
Java 泛型進階:型別抹除、PECS 與遞迴界限的真相
為什麼 List<String> 和 List<Integer> 在執行期是同一個型別?從型別抹除出發,看懂萬用字元、橋接方法與標準庫的視圖陷阱。
為什麼 List<String> 和 List<Integer> 在執行期是同一個型別?
你已經會用泛型(generics)把型別錯誤擋在編譯期了。但請先看一段會讓很多人吃驚的程式碼:
List<String> strs = new ArrayList<>();
List<Integer> ints = new ArrayList<>();
System.out.println(strs.getClass() == ints.getClass()); // true!
List<String> 和 List<Integer> 的 getClass() 竟然相等,兩者在執行期都只是 java.util.ArrayList。型別參數 <String>、<Integer> 在編譯後彷彿人間蒸發。這不是 bug,而是 Java 泛型最核心、也最容易踩雷的設計決策——型別抹除(type erasure)。
入門篇教你「泛型讓編譯器幫你檢查型別」,這篇要回答更深的問題:編譯器到底「在哪一層」檢查?檢查完之後型別資訊去了哪裡?為什麼有些看似合理的寫法(new T[]、catch (MyException<String> e))會被編譯器拒絕?以及,理解了抹除之後,你才能真正讀懂 Collections.sort 那串嚇人的 <T extends Comparable<? super T>> 簽章。
型別抹除:泛型只活在編譯期
Java 在 2004 年(Java 5)才加入泛型。為了讓舊的 .class 檔與新程式碼互通(向後相容),設計者選擇了抹除式實作:編譯器在檢查完型別安全後,把所有型別參數「抹掉」,換成它的上界(沒寫上界就是 Object),再插入必要的強制轉型。
換句話說,你寫的這段:
class Box<T> {
private T value;
public void set(T value) { this.value = value; }
public T get() { return value; }
}
Box<String> box = new Box<>();
box.set("hello");
String s = box.get();
編譯後在位元組碼層級,大致等同於:
class Box {
private Object value;
public void set(Object value) { this.value = value; }
public Object get() { return value; }
}
Box box = new Box();
box.set("hello");
String s = (String) box.get(); // 編譯器自動插入的 checkcast
兩個重要結論:
- 泛型是「編譯期的契約」,不是「執行期的型別」。型別檢查全部發生在編譯階段;通過之後,JVM 看到的就是一堆
Object加上自動轉型。 - 執行期不存在
Box<String>這個型別,只有Box。這就是為什麼strs.getClass() == ints.getClass()會是true。
這個設計的好處是相容性與零執行期開銷(不像 C# 的具現化泛型會為每個型別參數產生獨立的類別),代價則是一連串「型別資訊在執行期消失」所衍生的限制。
抹除帶來的四個限制(與它們的根因)
理解了「執行期沒有型別參數」這件事,下面這些編譯錯誤就不再是死記的規則,而是邏輯上的必然。
(一)不能 instanceof 帶型別參數
if (obj instanceof List<String>) { ... } // 編譯錯誤
if (obj instanceof List<?>) { ... } // OK,問號 wildcard 才合法
執行期 List<String> 不存在,JVM 無從檢查「這是不是裝 String 的 List」,所以直接禁止。
(二)不能 new T[] 或 new T()
class Stack<T> {
private T[] data = new T[10]; // 編譯錯誤:generic array creation
}
陣列在 Java 是具現化(reified)型別——它在執行期會記得自己的元素型別,並做執行期檢查(ArrayStoreException)。但泛型是抹除的,T 在執行期不存在,兩者的型別模型互相矛盾。標準做法是建 Object[] 再轉型,並把警告侷限在一處:
@SuppressWarnings("unchecked")
private T[] data = (T[]) new Object[10];
ArrayList 原始碼裡正是這樣做的(elementData 就是 Object[])。
(三)泛型類別不能繼承 Throwable
class MyException<T> extends Exception { } // 編譯錯誤
因為 catch 在執行期靠型別比對來決定要不要接住例外,而抹除後 catch (MyException<String> e) 與 catch (MyException<Integer> e) 無從區分。
(四)橋接方法(bridge method):抹除的隱形補丁
考慮這段覆寫:
class StringBox extends Box<String> {
@Override
public void set(String value) { /* ... */ }
}
父類 Box 抹除後 set 的簽章是 set(Object),子類卻寫了 set(String)。兩者簽章不同,理論上不構成覆寫!為了讓多型仍然成立,編譯器會在 StringBox 偷偷生成一個橋接方法:
// 編譯器自動生成(你看不到原始碼,但 javap 看得到)
public void set(Object value) {
set((String) value); // 轉發到真正的 set(String)
}
你可以用 javap -c StringBox 親眼看到這個 bridge 旗標的方法。橋接方法也解釋了一個經典陷阱:如果你不小心讓 set(Object) 與 set(String) 同時存在於同一個泛型階層中,可能撞上「name clash」編譯錯誤。
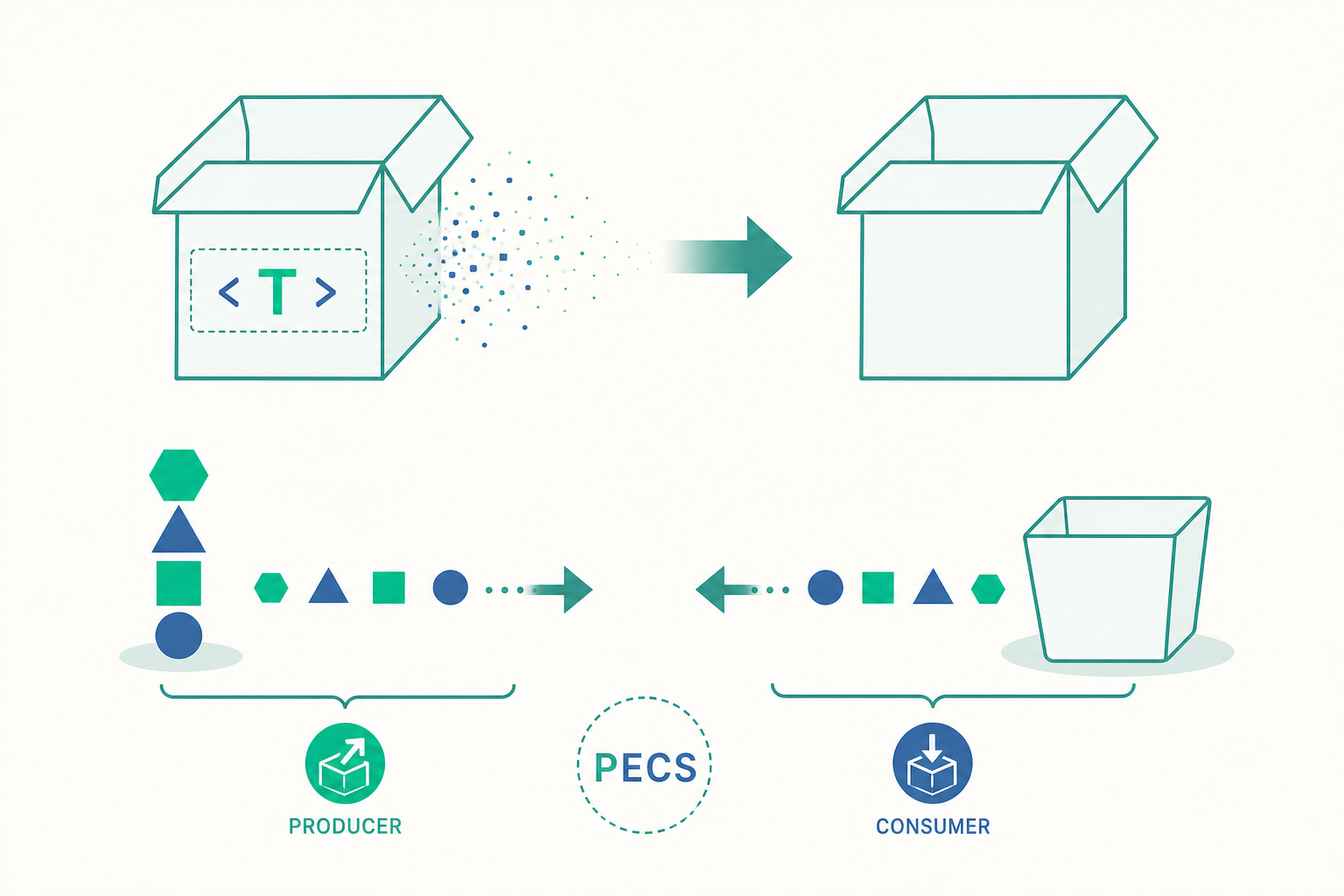
萬用字元與 PECS:泛型最實用的進階心法
入門篇可能讓你以為 List<Object> = new ArrayList<String>() 應該合法——畢竟 String 是 Object。但它不合法,因為泛型是不變的(invariant):
List<String> strs = new ArrayList<>();
List<Object> objs = strs; // 編譯錯誤!
objs.add(42); // 假如上一行成立,這裡就把 Integer 塞進 String 清單了
String s = strs.get(0); // 然後這裡爆炸
編譯器在第二行就擋下來,避免了第四行的執行期災難。為了在保持安全的前提下取回一些彈性,Java 提供有界萬用字元(bounded wildcard):
? extends T:上界萬用字元——「某種是 T 的子型別」。你能安全地讀出 T,但不能寫入(除了null)。? super T:下界萬用字元——「某種是 T 的父型別」。你能安全地寫入 T,但讀出時只保證是Object。
這就濃縮成 Joshua Bloch 在《Effective Java》中的口訣 PECS:Producer Extends, Consumer Super。
看一個例子
來看 Collections 裡一個教科書級的簽章——把元素從來源搬到目的地:
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
for (int i = 0; i < src.size(); i++) {
dest.set(i, src.get(i));
}
}
逐字拆解為什麼是這兩個方向:
src是生產者(producer)——我們只從它讀元素,所以用? extends T。這讓你可以把List<Integer>當作List<? extends Number>的來源。dest是消費者(consumer)——我們只往它寫元素,所以用? super T。這讓你可以把Number寫進List<Object>。
於是下面這種跨型別搬運就能通過編譯,且完全型別安全:
List<Integer> src = List.of(1, 2, 3);
List<Number> dst = new ArrayList<>(Arrays.asList(0, 0, 0));
Collections.copy(dst, src); // Integer(src)-> Number(dst),合法
如果你把方向寫反(從 ? super T 讀、往 ? extends T 寫),編譯器會立刻拒絕——因為那正是不安全的方向。
動手算一下:為什麼 Comparable<? super T>?
回到開頭提到的 Collections.sort 簽章:
public static <T extends Comparable<? super T>> void sort(List<T> list)
那個 ? super T 不是裝飾,而是真實需求。假設有繼承關係:
class Animal implements Comparable<Animal> {
public int compareTo(Animal o) { /* 比體重 */ return 0; }
}
class Dog extends Animal { } // Dog 沒有自己的 compareTo
Dog 並沒有實作 Comparable<Dog>,它繼承的是 Comparable<Animal>。如果 sort 的約束寫成 T extends Comparable<T>,那麼 sort(List<Dog>) 會失敗,因為 Dog 不是 Comparable<Dog>。改成 Comparable<? super T> 後,編譯器接受「Dog 是 Comparable<Animal>,而 Animal 是 Dog 的父型別」,於是 List<Dog> 順利排序。這就是 PECS 的「Consumer Super」用在比較器上的體現——compareTo 是「消費」當前物件去和別人比,需要的是父型別的比較能力。
遞迴泛型界限:讓型別「自我指涉」
最後一個讓人頭暈的進階構造,是型別參數出現在自己的界限裡:
enum Color implements Comparable<Color> { RED, GREEN, BLUE }
// Enum 的真實宣告
public abstract class Enum<E extends Enum<E>> implements Comparable<E> { ... }
E extends Enum<E> 看起來像在繞圈,其實是一種精確的自我約束,稱為 CRTP(Curiously Recurring Template Pattern) 或 F-bounded 多型。它的目的:讓父類別的方法能回傳「子類別自己的型別」,而不是被迫退回父型別。
看一個例子:型別安全的鏈式建造者
abstract class Builder<T extends Builder<T>> {
protected StringBuilder sb = new StringBuilder();
@SuppressWarnings("unchecked")
protected T self() { return (T) this; }
public T add(String part) {
sb.append(part);
return self(); // 回傳子類別型別,鏈式呼叫不會「降級」
}
}
class HtmlBuilder extends Builder<HtmlBuilder> {
public HtmlBuilder tag(String name) {
sb.append("<").append(name).append(">");
return this;
}
}
// 使用:add() 回傳的仍是 HtmlBuilder,所以後面還能呼叫 tag()
String html = new HtmlBuilder()
.add("hello ")
.tag("br") // 若沒有遞迴界限,add() 會回傳 Builder,這行就編不過
.add("world")
.sb.toString();
關鍵在於 add() 透過 self() 回傳 T(也就是 HtmlBuilder),於是鏈式呼叫中途不會掉回基底型別、丟失子類別專屬的 tag() 方法。
標準庫的進階暗門:Collections 的視圖與不可變性
理解泛型機制後,再回看標準庫,你會發現許多設計都建立在這些約束之上。兩個容易誤用的點:
Collections.unmodifiableList 回傳的是「視圖」不是「複本」。
List<Integer> base = new ArrayList<>(List.of(1, 2, 3));
List<Integer> view = Collections.unmodifiableList(base);
view.add(4); // UnsupportedOperationException(如預期)
base.add(99); // 但這個合法!
System.out.println(view); // [1, 2, 3, 99] —— view 跟著變了
unmodifiableList 只是包了一層「禁止修改」的轉接器,底層仍指向原 base。若要真正凍結,請用 List.copyOf(base) 或 List.of(...),它們會建立獨立的不可變複本。
Arrays.asList 回傳的是固定大小的視圖,而且會回頭改動原陣列:
Integer[] arr = {1, 2, 3};
List<Integer> list = Arrays.asList(arr);
list.set(0, 99); // 合法:原陣列 arr[0] 也變成 99
list.add(4); // UnsupportedOperationException:不能改大小
更隱晦的陷阱:Arrays.asList(1, 2, 3) 傳的是 int[] 還是 Integer...?答案取決於你傳基本型別陣列還是包裝型別。Arrays.asList(new int[]{1,2,3}) 會得到一個 List<int[]>(只有一個元素!),因為 int[] 不是 Object[],無法被當成可變參數展開。這正是泛型「只接受參考型別、不接受基本型別」的後果。
重點回顧
- 型別抹除讓泛型只活在編譯期:檢查通過後,型別參數被換成上界(預設
Object)並插入轉型,執行期List<String>與List<Integer>是同一個類別。 - 抹除衍生的限制都有同一個根因——「執行期沒有型別參數」:不能
instanceof T、不能new T[]、泛型不能繼承Throwable;而橋接方法是編譯器為了維持多型偷偷補上的。 - 泛型是不變的;要彈性就用有界萬用字元,並牢記 PECS:Producer Extends(讀用
extends)、Consumer Super(寫用super)。 <T extends Comparable<? super T>>不是炫技,而是讓繼承自父類compareTo的子型別也能被排序。- 標準庫的
unmodifiableList/Arrays.asList回傳的是視圖而非複本,要真正不可變請用List.copyOf/List.of。
深入探討(研究所視角)
變異(variance)的型別理論定位。 Java 用萬用字元提供的是使用點變異(use-site variance):協變(covariance, ? extends)與逆變(contravariance, ? super)標註在「使用該泛型的地方」。對比之下,Kotlin/Scala 主推宣告點變異(declaration-site variance)——在型別宣告時用 out/in(或 +T/-T)一次決定變異方向。兩種設計各有取捨:使用點變異更靈活但每處都要重寫標註;宣告點變異更簡潔但要求設計者預先想清楚。從子型別理論看,這對應到函式型別的經典規則:$A \to B$ 是參數逆變、回傳協變,即 $(A' \to B') <: (A \to B)$ 當且僅當 $A <: A'$ 且 $B' <: B$。
型別推論的演算法核心。 var、菱形運算子 <> 與泛型方法呼叫背後是約束式型別推論(constraint-based inference)。Java 8 之後採用的是基於 Hindley–Milner 思想改良的演算法:先收集 $\alpha <: \text{String}$ 這類子型別約束,再求解。但 Java 的子型別格(subtype lattice)比 ML 複雜得多(有 null、有萬用字元、有界限),因此推論是不完備的——某些情況需要你手動標註型別見證(type witness,如 Collections.<String>emptyList())。理解推論的局限,能幫你判讀那些「明明邏輯對卻編不過」的錯誤訊息。
抹除的安全邊界與 reifiable 型別。 Java 區分可具現化(reifiable)型別(如 String、List<?>、int[])與不可具現化型別(如 List<String>)。可變參數遇上不可具現化型別會產生著名的堆積污染(heap pollution)警告(@SafeVarargs 用來宣告「我保證安全」)。研究層面值得追問:若 Java 改採具現化泛型(如 Valhalla 專案中對特化泛型 List<int> 的探索),能消除裝箱開銷與抹除限制,但代價是相容性與類別膨脹。這正是「型別系統表達力 vs. 執行期成本 vs. 向後相容」三難的真實案例,也是研究所程式語言課程值得深挖的取捨。
延伸閱讀: Bloch《Effective Java》第 5 章(Generics);Naftalin & Wadler《Java Generics and Collections》對萬用字元與抹除有最嚴謹的論述;以及 OpenJDK Valhalla 專案的設計文件,了解 JVM 泛型的下一步。