
文字與多媒體編碼(進階):代理對、正規化與字素叢集
為什麼「café」的長度時而是 4 時而是 5?深入 UTF-16 代理對、Unicode 正規化、字素叢集、定序與同形字攻擊
為什麼「café」的長度有時是 4,有時是 5?
你在入門篇學會了 ASCII、Unicode 碼點(code point)與 UTF-8 變長編碼,也理解了亂碼怎麼來。看起來文字編碼似乎已經是個「解決了的問題」。但請先在 Python 試試下面這段:
a = "café" # 直接打出 é
b = "café" # e 後面接一個「結合重音符號」U+0301
print(a == b) # False ❗
print(len(a), len(b)) # 4 5
print(a, b) # 看起來一模一樣:café café
兩個字串螢幕上長得完全一樣,使用者也覺得它們是同一個詞,但電腦判定它們不相等、長度還不同。如果你的系統把這兩者當成不同帳號、不同檔名、不同密碼,麻煩就大了。這不是 bug,而是 Unicode 設計的必然結果——「一個使用者眼中的字」與「一個碼點」根本不是同一回事。進階篇要帶你穿過 UTF-8 表面,進入 UTF-16 的代理對、位元組序、正規化、字素叢集、定序,以及隱藏在網址列裡的同形字攻擊。這些才是真正讓工程師在生產環境踩坑的地方。
UTF-16 與代理對:當 16 位元不夠用
入門篇主打 UTF-8,但你會在 Java、JavaScript、C#、Windows API 與許多資料庫內部碰到另一種編碼:UTF-16。理解它的設計,才能解釋為什麼 JavaScript 的 "😀".length 是 2 而不是 1。
Unicode 早期天真地以為 16 位元(65536 個位置)足以容納人類所有文字,於是設計了固定 2 位元組的編碼。這個「基本多文種平面(Basic Multilingual Plane, BMP)」涵蓋 U+0000 到 U+FFFF。但後來 emoji、罕用漢字、歷史文字湧入,碼點突破了 U+FFFF。怎麼用 16 位元的單位塞下更大的數字?答案是代理對(surrogate pair)。
Unicode 特地保留了一段不對應任何真實字元的區間當作「拼接零件」:
- 高位代理(high surrogate):
U+D800–U+DBFF - 低位代理(low surrogate):
U+DC00–U+DFFF
任何超過 BMP 的碼點(U+10000 以上),都用「一個高位代理 + 一個低位代理」兩個 16 位元單位來表示。轉換公式如下,給定碼點 $C \geq \text{0x10000}$:
$$C' = C - \text{0x10000}, \quad \text{high} = \text{0xD800} + \left\lfloor \frac{C'}{\text{0x400}} \right\rfloor, \quad \text{low} = \text{0xDC00} + (C' \bmod \text{0x400})$$
動手算一下:把 😀 拆成代理對
笑臉 😀 的碼點是 U+1F600。我們手動跑一遍上面的公式:
C = 0x1F600 = 128512
C' = C - 0x10000 = 0xF600 = 62976
high = 0xD800 + (62976 // 1024)
= 0xD800 + 61
= 0xD800 + 0x3D = 0xD83D
low = 0xDC00 + (62976 % 1024)
= 0xDC00 + 512
= 0xDC00 + 0x200 = 0xDE00
所以 😀 在 UTF-16 中是兩個單位:D83D DE00。用 Python 驗證:
ch = "😀"
print(ord(ch)) # 128512 → 單一碼點
print(ch.encode("utf-16-be").hex()) # d83dde00 → 兩個 16 位元單位
print(ch.encode("utf-8").hex()) # f09f9880 → UTF-8 則用 4 位元組
# JavaScript 的 length 數的是 UTF-16 單位數,所以:
print(len(ch.encode("utf-16-be")) // 2) # 2
這就解釋了為什麼許多語言對「字串長度」的回答南轅北轍:它們其實在數編碼單位,而不是數字元。Python 3 的 len() 數的是碼點數(所以 len("😀") 是 1),但 JavaScript 與 Java 數的是 UTF-16 單位數(所以是 2)。沒有哪個是錯的,只是定義不同——而這正是跨語言處理文字時 bug 的溫床。
位元組序與 BOM:誰先誰後?
UTF-8 因為以單位元組為基本單位,不存在順序問題。但 UTF-16 與 UTF-32 的每個單位都跨越多個位元組,於是冒出一個古老的硬體問題:位元組序(endianness)。
以 16 位元單位 0x4E2D(「中」)為例,要寫進記憶體或檔案時,是先寫 4E 還是先寫 2D?
- 大端序(big-endian, BE):高位元組在前 →
4E 2D - 小端序(little-endian, LE):低位元組在前 →
2D 4E
x86/ARM 處理器多採小端序,網路傳輸協定多採大端序。為了讓讀取方知道該用哪種,檔案開頭可放一個位元組順序記號(Byte Order Mark, BOM),即碼點 U+FEFF:
text = "中"
print(text.encode("utf-16").hex()) # fffe2d4e → 含 BOM(fffe=LE) + 資料 2d4e
print(text.encode("utf-16-le").hex()) # 2d4e → 明確指定 LE,無 BOM
print(text.encode("utf-16-be").hex()) # 4e2d → 明確指定 BE,無 BOM
UTF-8 理論上不需要 BOM,但 Windows 上某些程式(如舊版記事本)會自作主張在 UTF-8 檔案前加上 EF BB BF(即 U+FEFF 的 UTF-8 編碼)。這個「UTF-8 BOM」經常惹禍:shell 腳本第一行的 #! 前多了三個隱形位元組導致無法執行、CSV 第一欄欄名前多了怪字元、JSON 解析器報錯。看到檔案開頭莫名其妙的 ,幾乎都是它。
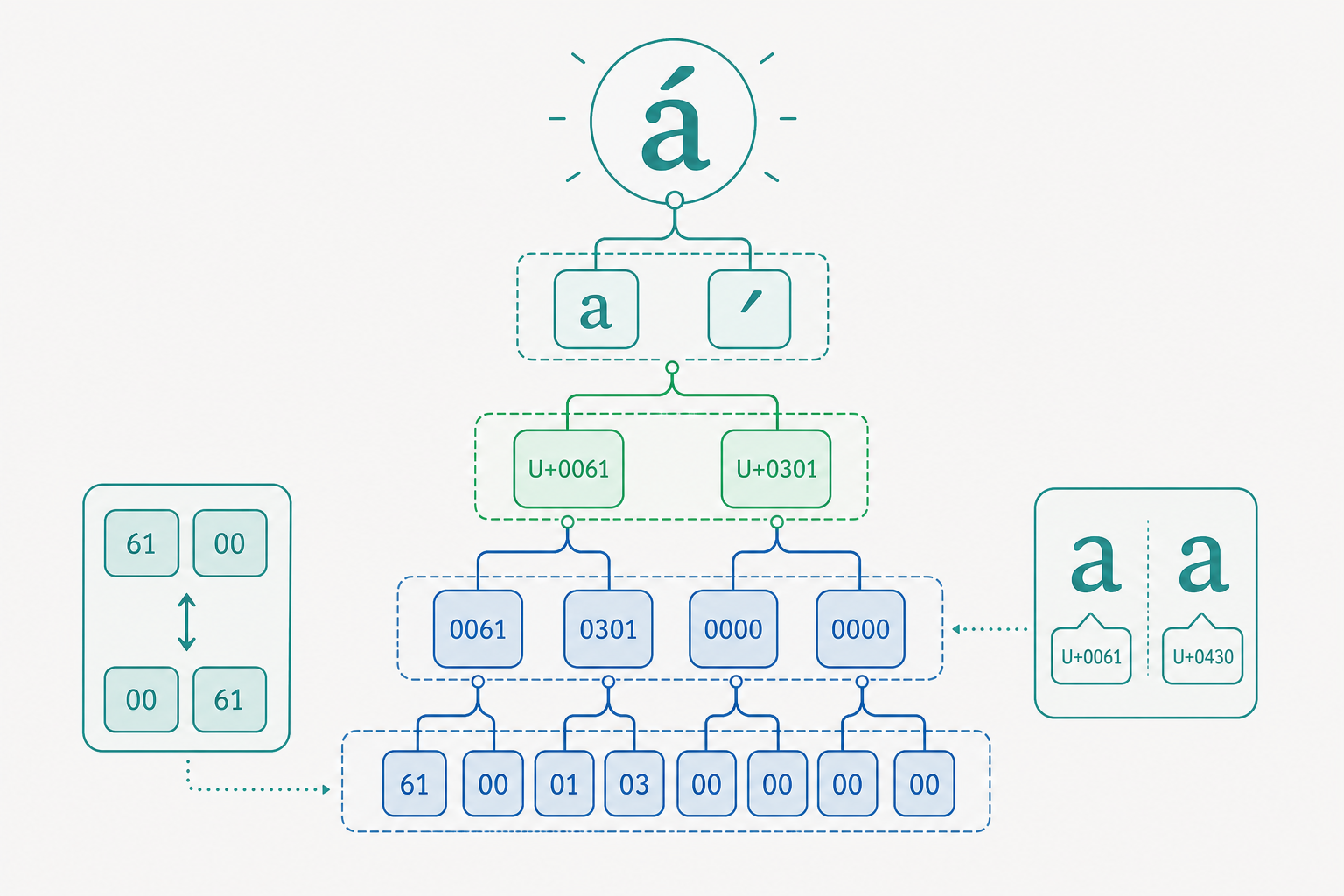
正規化:讓「看起來一樣」真的「相等」
回到開頭的 café 謎題。問題根源是 Unicode 對同一個視覺字元常提供多種合法的碼點組合:
- 預組合(precomposed):
é=U+00E9,單一碼點。 - 分解(decomposed):
é=e(U+0065) + 結合銳音符(U+0301),兩個碼點。
兩者語意相同、外觀相同,但位元組不同。為了讓比較與搜尋有意義,Unicode 定義了正規化(normalization),把字串轉成標準形式。四種形式中最常用兩種:
- NFC(Normalization Form C):盡量組合成預組合字元(較短,網頁、檔名推薦)。
- NFD(Normalization Form D):盡量分解成基底 + 結合符(某些語言學處理需要)。
import unicodedata
a = "café" # 預組合,4 碼點
b = "café" # 分解,5 碼點
print(a == b) # False
print(unicodedata.normalize("NFC", a) ==
unicodedata.normalize("NFC", b)) # True ✅
# 另一類:相容分解 NFKC 會把「視覺變體」也統一
print(unicodedata.normalize("NFKC", "①")) # 1
print(unicodedata.normalize("NFKC", "fi")) # fi(連字 → 兩個字母)
print(unicodedata.normalize("NFKC", "2026")) # 2026(全形 → 半形)
實務鐵則:任何要拿來比較、當索引鍵、做唯一性檢查的字串,都應先正規化(通常用 NFC)。使用者註冊名稱、檔案系統路徑、URL、密碼欄位若不正規化,就會出現「明明打一樣卻說帳號不存在」的靈異事件。NFKC 則更激進,連全形數字、上標、連字都拉平,適合搜尋與安全檢查,但會丟失格式資訊,需謹慎使用。
字素叢集:使用者眼中的「一個字」
現在來面對最反直覺的一層。問你:👨👩👧👦(一家四口 emoji)是「幾個字」?使用者會說「一個」。但它在底層是這樣的:
family = "👨👩👧👦"
print(len(family)) # 7(Python 數碼點)
print([hex(ord(c)) for c in family])
# ['0x1f468', '0x200d', '0x1f469', '0x200d', '0x1f467', '0x200d', '0x1f466']
# 👨 + ZWJ + 👩 + ZWJ + 👧 + ZWJ + 👦
它由四個人物 emoji,用三個零寬接合符(Zero Width Joiner, ZWJ, U+200D) 黏起來,共 7 個碼點,UTF-8 下佔 25 個位元組。但它在螢幕上是一個圖形。
這個「使用者感知的一個字」在 Unicode 術語裡叫字素叢集(grapheme cluster),由 Unicode 附件 UAX #29 嚴格定義。膚色修飾符(👍🏽 = 👍 + 膚色碼點)、國旗(🇹🇼 = 兩個區域指示符字母)、印度系文字的子音 + 母音符號,都是「多碼點組成一個字素」的例子。
這對工程實務的衝擊很實際:
- 截斷字串時若按碼點或位元組切,可能把一個字素切成兩半,畫面出現破碎的半截 emoji 或拆散的家庭。
- 游標移動、反白選取、刪除一個字(按一次退格)都應以字素叢集為單位,否則使用者按一次刪除卻只消掉半個 emoji。
- 計算「顯示寬度」(例如終端機排版)更複雜,因為東亞全形字佔兩格、結合符佔零格。
# Python 標準庫不內建字素分割,需第三方套件 grapheme 或 regex
import regex # pip install regex
clusters = regex.findall(r"\X", "👨👩👧👦café")
print(len(clusters)) # 5 → 1 個家庭 + c + a + f + é(NFC 下)
print(clusters) # ['👨👩👧👦', 'c', 'a', 'f', 'é']
記住這個層次階梯:位元組(byte) → 編碼單位(code unit) → 碼點(code point) → 字素叢集(grapheme cluster)。入門篇談的是前三層,而使用者真正在意的是最上面那層。多數「emoji 顯示成亂碼」「字串截斷出破圖」的災難,都源自工程師誤把碼點當成「字」。
定序:排序與比較沒你想的單純
「把名字按字母排序」聽起來簡單,但一旦離開純 ASCII 就步步是坑。直接用碼點數值排序(即 sorted() 預設行為)會得到語言學上荒謬的結果:
words = ["Zebra", "apple", "Äpfel", "äpfel"]
print(sorted(words))
# ['Zebra', 'apple', 'Äpfel', 'äpfel']
# 大寫 Z(0x5A) 竟排在小寫 a(0x61) 前面,Ä(0xC4) 又被丟到最後
問題在於碼點數值與人類的排序直覺無關。正確做法是依循 Unicode 定序演算法(Unicode Collation Algorithm, UCA, UTS #10),它為每個字元賦予多層定序權重(collation weight):第一層比基本字母、第二層比重音、第三層比大小寫,逐層比較。而且排序規則還因語言而異——同一個 ä,在德語電話簿排法裡視同 ae,在瑞典語裡卻排在字母表最後。
import locale
# 設定為某地區的定序規則(需系統支援該 locale)
# locale.setlocale(locale.LC_COLLATE, "de_DE.UTF-8")
# sorted(words, key=locale.strxfrm) → 得到符合德語習慣的順序
# 跨平台更穩的選擇是 PyICU(International Components for Unicode)
import icu # pip install PyICU
collator = icu.Collator.createInstance(icu.Locale("de_DE"))
print(sorted(["Zebra", "apple", "Äpfel", "äpfel"], key=collator.getSortKey))
# ['apple', 'äpfel', 'Äpfel', 'Zebra'] → 符合德語直覺
這也連動到資料庫設計:MySQL 的 utf8mb4_0900_ai_ci 中,ai 是 accent-insensitive(忽略重音)、ci 是 case-insensitive(忽略大小寫),底層正是 UCA 多層權重的取捨。選錯定序,WHERE name = 'müller' 可能找不到存成 Müller 的那筆資料,或反過來把不該相等的字當成相等——這就是為什麼 collation 是資料庫 schema 的關鍵決策,而不只是「裝飾」。
同形字攻擊:藏在網址裡的編碼陷阱
Unicode 的「萬國一表」也打開了資安的新攻擊面。國際化網域名稱(Internationalized Domain Name, IDN)允許網址含非 ASCII 字元,但 DNS 系統底層只接受 ASCII。於是有了 Punycode:把 Unicode 網域可逆地編碼成 xn-- 開頭的 ASCII 字串。
host = "中央大學.tw"
print(host.encode("idna")) # b'xn--fiqs8s...' 之類
print("台積電".encode("idna").decode()) # xn--... (瀏覽器網址列底層存的就是這個)
危險在於:許多字元在不同文字系統中長得一模一樣,稱為同形字(homoglyph)。例如:
- 拉丁字母
a(U+0061) vs. 西里爾字母а(U+0430)——肉眼完全無法分辨。 - 攻擊者註冊
аpple.com(第一個是西里爾а),它的 Punycode 是xn--pple-43d.com,與真正的apple.com是不同網域,卻在網址列顯示得幾乎一樣。
這類同形字釣魚(homograph attack) 讓使用者誤以為連到了正牌網站。防禦手段包括:瀏覽器對混用多種文字系統的網域強制顯示 Punycode 原文、限制單一標籤內可混用的文字系統(script)、以及對使用者輸入做 NFKC 正規化 + 文字系統一致性檢查。這正是前面正規化一節的實戰價值——NFKC 能把許多視覺變體拉平,是偵測偽冒輸入的第一道防線。同樣的邏輯也適用於使用者名稱、品牌名比對:永遠別假設「看起來一樣」等於「位元組一樣」。
多媒體編碼的進階一瞥:色彩空間與時間冗餘
入門篇談過 RGB 與取樣量化。進階一層,現代多媒體編碼有兩個你該認得的關鍵字。
第一是色彩子取樣(chroma subsampling)。人眼對亮度(luma) 的敏感度遠高於對色彩(chroma) 的敏感度,所以影像編碼常先把 RGB 轉成 YCbCr(亮度 Y + 兩個色差 Cb、Cr),再對色差分量降低解析度。常見的 4:2:0 表示色差在水平與垂直方向都只取一半樣本——色彩資料量直接砍到四分之一,肉眼卻幾乎察覺不到。這是 JPEG、H.264、HEVC 普遍採用的省空間手法。
第二是時間冗餘(temporal redundancy)。影片相鄰兩格畫面通常極度相似,逐格獨立壓縮太浪費。現代視訊編碼器因此區分 I 幀(intra-frame,完整畫面)、P 幀(predicted,記錄與前一格的差異) 與 B 幀(bidirectional,參考前後兩格),只儲存運動向量(motion vector) 與殘差。這把入門篇的「空間壓縮」推進到「時間維度的差分編碼」,也是串流影音能在有限頻寬下流暢播放的核心。
重點回顧
- UTF-16 用代理對(surrogate pair)表示 BMP 以外的碼點,這解釋了為何 JavaScript/Java 的「字串長度」數的是編碼單位而非字元;多位元組編碼還需用 BOM 或明確指定來處理位元組序。
- 同一個視覺字元可能有多種碼點組合(預組合 vs 分解),正規化(NFC/NFD/NFKC) 是所有比較、索引、唯一性檢查的前置步驟。
- 使用者眼中的「一個字」是字素叢集(如 ZWJ 串起的家庭 emoji、膚色修飾符),截斷、游標、刪除都應以字素為單位,切勿誤把碼點當字。
- 定序(UCA) 依語言而異且分層比較,碼點數值排序在非 ASCII 下毫無意義;資料庫的 collation 選擇直接影響查詢正確性。
- Unicode 的萬國性帶來同形字攻擊等資安風險,Punycode + 正規化 + 文字系統檢查是防線。
深入探討(研究所視角)
把這些主題串起來,會浮現一個貫穿資訊科學的張力:「身分(identity)」在離散表示下從來不是唯一的。同一個抽象實體(一個字、一個顏色、一段聲音)可以有無窮多種合法的位元表示,而系統正確性往往取決於我們是否在正確的等價類(equivalence class) 上做運算。Unicode 正規化本質上就是在定義字串的等價關係,並挑選每個等價類的正規代表元(canonical representative)——這與抽象代數中的商集(quotient set)、編譯器裡 SSA 的值編號(value numbering)、密碼學中對輸入做 canonicalization 以防繞過,是同一個數學思想的不同化身。一個沒有正規化的相等判斷,等於在錯誤的集合上推理。
定序的多層權重模型也值得從演算法角度細看。UCA 為每個字元產生一個定序鍵(sort key)——一串可直接用位元組比較(memcmp)的數值序列,把「依語言規則比較兩字串」這個 $O(n)$ 的複雜操作,攤提成「預先計算一次鍵、之後反覆快速比較」。這是典型的預計算換查詢速度設計,與資料庫索引、感知雜湊(perceptual hashing)的思路一致。但代價是定序鍵會膨脹(一個字元可能對應多層、多位元組的權重),且規則隨 Unicode 版本演進——同一份資料在不同 ICU 版本下排序結果可能改變,這對需要確定性可重現(deterministic reproducibility) 的系統(如分散式共識、版本控制、學術資料封存)是潛在地雷。
最後,把編碼與壓縮放在統一的視角下:兩者都是在某個約束下尋找從符號到位元的映射。無損編碼的約束是「可逆」,下限由 Shannon 熵給出;有損編碼的約束是「在感知失真容忍度內」,這把問題推向率失真理論(rate-distortion theory)——給定可接受的失真上界 $D$,求最小位元率 $R(D)$。色彩子取樣、心理聲學遮蔽、運動補償,本質都是在估計「哪些位元對人類感知貢獻最小」並優先捨棄。這正呼應 Uedu 的 Educational Omics 框架中 PhysioNeuromics 與 Linguomics 維度的核心關懷:無論是壓縮影音、處理多語文字,還是分析學習者的語言與生理訊號,關鍵都在於理解人類感知與語言的結構,才能找到最有效率、最不失真的表示方式。文字編碼看似基礎,卻是整個資訊表示哲學的縮影。