用到剛算出來的值、又要拿它做條件判斷」時才用它。
重點回顧
float是 IEEE 754 二進位近似。0.1 + 0.2 != 0.3是必然而非錯誤;比較浮點數請用math.isclose(),需要精確就用Decimal(且傳字串)。int是任意精度,永不溢位;但一旦混入/或浮點運算就會降格成有精度上限的float。- 運算子是 dunder 方法的語法糖。
a + b即a.__add__(b);自訂類別可透過實作這些方法支援運算子多載。 - 在函式內賦值會建立區域變數,要改全域用
global、改外層用nonlocal;閉包讓內層函式記住外層變數。 +=對可變物件是原地修改(會被共享參考看到),對不可變物件是重新綁定,兩者行為不同。
深入探討(研究所視角):CPython 的物件記憶體佈局與快取機制
要把上面的現象連成一張完整的圖,得鑽進 CPython 的實作。CPython 中每個物件的底層都是一個 C 結構 PyObject,內含兩個基本欄位:參考計數(reference count, ob_refcnt)與型別指標(ob_type)。int、float 等具體型別在此之上擴充。一個小小的 Python 整數 1,在 CPython 裡其實是一個 PyLongObject,佔用約 28 個位元組——遠大於 C 的 4 位元組 int。這正是 Python 「萬物皆物件」彈性的代價:每個值都背著物件標頭的開銷。
理解了這個佈局,幾個入門篇的現象就有了統一的解釋。小整數快取(small integer cache):CPython 在直譯器啟動時就預先建立了 −5 到 256 的整數物件,全域共用,所以 256 is 256 為 True、257 is 257 在某些情境為 False——因為前者命中快取、共用同一 PyLongObject,後者每次都新建。同理,字串駐留(string interning) 讓符合識別字規則的短字串共用物件,這也是為什麼 a = "hello"; b = "hello"; a is b 通常為 True。這些都是純粹的記憶體最佳化,絕不該被當作判斷值是否相等的依據——值相等永遠用 ==,物件同一才用 is。
把參考計數的視角接上可變性,許多進階陷阱就一目了然。CPython 主要靠參考計數做垃圾回收:當某物件的 ob_refcnt 歸零,記憶體立即釋放(另有循環偵測器處理參考環)。y = x 不複製串列,只是讓 x 指向的物件 ob_refcnt 加一、再讓 y 指向它——這就是共享參考與 += 原地修改陷阱的物理根源。延伸到函式呼叫,Python 的傳參既不是純「傳值」也不是純「傳參考」,而是 call by object reference(亦稱 call by sharing):傳進去的是物件的參考,函式內若對參數做「原地修改」(如 lst.append(x)),呼叫端看得到;若做「重新綁定」(如 lst = [...]),則只動到區域名字、呼叫端不受影響。
最後一個經典地雷把以上全部串起來——可變預設參數(mutable default argument):
def add_item(item, bag=[]): # 危險:預設值 [] 只在定義時建立一次
bag.append(item)
return bag
print(add_item("a")) # 輸出:['a']
print(add_item("b")) # 輸出:['a', 'b'] 竟然累積了!
原因是:def 執行時,預設值 [] 這個串列物件只被建立一次,並綁定在函式物件的 __defaults__ 屬性上。之後每次未傳 bag 的呼叫,用的都是同一個串列,於是 append 不斷累積。正確寫法是用 None 當哨兵:
def add_item(item, bag=None):
if bag is None:
bag = [] # 每次呼叫都建立全新串列
bag.append(item)
return bag
從 IEEE 754 的二進位近似、bignum 的 digit 陣列、dunder 方法構成的型別本質,到參考計數驅動的可變性與作用域綁定——這些看似零散的「Python 怪癖」,其實都是同一套物件模型在不同層面的投影。當你能用「物件 = 身分 + 型別 + 值,名字只是貼上去的標籤,運算子只是 dunder 呼叫」這組原語去推導每一個現象時,你對 Python 的掌握就真正從使用者層級,深入到了實作者層級。