
關聯式資料庫與 SQL
從一張雜亂的 Excel 出發,理解表格、主鍵外鍵與關聯如何讓資料變得可信賴,再用 SQL 的 SELECT、JOIN、GROUP BY 提問,最後看懂 JOIN 演算法與索引怎麼加速查詢、參數化查詢如何擋下 SQL 注入。
把雜亂的 Excel 變成可信賴的資料
想像你在學生社團當總務,手上有一份 Excel:每位社員的姓名、系所、繳費紀錄、參加過的活動全擠在同一張表裡。一開始還好,但社員愈來愈多,問題就浮現了:同一個人參加三場活動,他的姓名與系所就被抄三次;某人轉系了,你得在十幾個地方手動改;想知道「資工系誰還沒繳費」,你只能用滑鼠一列一列篩。資料一多,這份 Excel 就從幫手變成噩夢。
關聯式資料庫(relational database)正是為了解決這種混亂而生。它的核心想法很單純:把資料拆成多張結構嚴謹的表格,再用「關聯」把它們串起來,並提供一種叫 SQL 的語言,讓你用宣告式的方式描述「我想要什麼」,而不必親手操作每一列。
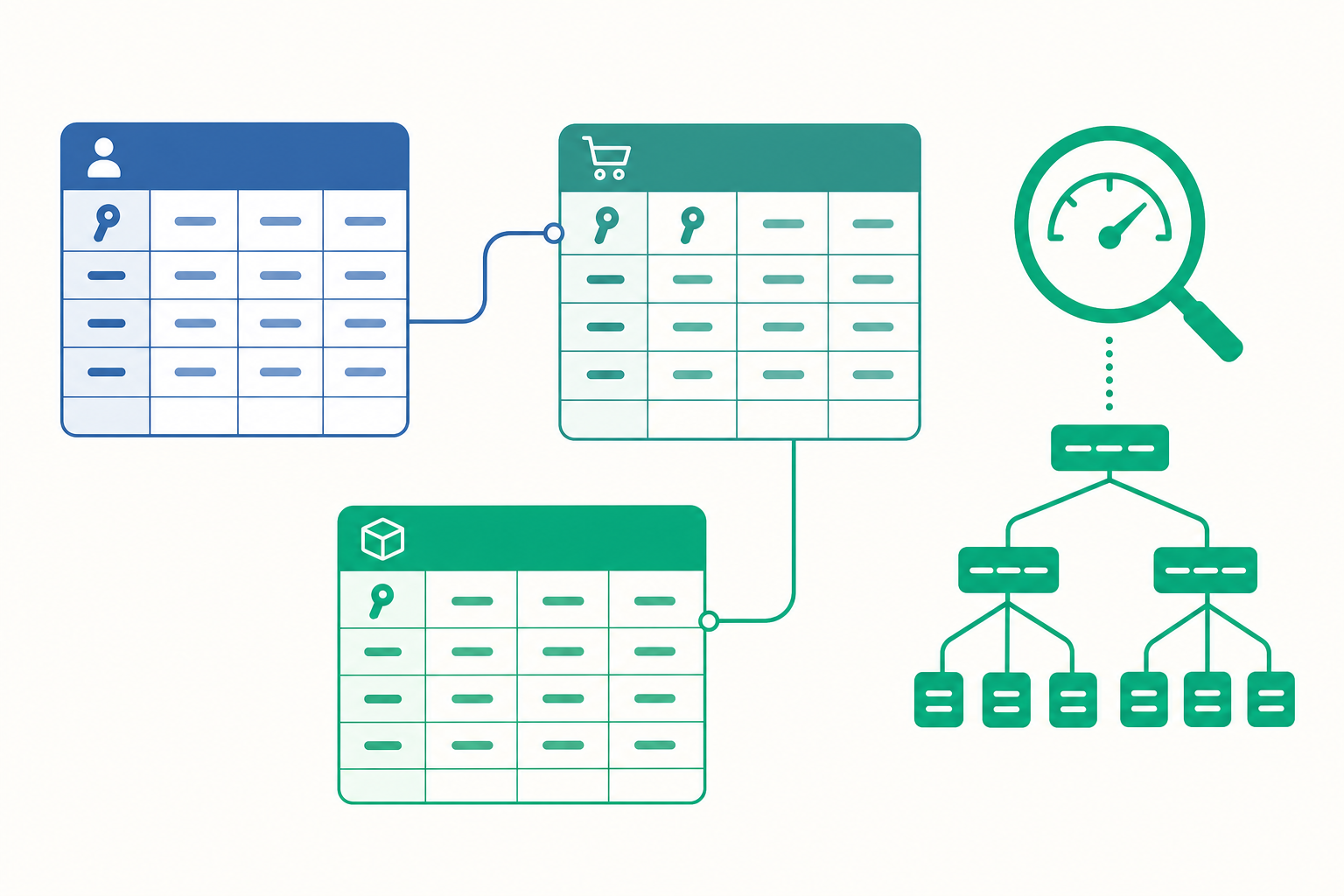
表格、列、欄:資料的基本骨架
關聯式資料庫的基本單位是表格(table),又稱關聯(relation)。一張表格由欄(column,又稱欄位/屬性)和列(row,又稱紀錄/tuple)組成。
以社團為例,我們可以設計一張 students(學生)表:
| id | name | department | |
|---|---|---|---|
| 1 | 林雅婷 | 資訊工程 | [email protected] |
| 2 | 陳建宏 | 企業管理 | [email protected] |
| 3 | 王思齊 | 資訊工程 | [email protected] |
每一欄代表一種屬性,並有固定的資料型別(data type),例如 id 是整數(integer)、name 是字串(varchar)、email 也是字串。每一列代表一個具體的學生。型別的約束很重要:它讓資料庫能保證「年齡欄不會塞進一段文字」,這種一致性是試算表給不了的。
主鍵與外鍵:讓每一列都有身分證
如果有兩位學生都叫「陳建宏」,我們怎麼區分?答案是主鍵(primary key)——一個能唯一識別每一列的欄位。上表中的 id 就是主鍵:它不可重複、不可為空(NOT NULL)。主鍵就像每一列的身分證號。
接下來才是關聯式資料庫的精髓。假設我們還有一張 activities(活動)表,以及一張記錄「誰參加了哪場活動」的 enrollments(報名)表:
activities enrollments
+----+--------------+ +----+------------+--------------+
| id | title | | id | student_id | activity_id |
+----+--------------+ +----+------------+--------------+
| 10 | 程式設計工作坊 | | 1 | 1 | 10 |
| 11 | 期末成果發表 | | 2 | 3 | 10 |
+----+--------------+ | 3 | 1 | 11 |
+----+------------+--------------+
enrollments 表裡的 student_id 並不是它自己的主鍵,而是指向 students.id 的外鍵(foreign key);同理 activity_id 是指向 activities.id 的外鍵。外鍵的意義是「這一欄的值必須在另一張表的主鍵中存在」。這帶來兩個關鍵好處:
- 避免重複:學生姓名、系所只在
students表存一次。enrollments只記student_id,要看姓名再去students查。林雅婷轉系,只改一個地方。 - 維護完整性(referential integrity):資料庫會拒絕你寫入一筆
student_id = 999而students裡根本沒有 999 的報名紀錄,避免出現「指向不存在學生」的孤兒資料。
這種「把資料拆開、用外鍵串聯」的設計思想,正式名稱叫正規化(normalization),目標是消除冗餘、避免更新時的不一致。
關聯的型態:一對多與多對多
students 與 enrollments 之間是一對多(one-to-many):一位學生可以有多筆報名紀錄,但每筆報名只屬於一位學生。
而 students 與 activities 之間其實是多對多(many-to-many):一位學生可參加多場活動,一場活動也有多位學生。關聯式資料庫無法直接表達多對多,標準做法就是引入一張中間的連接表(junction table)——這正是 enrollments 扮演的角色。它把一個多對多拆成兩個一對多,這是資料庫設計裡最常見也最重要的模式之一。
SQL:用宣告式語言提問
有了資料結構,我們需要一種語言來查詢和操作它,這就是 SQL(Structured Query Language,結構化查詢語言)。SQL 最迷人的地方在於它是宣告式(declarative)的:你描述「想要什麼結果」,至於「怎麼算出來」交給資料庫的查詢最佳化器去決定。
SELECT 與 WHERE:挑選你要的資料
最基本的查詢用 SELECT(選欄位)搭配 FROM(從哪張表)與 WHERE(篩選條件):
-- 找出所有資訊工程系的學生姓名與信箱
SELECT name, email
FROM students
WHERE department = '資訊工程';
WHERE 後面可以用 AND、OR、>、<、LIKE(模糊比對)等組合條件。例如找出系所包含「資訊」兩字的學生:WHERE department LIKE '%資訊%'。
JOIN:把多張表重新拼起來
既然我們刻意把資料拆成多張表,查詢時自然需要把它們重新組合,這就是 JOIN(連接)。假設我們想知道「每筆報名對應的學生姓名與活動名稱」:
SELECT s.name, a.title
FROM enrollments e
INNER JOIN students s ON e.student_id = s.id
INNER JOIN activities a ON e.activity_id = a.id;
INNER JOIN ... ON ... 的意思是:把 enrollments 的每一列,依照 ON 條件去 students 找出 id 相符的列,配對起來形成一個更寬的列。最後結果可能像這樣:
| name | title |
|---|---|
| 林雅婷 | 程式設計工作坊 |
| 王思齊 | 程式設計工作坊 |
| 林雅婷 | 期末成果發表 |
GROUP BY:分組與彙總
很多時候我們不要逐筆資料,而要統計數字。GROUP BY 把列依某欄分組,再用彙總函數(aggregate function)如 COUNT()、SUM()、AVG() 計算每組的結果:
-- 統計每場活動有多少人報名
SELECT a.title, COUNT(*) AS participant_count
FROM enrollments e
INNER JOIN activities a ON e.activity_id = a.id
GROUP BY a.title;
結果會是每場活動一列,附上報名人數。若要進一步只留「報名超過 5 人」的活動,要用 HAVING(針對分組後的結果篩選,而非 WHERE):HAVING COUNT(*) > 5。
動手看一個例子:找出尚未繳費的資工系學生
讓我們把概念串起來。假設 students 表多了一欄 has_paid(0 表示未繳、1 表示已繳),我們想列出「資訊工程系且尚未繳費」的學生,並依姓名排序:
SELECT name, email
FROM students
WHERE department = '資訊工程'
AND has_paid = 0
ORDER BY name ASC;
資料庫的執行邏輯大致是:
- 從
students表逐列檢視(或透過索引快速定位)。 - 套用
WHERE:只保留department = '資訊工程'且has_paid = 0的列。 - 套用
SELECT:只取出name、email兩欄。 - 套用
ORDER BY:依name由小到大排序。
短短四行,就完成了開頭那個「用滑鼠一列一列篩」的痛苦工作,而且資料量再大也是同一段查詢。
參數化查詢:別讓使用者輸入變成攻擊指令
當查詢的條件來自使用者輸入時,會出現一個嚴重的資安問題。假設你用字串拼接組出 SQL:
# 危險示範:絕對不要這樣做
username = request.args.get('username')
sql = "SELECT * FROM users WHERE username = '" + username + "'"
cursor.execute(sql)
如果攻擊者在 username 欄輸入 ' OR '1'='1,拼出來的 SQL 就變成 ... WHERE username = '' OR '1'='1',條件恆真,整張使用者表就外洩了。更惡劣的輸入甚至能刪除整張表。這種攻擊叫 SQL 注入(SQL injection),長年高居 Web 應用最常見的漏洞。
正確的防禦方式是參數化查詢(parameterized query),又稱預備語句(prepared statement)。你把 SQL 結構與資料分開傳遞,由資料庫驅動程式負責安全處理:
# 正確做法:參數化查詢
username = request.args.get('username')
cursor.execute("SELECT * FROM users WHERE username = %s", (username,))
這裡的 %s 是佔位符(placeholder),使用者輸入的值會被當成純資料對待,永遠不會被解讀成 SQL 指令的一部分。即使輸入 ' OR '1'='1,資料庫也只會老實地去找「使用者名稱剛好等於這串怪字元」的列,而不是改變查詢邏輯。
請記住一條鐵律:永遠不要用字串拼接把使用者輸入塞進 SQL,一律使用參數化查詢。這是合法防禦自家系統的基本功,也是任何資料庫應用的安全底線。
重點回顧
- 關聯式資料庫把資料拆成多張表格,每張表由欄(屬性)與列(紀錄)組成,欄位有固定型別以保證一致性。
- 主鍵唯一識別每一列;外鍵指向另一張表的主鍵,藉此建立關聯並維護參照完整性,多對多關係用連接表實現。
- SQL 是宣告式語言:
SELECT/WHERE挑資料、JOIN把多表拼回來、GROUP BY搭配彙總函數做統計。 - JOIN 依
ON條件配對多張表的列;索引能大幅加速查詢,避免逐列掃描。 - 條件含使用者輸入時,一律用參數化查詢防範 SQL 注入,絕不用字串拼接組 SQL。
深入探討(研究所視角)
開頭提過 SQL 是宣告式的,這引出一個關鍵概念:SQL 的語意建立在關聯代數(relational algebra)之上。SELECT 對應投影(projection, $\pi$)、WHERE 對應選擇(selection, $\sigma$)、JOIN 對應連接($\bowtie$)。一段 SQL 可以被改寫成多種等價的關聯代數運算式,而資料庫的查詢最佳化器(query optimizer)正是在這些等價式中,依據統計資訊估算成本,挑出最便宜的執行計畫(execution plan)。這也是為什麼宣告式查詢威力強大:你只說目標,最佳化器替你找最快的路。
JOIN 的運作機制值得細看。最樸素的做法是巢狀迴圈連接(nested loop join):對左表每一列,掃過右表每一列找符合 ON 條件者,複雜度約 $O(n \times m)$,資料一大就難以承受。因此實務上有兩種更快的演算法:雜湊連接(hash join) 先把較小的表依連接欄建成雜湊表(hash table),再掃描另一表逐列查表,平均可達 $O(n + m)$;排序合併連接(sort-merge join) 則先把兩表依連接欄排序,再像拉鍊般合併,複雜度由排序主導,約 $O(n \log n + m \log m)$。最佳化器會依資料量、是否已有排序或索引來選擇策略。
索引(index)如何加速查詢是另一塊核心。沒有索引時,WHERE id = 3 必須做全表掃描(full table scan),逐列比對,複雜度 $O(n)$。索引最常見的實作是 B-tree(更精確是 B+ tree):它是一棵平衡的多元搜尋樹,把鍵值有序地組織起來,查找、插入、刪除都是 $O(\log n)$。在 id 上建索引後,WHERE id = 3 只需從樹根往下走幾層就能定位到目標,把 $O(n)$ 降為 $O(\log n)$;範圍查詢如 WHERE id BETWEEN 100 AND 200 也能沿著 B+ tree 葉節點的有序鏈結快速掃出區間。索引同樣加速 JOIN:若連接欄上有索引,巢狀迴圈連接就能用索引快速定位匹配列(index nested loop join),而非掃整張表。
索引並非沒有代價:它佔額外儲存空間,且每次 INSERT/UPDATE/DELETE 都要同步維護索引結構,因此寫入會變慢。索引設計是讀寫權衡(read-write trade-off)——查詢密集的欄位值得建索引,頻繁寫入卻很少被查的欄位則未必。除了 B-tree,雜湊索引(hash index)適合等值查找但不支援範圍查詢,全文索引(full-text index)則用於文字搜尋,各有適用場景。
最後,這些機制與更廣的主題相連:交易(transaction)的 ACID 性質(原子性、一致性、隔離性、持久性)保證並行存取下的資料正確;當單一機器扛不住時,分散式資料庫會面臨 CAP 定理的取捨,並催生出放寬一致性的 NoSQL 系統。理解了關聯式資料庫的查詢最佳化、索引與連接演算法,正是踏入這些進階主題的穩固起點。