
C++ 指標與參考:把記憶體攤在你面前
從失靈的 swap 出發,理解位址、指標、參考、nullptr 與懸空指標——以及為何這是 C++ 的招牌
當你想知道「那個變數到底住在哪裡」
假設你正在寫一支 C++ 程式,要交換兩個整數的值。在 Python 裡你大概會直接 a, b = b, a,乾淨俐落,完全不用煩惱「值到底放在哪」。但在 C++ 裡,如果你寫一個函式 void swap(int a, int b),呼叫它之後會發現——原本的兩個變數紋風不動。函式裡的交換明明成功了,外面卻毫無變化。
這個「失靈的 swap」是幾乎每個 C++ 學習者都會撞上的牆。要翻過它,你必須理解 C++ 對「記憶體」的態度:在 C++ 裡,每個變數都有一個明確的位址(address),你可以拿到它、傳遞它、透過它去改別人的值。這就是指標(pointer)與參考(reference)的世界。
相較於 Python 把記憶體管理藏在背後(你永遠看不到物件的真實位址,只能看到 id() 這種抽象代號),C++ 把記憶體攤在你面前。這既是它最讓人卻步的地方,也是它能寫出作業系統、遊戲引擎、資料庫核心的根本原因。讓我們動手把這層面紗掀開。
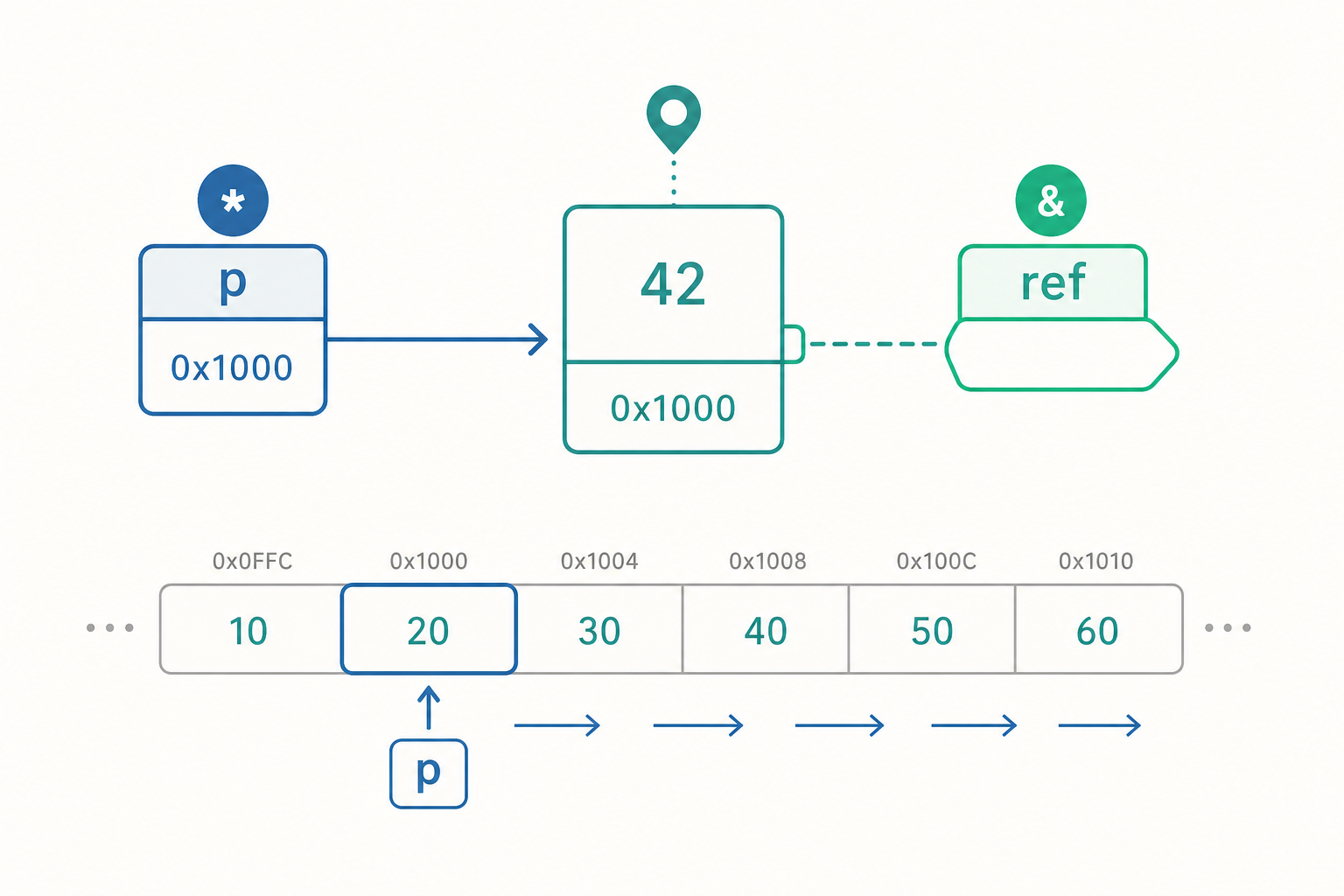
變數住在哪裡:位址與取址運算子 &
在 C++ 中,每個變數在程式執行時都被放在記憶體的某個位置,這個位置有一個編號,就是它的位址。你可以用取址運算子 & 拿到它:
#include <iostream>
using namespace std;
int main() {
int age = 20;
cout << "age 的值是:" << age << '\n';
cout << "age 的位址是:" << &age << '\n';
return 0;
}
執行後 &age 會印出類似 0x7ffd3a2b4c1c 的十六進位數字。這個數字每次執行可能不同(作業系統會隨機配置),但重點是:它是真實存在的記憶體位置。
相較於 Python,這裡有個關鍵差異。Python 的變數名稱只是貼在物件上的標籤,物件本身飄在堆積(heap)裡,你碰不到它的位址。而 C++ 的 int age = 20; 是實實在在地在記憶體劃出一塊 4 位元組的空間,把 20 放進去——這是靜態型別 + 編譯帶來的確定性:編譯器在編譯期就知道 age 要佔多大、放哪種型別。
指標:宣告與解參考 *
指標就是一個專門用來存「位址」的變數。 既然位址也是一種資料,當然也能存起來、傳來傳去。宣告指標時,在型別後面加 *:
#include <iostream>
using namespace std;
int main() {
int age = 20;
int* p = &age; // p 是「指向 int 的指標」,存的是 age 的位址
cout << "p 存的位址:" << p << '\n'; // 等同 &age
cout << "p 指向的值:" << *p << '\n'; // 解參考:取出 age 的值,印出 20
*p = 25; // 透過 p 去改 age
cout << "age 現在是:" << age << '\n'; // 印出 25
return 0;
}
這裡有兩個 *,意義完全不同,初學者一定要分清楚:
- 宣告時的
*:int* p表示「p是一個指標」,是型別的一部分。 - 使用時的
*:*p是解參考(dereference),意思是「順著p存的位址走過去,拿出那裡的東西」。
換句話說,p 是「地址」,*p 是「住在那個地址的人」。*p = 25 就是「把住在那個地址的值改成 25」——而那個地址正是 age,所以 age 真的被改了。
慣例提醒:
int* p與int *p在語法上完全等價。本文採int* p(星號貼著型別)以強調「指向 int 的指標」是一個整體型別。但要小心int* a, b;這個陷阱——這裡只有a是指標,b是普通int!這是少數int *a, *b;寫法反而更清楚的場合。
指標與陣列:C++ 的底層真相
在 C++ 裡,陣列名稱在大多數情境下會「退化(decay)」成指向第一個元素的指標。這揭露了陣列的底層本質:一塊連續的記憶體。
#include <iostream>
using namespace std;
int main() {
int arr[5] = {10, 20, 30, 40, 50};
int* p = arr; // arr 退化成 &arr[0],不需要寫 &
cout << *p << '\n'; // 10
cout << *(p + 1) << '\n'; // 20,往後移一個 int
cout << *(p + 2) << '\n'; // 30
// 用指標走訪整個陣列
for (int i = 0; i < 5; i++) {
cout << *(p + i) << ' ';
}
cout << '\n'; // 輸出:10 20 30 40 50
return 0;
}
注意 p + 1 不是「位址加 1 個位元組」,而是「位址加 1 個 int 的大小」(通常是 4 位元組)。編譯器知道 p 是 int*,所以會自動乘上 sizeof(int)。這就是為什麼 arr[i] 其實只是 *(arr + i) 的語法糖——你甚至可以寫出 3[arr] 這種看起來很怪但合法的寫法(因為 *(arr + 3) 與 *(3 + arr) 相等)。
相較於 Python 的 list(背後是動態的物件指標陣列,能裝任何型別、能自動成長),C++ 原生陣列是固定大小、同型別、緊湊排列的連續記憶體。這讓它存取速度極快($O(1)$ 隨機存取且對快取友善),但也意味著越界存取不會報錯,而是直接讀到隔壁的記憶體——這是 C++ 的危險與威力所在。
參考(reference):指標的安全替身
C++ 還有一個指標的近親:參考(reference)。參考是某個已存在變數的別名(alias)——同一塊記憶體的另一個名字。宣告時用 &(注意這裡的 & 是型別的一部分,不是取址):
#include <iostream>
using namespace std;
int main() {
int score = 90;
int& ref = score; // ref 是 score 的別名
ref = 100; // 等同 score = 100
cout << score << '\n'; // 輸出:100
cout << &score << '\n'; // 兩者位址相同,因為是同一塊記憶體
cout << &ref << '\n';
return 0;
}
參考和指標的差別:
指標 int* p |
參考 int& r |
|
|---|---|---|
| 必須初始化 | 否(但強烈建議) | 是,宣告時就要綁定 |
| 可改指向別人 | 是 | 否,一旦綁定終身不變 |
| 可以是 null | 是(nullptr) |
否 |
| 使用語法 | 要 *p 解參考 |
直接當變數用 |
簡單說:參考是「綁死的、不會是空的指標」,語法更乾淨。當你只是想「給某個變數取個別名」或「讓函式能改外面的值」時,優先用參考;當你需要「可以指向不同對象、可以是空、需要做指標算術」時,才用指標。
nullptr:明確表達「什麼都不指向」
指標可以不指向任何東西,這時應該讓它等於 nullptr:
#include <iostream>
using namespace std;
int main() {
int* p = nullptr; // 明確表示「目前不指向任何有效記憶體」
if (p == nullptr) {
cout << "p 是空指標,不能解參考\n";
} else {
cout << *p << '\n';
}
return 0;
}
nullptr 是 C++11 引入的關鍵字,取代了舊時代的 NULL(其實只是 0 的巨集)和裸寫 0。為什麼要特別搞一個關鍵字?因為 NULL 是整數 0,在函式重載時會搞混(編譯器分不清你要呼叫吃 int 的版本還是吃指標的版本)。nullptr 有專屬型別 std::nullptr_t,永遠被視為指標的「空」,語意明確。
鐵則:解參考 nullptr 是未定義行為(undefined behavior),通常直接讓程式崩潰(segmentation fault)。 因此在解參考前養成檢查的習慣。相較於 Python 存取 None.foo 會丟出乾淨的 AttributeError,C++ 的空指標解參考可能直接讓整個程式爆掉,甚至更糟——靜默地讀寫到不該碰的記憶體。
終於:修好那個失靈的 swap
回到開頭的問題。C++ 函式預設是傳值(pass by value)——把引數複製一份進函式,函式裡改的是副本,外面當然不變。要讓函式能改到外面的變數,有兩種正統做法:
#include <iostream>
using namespace std;
// 做法一:傳指標
void swapByPointer(int* a, int* b) {
int tmp = *a;
*a = *b;
*b = tmp;
}
// 做法二:傳參考(C++ 慣用,更乾淨)
void swapByReference(int& a, int& b) {
int tmp = a;
a = b;
b = tmp;
}
int main() {
int x = 3, y = 7;
swapByPointer(&x, &y); // 要明確取址
cout << x << ' ' << y << '\n'; // 7 3
swapByReference(x, y); // 直接傳,像普通變數
cout << x << ' ' << y << '\n'; // 3 7
return 0;
}
兩種版本效果相同,但參考版是現代 C++ 的慣用寫法:呼叫端 swapByReference(x, y) 看起來就像在傳普通變數,沒有滿天飛的 & 和 *。事實上,C++ 標準函式庫的 std::swap 就是用參考實作的。
這也是為什麼大型函式常用 const T&(常數參考)傳遞物件——既避免複製大物件的成本,又承諾「我只讀不改」。
動手寫一段:用傳參考統計一筆成績
來寫一個完整的小程式:傳入一個分數,函式同時算出「等第」並透過參考把「是否及格」回傳給呼叫端。
#include <iostream>
#include <string>
using namespace std;
// 回傳等第字串,並透過參考 passed 告知是否及格
string grade(int score, bool& passed) {
passed = (score >= 60);
if (score >= 90) return "A";
if (score >= 80) return "B";
if (score >= 70) return "C";
if (score >= 60) return "D";
return "F";
}
int main() {
int scores[3] = {95, 58, 73};
for (int i = 0; i < 3; i++) {
bool ok = false;
string g = grade(scores[i], ok); // ok 會被函式改寫
cout << "分數 " << scores[i]
<< " 等第 " << g
<< (ok ? " (及格)" : " (不及格)") << '\n';
}
return 0;
}
// 輸出:
// 分數 95 等第 A (及格)
// 分數 58 等第 F (不及格)
// 分數 73 等第 C (及格)
這裡 bool& passed 讓函式既能「回傳等第字串」又能「順手改寫呼叫端的 ok」——一個函式回傳兩種資訊,這正是參考的典型用法。試著動手把 bool& 改成普通 bool,重新編譯執行,你會發現 ok 永遠是 false:因為改的是副本。這個對照能讓你牢牢記住「傳值 vs 傳參考」的差別。
為什麼指標是 C++ 的招牌
你可能會問:既然參考這麼好用,為什麼還需要指標?因為指標能做到參考做不到的事,而這些事正是 C++ 之所以強大的核心:
- 動態記憶體管理:程式執行時才決定要多少記憶體(
new/delete),參考做不到。 - 可變指向:指標可以今天指這、明天指那,是建構鏈結串列、樹、圖的基礎。
- 可為空:用
nullptr表達「沒有」,例如「樹的葉節點沒有子節點」。 - 零成本的底層存取:直接操作硬體記憶體、與 C 程式碼互通、實作高效資料結構。
相較於 Python 把記憶體管理完全自動化(垃圾回收幫你清理,你永遠不碰指標),C++ 把這份控制權交給你。這就是 C++ 的設計哲學——零成本抽象(zero-cost abstraction):你不用為沒用到的功能付出代價,而當你需要極致控制時,語言不會擋你的路。代價是:你得自己負責不要把記憶體搞砸。
常見錯誤與重點回顧
初學者最常踩的雷,列在這裡反覆對照:
- 解參考空指標或未初始化指標:
int* p; *p = 5;是災難——p是垃圾值,寫進去等於亂射記憶體。宣告指標時若還沒有對象,先設nullptr,解參考前先檢查。 - 混淆
int* p, q;:這宣告的是「一個指標p和一個普通 intq」,不是兩個指標。要兩個指標請寫int *p, *q;或分兩行。 - 以為傳值能改外面:函式參數沒加
&(參考)或沒傳位址(指標),函式裡的修改不會反映到呼叫端。 - 參考必須初始化:
int& r;直接編譯失敗。參考宣告當下就要綁定對象,且終身不換。 - 回傳區域變數的位址或參考:函式結束後區域變數就消失了,回傳指向它的指標/參考會變成懸空(dangling),後續存取是未定義行為。
一句話總結三個核心符號:宣告時的 * 造指標、宣告時的 & 造參考、使用時的 * 是解參考、使用時的 & 是取址。同一個符號在不同位置意義不同,這是 C++ 語法最容易讓人混淆的地方,多寫幾次就能內化。
深入探討(研究所視角)
指標算術的精確語意
指標算術(pointer arithmetic)的單位是「被指型別的大小」,而非位元組。對 T* p,p + n 在數值上等於 (char*)p + n * sizeof(T)。這讓陣列走訪可以寫得極簡潔,但也有嚴格規範:標準只允許指標指向陣列內的元素,或指向陣列「尾後一個位置(one-past-the-end)」。end 指標可以拿來比較與計算,但不可解參考。超出這個範圍做算術或比較,即使沒崩潰,也是未定義行為。
兩個指向同一陣列的指標相減,得到的是它們相隔幾個元素(型別為 std::ptrdiff_t),這正是 STL 迭代器 end - begin 計算容器大小的底層機制。理解這點,你就能看懂 std::vector、std::sort 等是如何在指標/迭代器抽象上做到 $O(1)$ 的距離計算。
const 指標 vs 指標 const:從右往左讀
const 與指標的組合是經典考點,訣竅是從右往左讀:
int x = 1, y = 2;
const int* p1 = &x; // 指向 const int 的指標:不能透過 p1 改值,但 p1 可改指向
// *p1 = 5; ❌ 錯誤
p1 = &y; // ✅ 可以
int* const p2 = &x; // const 指標:p2 不能改指向,但可透過它改值
*p2 = 5; // ✅ 可以
// p2 = &y; ❌ 錯誤
const int* const p3 = &x; // 兩者皆 const:既不能改指向,也不能透過它改值
把宣告倒著唸:const int* p1 是「p1 is a pointer to const int」(值是常數);int* const p2 是「p2 is a const pointer to int」(指標本身是常數)。const T& 常數參考同理——這是傳大物件進函式又保證不被修改的標準做法,兼顧效率與安全。
懸空指標:C++ 最危險的陷阱
懸空指標(dangling pointer)指向一塊已經被釋放或已失效的記憶體。三種典型成因:
// 成因一:回傳區域變數位址
int* bad() {
int local = 42;
return &local; // ❌ 函式結束後 local 消失,回傳的指標懸空
}
// 成因二:use-after-free
int* p = new int(10);
delete p; // 記憶體歸還
// *p = 20; // ❌ 懸空,未定義行為
p = nullptr; // ✅ 釋放後立刻設 nullptr 是好習慣
// 成因三:指向已超出作用域的物件
int* q;
{
int tmp = 5;
q = &tmp;
} // tmp 在此銷毀
// *q; // ❌ q 懸空
懸空指標可怕在於它通常不會立刻崩潰——那塊記憶體可能還沒被覆寫,程式照常跑,直到某天被其他資料寫入,才在毫不相關的地方爆出難以追查的 bug。這類 use-after-free 也是真實世界中大量安全漏洞的根源。
相較於 Python/Java 靠垃圾回收保證「只要還有人指著,物件就不會消失」,C++ 把生命週期管理交給你。但現代 C++(C++11 起)強烈建議不要裸用 new/delete,而是用智慧指標(smart pointer):std::unique_ptr 表達獨佔所有權、std::shared_ptr 表達共享所有權(引用計數)、std::weak_ptr 打破循環引用。它們透過 RAII(Resource Acquisition Is Initialization)在物件離開作用域時自動釋放,把「手動管理記憶體」的大半危險消弭於無形——這正是現代 C++ 能在保有底層控制力的同時,寫出安全程式碼的關鍵。
理解了裸指標的危險,你才會真正體會智慧指標的價值。下次當你看到 std::unique_ptr<Node> 時,你會知道它背後正是一個被嚴格管控生命週期的指標——這就是 C++ 把「危險的力量」馴服成「安全的抽象」的方式。