
Python 入門與環境(進階):位元組碼、物件模型與可重現環境
拆開「直譯器逐行執行」的善意謊言,看清 CPython 從原始碼到執行之間真正走過的每一步
當你按下執行:那行 python hello.py 背後到底發生了什麼?
在入門篇裡,我們學會了寫出第一支程式、認識直譯器(interpreter)會「一行一行讀、一行一行跑」。這個心智模型對初學夠用,但它其實藏了一個善意的謊言:CPython 並不是真的逐行解讀你的原始碼。當你在終端機輸入 python hello.py,在程式印出任何東西之前,Python 已經悄悄把你的整份檔案編譯成一種叫做位元組碼(bytecode)的中介表示,再交給一台虛擬機器(virtual machine)去執行。
如果你曾經好奇:為什麼 Python 明明是「直譯語言」卻會生成 .pyc 檔?為什麼兩個專案裝了不同版本的同一套件卻能和平共存?為什麼 a = b 之後改 a 有時會連 b 一起變、有時又不會?這些問題的答案,全都藏在直譯器、環境與物件模型的細節裡。這篇進階文章就是要把這層「善意的謊言」拆開,讓你看見一支 Python 程式從原始碼到實際執行之間,真正走過的每一步。
編譯與直譯的混血:CPython 的兩段式執行
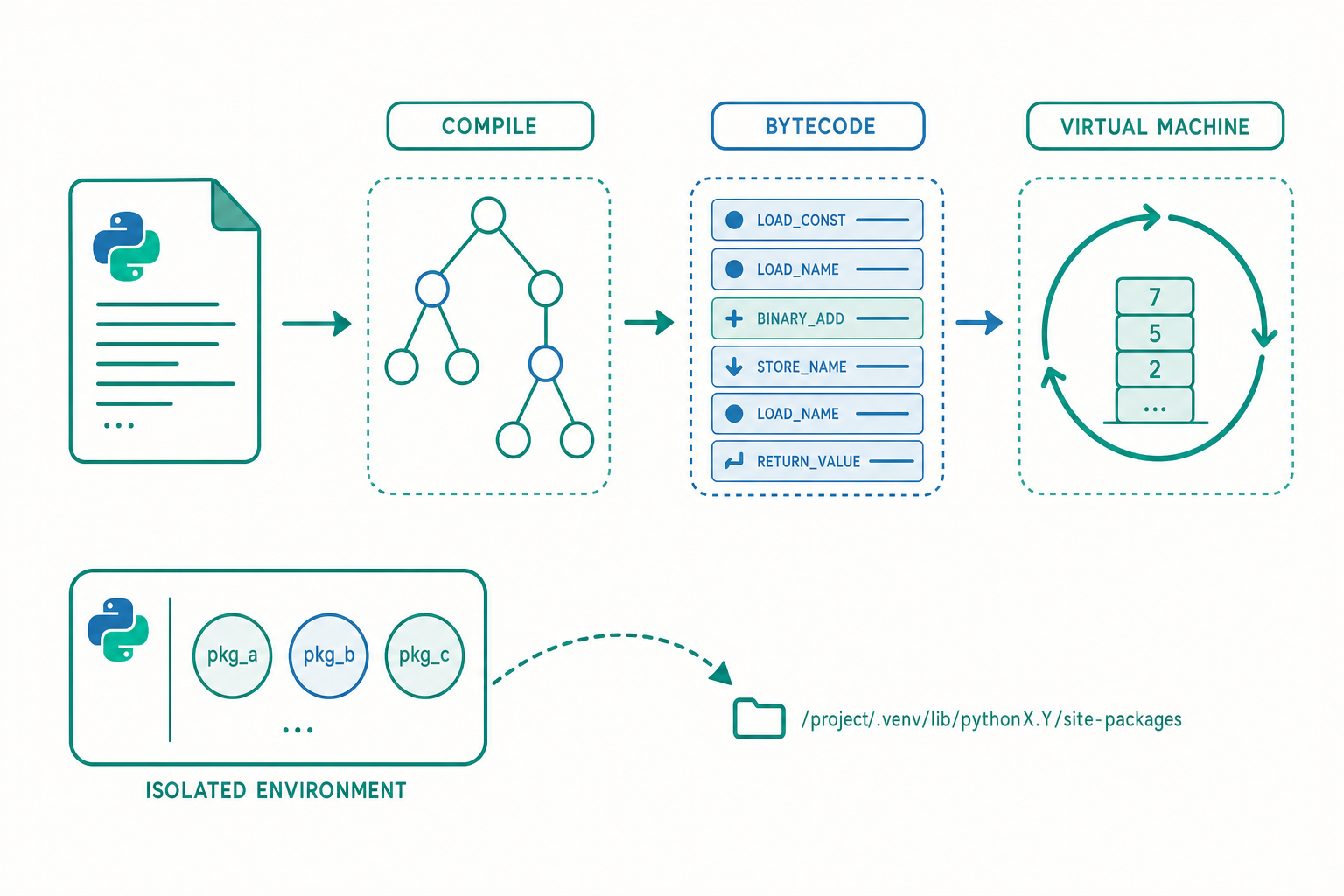
我們常把語言粗分成「編譯式」(如 C,先整份翻成機器碼再跑)與「直譯式」(如傳統 BASIC,邊讀邊跑)。但這個二分法太粗糙了。CPython——也就是你從官網下載、絕大多數人在用的那個 Python——其實是兩段式的:
第一段是編譯(compile):把 .py 原始碼經過詞法分析(tokenize)、語法分析(parse)建出抽象語法樹(Abstract Syntax Tree, AST),再編譯成位元組碼。這一步產生的不是 CPU 能直接執行的機器碼,而是給 Python 虛擬機器(PVM)看的指令。
第二段才是直譯(interpret):PVM 是一個巨大的求值迴圈(evaluation loop),它一條一條讀取位元組碼指令並執行。所以 Python 同時是「編譯」也是「直譯」——它編譯成位元組碼,再直譯這份位元組碼。
你可以親眼看到這份位元組碼。dis 模組(disassembler,反組譯器)就是為此而生:
import dis
def add_and_double(a, b):
total = a + b
return total * 2
dis.dis(add_and_double)
輸出大致長這樣(不同 Python 版本指令名稱會略有差異):
2 LOAD_FAST 0 (a)
LOAD_FAST 1 (b)
BINARY_OP 0 (+)
STORE_FAST 2 (total)
3 LOAD_FAST 2 (total)
LOAD_CONST 1 (2)
BINARY_OP 5 (*)
RETURN_VALUE
讀懂它其實不難:LOAD_FAST 把區域變數推上一個內部堆疊(stack),BINARY_OP 把堆疊頂端兩個值取出做運算再放回去,STORE_FAST 把結果存回變數,RETURN_VALUE 回傳堆疊頂端的值。這就是為什麼 CPython 被歸類為堆疊式虛擬機器(stack-based VM)——它沒有 CPU 那種暫存器(register)的概念,所有運算都在一個求值堆疊上進行。
理解這點有什麼實用價值?當你想知道「x += 1 和 x = x + 1 有沒有差別」「f-string 是不是真的比 + 串接快」這類效能問題時,與其憑感覺猜,不如直接 dis.dis() 看兩種寫法的位元組碼差幾條指令——這是最不會騙人的證據。
.pyc 檔的真相:快取,不是保護
當你 import 一個自己寫的模組,Python 會在旁邊生出一個 __pycache__ 資料夾,裡面有 模組名.cpython-312.pyc 之類的檔案。很多人誤以為這是「編譯後的保護版本」或「執行檔」,其實都不是。
.pyc 只是位元組碼的快取。它存在的唯一目的是:下次再 import 同一個模組時,如果原始碼沒變,就跳過「重新編譯成位元組碼」這一步,直接載入快取,加快啟動速度。檔名裡的 cpython-312 標明了它是由哪個直譯器版本產生的——這也是為什麼換 Python 版本後快取會重建。
兩個關鍵事實值得記住:
第一,.pyc 完全不是加密或保護。它可以被 dis 反組譯回幾乎等價的邏輯,變數名與字串常數都原封不動留著。如果有人告訴你「把 .py 編成 .pyc 就能保護原始碼」,那是錯的。
第二,直接執行的主程式不會產生 .pyc。只有被 import 的模組才會快取。所以你跑 python main.py,main.py 本身不會出現在 __pycache__ 裡,但它 import 的模組會。原因很單純:主程式通常只跑一次,快取它沒有效益。
# 想知道某個 .pyc 對應哪個原始碼、什麼時候編的,可以這樣看
import importlib.util
print(importlib.util.cache_from_source("mymodule.py"))
# -> '__pycache__/mymodule.cpython-312.pyc'
名稱、物件與參考:賦值到底在賦什麼
入門時我們說「變數是一個盒子,把值裝進去」。這個比喻在 Python 裡會害你踩坑,因為 Python 的變數不是盒子,而是貼在物件上的名牌(name binding)。
在 Python 裡,所有東西都是物件,每個物件有自己的身分(identity,可用 id() 查看,實作上接近記憶體位址)。賦值 a = [1, 2, 3] 做的事是:建立一個 list 物件,然後讓名稱 a 指向它。當你寫 b = a,並沒有複製這個 list,而是讓 b 也指向同一個物件。
看一個例子
a = [1, 2, 3]
b = a # b 與 a 指向同一個 list 物件
b.append(4)
print(a) # [1, 2, 3, 4] —— a 也變了!
print(a is b) # True —— 同一個物件
c = a[:] # 切片產生一個新的 list(淺複製)
c.append(5)
print(a) # [1, 2, 3, 4] —— 這次 a 沒變
print(a is c) # False —— 不同物件
理解「名稱綁定」之後,幾個惡名昭彰的陷阱就一目了然了。最經典的是可變的預設參數(mutable default argument):
def add_item(item, bucket=[]): # 危險!
bucket.append(item)
return bucket
print(add_item(1)) # [1]
print(add_item(2)) # [1, 2] —— 不是預期的 [2]!
為什麼?因為預設值 [] 這個 list 物件在函式定義時就建立了一次,之後每次呼叫都重用同一個物件。函式的預設值存在 add_item.__defaults__ 裡,自始至終是同一個 list。正確寫法是用 None 當哨兵(sentinel):
def add_item(item, bucket=None):
if bucket is None:
bucket = [] # 每次呼叫都建立新的
bucket.append(item)
return bucket
這也呼應入門篇對 is 與 == 的區分:== 問「值相等嗎」,is 問「是同一個物件嗎」。在判斷 None 時永遠用 is,因為 None 是單例(singleton),全程式只有一個。
記憶體怎麼回收:參考計數加循環偵測
C 語言要你手動 malloc 與 free,Python 則自動管理記憶體。它的主力機制是參考計數(reference counting):每個物件記錄「有多少名稱或容器正指向我」,計數歸零的瞬間立刻回收。
import sys
x = []
print(sys.getrefcount(x)) # 通常是 2:x 本身 + getrefcount 參數暫時持有
y = x
print(sys.getrefcount(x)) # 3:多了 y
del y
print(sys.getrefcount(x)) # 回到 2
參考計數的優點是即時——物件一沒人用就回收,不必等待。但它有個致命弱點:循環參考(reference cycle)。如果 A 指向 B、B 又指回 A,即使外界已經沒人用它們,兩者的計數都還是 1,永遠歸不了零。
a = {}
b = {}
a["partner"] = b
b["partner"] = a # 互相指向,形成循環
del a
del b # 外界沒人用了,但計數仍 > 0,靠純參考計數無法回收
為了補這個洞,CPython 額外配了一個循環垃圾回收器(cyclic garbage collector),週期性掃描那些「計數沒歸零、但其實構成孤立循環」的物件群並回收它們。這就是 gc 模組管的東西。理解這層機制,你才會知道為什麼長時間執行的服務偶爾會有 GC 造成的微小停頓,以及為什麼處理大量互相參照的物件時要小心記憶體。
環境隔離的真相:venv 到底隔離了什麼
入門篇教過用 python -m venv 建立虛擬環境。但「虛擬環境」這四個字常被想得太神秘。它沒有虛擬化作業系統、沒有沙箱、沒有容器化。它做的事樸素到近乎簡陋:
一個虛擬環境本質上是一個資料夾,裡面有一個指向(或複製)系統 Python 直譯器的連結、一個獨立的 site-packages 套件安裝目錄,以及一個 pyvenv.cfg 設定檔。當你「啟用(activate)」它時,真正改變的只有一件事——把這個資料夾的 bin(Windows 上是 Scripts)塞到 PATH 環境變數最前面,於是你打 python 或 pip 時,系統先找到的是這個環境裡的版本。
關鍵機關藏在直譯器啟動時:Python 會找到自己執行檔旁邊的 pyvenv.cfg,據此把套件搜尋路徑(sys.path)指向這個環境專屬的 site-packages,而不是全系統共用的那個。所以兩個專案各自的 venv 才能裝不同版本的同一套件而互不干擾——它們的 sys.path 指向不同地方。
import sys
# 看看目前直譯器的真身與套件搜尋路徑
print(sys.executable) # 啟用 venv 後會指向 venv 內的 python
print(sys.prefix) # 指向 venv 根目錄
for p in sys.path:
print(p) # 套件就是從這些路徑依序尋找
值得強調的是,現代實務上你不一定要手動 activate。直接呼叫 venv/bin/python script.py(完整路徑)效果完全相同——activate 只是個方便的捷徑,真正起作用的是「用哪個 Python 執行檔」。本專案的 cron 腳本就是直接寫完整路徑 /var/www/uedu_tw/venv/bin/python,正是這個道理。
可重現性:鎖定版本,而不是祈禱
當你的程式要交給別人跑、或部署到伺服器時,「在我電腦上可以跑」是不夠的。真正的工程問題是可重現性(reproducibility):別人裝出來的環境要和你一模一樣。
pip freeze 能匯出當前環境精確到版本號的套件清單:
pip freeze > requirements.txt
# 內容類似:
# flask==3.0.2
# pymysql==1.1.0
# openai==1.30.1
但這裡有個常被忽略的層次差別。requirements.txt 只鎖了你直接列出的套件,而每個套件又會拉進一堆間接相依(transitive dependencies)。如果只用寬鬆的版本範圍(如 flask>=3.0),不同時間裝出來的間接相依版本可能不同,於是出現「同一份 requirements,今天裝和上個月裝行為不一樣」的詭異現象。這就是為什麼會有 pip-tools、poetry、uv 這類工具產生鎖定檔(lock file)——把整棵相依樹的每個版本與雜湊值(hash)都釘死,達成位元級的可重現。
動手算一下
假設你的專案直接相依 5 個套件,每個套件平均又相依 4 個套件,而那些套件平均再相依 3 個。光算前三層,實際被裝進環境的套件數量級是:
$$5 + 5 \times 4 + 5 \times 4 \times 3 = 5 + 20 + 60 = 85$$
也就是說,你「明明只裝了 5 個套件」,環境裡卻可能躺著近百個套件。任何一個的版本飄移都可能讓行為改變。這個簡單估算就解釋了為什麼「只鎖直接相依」遠遠不夠,以及為什麼可重現性是個需要工具支援、而非靠人記憶的工程課題。
重點回顧
- CPython 是兩段式的:先把原始碼編譯成位元組碼(bytecode),再由堆疊式虛擬機器(stack-based VM)直譯執行。用
dis模組可以親眼看到位元組碼,是判斷效能差異最可靠的方法。 .pyc是快取,不是保護:它加速重複 import,但可被輕易反組譯,沒有任何加密效果;直接執行的主程式不產生.pyc。- Python 變數是名牌不是盒子:賦值是名稱綁定(name binding),
b = a不複製物件。這解釋了可變預設參數陷阱,以及為什麼判斷None要用is。 - 記憶體靠參考計數 + 循環回收:計數歸零即時回收,循環參考則由
gc週期性偵測清除。 - venv 只是改路徑:它不虛擬化系統,本質是切換
sys.path指向專屬的site-packages;可重現性要靠鎖定整棵相依樹的版本,而非只列直接相依。
深入探討(研究所視角)
把鏡頭拉遠,這篇談的每個主題都通往一個更深的計算機科學議題。
從位元組碼到 JIT 編譯。 CPython 的求值迴圈用的是一種叫 computed goto 的分派(dispatch)技巧加速指令切換,但本質上每條位元組碼仍需經過「取指令、解碼、執行」的循環,這正是 Python 比 C 慢的結構性原因。近年的方向是即時編譯(Just-In-Time compilation, JIT):PyPy 用 meta-tracing 技術,在執行期觀察到熱點迴圈後把它編譯成機器碼;而 CPython 自 3.13 起也引入了實驗性的 JIT 與「無 GIL(free-threaded)」建置選項。值得探究的研究問題是:在保有 Python 動態語意(任何屬性都可能在執行期被改)的前提下,編譯器能做多少假設與優化?這牽涉到特化(specialization)與去最佳化保護(deoptimization guard)的設計權衡。
全域直譯器鎖(GIL)與並行模型。 CPython 的參考計數不是執行緒安全的,為了避免每次增減計數都上鎖的開銷,歷史上採用一把全域直譯器鎖(Global Interpreter Lock, GIL):同一時刻只有一條執行緒能執行 Python 位元組碼。這讓 CPython 在 CPU 密集任務上無法靠多執行緒擴展,是長年爭議。free-threaded CPython(PEP 703)正試圖移除 GIL,但代價是參考計數要改用更複雜的並行安全方案(如偏向鎖、不可變物件免計數)。這是一個經典的正確性與效能權衡(correctness-performance trade-off)案例,值得對照 Java、Go 的記憶體模型來思考。
import 系統作為一個可程式化協定。 我們談的 sys.path 與 .pyc 快取,其實只是 import 機制的表層。完整的 import 系統是一套由 finder(尋找器) 與 loader(載入器) 構成的可插拔協定(importlib),你甚至能寫一個從網路、從加密來源、從記憶體載入模組的自訂 finder。venv 的隔離、namespace package、乃至把 .zip 當套件來源,全都建立在這套協定上。這通往一個更普遍的軟體工程主題:相依解析(dependency resolution)本身是一個 NP 困難的可滿足性問題——當套件 A 要 B<2、套件 C 要 B>=2 時,求解器要在版本約束的組合空間裡找出可行解,這正是 pip 新版解析器與 uv 等工具投入大量工程的所在。
把這些線索串起來,你會發現「執行一支 Python 程式」絕非小事:它橫跨了編譯器設計、虛擬機器、記憶體管理、並行理論與相依求解。入門讓你會用這門語言,而理解這些底層機制,才讓你有能力判斷它在什麼情境下會慢、會錯、會難以重現——以及如何應對。