
排序與搜尋(進階):為什麼世界上最快的排序不是任何單一演算法
越過漸近複雜度的地平線,從決策樹下界、Timsort、快取階層到 B 樹與 learned index,看真實系統如何在理論保證與硬體現實之間握手
為什麼世界上最快的排序,不是任何單一演算法?
如果你讀過入門篇,你已經知道在字典裡查單字,用「對半翻」的二分搜尋(binary search)比一頁頁翻快得多;也知道把資料排好序之後,搜尋會變得輕鬆。那是漂亮的世界觀,但它有一個隱藏的前提:我們假設所有比較的成本一樣、資料剛好放得進記憶體、而且我們只在乎「比較幾次」。
真實世界沒有這麼仁慈。當你在 Python 裡呼叫 sorted()、在 C++ 裡呼叫 std::sort()、或在 Java 裡呼叫 Arrays.sort(),背後執行的都不是課本上那個單一演算法。它們是混血兒——Timsort、introsort、dual-pivot quicksort——每一個都是工程師為了對抗真實資料的「壞脾氣」而拼裝出來的。
這篇文章要帶你越過入門篇的地平線:我們不再問「哪個演算法比較快」,而是問「快」到底是什麼意思,以及為什麼一個理論上完美的演算法,在真實 CPU 上可能輸給一個「看起來比較笨」的對手。
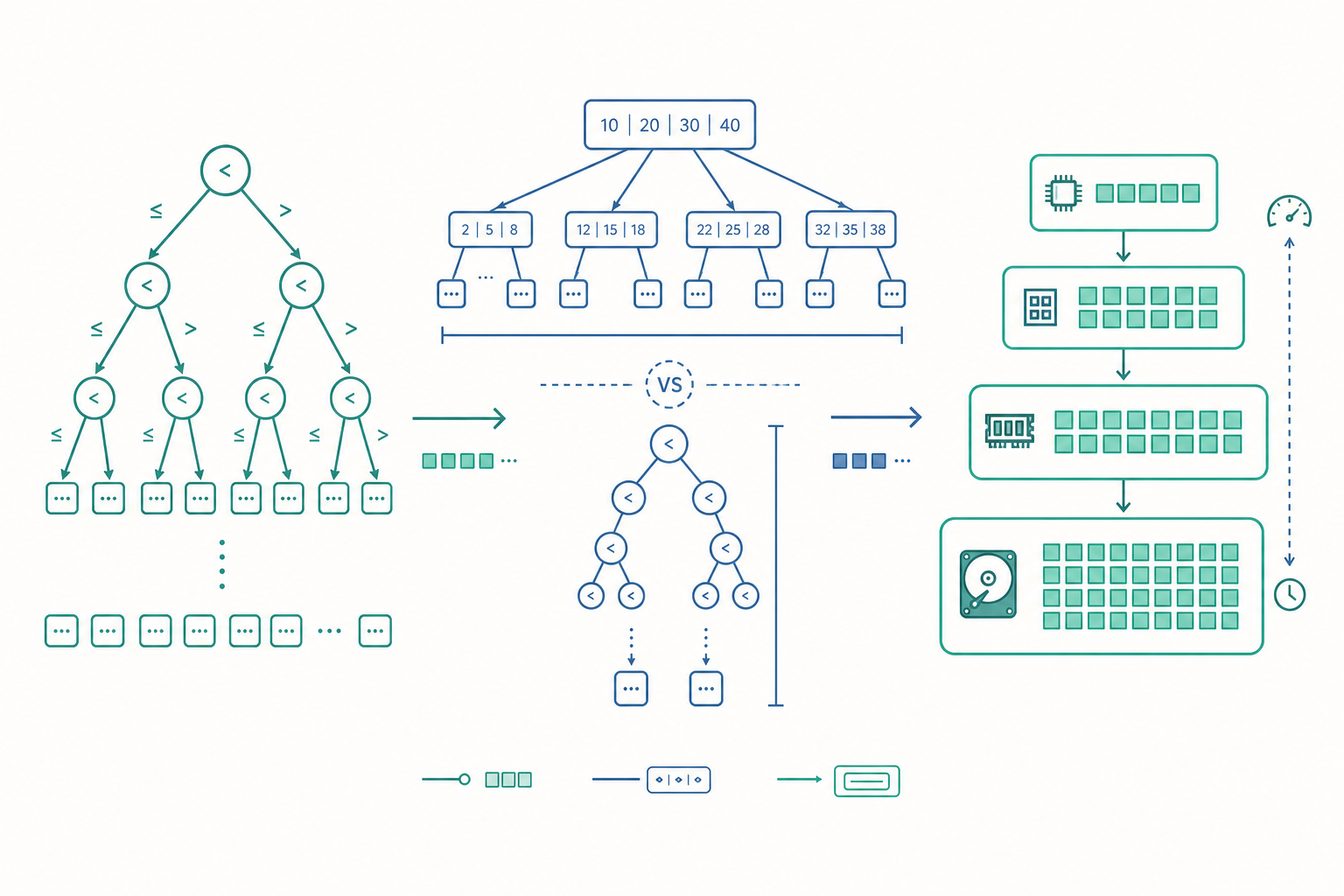
比較排序的下界:為什麼沒有人能突破 $O(n \log n)$
入門篇告訴你合併排序(merge sort)與快速排序(quick sort)都是 $O(n \log n)$。但你有沒有想過一個更深的問題:有沒有可能發明一個比 $O(n \log n)$ 更快的比較排序?
答案是不可能,而且我們可以證明它。這是計算機科學少數能給出「理論天花板」的優美時刻。
想像排序的過程,本質上是在一棵「決策樹」(decision tree)上走路。每一次「比較兩個元素」,就是一個分岔:左邊代表 $a < b$,右邊代表 $a > b$。對 $n$ 個元素來說,可能的排列順序共有 $n!$ 種,而每一種正確的輸出都必須對應到決策樹的一片葉子——因為演算法必須能區分這 $n!$ 種情況。
一棵高度為 $h$ 的二元樹,最多有 $2^h$ 片葉子。要容納 $n!$ 片葉子,必須滿足:
$$2^h \geq n! \quad\Longrightarrow\quad h \geq \log_2(n!)$$
而樹的高度 $h$ 就是「最壞情況下要做幾次比較」。利用 Stirling 近似(Stirling's approximation):
$$\log_2(n!) \approx n \log_2 n - n \log_2 e = \Theta(n \log n)$$
所以任何以「兩兩比較」為基礎的排序,最壞情況都至少要做 $\Omega(n \log n)$ 次比較。Timsort 再聰明、quicksort 再快,都逃不出這個牢籠。
動手算一下
你可能會說:「等等,那計數排序(counting sort)、基數排序(radix sort)不是號稱 $O(n)$ 嗎?這不是打臉了嗎?」
沒有打臉。關鍵在於:這些演算法不靠比較。 計數排序直接用元素的「值」當陣列索引,跳過了比較這個動作,所以不受 $\Omega(n \log n)$ 下界約束。代價是它需要知道值域範圍,且只適用於整數或可映射到整數的鍵。
def counting_sort(arr, max_val):
"""對 0..max_val 範圍內的整數排序,時間 O(n + max_val)"""
count = [0] * (max_val + 1)
for x in arr: # 統計每個值出現幾次(不做任何比較!)
count[x] += 1
result = []
for value, freq in enumerate(count):
result.extend([value] * freq)
return result
print(counting_sort([3, 1, 4, 1, 5, 9, 2, 6, 5, 3], 9))
# [1, 1, 2, 3, 3, 4, 5, 5, 6, 9]
注意這裡沒有任何一行在比較兩個元素的大小——它是在「數數」。這就是為什麼下界不適用。但若值域 max_val 大到 $10^{18}$,這個方法會瞬間崩潰,記憶體爆炸。理論的優美與工程的現實,永遠在拉扯。
真實世界的排序:Timsort 為什麼贏
理論說 $O(n \log n)$ 是天花板,但天花板下還有很大的高度差。Python 的 list.sort() 用的是 Timsort,由 Tim Peters 在 2002 年設計,後來被 Java、Android、Rust(早期)採用。它的核心洞見是一句樸素的觀察:
真實世界的資料幾乎從不是隨機的——它常常「部分已排序」。
你的銷售紀錄大致按時間遞增、你的日誌檔案大多有序、使用者名單往往一段一段有規律。Timsort 專門剝削這種「殘餘秩序」。
它的做法是先掃描陣列,找出已經天然遞增(或遞減)的連續區段,稱為 run。如果一段資料本來就排好了,Timsort 直接拿來用,一次比較都不浪費。然後它用一套精心設計的合併策略把這些 run 併起來。
def find_runs(arr):
"""示意:把陣列切成已經有序的 run(簡化版,未含反轉遞減段)"""
runs = []
i = 0
n = len(arr)
while i < n:
start = i
i += 1
while i < n and arr[i] >= arr[i - 1]: # 持續遞增就延長這個 run
i += 1
runs.append(arr[start:i])
return runs
print(find_runs([1, 3, 5, 2, 4, 6, 8, 7]))
# [[1, 3, 5], [2, 4, 6, 8], [7]] ← 三個天然有序段
對「幾乎已排序」的資料,Timsort 可以達到接近 $O(n)$ 的最佳情況——遠快於每次都假設最壞的標準合併排序。這就是為什麼「最壞情況複雜度相同」的兩個演算法,在真實負載下表現可能天差地遠。入門篇談的是漸近複雜度(asymptotic complexity),這裡談的是常數因子與資料分布——那才是工程師每天真正在搏鬥的戰場。
看一個例子
讓我們用實驗感受「資料分布」的威力。對同樣大小、但「已排序程度」不同的資料排序:
import random, time
def timed_sort(data):
t = time.perf_counter()
sorted(data)
return (time.perf_counter() - t) * 1000 # 毫秒
n = 2_000_000
random_data = [random.random() for _ in range(n)]
sorted_data = sorted(random_data) # 完全有序
nearly = sorted_data[:] # 幾乎有序:只打亂 0.1%
for _ in range(n // 1000):
i, j = random.randrange(n), random.randrange(n)
nearly[i], nearly[j] = nearly[j], nearly[i]
print(f"隨機資料: {timed_sort(random_data):.1f} ms")
print(f"幾乎已排序: {timed_sort(nearly):.1f} ms")
print(f"完全已排序: {timed_sort(sorted_data):.1f} ms")
在多數機器上,你會看到「完全已排序」比「隨機」快好幾倍。同一個 sorted()、同樣的 $n$,但結果差異來自資料的內在結構,而非演算法的漸近上限。這是入門篇的 big-O 視角看不見的真相。
隱藏的成本:記憶體階層與快取
現在來談一件大學課堂常常略過、但決定真實效能的事:現代 CPU 存取記憶體的速度,差距大到驚人。
從 CPU 暫存器拿一筆資料約 1 個週期;從 L1 快取約 4 個週期;從主記憶體(RAM)卻要 200 個週期以上——慢了五十倍。這意味著演算法跑得快不快,常常不取決於「做幾次運算」,而取決於「它讀記憶體的方式對快取友不友善」。
這解釋了一個違反直覺的現象:理論上較慢的演算法,有時跑得比較快。
考慮快速排序 vs. 合併排序。兩者都是 $O(n \log n)$,但快速排序通常在實務上更快,部分原因是它就地(in-place)操作,存取的記憶體位置集中、連續,對快取友善(cache-friendly)。合併排序則需要額外的輔助陣列,資料在記憶體中跳來跳去,快取命中率(cache hit rate)較差。
# 概念示意:快速排序的「分區」是連續掃描,對快取友善
def quicksort_partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high): # 從左到右「連續」掃描 → 快取喜歡這樣
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
這也是為什麼 C++ 的 std::sort 採用 introsort:它平時跑快速排序(快取友善、常數小),但會監測遞迴深度,一旦發現快速排序退化到 $O(n^2)$ 的危險(例如遇到惡意建構的輸入),就切換成堆積排序(heapsort)保底,鎖死最壞情況在 $O(n \log n)$。這是「實務速度」與「理論保證」的精妙妥協——兩個世界的握手。
搜尋的進階:當「排好序再二分」不夠用
入門篇的二分搜尋很美,但它假設資料是靜態的、放在連續陣列裡。真實系統很少這麼單純。如果資料不斷被新增、刪除,每次插入都要維持排序,移動陣列元素的成本是 $O(n)$,這會拖垮整個系統。
於是我們需要自平衡搜尋樹(如紅黑樹,red-black tree)或雜湊表(hash table)。但這裡我想介紹一個更貼近資料庫底層、卻常被大學課程忽略的結構:B 樹(B-tree)。
為什麼資料庫(MySQL、PostgreSQL)的索引幾乎都用 B 樹,而不是二元搜尋樹?答案又回到記憶體階層。當資料大到放不進 RAM、必須存在磁碟(disk)上時,每一次磁碟讀取的成本是天文數字——比 RAM 慢上萬倍。
二元搜尋樹每個節點只有 2 個分支,搜尋 $n$ 筆資料需要 $\log_2 n$ 次「跳節點」,每跳一次可能就是一次磁碟讀取。但 B 樹的每個節點可以有幾百個分支,於是樹變得又寬又矮,搜尋只需 $\log_{几百} n$ 次跳躍。對 10 億筆資料,二元樹要約 30 次磁碟讀取,B 樹可能只要 3 到 4 次。
class BTreeNode:
"""B 樹節點:一個節點裝「很多」個鍵,刻意配合磁碟分頁大小"""
def __init__(self, leaf=True):
self.keys = [] # 一個節點存數百個鍵 → 樹變矮 → 磁碟讀取次數少
self.children = [] # 分支數 = len(keys) + 1
self.leaf = leaf
def search(self, key):
i = 0
while i < len(self.keys) and key > self.keys[i]:
i += 1
if i < len(self.keys) and self.keys[i] == key:
return self # 找到了
if self.leaf:
return None # 到葉子還沒找到 → 不存在
return self.children[i].search(key) # 往下一層(可能觸發一次磁碟讀取)
關鍵設計哲學:B 樹節點的大小,刻意對齊磁碟的分頁大小(page size,通常 4KB 或 8KB)。 每讀一次磁碟,就把一整頁、塞滿數百個鍵的節點一次抓進來,最大化每次昂貴 I/O 的價值。這是「演算法設計必須臣服於硬體現實」的最佳教材——入門篇的 big-O 計數完全看不到 I/O 這個維度。
動手算一下:分支數如何壓垮樹高
假設我們要搜尋 10 億($10^9$)筆資料:
- 二元搜尋樹:樹高 $\approx \log_2(10^9) \approx 30$,最壞 30 次磁碟讀取。
- B 樹(每節點 256 個分支):樹高 $\approx \log_{256}(10^9) = \frac{\log_2 10^9}{\log_2 256} = \frac{30}{8} \approx 3.75$,約 4 次磁碟讀取。
import math
for branching in [2, 16, 256]:
height = math.log(10**9, branching)
print(f"分支數 {branching:>4}:樹高約 {height:.1f} 層 → 約 {math.ceil(height)} 次磁碟讀取")
# 分支數 2:樹高約 29.9 層 → 約 30 次磁碟讀取
# 分支數 16:樹高約 7.5 層 → 約 8 次磁碟讀取
# 分支數 256:樹高約 3.7 層 → 約 4 次磁碟讀取
從 30 次降到 4 次——這 7 倍的差距,就是你每天用 Google 或刷社群媒體時,背後讓查詢「秒回」的物理原因之一。 演算法的勝負,最終常常是在「貼著硬體設計」的層次上決定的。
重點回顧
- 比較排序有理論天花板:任何靠兩兩比較的排序,最壞情況都不可能突破 $\Omega(n \log n)$,這由決策樹高度與 $n!$ 種排列嚴格證明。要更快,必須跳出「比較」框架(如計數排序、基數排序),但得付出值域與記憶體的代價。
- 漸近複雜度不等於真實速度:兩個都是 $O(n \log n)$ 的演算法,因常數因子、資料分布、快取友善度而表現懸殊。Timsort 剝削「部分已排序」可達近 $O(n)$。
- 記憶體階層是隱形主宰:RAM 比快取慢 50 倍、磁碟比 RAM 慢上萬倍。快取友善的快速排序常勝過理論相當的合併排序;introsort 兼顧速度與保底。
- 動態資料與大資料需要不同結構:靜態陣列適合二分搜尋,但頻繁增刪需要平衡樹;資料大到上磁碟時,B 樹用「寬而矮」把昂貴的磁碟 I/O 次數壓到極低。
- 好的工程師同時看兩層:理論(big-O 保證正確性與上界)與硬體(快取、I/O、資料分布決定真實效能)缺一不可。
深入探討(研究所視角)
如果你想再往前走,這裡有幾條通往研究前沿的路徑。
Cache-oblivious 演算法。 我們談的 B 樹是 cache-aware:它必須知道分頁大小才能調參。1999 年 Frigo 等人提出 cache-oblivious 模型——設計不需知道快取參數,卻能在「任意層級的記憶體階層」上自動達到漸近最優 I/O 複雜度的演算法。代表作是 funnel sort 與遞迴式 van Emde Boas 佈局(recursive vEB layout)。其核心是把問題遞迴地切成子問題,使得在每一個未知大小的快取層級上,存取模式都恰好是局部的。這是演算法理論與系統架構交會處最深刻的成果之一。
自適應排序與 entropy 下界。 Timsort「剝削殘餘秩序」可以被嚴格形式化。對於已有 $k$ 個逆序對(inversions)的序列,存在演算法在 $O(n \log(k/n + 1))$ 時間內排好——當 $k$ 很小時趨近 $O(n)$。更一般地,自適應排序(adaptive sorting)以各種「無序度量」(measures of disorder,如 Inv、Runs、Max-Reg)為參數刻畫複雜度。Timsort 本身的最壞情況分析意外地棘手,2015 年研究者才用形式化方法(含 Coq 證明)發現並修補了其合併不變量中的一個邊界錯誤——這是「業界廣泛部署的程式碼,其正確性仍可能藏著數學漏洞」的著名案例。
Learned index structures。 2018 年 Kraska 等人提出一個顛覆性想法:索引的本質是一個函數——給定鍵,預測它在排序陣列中的位置。既然如此,何不用機器學習模型(甚至神經網路)去學習這個累積分布函數(CDF),取代 B 樹?對於分布規律的資料,learned index 可以更小、更快。這條路把「資料結構」與「機器學習」縫在一起,至今仍是資料庫頂會(SIGMOD、VLDB)的活躍題目,也是「搜尋」這個古老問題在 AI 時代的新生。
並行與外部記憶體模型。 當資料大到單機放不下,分析框架要換成 external memory model(I/O 複雜度,以 $B$ 為區塊大小、$M$ 為記憶體大小,排序下界為 $\Theta(\frac{n}{B} \log_{M/B} \frac{n}{B})$)或 PRAM / work-span 模型(並行演算法以 work 與 span 雙參數刻畫)。MapReduce 式的分散式排序、GPU 上的並行基數排序,都是這些理論的工程化身。當你下次看到「排序」兩個字時,記得它早已不是課本裡那個在單一陣列上交換元素的小程式——它是橫跨理論、硬體、分散式系統與機器學習的一整片風景。