
文字與多媒體編碼
從 ASCII、Unicode 到 UTF-8,理解亂碼的成因,並認識聲音、影像如何數位化與壓縮
為什麼朋友傳來的訊息變成一堆「□□□」?
你一定遇過這種情況:朋友從某個老舊系統複製一段中文貼到聊天室,結果你看到的卻是「ä¸æ–‡」或滿螢幕的「□□□」。明明對方打的是好好的中文,到了你這裡卻成了無法辨識的符號。這不是網路出錯,也不是檔案毀損,而是一個更根本的問題:電腦其實看不懂文字,它只認得數字。
電腦內部只有 0 與 1,所有的字、聲音、圖片、影片,最終都得轉換成一串數字才能被儲存與傳輸。把「人類看得懂的內容」翻譯成「電腦能處理的數字」,這個翻譯規則就叫做編碼(encoding)。而當寫入時用的規則,跟讀出時用的規則對不上,亂碼就誕生了。本文會帶你從最基礎的 ASCII,一路理解到中文如何被編碼、聲音與影像如何數位化,以及壓縮背後的核心概念。
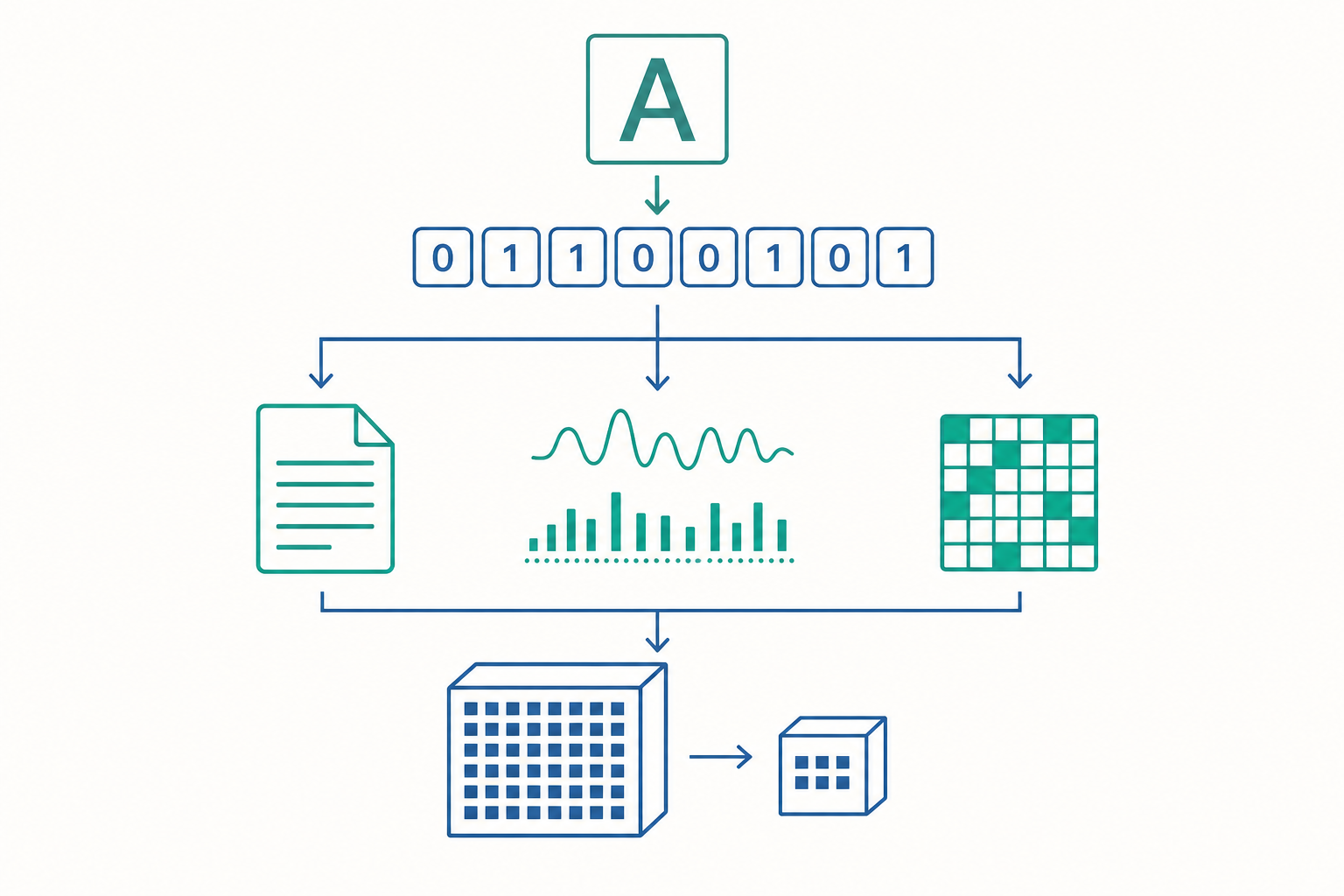
ASCII:一切的起點
在 1960 年代,電腦主要在英語世界使用,工程師需要一套統一的對照表,把英文字母、數字與符號對應到數字。這套表就是 ASCII(American Standard Code for Information Interchange)。
ASCII 用 7 個位元(bit)來表示一個字元,可以表達 $2^7 = 128$ 種不同的符號。它涵蓋了:
- 大小寫英文字母(A–Z 對應 65–90,a–z 對應 97–122)
- 數字 0–9(對應 48–57)
- 標點符號(如
!、?、,) - 控制字元(如換行、Tab、退格,這些看不見但有作用)
舉例來說,當你在鍵盤上按下大寫 A,電腦實際儲存的是數字 65,也就是二進位的 1000001。
ASCII 簡單又高效,但它有個致命限制:只有 128 個位置。對英文夠用,但世界上有中文、日文、阿拉伯文、emoji……光是常用中文字就有數千個。128 個格子,連塞中文的零頭都不夠。於是各國各自發明了自己的擴充編碼(例如台灣的 Big5、中國的 GB2312),彼此互不相容——這正是早期跨國亂碼的溫床。
Unicode:給全世界每個字一個身分證
為了終結各國編碼各自為政的混亂,Unicode 應運而生。它的理念很單純卻很偉大:為人類使用過的每一個字元,分配一個唯一的編號,這個編號稱為碼點(code point)。
碼點通常寫成 U+ 加上十六進位數字。例如:
- 字母
A是U+0041(十進位 65,與 ASCII 相容) - 中文「中」是
U+4E2D - 笑臉 emoji 😀 是
U+1F600
到目前為止,Unicode 已收錄超過十萬個字元,足以容納全球幾乎所有語言文字,外加數學符號、emoji 等。
但這裡要釐清一個常見迷思:Unicode 只是「字元與編號的對照表」,它本身並沒有規定這些編號要怎麼用位元組存進檔案。從「碼點」到「實際的位元組序列」,還需要一套編碼方式(encoding form),而其中最重要、最普及的就是 UTF-8。
UTF-8:聰明的變長編碼
如果直接把每個碼點都用固定 4 個位元組儲存,那麼一篇純英文文章的體積會暴增四倍(因為英文只用得到最小的數字,前面三個位元組全是 0,純屬浪費)。UTF-8 的精妙之處在於它是變長編碼(variable-length encoding):常用的字用較少位元組,罕用的字才用較多位元組。
UTF-8 的規則是這樣的:
| 碼點範圍 | 位元組數 | 用途範例 |
|---|---|---|
| U+0000 – U+007F | 1 | ASCII 英文、數字、符號 |
| U+0080 – U+07FF | 2 | 拉丁字母擴充、希臘文、希伯來文 |
| U+0800 – U+FFFF | 3 | 中文、日文、韓文 |
| U+10000 – U+10FFFF | 4 | emoji、罕見字 |
UTF-8 最漂亮的設計,是它完全相容 ASCII:任何一個 ASCII 字元在 UTF-8 中仍然是那一個位元組、那個數值。這代表所有舊有的英文文件,天生就是合法的 UTF-8。也正因如此,UTF-8 成為今天網路上的事實標準,超過 98% 的網頁都採用它。
動手看一個例子
讓我們實際拆解,看看中文「中」是怎麼被 UTF-8 編碼成位元組的。「中」的碼點是 U+4E2D,落在 3 位元組範圍。
UTF-8 的 3 位元組格式是固定的樣板(x 代表存放資料的位置):
1110xxxx 10xxxxxx 10xxxxxx
注意這些開頭的標記位元:第一個位元組以 1110 開頭,告訴讀取程式「接下來總共有 3 個位元組」;後續每個位元組都以 10 開頭,表示「我是延續位元組,不是新字的開頭」。這個設計讓程式即使從檔案中間開始讀,也能快速判斷字元的邊界。
接著把碼點 U+4E2D 換成二進位(共 16 位元),依序填入樣板的 x:
U+4E2D = 0100 1110 0010 1101 (二進位)
填入樣板:
1110 0100 10 111000 10 101101
└─0100 └─111000 └─101101
最終 3 個位元組(十六進位):E4 B8 AD
我們可以用 Python 驗證:
s = "中"
encoded = s.encode("utf-8")
print(encoded) # b'\xe4\xb8\xad'
print(len(encoded)) # 3 → 佔 3 個位元組
# 對照純英文
print("A".encode("utf-8")) # b'A' → 只佔 1 個位元組
結果正是 E4 B8 AD,與我們手算一致。
亂碼到底怎麼來的
理解了編碼,亂碼的成因就一目了然了。亂碼的本質是:寫入時用一套規則,讀取時卻用了另一套規則。
- 對方用 UTF-8 存了「中」(位元組
E4 B8 AD),但你的程式誤以為這是 Big5 編碼去解讀,於是把這 3 個位元組拆成不同的字,跑出「銝」之類的怪字。 - 反過來,UTF-8 的中文若被當成 Latin-1(西歐單位元組編碼)逐位元組解讀,就會變成「ä¸」這種西文字母拼湊。
- 那個「□」或「�」則是替換字元:程式知道這串位元組「不是合法的某編碼」,無法對應到任何字,只好用一個佔位符告訴你「這裡有東西,但我認不出來」。
解方也很清楚:從頭到尾使用同一套編碼。今天的最佳實務就是統一採用 UTF-8——寫檔、讀檔、網頁宣告(<meta charset="utf-8">)、資料庫欄位,全部對齊,亂碼自然絕跡。
聲音的數位化:取樣與量化
文字只是開端。聲音本質上是空氣中連續變化的波形,而電腦只能處理離散的數字,因此必須把連續的聲波切成一個個數值。這個過程靠兩個步驟:取樣(sampling) 與 量化(quantization)。
取樣是「在時間軸上切割」:每隔一段極短的時間,測量一次聲波的振幅。每秒取樣的次數稱為取樣率(sampling rate),單位是赫茲(Hz)。CD 音質的取樣率是 44100 Hz,也就是每秒測量 44100 次。
為什麼是這個數字?根據奈奎斯特定理(Nyquist theorem),要完整還原一個頻率為 $f$ 的聲音,取樣率至少要達到 $2f$。人耳可聽範圍約到 20000 Hz,因此 $2 \times 20000 = 40000$ Hz 是理論下限,44100 Hz 留了一點餘裕。
量化則是「在振幅軸上切割」:每次測得的振幅,要對應到一個離散的數值。能用幾個位元來記錄這個數值,稱為位元深度(bit depth)。CD 採用 16 位元,能表示 $2^{16} = 65536$ 個不同的音量階層。位元深度越高,音量的層次就越細膩,量化造成的誤差(量化雜訊)也越小。
一段未壓縮聲音的資料量可以這樣估算:
$$\text{每秒位元組數} = \text{取樣率} \times \frac{\text{位元深度}}{8} \times \text{聲道數}$$
以 CD 立體聲為例:$44100 \times \frac{16}{8} \times 2 = 176400$ 位元組/秒,約 172 KB。一首四分鐘的歌就要 40 MB 以上——這正是為什麼我們需要壓縮。
影像的數位化:像素與色彩深度
數位影像由一格格的像素(pixel) 構成,每個像素是一個帶有顏色的小方塊。影像的解析度(例如 1920×1080)指的就是水平與垂直方向各有多少像素。
每個像素的顏色怎麼表示?最常見的是 RGB 模型:用紅(Red)、綠(Green)、藍(Blue)三原色的強度混合出各種顏色。若每個顏色分量用 8 個位元(0–255)來記錄,三個分量合起來就是 24 位元,這稱為色彩深度(color depth) 24 位元,可表現 $2^{24} \approx 1677$ 萬種顏色,俗稱「全彩」。
一張未壓縮的全彩影像,資料量為:
$$\text{位元組數} = \text{寬} \times \text{高} \times \frac{\text{色彩深度}}{8}$$
一張 1920×1080 的全彩照片:$1920 \times 1080 \times 3 = 6220800$ 位元組,約 5.9 MB。影片每秒約 30 張這樣的畫面,一分鐘未壓縮影片就超過 10 GB。再一次,壓縮成了不可或缺的技術。
壓縮:用更少的位元說同樣的事
壓縮(compression) 的目標,是用更少的位元組來表達同樣(或近乎同樣)的內容。它分成兩大類:
無損壓縮(lossless compression):解壓後能 100% 還原原始資料,一個位元都不差。它利用資料中的重複與規律來節省空間。例如一張圖有連續 1000 個白色像素,與其老實記 1000 次,不如記成「白色 ×1000」——這就是遊程編碼(run-length encoding) 的概念。文字檔的 ZIP、圖片的 PNG、無損音樂 FLAC 都屬此類。重要資料(程式碼、文件、原始資料)必須用無損壓縮。
有損壓縮(lossy compression):刻意丟棄人類不易察覺的細節來換取更高的壓縮率,解壓後無法完全還原。JPEG 照片、MP3 音樂、MP4 影片都是有損的。MP3 會移除人耳難以聽見的頻率,JPEG 會犧牲人眼不敏感的細微色彩變化。檔案因此小上數十倍,但每壓一次就掉一點品質——這也是為什麼 JPEG 反覆儲存後會越來越糊。
選擇的原則很單純:能不能容忍失真。試算表、合約、病歷不能失真,用無損;串流影音、社群相片可以接受些微失真換取流量,用有損。
重點回顧
- 電腦只認得數字,編碼就是把文字、聲音、影像翻譯成數字的規則;寫入與讀取規則不一致就會產生亂碼。
- ASCII 用 7 位元表示 128 個英文字符;Unicode 為全世界每個字元分配唯一碼點;UTF-8 是把碼點轉成位元組的變長編碼,相容 ASCII 且是當今網路標準。
- 聲音數位化靠取樣(切時間,取樣率受奈奎斯特定理約束)與量化(切振幅,位元深度決定精細度);影像則由像素與色彩深度決定。
- 壓縮分為可完全還原的無損(PNG、ZIP、FLAC)與犧牲細節換體積的有損(JPEG、MP3、MP4);選擇取決於是否容忍失真。
深入探討(研究所視角)
從更底層看,UTF-8 的變長設計並非任意,而是一套自同步(self-synchronizing) 的前綴碼。每個位元組透過開頭的標記位元(0、110、1110、11110 表示字首;10 表示延續),讓任何延續位元組都不可能被誤認為字首。這帶來實務上的關鍵好處:即使資料流中途有位元組遺失或從隨機位置開始讀取,程式只要往後掃描到下一個非 10 開頭的位元組,就能重新對齊字元邊界,最多損失一個字元而不會整串崩解。這也使得 UTF-8 的字串能安全地用簡單的位元組比對來搜尋子字串——一個合法字元的位元組序列絕不會偶然出現在另一個字元的位元組序列之中。
壓縮的理論上限則由資訊理論(information theory) 給出。Claude Shannon 定義了熵(entropy) 來量化一個資訊源的平均不確定性:
$$H(X) = -\sum_{i} p(x_i) \log_2 p(x_i)$$
其中 $p(x_i)$ 是符號 $x_i$ 出現的機率。熵代表「平均每個符號至少需要幾個位元才能無損編碼」的理論下限。任何無損壓縮演算法都無法把資料壓得比其熵更小——這是物理般的硬限制。霍夫曼編碼(Huffman coding) 正是逼近此下限的經典方法:替出現頻率高的符號分配較短的位元碼、頻率低的分配較長的碼,讓平均碼長趨近熵值。更現代的算術編碼(arithmetic coding) 與 ZIP 使用的 DEFLATE(結合 LZ77 字典法與霍夫曼)則進一步提升效率。
值得一提的是,這也解釋了一個常見現象:已經壓縮過的檔案(如 JPEG、MP3)再用 ZIP 壓幾乎縮不動。因為有損壓縮已經把資料推向接近其熵的高亂度狀態,剩下的位元幾乎沒有可利用的冗餘了。
有損壓縮則跳脫純粹的資訊理論,引入了感知模型(perceptual model)。JPEG 的核心是離散餘弦轉換(discrete cosine transform, DCT),把影像從空間域轉到頻率域,再依據人眼對高頻細節較不敏感的特性,對高頻分量做較粗的量化而捨棄之。MP3 的心理聲學模型(psychoacoustic model) 則利用聽覺遮蔽效應——一個響亮的音會掩蓋鄰近頻率的微弱音,於是那些反正聽不見的成分就被丟棄。這把「壓縮」從單純的數學問題,連結到了人類感官的生理特性,也呼應了本平台 Educational Omics 框架中 PhysioNeuromics 維度對感知與生理訊號的關注:理解資料如何被人類感知,往往是高效表示資料的關鍵。