
演算法與複雜度:當輸入變大,成本以多快的速度膨脹?
從圖書館找書談起,理解漸近分析、Big-O/Ω/Θ、常見複雜度等級、最壞與平均情況、時間與空間的權衡,並深入漸近分析的數學定義與攤銷分析。
為什麼同樣一支程式,在百萬筆資料前會「卡死」?
想像你在圖書館找一本書。如果書架完全沒有排序,你只能一本一本翻,最壞的情況是翻到最後一本才找到;但如果書是按書名排好的,你可以先翻到中間,判斷要往左還是往右,每翻一次就排除掉一半的書。一萬本書,第一種方法最壞要翻一萬次,第二種方法卻只要約十四次。
這個差距不是「電腦快一點慢一點」的問題。當資料量從一萬變成一百萬,第一種方法慢了一百倍,第二種方法只多了七次左右。決定一支程式能不能在現實規模下存活的,往往不是程式語言、也不是硬體,而是演算法本身的成長速度。這正是「演算法與複雜度」要回答的核心問題:當輸入變大,計算成本會以多快的速度膨脹?
演算法是什麼:從問題到一份明確的食譜
演算法(algorithm)是一段「明確、有限、可機械執行」的步驟,把輸入轉換成期望的輸出。它不是某種特定的程式語言,而是解題的邏輯骨架。同一個演算法可以用 Python、C 或 Java 寫出來,也可以用自然語言或虛擬碼(pseudocode)描述。
我們常用虛擬碼來表達演算法,因為它聚焦在邏輯本身,不被語法細節綁架。例如「在陣列中找最大值」可以這樣寫:
函式 找最大值(A)
max ← A[0]
對 i 從 1 到 length(A) - 1
若 A[i] > max
max ← A[i]
回傳 max
一個好的演算法首先要正確(correctness):對所有合法輸入都產生正確的輸出,而且一定會在有限步驟內停止。我們通常用「迴圈不變量(loop invariant)」來論證正確性——找出一個在每次迴圈前後都保持為真的性質。以上面為例,不變量是:「每次進入迴圈時,max 等於 A[0..i-1] 中的最大值」。迴圈開始前成立(只看了 A[0]),每一輪都維持,迴圈結束時 i 走過整個陣列,於是 max 就是全陣列最大值。正確性論證的價值在於:它讓我們不必靠「跑幾筆測試沒出錯」來猜,而是有邏輯保證。
為什麼要談複雜度,而不是直接量秒數
你可能會想:想知道哪個演算法快,直接用碼表量不就好了?問題在於,量到的秒數會被太多無關因素污染——CPU 型號、是否有快取(cache)命中、其他程式在搶資源、甚至當天室溫。同一支程式在你的筆電和伺服器上跑出來的數字完全不同,無法用來比較演算法的「本質效率」。
複雜度分析換了一個角度:我們不問「跑幾秒」,而問「當輸入規模 $n$ 增大時,基本運算的次數如何成長」。基本運算指的是比較、加法、賦值這類花費固定時間的動作。我們刻意忽略常數倍率與低階項,因為當 $n$ 夠大時,成長最快的那一項會主宰一切。一個執行 $5n^2 + 100n + 3000$ 次運算的演算法,在 $n$ 很大時,$n^2$ 那一項才是關鍵,前面的係數 5 和後面的 $100n$、$3000$ 都顯得微不足道。這種「看大局、忽略細節」的思維就是漸近分析(asymptotic analysis)。
Big-O、Ω、Θ:成長速度的三種界線
漸近分析用三個希臘記號來精確描述成長速度,它們分別捕捉「上界、下界、緊界」:
- 大 O ($O$) 描述上界——成長不會比它快。$f(n) = O(g(n))$ 表示存在常數 $c > 0$ 與 $n_0$,使得對所有 $n \ge n_0$,都有 $f(n) \le c \cdot g(n)$。直覺上「$f$ 最多和 $g$ 一樣快」。
- 大 Omega ($\Omega$) 描述下界——成長至少有這麼快。$f(n) = \Omega(g(n))$ 表示存在 $c > 0$ 與 $n_0$,使得對所有 $n \ge n_0$,$f(n) \ge c \cdot g(n)$。
- 大 Theta ($\Theta$) 描述緊界——上下界都吻合。$f(n) = \Theta(g(n))$ 表示 $f(n)$ 同時是 $O(g(n))$ 與 $\Omega(g(n))$,也就是 $f$ 的成長率與 $g$ 完全同階。
一個常見迷思是把 Big-O 當成「平均」或「實際就是這麼慢」。其實 Big-O 只說「不會更糟」。例如線性搜尋是 $O(n)$,但若要找的元素剛好在第一個,實際只跑一步。三個記號回答的是不同問題:$O$ 是「最糟能糟到哪」,$\Omega$ 是「最好也好不過哪」,$\Theta$ 是「上下夾住、就是這個量級」。
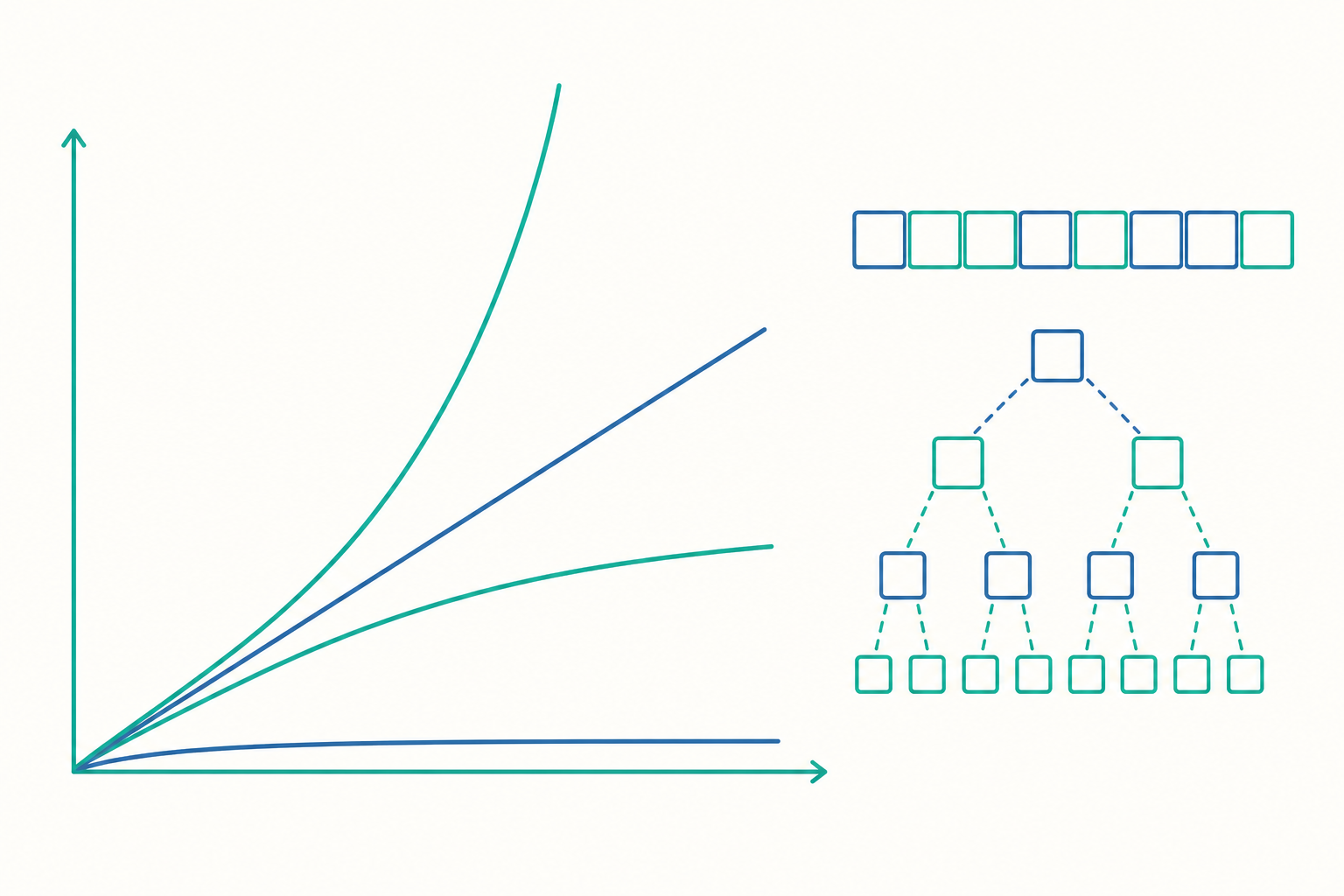
常見複雜度等級:一張你該背下來的階梯
下表列出最常見的複雜度等級,由快到慢。第三欄給出當 $n = 1{,}000{,}000$ 時的大致運算量,讓你感受差距有多懸殊。
| 複雜度 | 名稱 | $n = 10^6$ 時的量級 | 典型例子 |
|---|---|---|---|
| $O(1)$ | 常數 | 1 | 陣列依索引取值、雜湊表(hash table)查找 |
| $O(\log n)$ | 對數 | 約 20 | 二分搜尋(binary search) |
| $O(n)$ | 線性 | $10^6$ | 線性搜尋、遍歷陣列 |
| $O(n \log n)$ | 線性對數 | 約 $2 \times 10^7$ | 合併排序(merge sort)、快速排序(quick sort) 平均 |
| $O(n^2)$ | 平方 | $10^{12}$ | 氣泡排序(bubble sort)、巢狀雙迴圈 |
| $O(2^n)$ | 指數 | 天文數字 | 暴力枚舉所有子集 |
| $O(n!)$ | 階乘 | 更天文 | 暴力枚舉所有排列(如旅行推銷員暴解) |
關鍵體會:$O(n^2)$ 在百萬筆資料下要做一兆次運算,即使每秒十億次也得跑十幾分鐘;而 $O(n \log n)$ 只要約兩千萬次,眨眼就完成。$O(2^n)$ 與 $O(n!)$ 則在 $n$ 才幾十的時候就已經無法在宇宙年齡內算完——這也是為什麼許多困難問題我們轉而追求近似解。
動手看一個例子
讓我們具體比較線性搜尋與二分搜尋。假設要在一個已排序的陣列中找數字 7。
線性搜尋從頭逐一比對:
def linear_search(arr, target):
for i in range(len(arr)): # 最壞情況跑 n 次
if arr[i] == target:
return i
return -1
二分搜尋利用「已排序」這個前提,每次砍掉一半:
def binary_search(arr, target):
lo, hi = 0, len(arr) - 1
while lo <= hi:
mid = (lo + hi) // 2 # 每輪檢查中間值
if arr[mid] == target:
return mid
elif arr[mid] < target:
lo = mid + 1 # 目標在右半
else:
hi = mid - 1 # 目標在左半
return -1
假設陣列是 [1, 3, 5, 7, 9, 11, 13, 15](共 8 個元素),找 7 的過程:
| 步驟 | lo | hi | mid | arr[mid] | 判斷 |
|---|---|---|---|---|---|
| 1 | 0 | 7 | 3 | 7 | 命中,回傳 3 |
只比較一次就找到了。若改找 13:
| 步驟 | lo | hi | mid | arr[mid] | 判斷 |
|---|---|---|---|---|---|
| 1 | 0 | 7 | 3 | 7 | 7 < 13,往右 |
| 2 | 4 | 7 | 5 | 11 | 11 < 13,往右 |
| 3 | 6 | 7 | 6 | 13 | 命中,回傳 6 |
8 個元素,最壞情況只需 $\log_2 8 = 3$ 次比較。線性搜尋最壞要 8 次。當元素變成一百萬,差距是 $20$ 次對上 $1{,}000{,}000$ 次。但要注意:二分搜尋的前提是資料已排序,這個前提本身需要 $O(n \log n)$ 的排序成本——是否划算取決於你要查找幾次。
最壞情況、平均情況與最佳情況
同一個演算法,面對不同的輸入內容,成本可能天差地遠。我們用三種情況來描述:
- 最壞情況(worst case):在所有大小為 $n$ 的輸入中,跑最久的那一種。這是最常用的指標,因為它給出保證——無論輸入多刁鑽,都不會比這更慢。
- 平均情況(average case):對輸入的某種機率分布取期望值。它更貼近「日常表現」,但需要對輸入分布做假設。
- 最佳情況(best case):跑最快的那種輸入,實務上參考價值較低,因為很少能假設總是遇到好運。
快速排序(quick sort)是經典例子:它平均是 $O(n \log n)$,速度通常很快;但若每次選到的基準點(pivot)都是最大或最小值(例如對已排序陣列用最簡單的選法),分割會極度不平衡,退化成 $O(n^2)$。這提醒我們:報告複雜度時必須說清楚是哪一種情況,否則容易誤導。實務上人們用「隨機化選 pivot」來讓最壞情況極難發生,把平均行為變成幾乎可靠的保證。
時間複雜度 vs 空間複雜度:一場常見的交易
複雜度不只看時間,也看空間——演算法額外需要多少記憶體。空間複雜度同樣用 Big-O 表示,計算的是除了輸入本身之外,演算法用掉的額外儲存。
許多時候,時間與空間是可以互換的,這稱為時間-空間權衡(time-space tradeoff)。一個經典例子是計算費氏數列(Fibonacci):
# 版本 A:純遞迴,時間 O(2^n),空間 O(n)(遞迴堆疊深度)
def fib_recursive(n):
if n <= 1:
return n
return fib_recursive(n - 1) + fib_recursive(n - 2)
# 版本 B:記憶化(memoization),時間 O(n),空間 O(n)
def fib_memo(n, cache={}):
if n <= 1:
return n
if n not in cache:
cache[n] = fib_memo(n - 1) + fib_memo(n - 2)
return cache[n]
版本 A 重複計算了大量相同的子問題,時間呈指數爆炸;版本 B 用一個字典(dictionary)把算過的結果存起來,花一點空間換來時間從指數降到線性。這就是典型的拿空間換時間。反過來,在記憶體極度受限的嵌入式系統裡,有時也會願意多花時間、少用空間。沒有絕對的好壞,只有對當下情境的權衡。
重點回顧
- 演算法是解題的邏輯骨架,獨立於程式語言;好的演算法首先要正確(對所有輸入產生正確結果且會停止),可用迴圈不變量論證。
- 複雜度分析比量秒數更可靠,因為它描述的是成長速度而非受硬體污染的絕對時間;漸近分析刻意忽略常數與低階項。
- $O$(上界,不會更糟)、$\Omega$(下界,至少這麼快)、$\Theta$(緊界,上下吻合)回答的是不同問題;Big-O 不等於「平均」也不等於「實際就這麼慢」。
- 常見等級由快到慢:$O(1) < O(\log n) < O(n) < O(n \log n) < O(n^2) < O(2^n) < O(n!)$;等級的差距在大資料下會放大成數量級的鴻溝。
- 同一演算法要區分最壞/平均/最佳情況;時間與空間常可互換(時間-空間權衡),記憶化是拿空間換時間的代表。
深入探討(研究所視角)
到了研究所層次,前面那套「直覺上忽略常數」需要被放回嚴謹的數學定義裡,而且我們會遇到「逐次操作看似很貴、整體攤平卻很便宜」的現象,這時需要更精細的工具。
漸近分析的形式定義:前面對 $O$、$\Omega$、$\Theta$ 的描述其實就是它們的正式定義,這裡把它寫成集合語言以便嚴謹推論。給定函式 $f, g: \mathbb{N} \to \mathbb{R}^{+}$:
$$O(g(n)) = \{ f(n) : \exists\, c > 0,\ n_0 > 0 \text{ 使得 } 0 \le f(n) \le c\,g(n),\ \forall n \ge n_0 \}$$
$$\Omega(g(n)) = \{ f(n) : \exists\, c > 0,\ n_0 > 0 \text{ 使得 } 0 \le c\,g(n) \le f(n),\ \forall n \ge n_0 \}$$
$$\Theta(g(n)) = O(g(n)) \cap \Omega(g(n))$$
嚴格寫法是 $f(n) \in O(g(n))$($O(g(n))$ 是一個函式集合),但慣例上常寫成 $f(n) = O(g(n))$,這是一種「單向等式」的濫用記號,不可反向解讀。另外還有兩個更嚴格的記號:小 o 表示「嚴格較小」——$f(n) = o(g(n))$ 代表 $\lim_{n \to \infty} f(n)/g(n) = 0$(例如 $n = o(n^2)$);小 $\omega$ 對稱地表示「嚴格較大」。$O$ 與 $\Theta$ 的差別正在於:$O$ 允許 $f$ 嚴格慢於 $g$,$\Theta$ 不允許。
攤銷分析(amortized analysis):考慮動態陣列(dynamic array,如 Python 的 list)的 append 操作。大多數時候空間還夠,append 只是 $O(1)$;但偶爾陣列滿了,需要配置兩倍大的新空間並把所有元素搬過去,這一次是 $O(n)$。若只看單次最壞情況,會誤判 append 是 $O(n)$。攤銷分析回答的是:「連續做 $n$ 次操作,總成本平均到每次是多少?」答案是 $O(1)$——因為昂貴的擴容很罕見,且每次擴容後要再填滿一倍元素才會觸發下一次。
形式化攤銷分析有三種方法。聚合法(aggregate method) 直接計算 $n$ 次操作的總成本再除以 $n$:以倍增策略,$n$ 次 append 的搬移總量是 $1 + 2 + 4 + \cdots + n < 2n = O(n)$,故攤銷成本 $O(n)/n = O(1)$。記帳法(accounting method) 為每次操作預收「代幣」,便宜操作多收的代幣存起來,付給未來昂貴的操作;只要證明帳戶餘額永不為負,預收金額就是攤銷上界——每次 append 收 3 枚代幣(1 枚做當次插入、2 枚存著供未來搬自己和一個舊夥伴),即可覆蓋擴容成本。位能法(potential method) 定義一個位能函數 $\Phi$ 把資料結構狀態映到非負實數,單次攤銷成本定為 $\hat{c_i} = c_i + \Phi_i - \Phi_{i-1}$;昂貴操作降低位能(用掉之前存的勢能),便宜操作累積位能,整段序列的攤銷總和 $\sum \hat{c_i} = \sum c_i + \Phi_n - \Phi_0$,只要 $\Phi_n \ge \Phi_0$ 就是真實總成本的上界。
攤銷 ≠ 平均:這是研究生最常混淆的一點。平均情況依賴輸入的機率分布,攤銷分析則是對最壞的操作序列取每次操作的平均,不涉及任何隨機性假設,因此給出的是確定性保證。一個經常被攤銷分析點亮的結構是並查集(union-find) 配合路徑壓縮與按秩合併,其單次操作的攤銷成本是 $O(\alpha(n))$,其中 $\alpha$ 是反阿克曼函數(inverse Ackermann function)——在任何現實 $n$ 下都不超過 4,幾乎可視為常數。
與其他主題的連結:漸近分析與攤銷分析是演算法設計(分治、動態規劃、貪婪法的成本論證)、資料結構(攤銷分析正是 splay tree、Fibonacci heap 等進階結構的分析支柱)與計算複雜度理論的共同語言。再往上走,複雜度理論會把焦點從「具體演算法跑多快」抬升到「問題本身有多難」——P 與 NP 的分野、NP-完全(NP-complete)問題的歸約,討論的是某類問題是否存在多項式時間演算法。換句話說,本文教你分析一個演算法的效率,而複雜度理論問的是所有可能演算法的效率下限,那是這條學習路徑自然的下一站。