
數字系統與進位(進階):浮點數的真相與另類進位制
從 IEEE 754 的位元拆解,到定點數、BCD、格雷碼與剩餘數系——看懂電腦如何在有限位元裡逼近實數,以及進位制的設計空間有多寬廣
為什麼 0.1 + 0.2 會等於 0.30000000000000004,而不是別的數字?
入門篇我們提過:許多十進位小數在二進位裡是「無限循環」的,所以浮點數先天無法精確存下 0.1。但這個答案其實只講了一半。真正令人不安的問題不是「為什麼有誤差」,而是「為什麼誤差恰好是 ...04,而不是 ...03 或 ...05?」這個多出來的尾巴並不是隨機雜訊——它是 IEEE 754 標準下一連串可以完全被預測、被推導的捨入(rounding)結果。
如果你能親手把 0.1、0.2 與 0.3 三個數字逐一編碼成 64 位元、再做一次浮點加法、最後解釋那個 4 從哪一個位元冒出來,那麼你對「電腦如何表達實數」的理解,就從「知道有坑」升級成「知道坑的座標」。這正是進階篇要做的事:把入門篇一筆帶過的浮點數、定點數、以及那些教科書很少提的「另類進位制」,逐一拆開來看。
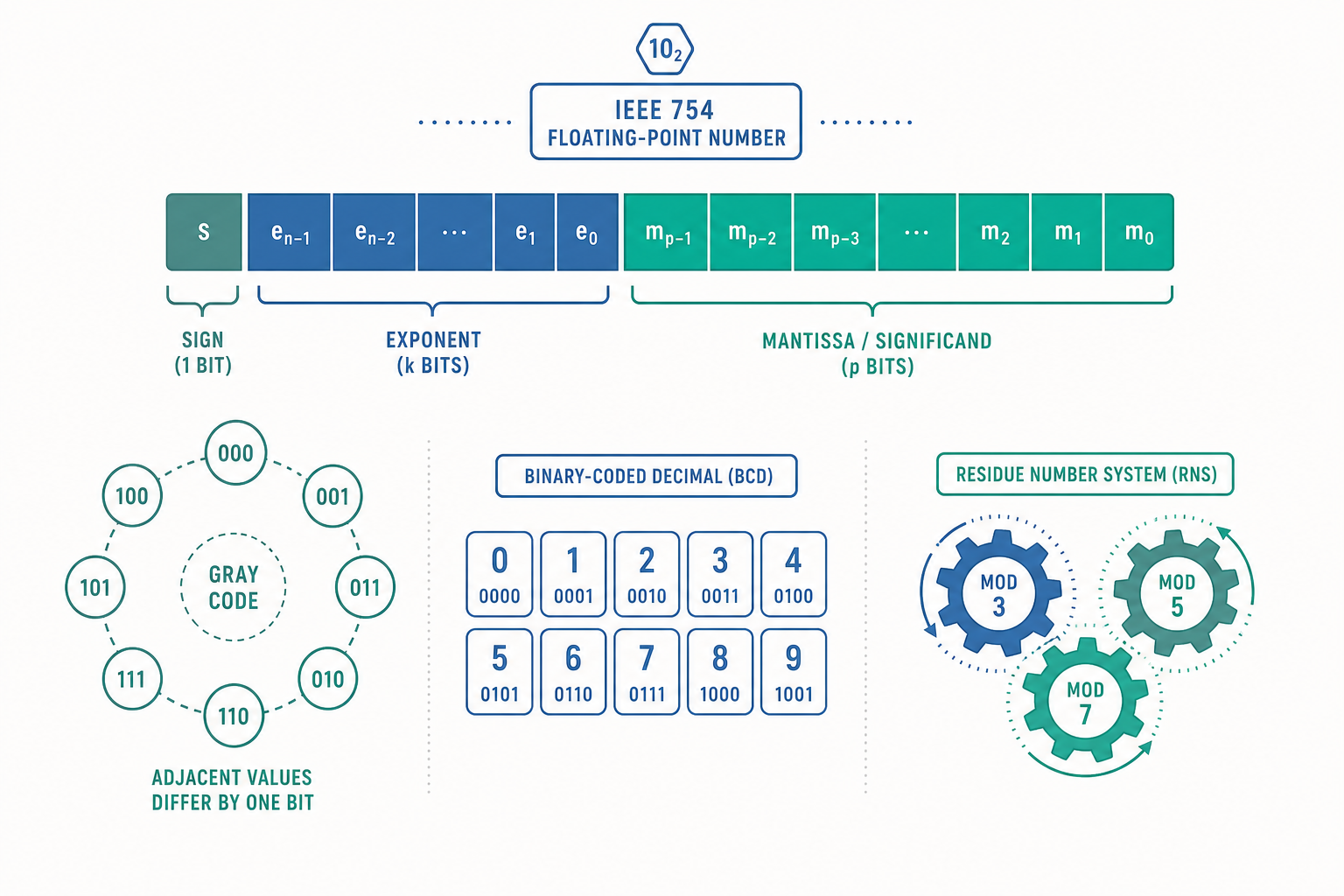
IEEE 754:把實數塞進 64 個位元的格式
入門篇談的整數,是 $\mathbb{Z}/2^n\mathbb{Z}$ 這個有限環裡的精確元素。浮點數(floating-point)則完全不同——它是用「科學記號的二進位版本」去逼近實數。十進位科學記號把 $6.022 \times 10^{23}$ 拆成符號、尾數、指數三部分,IEEE 754 做的是一模一樣的事,只是底數換成 2。
以最常用的雙精度(double precision, binary64)為例,一個浮點數佔 64 位元,切成三段:
┌─┬───────────┬──────────────────────────────────────────────────┐
│S│ exponent │ fraction (mantissa) │
│1│ 11 bits │ 52 bits │
└─┴───────────┴──────────────────────────────────────────────────┘
63 62 52 51 0
它代表的數值為:
$$(-1)^{S} \times 1.f \times 2^{(E - 1023)}$$
三個欄位各司其職:
- 符號位 $S$:0 為正、1 為負。
- 指數 $E$:11 位元的「偏移碼(biased exponent)」,實際指數要減去偏移量(bias) $1023$。為什麼用偏移而不用 2 的補數?因為這樣指數欄位可以直接當無號數比較大小,浮點數比大小就能沿用整數比較電路,硬體更省。
- 尾數 $f$:52 位元,但因為正規化(normalization)後二進位科學記號的整數部分永遠是 1,這個 1 不必存,稱為「隱藏位元(hidden bit)」。於是實際有效精度是 53 位元。
動手算一下:把 0.1 編碼成 binary64
先把 0.1 寫成二進位。用入門篇的「乘 2 取整數」法,會得到一個循環節:
0.1₁₀ = 0.0001100110011001100110011...₂ (1001 無限循環)
正規化成 $1.f \times 2^e$ 的形式,要把小數點移到第一個 1 之後:
0.000110011..._2 = 1.100110011001100..._2 × 2⁻⁴
所以指數 $e = -4$,存進去的偏移碼 $E = -4 + 1023 = 1019 = 01111111011_2$。
接著是關鍵:尾數只有 52 位元,但 $1001$ 是無限循環的,必須捨入。IEEE 754 預設用「就近捨入、逢中取偶(round to nearest, ties to even)」。把第 53 位元之後砍掉時,要看被丟棄的部分是否 $\ge$ 半個最低位(half ULP)來決定進位或捨去。對 0.1 而言,捨入的結果是尾數最後一位被「進位」了。最終 0.1 在記憶體裡實際存的是:
0 01111111011 1001100110011001100110011001100110011001100110011010
↑
最後這個 0 因捨入由 ...1001 進位成 ...1010
這個位元組合解回十進位,其實是 0.1000000000000000055511151231257827021181583404541015625,比 0.1 略大一點點。0.2 同理,存進去的值也比 0.2 略大。兩個「略大」相加,誤差累積,再經過一次結果捨入,就湊出了那個著名的 0.30000000000000004。
# 在 Python 直接驗證每個數字「真正」存了什麼
from decimal import Decimal
print(Decimal(0.1)) # 0.1000000000000000055511151231257827021181583404541015625
print(Decimal(0.2)) # 0.200000000000000011102230246251565404236316680908203125
print(Decimal(0.3)) # 0.299999999999999988897769753748434595763683319091796875
print(Decimal(0.1 + 0.2))
# 0.3000000000000000444089209850062616169452667236328125
# 注意:0.3 本身存的是「略小」,而 0.1+0.2 的結果存的是「略大」
# 兩者落在不同的可表示浮點數上,所以 0.1 + 0.2 == 0.3 為 False
print(0.1 + 0.2 == 0.3) # False
迷思澄清:這不是「Python 的 bug」,也不是「浮點數不準」。同一段邏輯在 C、Java、JavaScript、Rust 都會得到完全相同的位元結果,因為它們全都遵守 IEEE 754。誤差是確定性的、可重現的,不是隨機的。
這也帶出一個常被誤解的工程準則:永遠不要用 == 直接比較兩個浮點數。正確的做法是檢查兩者的差距是否落在可容忍的誤差範圍(epsilon)內。但要小心,固定的絕對誤差在數值很大時會失效——因為大數值的 ULP 本身就很大。因此實務上常用「相對誤差」或「ULP 距離」來比較:
import math
# math.isclose 同時考慮相對與絕對誤差,是比較浮點數的正確工具
print(0.1 + 0.2 == 0.3) # False(永遠不要這樣比)
print(math.isclose(0.1 + 0.2, 0.3)) # True(用相對誤差比較)
# rel_tol 預設 1e-9,必要時可調整;abs_tol 用於與 0 比較的場合
print(math.isclose(1e-18, 0.0)) # False(相對誤差對 0 無意義)
print(math.isclose(1e-18, 0.0, abs_tol=1e-9)) # True(與 0 比較要給 abs_tol)
特殊值:不是每個位元組合都代表普通數字
11 位元的指數欄位有 $2^{11} = 2048$ 種值,IEEE 754 把其中兩個(全 0 與全 1)保留下來表達特殊狀態:
指數欄位 尾數欄位 代表的意義
全 0 全 0 ±0 (有 +0 和 -0 兩種)
全 0 非 0 次正規數 (subnormal,填補 0 附近的空隙)
全 1 全 0 ±∞ (溢位、1.0/0.0)
全 1 非 0 NaN (Not a Number,如 0.0/0.0、√-1)
次正規數(subnormal/denormal)是個精巧設計:正規數最小只能到約 $2^{-1022}$,再小就會「斷崖式」跳到 0,造成 $a - b = 0$ 但 $a \ne b$ 的怪事。次正規數放棄隱藏位元,讓數值能平滑地「漸進歸零(gradual underflow)」,代價是精度逐漸下降。
NaN 還有一個反直覺的性質:它不等於任何值,包括它自己。這常被拿來當作偵測 NaN 的小技巧:
x = float('nan')
print(x == x) # False ← 只有 NaN 會這樣
print(x != x) # True ← 慣用的 NaN 偵測法
import math
print(math.isnan(x)) # True ← 正式寫法
半精度、單精度、雙精度:精度與範圍的取捨
並不是所有場合都需要 64 位元。位元數的選擇,本質是「動態範圍(指數位元)」與「精度(尾數位元)」之間的工程取捨。
| 格式 | 總位元 | 符號 | 指數 | 尾數 | 有效十進位位數 | 典型用途 |
|---|---|---|---|---|---|---|
| binary16(半精度,half) | 16 | 1 | 5 | 10 | 約 3.3 位 | 深度學習推論、GPU |
| binary32(單精度,float) | 32 | 1 | 8 | 23 | 約 7.2 位 | 圖學、訊號處理 |
| binary64(雙精度,double) | 64 | 1 | 11 | 52 | 約 15.9 位 | 科學計算、金融 |
近年機器學習還催生了 bfloat16:它和 binary16 一樣是 16 位元,卻把位元重新分配成「8 位指數 + 7 位尾數」,刻意保留和 binary32 相同的指數範圍。理由是訓練神經網路時,「梯度數值不要溢位/下溢」比「尾數多幾位精度」更重要——這是一個典型的「為特定應用重新切分位元」的例子,說明 IEEE 754 的欄位劃分並非神聖不可更動。
看一個例子:精度耗盡時整數會「跳號」
雙精度有 53 位有效位元,能精確表示的最大連續整數是 $2^{53}$。超過之後,相鄰可表示整數之間的間隙(ULP)會大於 1,於是某些整數根本「存不進去」:
print(2**53) # 9007199254740992
print(2**53 + 1) # 想存 9007199254740993,但...
print(float(2**53 + 1)) # 9007199254740992.0 ← 被吃掉了!
# 連續性在這裡崩潰
a = 2.0**53
print(a == a + 1) # True ← a 和 a+1 是同一個浮點數
這正是為什麼 JavaScript(所有 number 都是 binary64)要額外引入 BigInt,也是為什麼資料庫的 64 位整數主鍵絕對不能用浮點數型別來接。
定點數與 BCD:當你不能容忍捨入誤差
既然浮點數有捨入誤差,金融、會計這類「一分錢都不能錯」的系統怎麼辦?答案是換一套不依賴二進位科學記號的表示法。
定點數(fixed-point) 的想法很單純:用整數來存,但約定好小數點固定在某個位置。例如用整數存「分」而非「元」,$\$ 12.34$ 就存成整數 1234。所有運算都是精確的整數運算,最後顯示時再插回小數點。
# 用整數做「分」的精確金額運算,完全沒有浮點誤差
price_cents = 10 # 0.10 元
tax_cents = 20 # 0.20 元
total = price_cents + tax_cents
print(f"{total // 100}.{total % 100:02d}") # 0.30 ← 精確!
# Python 的 Decimal 則提供十進位浮點,兼顧精確與小數運算
from decimal import Decimal
print(Decimal('0.1') + Decimal('0.2')) # 0.3 ← 精確
print(Decimal('0.1') + Decimal('0.2') == Decimal('0.3')) # True
BCD(Binary-Coded Decimal,二進位編碼十進位) 則是另一條路:不把整個數字轉成二進位,而是「每一個十進位數字各用 4 位元獨立編碼」。例如十進位 $59$ 在 BCD 裡是 0101 1001,而不是真正的二進位 $111011$。
十進位 5 9
↓ ↓
BCD 0101 1001 → 0101 1001
BCD 的代價是浪費——4 位元本可表示 0–15,卻只用到 0–9,浪費了 6 種組合。但它的好處是「沒有十進位↔二進位的轉換誤差」,且方便驅動七段顯示器。早期計算機、金融大型主機(IBM 的 zSeries 至今仍有硬體 decimal 指令)、以及許多計算機晶片都用 BCD。IEEE 754 在 2008 年版甚至正式納入了 decimal64/decimal128 十進位浮點格式,專門服務金融運算。
那些教科書很少提的「另類進位制」
入門篇談的二進位、八進位、十六進位都是「整數基底、固定權重」的位值制。但數字系統的設計空間遠比這寬廣,以下幾種在特定領域大放異彩。
格雷碼(Gray code) 的特色是:相鄰兩個數字的編碼只差一個位元。一般二進位從 3(011)跳到 4(100)時三個位元同時翻轉,在機械式旋轉編碼器上,三個位元不可能瞬間同步切換,中間可能短暫讀到 111(=7) 這種完全錯誤的值。格雷碼避免了這個問題。
十進位 標準二進位 格雷碼
0 000 000
1 001 001
2 010 011 ← 相鄰只差 1 位
3 011 010
4 100 110
5 101 111
6 110 101
7 111 100
def to_gray(n: int) -> int:
"""二進位轉格雷碼:n XOR (n 右移一位)"""
return n ^ (n >> 1)
def from_gray(g: int) -> int:
"""格雷碼轉回二進位"""
n = 0
while g:
n ^= g
g >>= 1
return n
for i in range(8):
print(i, format(to_gray(i), '03b'))
# 驗證每一行的格雷碼與上一行只差一個位元
剩餘數系(Residue Number System, RNS) 則徹底拋棄位值制。它用一組互質的模數 $\{m_1, m_2, \dots, m_k\}$,把一個數 $X$ 表示成它對每個模數的餘數 $(X \bmod m_1, X \bmod m_2, \dots)$。神奇之處在於:加法、減法、乘法都可以對每個餘數獨立、並行地做,完全沒有進位(carry)在位與位之間傳遞的延遲。
取模數 {3, 5, 7}(可表示 0 到 3×5×7−1 = 104)
10 → (10%3, 10%5, 10%7) = (1, 0, 3)
7 → ( 7%3, 7%5, 7%7) = (1, 2, 0)
───────────────────────────────────────
各分量獨立相加再取模:
(1+1)%3, (0+2)%5, (3+0)%7 = (2, 2, 3)
還原 → 17 (10 + 7 = 17 ✓,由中國剩餘定理還原)
沒有進位鏈,意味著超大整數的加法可以無視位數一次算完,這在某些高效能 DSP 與密碼學硬體中很有價值。代價是「比大小」和「除法」變得很麻煩——天下沒有白吃的午餐。
值得一提的還有有號位元表示法(signed-digit representation),它允許每一位數使用負值,例如非相鄰形式(Non-Adjacent Form, NAF)讓二進位的每一位可以是 $-1$、$0$、$1$。這乍看多此一舉,卻能讓「1 的個數」最小化,在乘法器與密碼學的「平方-乘法(square-and-multiply)」指數運算中大幅減少所需的加法次數。這再次說明:進位制不是只有「一種符號集合配一種基底」這麼單純,符號集合本身也是可以設計的變數,工程師會依運算成本來量身打造。
重點回顧
- IEEE 754 是逼近不是儲存:浮點數用「符號 + 偏移指數 + 隱藏位元尾數」逼近實數,
0.1 + 0.2的誤差是捨入規則(就近、逢中取偶)導致的確定性結果,不是隨機雜訊。 - 指數用偏移碼、尾數有隱藏位元:偏移碼讓浮點數能沿用整數比較電路;隱藏位元讓 52 位尾數提供 53 位有效精度。
- 位元數是工程取捨:half/float/double 在「動態範圍」與「精度」間權衡;bfloat16 為深度學習刻意保留大指數、犧牲尾數,證明欄位劃分可依應用重新設計。
- 精確需求改用定點數或 BCD:金融系統用整數定點或 Decimal 避開捨入誤差;BCD 以每位 4 bit 換取無轉換誤差與顯示便利。
- 進位制設計空間很大:格雷碼讓相鄰碼只差一位、抗讀取錯誤;剩餘數系拋棄位值制換取無進位鏈的並行運算。
深入探討(研究所視角)
把浮點數放進數值分析的框架,會看到一個更銳利的圖像。IEEE 754 的捨入運算可以形式化為 $\text{fl}(x) = x(1 + \delta)$,其中 $|\delta| \le u$,$u$ 是單位捨入誤差(unit roundoff),對 binary64 約為 $2^{-53} \approx 1.1 \times 10^{-16}$。這個簡單的模型是整個誤差分析的基石:它讓我們能對一連串浮點運算做「向後誤差分析(backward error analysis)」,證明「計算出的結果,是某個被微擾過的輸入的精確解」。災難性抵消(catastrophic cancellation)——兩個相近的數相減導致有效位元大量喪失——正是在這個框架下被精確量化的,也是為什麼數值穩定的演算法(如計算 $\sqrt{x^2+1}-1$ 時改寫成 $\frac{x^2}{\sqrt{x^2+1}+1}$)如此重要。
更前沿的方向是對 IEEE 754 本身的挑戰。近年由 John Gustafson 提出的 posit(unum III) 數字格式主張用「動態長度的指數區段(regime)」取代固定寬度的指數欄位:數值越接近 1,分配的尾數位元越多、精度越高;越極端則精度越低。這呼應了「實際運算中的數值大多集中在中等量級」的統計觀察,在相同位元數下對常見數值範圍能提供更高精度,且只有一個 NaN、沒有 ±0 的二義性。posit 是否能取代 IEEE 754 仍有爭議,但它揭示了一個核心洞見:浮點格式的欄位劃分本質上是一個「在固定位元預算下,如何把精度分配給不同數值範圍」的最佳化問題,而 IEEE 754 的均勻指數只是眾多解之一。
最後值得連結的是 RNS 與抽象代數、乃至後量子密碼學的關聯。剩餘數系背後是中國剩餘定理(Chinese Remainder Theorem),它在數學上建立了環同構 $\mathbb{Z}/(m_1 m_2 \cdots m_k)\mathbb{Z} \cong \mathbb{Z}/m_1\mathbb{Z} \times \cdots \times \mathbb{Z}/m_k\mathbb{Z}$。這個同構不只是 RNS 並行運算的理論依據,更是 RSA 解密加速、以及格密碼(lattice-based cryptography)中 NTT(數論變換)等運算的數學引擎。當你問「電腦如何表示一個數」時,答案最終會把你帶到環論、同態與計算複雜度的交界——數字系統從來不只是入門課題,而是一張通往現代計算理論與密碼學深處的地圖。