
當 break 不夠用:Java 流程控制的進階機制與正確性論證
標籤化跳轉、switch expression、短路求值、迴圈不變量,以及流程控制背後的控制流程圖與霍爾邏輯
當 break 不夠用:你的迴圈其實藏著一台「狀態機」
入門篇我們用紅綠燈學會了 if/switch 做決定、用 for/while 做重複。但真實程式的流程控制,很少是「跑完三盞燈就結束」這麼乾淨。考慮這個情境:你要解析一段使用者輸入的字串,跳過開頭的空白、讀取數字、遇到逗號就切換、遇到非法字元就回報錯誤。你會發現,單純堆疊 if 開始失控——巢狀越來越深,break 跳出哪一層越來越難說清楚。
這篇進階篇要談的,正是入門篇刻意略過的那些「邊角機制」:標籤化的 break/continue、switch 真正的 fall-through 與 Java 14 之後的 arrow form、迴圈不變量(loop invariant)如何讓你證明程式正確、短路求值(short-circuit evaluation)背後的副作用陷阱,以及流程控制在編譯器眼中其實是一張控制流程圖(control-flow graph, CFG)。讀完之後,你看 for 迴圈的眼光會不太一樣。
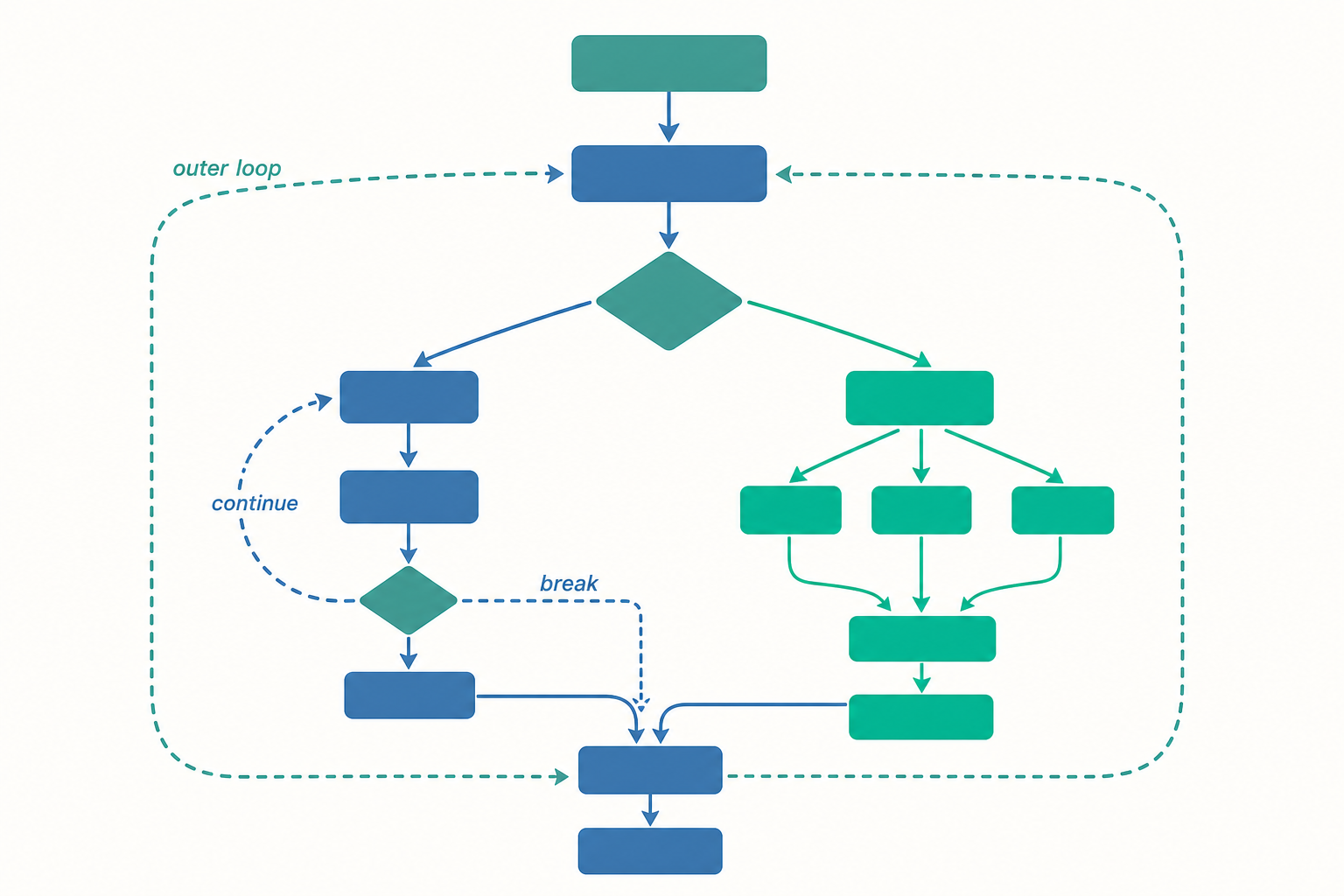
標籤化的 break 與 continue:跳出你指定的那一層
入門篇說過 break 會「離開迴圈」。但離開「哪一個」迴圈?預設是最內層那一個。當你有巢狀迴圈時,這個預設常常不夠用。
假設要在一個二維陣列裡找到第一個負數,找到就停止全部搜尋:
int[][] grid = {
{3, 5, 7},
{2, -8, 4},
{9, 1, 6}
};
// 笨方法:用一個 flag 變數來控制外層
boolean found = false;
for (int i = 0; i < grid.length && !found; i++) {
for (int j = 0; j < grid[i].length; j++) {
if (grid[i][j] < 0) {
System.out.println("找到負數於 (" + i + "," + j + ")");
found = true;
break; // 只跳出內層
}
}
}
這個 found flag 是雜訊。Java 提供標籤(label)讓你直接指名要跳出哪一層:
search:
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[i].length; j++) {
if (grid[i][j] < 0) {
System.out.println("找到負數於 (" + i + "," + j + ")");
break search; // 直接跳出標記為 search 的外層迴圈
}
}
}
標籤就是一個識別字加上冒號,放在迴圈前面。break search 會一口氣離開整個 search 結構。同理,continue label 會跳到該標籤迴圈的下一輪。
continue 的標籤版本更微妙。看這個例子:檢查一個矩陣,只要某一列含有 0,就整列跳過、處理下一列:
rowLoop:
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[i].length; j++) {
if (grid[i][j] == 0) {
continue rowLoop; // 放棄這一列剩下的元素,跳到下一列
}
System.out.print(grid[i][j] + " ");
}
System.out.println();
}
continue rowLoop 並不是「離開外層」,而是「讓外層進入下一次迭代」。內層剩下的元素被略過,i 加 1,外層繼續。理解這個差別,是區分初學者與進階者的分水嶺。
一個務實的提醒:標籤化的跳轉很強大,但濫用會讓控制流變得像 goto 一樣難讀。業界慣例是——標籤只用於跳出巢狀迴圈,且巢狀層數不超過兩三層。如果你發現自己需要三個標籤互相跳來跳去,那通常是訊號:該把內層邏輯抽成一個獨立方法,用 return 取代 break。
switch 的兩張臉:fall-through 與 arrow form
入門篇大概只教了「switch 配 case 配 break」。但 switch 其實藏著一個經典陷阱與一個現代解法。
傳統 switch 的 fall-through
傳統(colon form)switch 的每個 case 如果沒有 break,會繼續往下執行下一個 case,這叫 fall-through(穿透)。這常常是 bug 的來源:
int month = 2;
int days;
switch (month) {
case 1:
case 3:
case 5:
case 7:
case 8:
case 10:
case 12:
days = 31;
break;
case 4:
case 6:
case 9:
case 11:
days = 30;
break;
case 2:
days = 28; // 簡化:先不管閏年
break;
default:
days = -1;
}
這裡的 fall-through 是刻意的——case 1 沒有 body 直接穿透到 case 3……最後一起執行 days = 31。但如果你不小心漏寫 break,編譯器不會報錯,程式卻會悄悄跑錯。這是 C 系語言流傳數十年的著名陷阱。
Java 14+ 的 arrow form 與 switch expression
Java 14 正式引入 arrow form,徹底消除 fall-through:
int days = switch (month) {
case 1, 3, 5, 7, 8, 10, 12 -> 31;
case 4, 6, 9, 11 -> 30;
case 2 -> 28;
default -> throw new IllegalArgumentException("非法月份:" + month);
};
注意兩個關鍵變化:
->箭頭右邊只執行那一個分支,不會穿透,也不需要break。- 整個
switch變成一個運算式(expression),會回傳值,可以直接賦給days。這就是 switch expression。
如果分支需要多行邏輯,用大括號加 yield 回傳值:
String size = switch (count) {
case 0 -> "空";
default -> {
int level = count / 10;
yield "等級 " + level; // yield 是 switch expression 專用的回傳關鍵字
}
};
更重要的是,switch expression 具有窮盡性檢查(exhaustiveness check)。當你對 enum 或 sealed 型別做 switch expression,編譯器會強制你涵蓋所有可能值(或加 default),否則拒絕編譯。這把「忘記處理某個情況」從執行期錯誤提前到了編譯期——這是現代型別系統幫你做的流程控制保險。
enum Signal { RED, YELLOW, GREEN }
String action(Signal s) {
return switch (s) {
case RED -> "停";
case YELLOW -> "準備";
case GREEN -> "通行";
// 不需要 default:編譯器確認三個 case 已窮盡所有 enum 值
};
}
若哪天有人在 Signal 裡加了第四個值 FLASHING,這段程式會編譯失敗,逼你去補上對應邏輯。傳統 if-else 鏈無法給你這個保障。
短路求值:流程控制藏在運算子裡
流程控制不只存在於 if 和迴圈,也藏在邏輯運算子 && 和 || 裡。它們是短路(short-circuit)的:
a && b:如果a為false,根本不會計算b,整體直接是false。a || b:如果a為true,根本不會計算b,整體直接是true。
這不只是效能優化,更是一種控制流。最常見的用途是防衛性檢查(guard):
String name = getUser(); // 可能回傳 null
// 安全:左邊先擋住 null,name 是 null 時右邊不執行,避免 NullPointerException
if (name != null && name.length() > 0) {
System.out.println("歡迎," + name);
}
如果把順序寫反成 name.length() > 0 && name != null,當 name 是 null 時,左邊先觸發 NullPointerException,程式直接崩潰。短路求值讓運算子的順序變成有意義的流程控制。
看一個例子:副作用與短路的交互作用
短路最隱晦的陷阱是「右邊有副作用時,它可能不執行」。觀察這段程式的輸出:
public class ShortCircuitDemo {
static int counter = 0;
static boolean increment() {
counter++;
return true;
}
public static void main(String[] args) {
boolean a = false && increment(); // increment() 不會被呼叫
System.out.println("counter = " + counter); // 輸出 0
boolean b = true || increment(); // increment() 同樣不會被呼叫
System.out.println("counter = " + counter); // 仍是 0
boolean c = true && increment(); // 這次會呼叫
System.out.println("counter = " + counter); // 輸出 1
}
}
如果你以為 increment() 一定會跑而把重要的狀態更新放在那裡,程式就會出現難以察覺的 bug。Java 另外提供非短路版本 &(and)與 |(or),它們保證兩邊都求值:
boolean d = false & increment(); // increment() 一定執行,counter 變 1
但在布林邏輯中使用 &/| 相當罕見,且容易誤導讀者。實務上幾乎一律用 &&/||,並把「保證執行的副作用」明確寫在條件之外。
迴圈不變量:用數學證明你的迴圈是對的
進階程式設計師看迴圈,不只看「它會不會跑完」,還看「它跑完後保證得到正確結果嗎」。形式化的工具叫迴圈不變量(loop invariant):一個在每次迭代開始與結束時都成立的條件。
動手算一下:對求和迴圈做正確性論證
int[] arr = {4, 2, 7, 1, 9};
int sum = 0;
int i = 0;
while (i < arr.length) {
// 不變量:sum == arr[0] + arr[1] + ... + arr[i-1]
sum += arr[i];
i++;
}
// 結束時 i == arr.length,由不變量得 sum == 全部元素之和
我們宣告的不變量是:「在每次迴圈條件檢查時,sum 等於前 i 個元素的總和」。要證明它,套用數學歸納法的三步驟:
- 初始化(initialization):進入迴圈前
i = 0、sum = 0。「前 0 個元素之和」是 0,不變量成立。 - 保持(maintenance):假設某次迭代開始時不變量成立(
sum是前i個之和)。執行sum += arr[i]後sum變成前i+1個之和,接著i++讓i增加 1。於是下一次檢查時,「sum等於前i個之和」依然成立。 - 終止(termination):迴圈因
i == arr.length而結束。代入不變量,sum等於前arr.length個元素之和,正是我們要的答案。
這三步驟看似繁瑣,但它是電腦科學裡證明演算法正確性的標準方法。當你面對二分搜尋、排序這類容易寫錯邊界的演算法時,先想清楚不變量,往往比反覆 debug 更快找到問題。例如二分搜尋的不變量是「若目標存在,它一定落在 [lo, hi] 區間內」——只要每次迭代都維持這個性質,搜尋就不會漏掉答案。
重點回顧
- 標籤化 break/continue:
break label跳出指定的外層迴圈,continue label讓指定迴圈進入下一次迭代;用於巢狀迴圈,但層數別太深。 - switch 的兩種形式:傳統 colon form 有 fall-through 陷阱(漏
break會穿透);Java 14+ 的 arrow form(->)不穿透、可當運算式回傳值、對 enum/sealed 型別有窮盡性檢查。 - 短路求值是流程控制:
&&/||會跳過不必要的右運算元;運算子順序可用來防NullPointerException;右邊有副作用時要警覺它可能不執行。 - 迴圈不變量:用「初始化、保持、終止」三步驟可形式化證明迴圈正確性,是分析二分搜尋、排序等演算法的利器。
- 控制流是一張圖:所有
if/迴圈/break在編譯器內部都被翻譯成控制流程圖(CFG),這是優化與靜態分析的基礎。
深入探討(研究所視角)
到了研究所的層次,流程控制不再是語法問題,而是程式分析(program analysis)與編譯器理論的核心。
控制流程圖(CFG)與基本區塊。 編譯器會把你的程式拆成基本區塊(basic block)——一段沒有分支進入、也沒有分支離開的最大連續指令序列。區塊之間用有向邊連接,形成 CFG。你寫的 if、while、break、switch,最終都被「攤平」成這張圖上的邊。有了 CFG,編譯器才能做到達定義分析(reaching definitions)、活躍變數分析(live variable analysis)等資料流分析(dataflow analysis),進而做死碼消除、暫存器配置等優化。Java 編譯器拒絕「unreachable code」(例如 return 之後的敘述)就是 CFG 可達性分析的直接結果。
結構化程式定理。 1966 年的 Böhm–Jacopini 定理證明了一件深刻的事:任何可計算的流程,都只用循序(sequence)、選擇(selection, if)、迭代(iteration, while)三種結構就能表達,完全不需要 goto。這是「結構化程式設計」運動的理論基石,也解釋了為什麼現代語言(包括 Java)刻意不提供 goto——標籤化的 break/continue 是它在受控範圍內的妥協替代品。
迴圈不變量與形式化驗證。 我們示範的不變量論證,在學術上對應霍爾邏輯(Hoare logic)。一段程式可用三元組 $\{P\}\, C\, \{Q\}$ 描述:前置條件 $P$ 成立時執行程式 $C$,結束後後置條件 $Q$ 成立。while 迴圈的推論規則正是建立在不變量 $I$ 上:
$$\frac{\{I \wedge B\}\; C\; \{I\}}{\{I\}\; \texttt{while } B \texttt{ do } C\; \{I \wedge \neg B\}}$$
這條規則是工具如 Dafny、KeY、JML 做自動程式驗證的數學基礎。研究者用它證明排序演算法、並行資料結構的正確性,把「測了很多遍都對」升級為「在數學上保證對」。
終止性與停機問題。 不變量證明「若迴圈結束,結果正確」,但它不保證迴圈一定結束。要證明終止,需要額外提供一個變異量(ranking function / variant):一個隨每次迭代嚴格遞減、且有下界的整數量(在求和例中是 arr.length - i)。而「任意給定程式是否一定停機」這個一般性問題,正是 Turing 在 1936 年證明不可判定(undecidable)的停機問題(halting problem)。這劃定了自動化程式分析的根本極限——再強的工具也無法對所有程式判定它是否會停。
理解到這一層,你會明白:流程控制看似是入門語法,但它一路通往可計算性理論的邊界。下次寫 while 時,不妨多問一句——「它的不變量是什麼?它的變異量又是什麼?」這個習慣,會讓你從「會寫程式」走向「能論證程式」。