
Java 與 JVM 進階:記憶體模型、垃圾回收與類別載入的真相
當多執行緒共享同一片堆積,「順序」與「可見性」不再理所當然——深入 JMM、GC 演算法權衡與延遲初始化
兩個執行緒讀寫同一個變數,為什麼結果可能違反你對「順序」的直覺?
入門篇把 JVM 當成一個忠實的翻譯機:位元碼(bytecode)丟進去,機器碼吐出來,垃圾回收(Garbage Collection,GC)自動把死掉的物件收走。這個圖像在單執行緒的世界裡夠用了。但現代企業系統幾乎都是多執行緒的——一台伺服器同時服務上千個請求,這些請求的執行緒共享同一片堆積(Heap)裡的物件。一旦多個執行緒同時讀寫同一塊記憶體,事情就變得反直覺到令人不安。
看這段程式:一個執行緒不斷把 ready 設成 true、把 value 設成 42;另一個執行緒等到看見 ready 為 true 時,把 value 印出來。
public class Surprise {
static int value = 0;
static boolean ready = false;
public static void main(String[] args) throws InterruptedException {
Thread writer = new Thread(() -> {
value = 42; // (1)
ready = true; // (2)
});
Thread reader = new Thread(() -> {
while (!ready) { } // (3) 等待
System.out.println(value); // (4)
});
reader.start();
writer.start();
}
}
憑直覺,讀取執行緒看到 ready 為 true(離開迴圈)後,理應印出 42。但在沒有適當同步的情況下,這段程式可能印出 0,甚至可能永遠卡在迴圈裡跑不完。寫入執行緒明明先設 value 再設 ready,為什麼另一個執行緒會看到一個「ready 已變、value 未變」的矛盾世界?
答案藏在入門篇刻意沒打開的盒子裡:Java 記憶體模型(Java Memory Model,JMM)。這篇文章我們要深入 JVM 在多執行緒下的真實行為、GC 演算法的內部權衡,以及類別載入的精細機制——這些都是把 Java 從「會寫」推向「懂得為什麼」的關鍵。
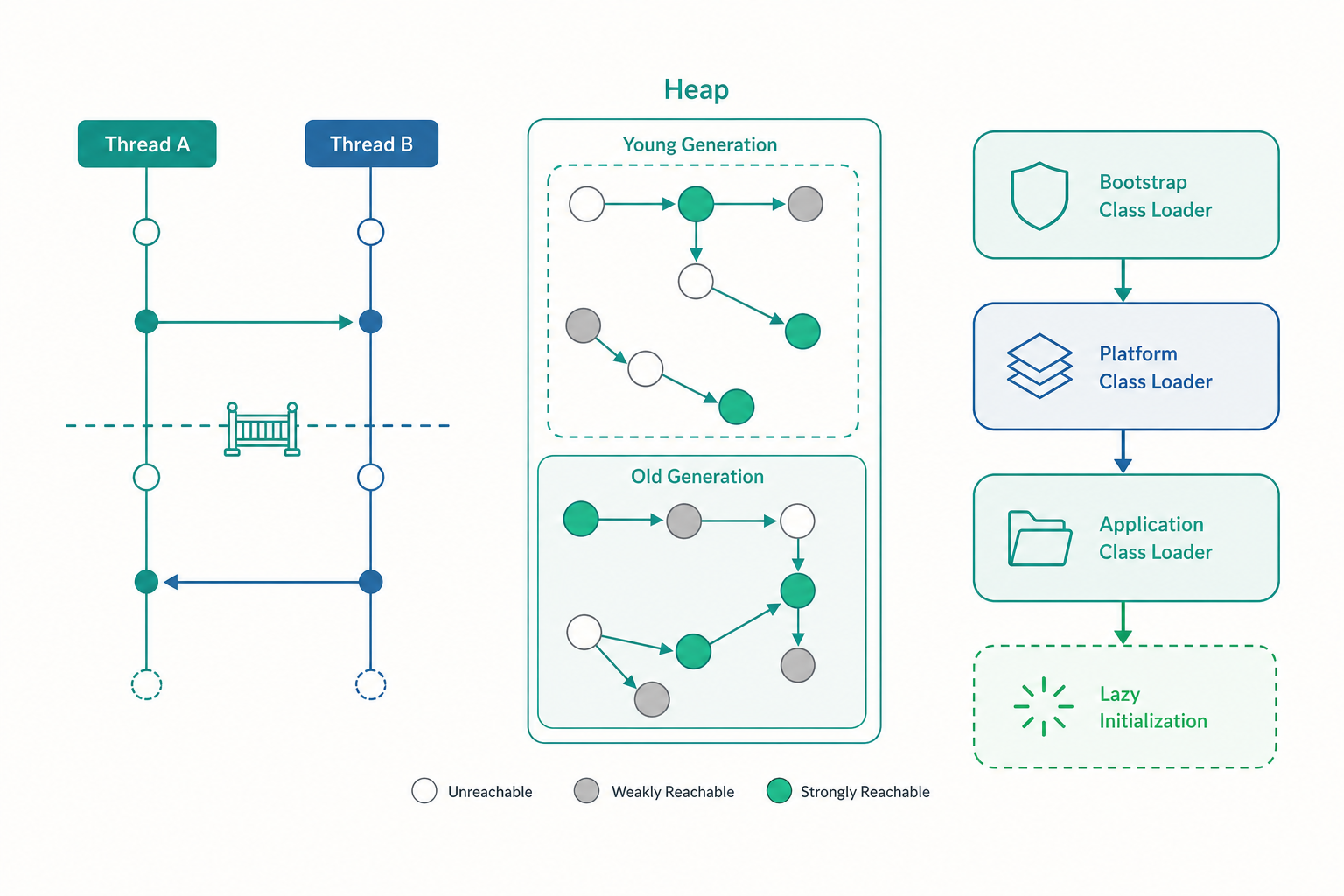
重排序與可見性:編譯器和 CPU 都在「動手腳」
上面那段程式之所以詭異,是因為在你和硬體之間,有兩層都會偷偷重排你的指令順序。
第一層是 JIT 編譯器。 入門篇談過即時編譯(Just-In-Time,JIT)會把熱點程式碼最佳化成機器碼。最佳化的手段之一就是指令重排序(reordering):只要在單一執行緒看來結果不變,編譯器就有權調換指令順序。對寫入執行緒而言,先設 value 還是先設 ready,在「它自己」看來毫無差別,所以編譯器完全可以把 (1) 和 (2) 對調。
第二層是 CPU 與快取。 即使編譯器不動,現代多核心 CPU 每顆核心有自己的快取(cache)。寫入執行緒把 value = 42 寫進的可能只是它那顆核心的快取,還沒同步到主記憶體;而讀取執行緒在另一顆核心上,看到的是它自己快取裡的舊值。兩顆核心對「現在記憶體長什麼樣」的認知可以暫時不一致——這就是可見性(visibility)問題。
所以「value = 42 先發生,所以另一個執行緒一定看得到」這個推論是錯的。在多執行緒下,沒有同步機制,一個執行緒的寫入何時、是否會被另一個執行緒看見,完全沒有保證。這不是 JVM 的 bug,而是所有現代語言(C++、Go 都一樣)為了榨出效能必須付出的代價。
JMM 的存在,就是為了在「效能(允許重排)」與「正確(程式設計師能推理)」之間,劃出一條明確的契約。
happens-before:JMM 給你的唯一保證
JMM 的核心是一個叫 happens-before(先行發生) 的偏序關係。它的意義非常精確:
若動作 A happens-before 動作 B,則 A 的所有記憶體寫入,對 B 都是可見的,且 A 不會被重排到 B 之後。
注意「happens-before」講的不是時間先後,而是可見性與順序的保證。兩個動作在時間上有先後、卻沒有 happens-before 關係,那麼後發生的那個也不保證看得見前一個的結果。JMM 規定了幾條會自動建立 happens-before 的規則,最常用的是:
- 程式順序規則:同一個執行緒內,前面的動作 happens-before 後面的動作。
- 監視鎖規則:對一把鎖的解鎖 happens-before 後續對同一把鎖的加鎖。
- volatile 規則:對
volatile變數的寫入 happens-before 後續對同一變數的讀取。 - 執行緒啟動規則:
thread.start()happens-before 該執行緒內的任何動作。 - 傳遞性:A happens-before B、B happens-before C,則 A happens-before C。
回到開頭的問題:寫入執行緒裡 (1) happens-before (2)(程式順序規則),但 (2) 和讀取執行緒的 (3) 之間沒有任何 happens-before 關係——ready 只是個普通變數,跨執行緒的讀寫不在規則涵蓋內。於是讀取執行緒看到 (2) 的結果時,並不保證能看到 (1) 的結果。整條推理鏈在這裡斷掉。
看一個例子:用 volatile 修好它
最小的修法是把 ready 宣告成 volatile:
public class Fixed {
static int value = 0;
static volatile boolean ready = false; // 關鍵:volatile
public static void main(String[] args) throws InterruptedException {
Thread writer = new Thread(() -> {
value = 42; // (1)
ready = true; // (2) 對 volatile 變數寫入
});
Thread reader = new Thread(() -> {
while (!ready) { } // (3) 對 volatile 變數讀取
System.out.println(value); // (4) → 保證印出 42
});
reader.start();
writer.start();
}
}
關鍵推理鏈是這樣串起來的:
- (1) happens-before (2):同執行緒程式順序。
- (2) happens-before (3):volatile 規則——對
ready的寫入 happens-before 後續對ready的讀取。 - (3) happens-before (4):同執行緒程式順序。
- 由傳遞性,(1) happens-before (4):所以讀取執行緒在 (4) 一定看得見
value = 42。
值得玩味的是:value 自己並不是 volatile,卻因為「搭上了」ready 這個 volatile 變數建立的 happens-before 邊,它的寫入也被保證可見。volatile 不只保證該變數自己的可見性,還像一道記憶體屏障(memory barrier):寫入 volatile 之前的所有寫入,都不能被重排到它之後,並會一起被刷新到主記憶體。這就是它能「順便」修好 value 的原因。
一個常見迷思要在這裡澄清:volatile 不能取代 synchronized。它只保證可見性與禁止重排,不保證原子性(atomicity)。count++ 即使 count 是 volatile,仍是「讀—改—寫」三步,兩個執行緒同時做會互相覆蓋。要原子遞增,得用 synchronized、AtomicInteger,或 java.util.concurrent 裡的工具。
GC 不是魔法:分代、停頓與吞吐量的權衡
入門篇說 GC 會「在適當時機自動回收」。研究這個「適當時機」與「怎麼回收」,會發現 GC 是 JVM 工程裡權衡最深的一塊。
所有現代 JVM 的 GC 都建立在一個經驗觀察上,叫弱分代假說(weak generational hypothesis):絕大多數物件出生後很快就死,活很久的物件相對稀少。 想想我們寫的程式,迴圈裡 new 出來的臨時字串、方法內的暫存物件,往往用完即丟。
基於這個假說,堆積被切成新生代(Young Generation)與老年代(Old Generation):
- 新物件先配置在新生代。新生代的回收(Minor GC)很頻繁,但因為大部分物件已死,只要把少數倖存者複製出來、整片清空即可,非常快。
- 在新生代熬過數次回收的「老兵」會被晉升(promote)到老年代。老年代的回收(Major / Full GC)較少發生,但範圍大、較慢。
GC 怎麼判斷一個物件「死了」?不是用引用計數(reference counting,那會被循環引用騙過),而是可達性分析(reachability analysis):從一組 GC Roots(執行緒堆疊上的區域變數、靜態欄位等)出發,沿引用走訪,走得到的物件就是活的,走不到的就是垃圾。這天生不怕循環引用——兩個互相指、但沒人從 root 指得到的物件,照樣被判定為垃圾回收掉。
三個你必須懂的指標
評價一個 GC 策略,看三個彼此拉扯的指標:
| 指標 | 意義 | 誰最在乎 |
|---|---|---|
| 吞吐量(throughput) | 單位時間能做多少有用工作(非 GC 時間佔比) | 批次運算、離線分析 |
| 延遲 / 停頓(latency / pause) | 單次 GC 讓應用「卡住」多久 | 線上交易、即時服務 |
| 記憶體足跡(footprint) | 為了達成上述兩者要付出多少額外記憶體 | 容器、邊緣裝置 |
這三者是不可能三角:想要停頓短,往往得犧牲吞吐量或多吃記憶體。所以 JVM 提供多種 GC 演算法讓你依場景選擇,而不是一招打天下。
動手算一下:停頓時間怎麼估
假設一個服務的堆積有 4 GB,採用會「停止全世界(Stop-The-World,STW)」的回收器,標記與整理的速度約為每秒處理 2 GB 存活物件,而某次 Full GC 時老年代有 1.5 GB 存活物件。粗估這次的停頓:
$$ \text{停頓} \approx \frac{1.5\ \text{GB}}{2\ \text{GB/s}} = 0.75\ \text{秒} $$
750 毫秒對一個要求「99 分位延遲低於 100 毫秒」的線上交易系統是災難——這 0.75 秒內,所有應用執行緒全部凍結。這正是為什麼大堆積、低延遲場景不能用傳統 STW 回收器。現代的 G1(Garbage-First) 把堆積切成許多小區塊(region),優先回收垃圾最多的區塊,並讓大部分標記工作與應用執行緒並行(concurrent)進行,把單次停頓壓到可預測的數十毫秒。再進一步的 ZGC 與 Shenandoah 透過讀屏障(load barrier)與並行整理,能在 TB 級堆積上把停頓壓到毫秒以下,代價是吞吐量略降、實作複雜度高。
實務上你可以這樣指定與觀察:
# 選用 G1(較新的 JDK 預設就是 G1)
java -XX:+UseG1GC -Xmx4g -Xlog:gc MyApp
# 想要極低延遲,TB 級堆積,選 ZGC
java -XX:+UseZGC -Xmx16g -Xlog:gc MyApp
-Xlog:gc 會把每次 GC 的類型、回收前後堆積大小、停頓時間印出來。調 GC 的第一守則是先量再調——憑感覺亂加參數,常常讓事情更糟。
類別載入:執行期才綁定的延遲魔法
入門篇提過類別載入子系統與雙親委派模型(parent delegation model)。這裡我們看一個它帶來的、會直接影響你寫程式判斷的具體行為:類別在「第一次被主動使用」時才載入與初始化,而不是程式一啟動就全部載入。
看一個例子:靜態初始化的時機
public class LazyInit {
static class Heavy {
static {
System.out.println(">> Heavy 的 static 區塊執行了");
}
static final int X = 100;
static int y = compute();
static int compute() {
System.out.println(">> compute() 被呼叫");
return 42;
}
}
public static void main(String[] args) {
System.out.println("程式開始");
System.out.println("常數 X = " + Heavy.X); // (A)
System.out.println("欄位 y = " + Heavy.y); // (B)
}
}
輸出是:
程式開始
常數 X = 100
>> Heavy 的 static 區塊執行了
>> compute() 被呼叫
欄位 y = 42
兩個反直覺的點:
- 存取
Heavy.X並沒有觸發Heavy的初始化(static 區塊沒印)。因為X是static final的編譯期常數(compile-time constant),它在編譯時就被內聯(inline)成字面值100直接嵌進main裡,根本不需要碰Heavy這個類別。 - 直到存取
Heavy.y(非常數的靜態欄位)才真正初始化Heavy:這時 static 區塊與compute()才依序執行。
這個「延遲初始化」不是小細節。它解釋了為什麼有時你以為某段 static 初始化早就跑了、實際卻還沒跑;也是許多單例(singleton)模式與設定載入 bug 的根源。理解「主動使用才初始化」這條規則,你才能精準預測程式的初始化順序。
順帶一提,「初始化的執行緒安全」是 JVM 免費送你的:JVM 保證一個類別的初始化過程是執行緒安全的,多執行緒同時首次使用同一個類別,只有一個會執行初始化,其餘會等它完成。這讓「靜態持有者(holder)」成為實作執行緒安全延遲單例最優雅的方式之一,不需要任何顯式鎖。
重點回顧
- 在多執行緒下,沒有同步就沒有可見性與順序保證:JIT 重排序與 CPU 快取會讓一個執行緒看到另一個執行緒「不一致的世界」。
- JMM 用 happens-before 提供唯一的推理依據;
volatile、synchronized、執行緒啟動等會建立 happens-before 邊。volatile保證可見性與禁止重排,但不保證原子性。 - GC 建立在弱分代假說之上,用可達性分析(而非引用計數)判定垃圾;吞吐量、延遲、記憶體足跡構成不可能三角,G1/ZGC 用並行與分區換取可預測的低停頓。
- 類別第一次被主動使用時才初始化;
static final編譯期常數會被內聯,不觸發初始化。JVM 保證類別初始化的執行緒安全。
深入探討(研究所視角)
把上面三條線拉到研究所層次,會看到它們背後共同的理論骨架。
JMM 是一套「公理化的記憶體模型」。 它並非描述某顆 CPU 的行為,而是定義一個抽象的、允許重排的執行語意,再用 happens-before 限制哪些執行是「合法(well-formed)」的。形式化的核心問題是資料競爭(data race):當兩個動作存取同一變數、至少一個是寫入、且彼此沒有 happens-before 關係時,就構成資料競爭。JMM 提供著名的 DRF-SC 保證(Data-Race-Free implies Sequential Consistency):只要你的程式沒有資料競爭,JVM 就保證它的行為等同於某種「循序一致(sequentially consistent)」的執行——也就是符合你天真的直覺。換句話說,正確使用同步原語的程式,可以完全不必去想重排序;重排只會在有競爭的程式裡咬你。這是一條極其優雅的設計:把「允許激進最佳化」與「程式設計師可推理」用一條定理連起來。實作上,volatile 寫入會被編譯成適當的記憶體屏障(如 x86 的 store-load fence),不同硬體記憶體模型(x86 的 TSO、ARM 的弱序)需要插入的屏障強度不同,JMM 正是抹平這層硬體差異的抽象。
GC 的本質是並行圖追蹤問題。 並行回收器最難的點在於:應用執行緒(mutator)在回收器標記存活物件的同時,還在不斷修改物件間的引用。若處理不當,會發生「標記遺漏」——一個本來活的物件被誤判為垃圾而回收,導致記憶體損毀。理論上的判準是三色標記不變式(tri-color invariant):把物件染成白(未訪問)、灰(已訪問但引用尚未掃完)、黑(已完全掃完)三色,危險情境是「一個黑物件指向白物件,且通往該白物件的所有灰路徑都被切斷」。回收器必須用寫屏障(write barrier) 攔截引用更新來維持不變式,分為 SATB(snapshot-at-the-beginning,G1 採用)與 incremental-update 兩大流派。ZGC 更進一步用著色指標(colored pointers) 加 load barrier,把物件搬移與引用修正攤平到每次讀取,達成並行整理。理解這層,你才明白為什麼「低停頓 GC」不是把演算法改快,而是把工作從一次性的 STW 重新分配到 mutator 的每次讀寫上——天下沒有白吃的午餐,停頓變短的代價是 barrier 帶來的常態化吞吐量損耗。
類別載入是 JVM 動態性與安全性的交會點。 雙親委派模型本質上是一套命名空間隔離機制:類別的執行期身份是 (全限定名, 定義它的 ClassLoader) 這個二元組,而非僅僅是名字。這意味著同一個 com.example.Foo,被兩個不同的 ClassLoader 載入,會是兩個互不相容的型別——這正是應用伺服器能讓多個 web 應用各自隔離、OSGi 能做模組熱抽換、外掛系統能動態載卸的底層機理,但也是 ClassCastException: Foo cannot be cast to Foo 這種看似荒謬錯誤的來源。配合執行期的反射(reflection)、MethodHandle 與 invokedynamic 指令(Lambda 與許多 JVM 語言的實作基礎),Java 在「靜態強型別的編譯期安全」之外,保有了一套強大的執行期動態能力。整個 JVM 的設計哲學,到這裡可以收束成一句話:用一層精心設計的虛擬機器抽象,在編譯期安全、執行期彈性、跨平台可移植、與並行高效能之間,同時拿到原本看似互斥的多個目標。 這正是它能支撐三十年企業級系統的根本理由。