
記憶體階層:為什麼資料離 CPU 越近越關鍵
從暫存器到硬碟的速度與容量取捨,理解區域性原理、快取對應方式與命中率如何主宰真實效能
為什麼程式跑得快,常常不是因為 CPU 變快
想像你正在圖書館趕一份報告。手邊的桌面只能攤開幾本書,這是你「立刻」就能翻閱的資料;想再多查一點,得起身走到旁邊的開架書櫃;如果連書櫃都沒有,就只能填單子請館員去地下密集書庫調閱,等上十幾分鐘。聰明的人不會把每本書都跑去密集書庫拿,而是把「等一下還會用到」的書先抱回桌面,需要時伸手就有。
電腦處理資料的方式幾乎一模一樣。中央處理器(CPU)的運算速度極快,但它能直接觸及的「桌面」非常小;真正容量大的儲存裝置(storage)又慢得驚人。整台電腦的效能,往往不取決於 CPU 時脈有多高,而取決於它需要的資料「此刻離它有多近」。這套「把常用資料放在離 CPU 越近、越快的地方」的設計哲學,就是記憶體階層(memory hierarchy)。
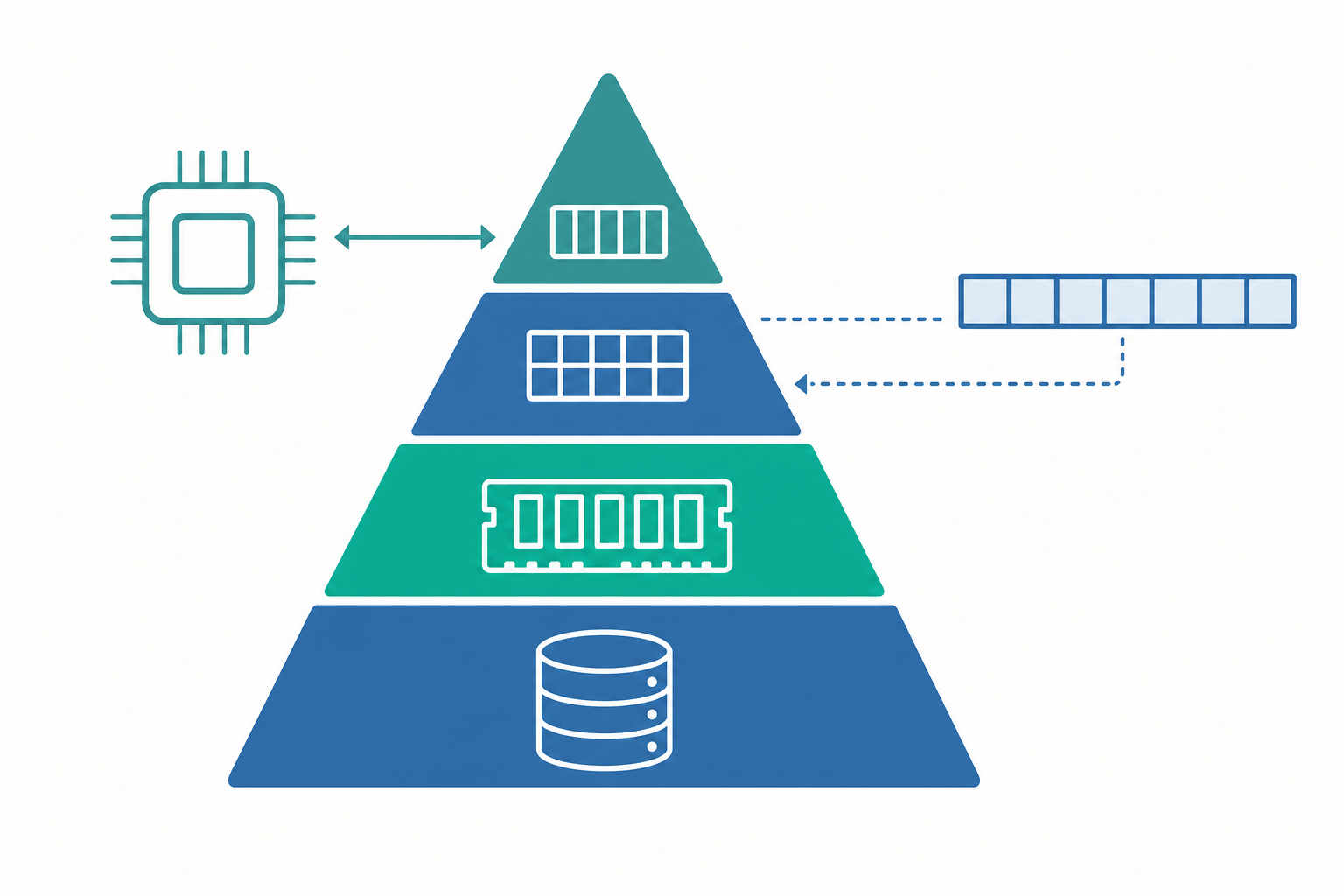
速度與容量的根本取捨
為什麼不乾脆把所有記憶體都做成最快的那種?答案是物理與成本:越快的記憶體,每位元(bit)的造價越高、發熱越大、佔的晶片面積越多,因此容量註定做不大。工程師於是做了一個務實的妥協——分層。每一層在「速度」與「容量」之間取不同的平衡點,由快而小、到慢而大,疊成一座金字塔。
典型的記憶體階層,由近而遠大致如下:
| 層級 | 典型存取時間 | 典型容量 | 每位元成本 | 揮發性 |
|---|---|---|---|---|
| 暫存器(register) | < 1 ns | 數十至數百個字組 | 最高 | 揮發 |
| L1 快取(cache) | 約 1 ns | 數十 KB | 高 | 揮發 |
| L2 / L3 快取 | 數 ns 至數十 ns | 數百 KB 至數十 MB | 中高 | 揮發 |
| 主記憶體(main memory, DRAM) | 約 50–100 ns | 數 GB 至數十 GB | 中 | 揮發 |
| 固態硬碟(SSD) | 數十 μs | 數百 GB 至數 TB | 低 | 非揮發 |
| 硬式磁碟(HDD) | 數 ms | 數 TB | 最低 | 非揮發 |
這張表最值得記住的,不是某個確切數字(它們隨硬體世代不斷變動),而是跨層級的差距是「數量級(order of magnitude)」等級的。主記憶體比 L1 快取慢約一百倍;SSD 又比主記憶體慢約一千倍;HDD 再慢上一個數量級。換算成生活時間感受更震撼:如果把暫存器的一次存取想成「1 秒」,那麼一次主記憶體存取大約是「2 分鐘」,而一次傳統硬碟尋軌則是「好幾個月」。CPU 每次「向下一層」要資料,付出的等待都是天文數字。
這也解釋了揮發性(volatility)的分工:上層的暫存器、快取、DRAM 都是揮發性的,斷電即失去內容,換來的是速度;下層的 SSD、HDD 是非揮發性的,斷電後資料仍在,代價是慢。我們開機時把作業系統「從磁碟載入記憶體」,正是把資料從慢而持久的下層,搬到快而短暫的上層。
為什麼分層真的有效:區域性原理
分層之所以不是徒勞,關鍵在於真實程式的記憶體存取並非隨機,而是高度有規律。這條規律稱為區域性原理(principle of locality),分為兩種:
- 時間區域性(temporal locality):剛被存取過的資料,很可能在不久後再次被存取。例如迴圈中的計數器變數、頻繁呼叫的函式。
- 空間區域性(spatial locality):被存取的資料附近的資料,很可能接著被存取。例如循序走訪陣列(array)、依序執行的指令。
有了區域性,「把資料抱回桌面」的策略才划算:我們花一次昂貴的成本把資料從下層搬上來,接下來的許多次存取就都能在上層快速完成,把成本「攤平(amortize)」掉。如果程式真的是完全隨機存取、毫無區域性,快取就形同虛設——這也是為什麼有些演算法(如大型雜湊表的隨機探查)對快取特別不友善。
正因如此,快取一次不只搬一個位元組,而是搬一整塊連續資料,稱為一個快取列(cache line),常見大小為 64 位元組。這正是在押注空間區域性:既然你要了這個位址的資料,順手把鄰居一起帶上,賭你等一下會用到。
快取命中與失誤
當 CPU 需要某筆資料,它會先問最近的快取:「你有嗎?」
- 若快取裡有,稱為快取命中(cache hit),資料極快回傳。
- 若快取裡沒有,稱為快取失誤(cache miss),必須向下一層(更慢的快取或主記憶體)索取,把整個快取列載入後再回傳。這段額外等待稱為失誤代價(miss penalty)。
衡量快取表現的核心指標是命中率(hit rate)——所有存取中命中的比例;其補數是失誤率(miss rate) = 1 − 命中率。一個系統的平均記憶體存取時間(Average Memory Access Time, AMAT)可寫成:
$$\text{AMAT} = T_{\text{hit}} + \text{(miss rate)} \times T_{\text{penalty}}$$
其中 $T_{\text{hit}}$ 是命中時的存取時間,$T_{\text{penalty}}$ 是失誤時額外付出的代價。這條式子的威力在於:因為 $T_{\text{penalty}}$ 通常是 $T_{\text{hit}}$ 的數十到上百倍,即使失誤率只從 5% 降到 1%,平均存取時間也可能大幅改善。效能的槓桿,藏在命中率的小數點後幾位。
快取失誤通常分為三類,俗稱「3C」:
- 強制失誤(compulsory miss):資料第一次被存取,快取裡本來就不可能有,又稱冷啟動失誤。
- 容量失誤(capacity miss):工作集(working set)太大,快取裝不下,舊資料被擠出後又被用到。
- 衝突失誤(conflict miss):因對應方式限制,多筆資料搶同一個位置而互相驅逐,即使整體容量還夠。
快取如何決定資料放哪裡:對應方式
理解第三類「衝突失誤」,必須先理解快取對應方式(cache mapping)——當一個快取列要進入快取時,它能放在哪些位置。常見有三種策略:
1. 直接對應(direct-mapped):每個主記憶體區塊只能放在唯一一個快取位置(通常以位址取模決定)。查找最快、硬體最簡單,但缺點明顯:若兩塊常用資料剛好對應到同一格,就會反覆互相驅逐,產生大量衝突失誤。
2. 全關聯(fully associative):任何區塊可放進快取的任意位置。彈性最高、衝突失誤最少,但每次查找都得「比對所有位置」,硬體昂貴、不適合做大。
3. 組關聯(set-associative):折衷方案,也是現代 CPU 的主流。快取分成許多「組(set)」,每組有 $N$ 個位置(稱為 $N$-way 組關聯)。一個區塊先用位址映射到唯一一組,再在組內任選一格存放。例如 8-way 組關聯,代表每組有 8 個候選位置。這樣只需在組內比對 8 個位置,兼顧了彈性與查找成本。
當一組已滿、又有新資料要進來,就得用置換策略(replacement policy)決定犧牲誰,最常見的是最近最少使用(Least Recently Used, LRU)——驅逐最久沒被碰過的那一筆,這正是時間區域性的直接應用。
動手看一個例子
讓我們用一段最樸素的程式碼,親眼看見區域性如何左右效能。考慮把一個二維陣列(matrix)所有元素相加。在 C 或 Python 這類列主序(row-major)儲存的語言裡,A[i][j] 與 A[i][j+1] 在記憶體中是相鄰的。
N = 4096
total = 0
# 版本 A:逐列走訪(row-major,順著記憶體排列)
for i in range(N):
for j in range(N):
total += A[i][j]
# 版本 B:逐欄走訪(column-major,跨越記憶體大步跳)
for j in range(N):
for i in range(N):
total += A[i][j]
兩個版本的計算結果完全相同,加法次數也一樣,但在底層編譯語言中實測,版本 A 常比版本 B 快上數倍。原因全在快取:
- 版本 A 順著記憶體連續前進。一次快取失誤載入 64 位元組的快取列(假設每個元素 4 位元組,等於一次帶回 16 個元素),接下來的 15 次存取全是命中。空間區域性被充分利用,命中率極高。
- 版本 B 每次內層迴圈跳過一整列(跨越
N個元素的距離),幾乎每次存取都落在不同的快取列上。剛載入的列還沒用到第二個元素就被換掉,等於每次都是失誤。
我們用 AMAT 估算這個差距。假設 $T_{\text{hit}} = 1$ ns、$T_{\text{penalty}} = 100$ ns:
- 版本 A 命中率約 $15/16 \approx 93.75\%$,失誤率約 $6.25\%$:
$$\text{AMAT}_A = 1 + 0.0625 \times 100 = 7.25 \text{ ns}$$
- 版本 B 失誤率接近 $100\%$:
$$\text{AMAT}_B = 1 + 1.0 \times 100 = 101 \text{ ns}$$
僅僅交換兩層迴圈的順序,平均每次存取就差了約 14 倍。這就是「同樣的演算法、同樣的複雜度 $O(N^2)$,效能卻天差地遠」的真相——漸進複雜度看不見的常數,很多時候藏在記憶體階層裡。
重點回顧
- 記憶體階層用「越近越快越小、越遠越慢越大」的金字塔結構,在速度與容量的根本取捨間取得平衡;跨層級差距是數量級等級的。
- 分層之所以有效,奠基於區域性原理:程式傾向重複存取剛用過的資料(時間區域性)與其鄰近資料(空間區域性)。快取因此以「快取列」為單位整塊搬運。
- 命中率主宰實際效能。由 $\text{AMAT} = T_{\text{hit}} + \text{miss rate} \times T_{\text{penalty}}$ 可知,因失誤代價極高,命中率的微小提升就能帶來顯著加速。
- 快取對應方式(直接對應/全關聯/組關聯)決定資料能放哪裡,並影響衝突失誤;現代 CPU 多採組關聯搭配 LRU 置換。
- 寫程式時讓存取模式貼合記憶體佈局(如列主序順序走訪、改善資料局部性),是不改變演算法複雜度、卻能大幅提速的實用手段。
深入探討(研究所視角)
快取對應方式與命中率對效能的影響,是計算機架構的核心議題之一。 從直接對應到全關聯,本質上是在「查找成本」與「衝突失誤率」之間的連續光譜上取點。提高關聯度(associativity)能降低衝突失誤,但收益遞減且帶來能耗與延遲代價——這是「2:1 cache rule of thumb」的經驗觀察:一個容量為 $C$ 的直接對應快取,其失誤率大致與容量 $C/2$ 的 2-way 組關聯快取相當。換言之,提升關聯度可在不加大容量的情況下換取相近的命中率,但實務上 CPU 設計者必須在電晶體預算、時脈與功耗之間綜合權衡。
更深一層,置換策略與對應方式的互動值得注意。理論上的最佳置換是 Bélády 最佳演算法——驅逐「未來最久才會被用到」的區塊,但它需要預知未來,僅能作為離線的效能上界。實務以 LRU 近似之,然而 LRU 在某些存取模式(如循序掃過大於快取容量的陣列)會退化到接近最差,催生了 LRU 的各種近似與改良(如偽 LRU、LFU 變體、以及學界的 RRIP、DRRIP 等掃描抗性策略)。這些都是為了讓有限的快取面對多樣化工作集時仍維持高命中率。
值得釐清的常見迷思是:快取階層不只是效能優化,更牽涉正確性與一致性。在多核(multi-core)系統中,每顆核心有私有快取,同一筆主記憶體資料可能在多份快取中各有副本,於是必須用快取一致性協定(cache coherence protocol)(如 MESI 及其變體)來保證各核看到一致的值。這把記憶體階層從單純的速度議題,延伸到並行程式設計的記憶體模型(memory consistency model)與同步語意。
最後,記憶體階層的概念遠超出 CPU 快取本身,而是一個遞迴出現的系統設計母題。作業系統的虛擬記憶體(virtual memory)把主記憶體當成磁碟的快取,並用 TLB(Translation Lookaside Buffer)——本質上是「頁表的快取」——加速位址轉譯;資料庫的緩衝池(buffer pool)把記憶體當成磁碟的快取;CDN 把邊緣節點當成來源伺服器的快取;甚至 CPU 的分支預測器也可視為對控制流的快取。理解了「快取命中/失誤/命中率/置換策略」這組詞彙,你就掌握了一把能反覆套用到網路、儲存、分散式系統各層的通用鑰匙。從這個視角回望,演算法分析裡的 RAM 模型(假設所有記憶體存取等成本)只是方便的理想化;更貼近真實的 cache-oblivious 與 external-memory(I/O)模型則明確把存取成本的層級差異納入,正是為了回答「在真實記憶體階層上,什麼演算法才真正快」這個問題。