
C++ 編譯進階:翻譯單元、ODR 與抽象機器
從四階段建置流程、One Definition Rule 到 name mangling 與 undefined behavior,看懂 C++ 建置系統的真正運作機制
為什麼改了一個標頭檔,整個專案要重編三分鐘?
你已經知道 C++ 程式從原始碼到可執行檔,要經過編譯(compile)與連結(link)。但當你真正開始寫稍具規模的程式,會遇到一些令人困惑的現象:明明只改了一行 .h 檔,重新建置卻要花好幾分鐘;兩個 .cpp 都 include 了同一個函式定義,連結器就跳出一長串看不懂的 multiple definition 錯誤;換了個編譯器,同一份程式碼竟然執行結果不一樣。
這些現象都不是隨機的。它們的根源,藏在入門篇沒有細談的地方——翻譯單元(translation unit)、One Definition Rule(ODR)、name mangling,以及 C++ 標準如何用「抽象機器」定義程式的意義。讀懂這些機制,你才能真正掌握 C++ 建置系統,而不是把編譯器當成黑盒子,出錯時只能瞎猜。
編譯流程的真正樣貌:四個階段
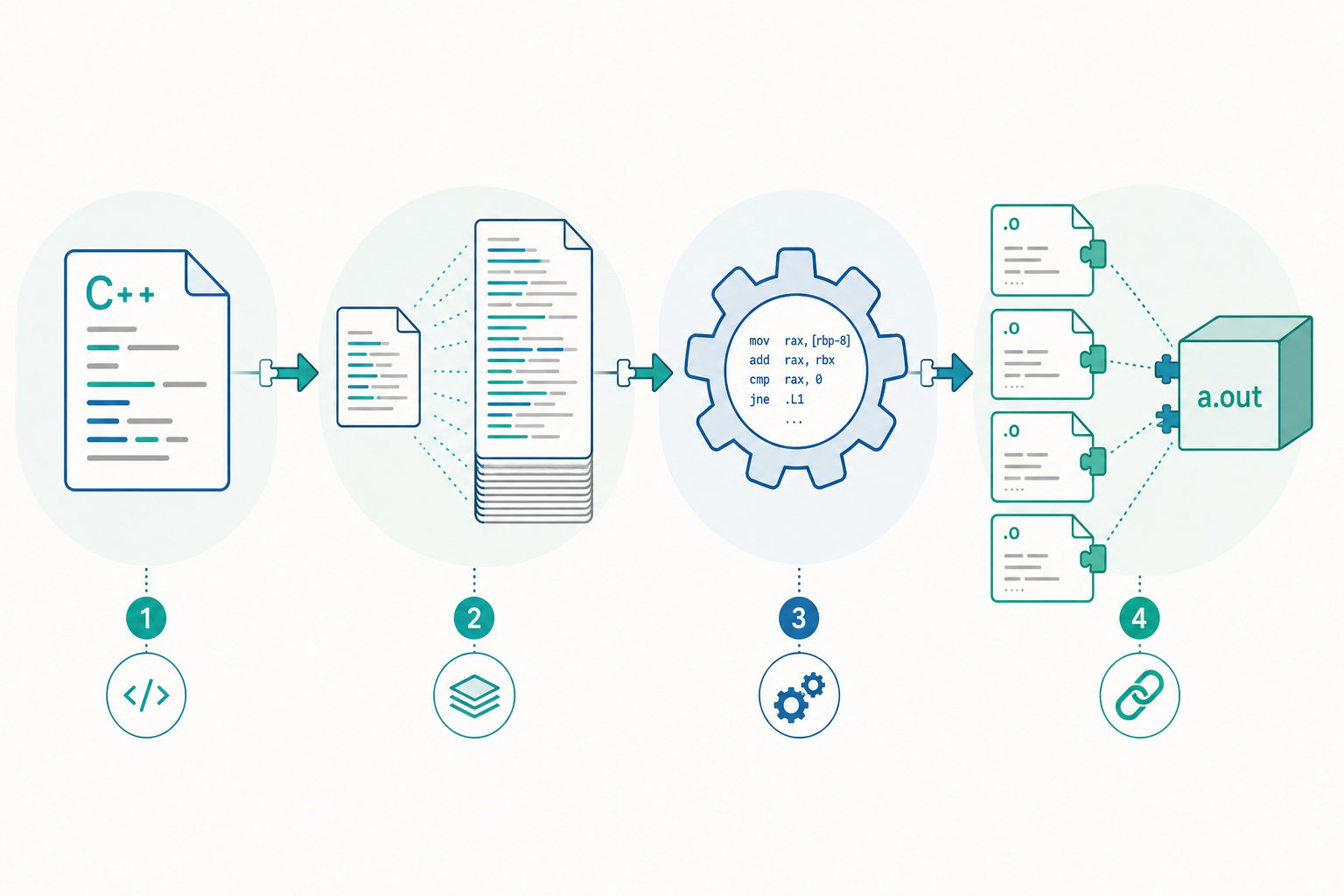
入門篇把「編譯」當成單一動作,但實際上一個 .cpp 變成 .o(object file,目的檔)要走過四個獨立階段。我們用 GCC 來把每個階段的中間產物逼出來:
# 階段一:前置處理(preprocessing)——展開 #include、#define、#ifdef
g++ -E main.cpp -o main.ii
# 階段二:編譯成組合語言(compilation)
g++ -S main.ii -o main.s
# 階段三:組譯成機器碼目的檔(assembly)
g++ -c main.s -o main.o
# 階段四:連結(linking)——把多個 .o 與函式庫合成可執行檔
g++ main.o -o main
關鍵理解在階段一。前置處理器(preprocessor)不懂 C++ 語法,它只做純文字替換。當你寫 #include <vector>,它就把 <vector> 整個檔案的內容原封不動貼進來。這就是為什麼一個只有 10 行的 main.cpp,經過 -E 之後可能膨脹成幾萬行:
g++ -E main.cpp | wc -l
# 輸出可能是 40000 行以上
這也直接回答了開頭的問題:當你改了一個被很多 .cpp include 的標頭檔,每一個包含它的翻譯單元都必須重新走完整個四階段流程。標頭檔的「文字貼上」特性,讓它的修改具有放射狀的影響範圍。
翻譯單元與 One Definition Rule
C++ 編譯的基本單位不是「檔案」,而是翻譯單元:一個 .cpp 加上它透過 #include 遞迴拉進來的所有標頭內容,前置處理完成後的整體。每個翻譯單元被獨立編譯成一個 .o,彼此互不知道對方的存在。編譯器看 a.cpp 時,完全不知道 b.cpp 寫了什麼。
這個「獨立編譯」模型威力強大(可平行編譯、可增量建置),但也帶來一條必須遵守的鐵律——One Definition Rule(ODR,單一定義規則):
- 任何變數、函式、類別、樣板,在整個程式中只能有一個定義(definition)。
- 但宣告(declaration)可以出現無限多次。
宣告與定義的差別是理解 C++ 連結的核心。宣告只告訴編譯器「這東西存在、長這樣」;定義才真正配置實體(函式的程式碼、變數的記憶體)。
看一個例子
假設我們犯了一個經典錯誤,把函式定義放進標頭檔:
// math_utils.h —— 錯誤示範
int square(int x) { // 這是「定義」,不是宣告
return x * x;
}
// a.cpp
#include "math_utils.h"
int useA() { return square(3); }
// b.cpp
#include "math_utils.h"
int useB() { return square(4); }
前置處理後,a.o 和 b.o 各自都含有一份 square 的完整機器碼。連結器把它們湊在一起時發現有兩個 square,違反 ODR,於是報錯:
/usr/bin/ld: b.o: in function `square(int)':
b.cpp:(.text+0x0): multiple definition of `square(int)';
a.o:b.cpp:(.text+0x0): first defined here
正確做法是標頭只放宣告,定義放在單一 .cpp:
// math_utils.h
int square(int x); // 宣告(declaration)
// math_utils.cpp
int square(int x) { // 定義(definition),只此一份
return x * x;
}
那 inline 函式和標頭裡的類別成員函式為什麼能放在標頭、被多個 .cpp include 卻不報錯?因為它們屬於 ODR 的特例:標準允許 inline 實體在多個翻譯單元中各有一份完全相同的定義,連結器會把這些重複的定義「摺疊」成一份。這正是現代 header-only 函式庫能成立的基礎,也是 C++17 引入 inline 變數的動機。
連結階段的核心:符號與 name mangling
連結器(linker)的工作是「對帳」。每個 .o 裡有兩種符號(symbol):
- 已定義符號(defined):我這裡有
square的實體。 - 未定義符號(undefined):我用到了
square,但實體在別處,請幫我找。
連結器把所有 .o 的未定義符號,與某個 .o 提供的已定義符號配對。配不上就是那個你一定踩過的錯誤:undefined reference to ...。
但這裡藏著 C++ 特有的機制。C++ 支援函式多載(overloading),print(int) 和 print(double) 是兩個不同函式。可是連結器只認符號名稱字串,光靠 print 無法區分。解法是 name mangling(名稱修飾):編譯器把函式的參數型別、命名空間等資訊編碼進符號名稱。
namespace geo {
int area(int w, int h);
double area(double r);
}
編譯後用工具觀察符號:
g++ -c shapes.cpp -o shapes.o
nm shapes.o | c++filt # nm 列符號,c++filt 還原成可讀名稱
你會看到類似這樣的修飾名稱(以 Itanium ABI 為例):
_ZN3geo4areaEii -> geo::area(int, int)
_ZN3geo4areaEd -> geo::area(double)
_ZN3geo4area... 把命名空間 geo、函式名 area、參數型別 ii(兩個 int)/ d(double)全部編碼進去,於是兩個多載成了兩個不同符號。
這也解釋了一個跨語言開發的經典陷阱:當你要在 C++ 裡呼叫 C 函式庫,必須用 extern "C" 包起來,關閉 name mangling,否則連結器會去找一個被修飾過的名稱,而 C 編譯出來的符號沒有修飾,配對失敗:
extern "C" {
#include "legacy_c_lib.h" // C 函式:符號不做 mangling
}
理解 mangling 後,你看到 undefined reference to 'foo(int)' 這種帶參數型別的錯誤,就知道是 C++ 連結;看到 undefined reference to 'foo' 光禿禿沒參數,多半牽涉 C 連結或 extern "C"。
動手算一下:宣告、定義與連結錯誤的對應
給定以下三個檔案,判斷會發生什麼:
// counter.h
extern int g_count; // 宣告全域變數(extern = 定義在別處)
void tick(); // 宣告函式
// main.cpp
#include "counter.h"
#include <cstdio>
int main() {
tick();
printf("%d\n", g_count);
return 0;
}
// counter.cpp
#include "counter.h"
int g_count = 0; // 定義
void tick() { ++g_count; } // 定義
逐項推理:
counter.h兩行都是宣告,可被任意多個.cppinclude,不違反 ODR。g_count用extern修飾——若拿掉extern,標頭就變成「定義」,被main.cpp與counter.cpp各 include 一次就成了兩個定義,連結報multiple definition。g_count = 0與tick()的實體在counter.cpp,只此一份,符合 ODR。
所以:只編譯 main.cpp 不連結 counter.o 會得到 undefined reference to 'g_count' 與 undefined reference to 'tick()';正確連結則一切正常:
g++ main.cpp counter.cpp -o app # 正確
g++ main.cpp -o app # undefined reference!缺 counter.o
C++ 標準與「抽象機器」:為什麼換編譯器結果會變
入門篇可能讓你以為「C++ 程式碼決定了一切行為」。但其實 C++ 標準(ISO/IEC 14882)並不直接描述真實 CPU,而是定義了一台抽象機器(abstract machine)。標準只規定「在這台抽象機器上,程式應觀察到什麼效果」,至於底層 CPU 怎麼達成,是編譯器與硬體的自由。這帶來三個層級的「不確定」:
- 未指定行為(unspecified behavior):標準允許多種結果,但不要求記錄。例如函式參數的求值順序——
f(g(), h())中g()與h()誰先執行,C++17 之前沒有保證。 - 實作定義行為(implementation-defined):結果由實作決定,但必須記錄。例如
int的位元數、char是否帶號。 - 未定義行為(undefined behavior, UB):標準完全放棄保證。例如有號整數溢位、存取陣列越界、解參考空指標。
UB 是 C++ 最危險也最被誤解的概念。許多學生以為「未定義」代表「會當掉」或「會回傳垃圾值」,但實際上更可怕——編譯器可以假設 UB 永遠不發生,並據此最佳化。
看一個例子:UB 如何讓檢查「消失」
#include <climits>
#include <cstdio>
int check(int x) {
if (x + 100 < x) { // 想偵測「加 100 後溢位」
return -1; // 溢位了
}
return x + 100;
}
int main() {
printf("%d\n", check(INT_MAX));
return 0;
}
直覺上 INT_MAX + 100 會溢位,x + 100 < x 應為真,回傳 -1。但有號整數溢位是 UB。編譯器推理:「既然 UB 不會發生,那 x + 100 必定不溢位,所以 x + 100 < x 數學上恆為假」,於是在 -O2 下直接把整個 if 刪掉:
g++ -O2 -S overflow.cpp -o overflow.s
# 在組合語言中你會發現比較與分支整段消失了
這不是編譯器的 bug,而是標準授權的合法最佳化。教訓是:偵測溢位不能依賴溢位本身的行為,要用安全寫法:
if (x > INT_MAX - 100) { /* 即將溢位 */ } // 比較前先確保不溢位
理解抽象機器,你才會明白為什麼同一份含 UB 的程式碼,在 -O0 與 -O2、在不同編譯器之間結果會南轅北轍——不是玄學,是你的程式違反了與標準的契約。實務上請善用 -Wall -Wextra 與 -fsanitize=undefined(UBSan)在執行期捕捉這類錯誤。
預處理器與 include guard:別讓標頭被貼兩次
既然 #include 是純文字貼上,那當 a.h include c.h、b.h 也 include c.h,而某個 .cpp 同時 include a.h 與 b.h,c.h 的內容就會被貼兩次,導致重複定義。解法是 include guard(包含防衛):
// c.h
#ifndef C_H // 若尚未定義 C_H
#define C_H // 就定義它
// ... 標頭內容 ...
#endif // C_H
第二次貼上時 C_H 已定義,#ifndef 為假,整段內容被跳過。現代編譯器普遍支援更簡潔的 #pragma once:
// c.h
#pragma once
// ... 標頭內容 ...
兩者目的相同,但機制不同:include guard 是標準保證、靠巨集名稱去重(巨集撞名會出問題);#pragma once 靠編譯器以檔案的實際路徑/inode 去重,更不易撞名,但非標準(雖然幾乎所有主流編譯器都支援)。
重點回顧
- 編譯實際分四階段:前置處理 → 編譯 → 組譯 → 連結。前置處理是純文字替換,這解釋了改標頭檔為何觸發大範圍重編。
- C++ 的編譯單位是翻譯單元(
.cpp+ 遞迴 include 的標頭),各自獨立編譯,再由連結器對帳。 - One Definition Rule:定義全程式唯一、宣告可重複。「標頭放宣告、
.cpp放定義」正是為了遵守它;inline是其特例。 - Name mangling 把參數型別等編碼進符號名稱以支援多載;跨語言呼叫 C 要用
extern "C"關閉它。 - C++ 標準以抽象機器定義語意,留下 unspecified / implementation-defined / undefined behavior 三層空間;UB 會被編譯器當作「不可能發生」而觸發激進最佳化。
深入探討(研究所視角)
ODR 的形式化與 ABI 穩定性。 ODR 在標準中其實是一組精細的條件:同一實體在不同翻譯單元的多份定義必須由「相同的 token 序列」組成,且名稱查找解析到相同實體。當你連結兩個用不同編譯旗標(如不同 -D 巨集、不同 std 版本)編出的 .o,可能在語法上都通過卻造成 ODR violation(IFNDR,ill-formed, no diagnostic required)——標準不要求編譯器報錯,程式卻已進入未定義狀態。這是大型專案「明明都能編、跑起來卻詭異崩潰」的隱形殺手,也是 C++20 模組(modules)想根除的問題之一。模組以語意化的匯入取代文字貼上,從根本上消除標頭的重複貼上與巨集污染。
Name mangling 與 ABI。 mangling 規則屬於 ABI(Application Binary Interface,應用程式二進位介面)的一部分。Itanium C++ ABI(Linux/macOS 上 GCC、Clang 採用)與 MSVC ABI 的 mangling 方案完全不同,這就是為什麼 Windows 上不能直接連結 GCC 與 MSVC 編出的 C++ 目的檔。ABI 還規範了物件佈局、虛擬表(vtable)結構、例外處理的展開(unwinding)等。理解 ABI 是做跨編譯器外掛、二進位相容函式庫的必修課。
As-if rule 與最佳化的理論邊界。 抽象機器的核心是 as-if rule:編譯器可任意轉換程式,只要最終的可觀察行為(observable behavior,主要指 I/O 與 volatile 存取)與抽象機器一致即可。這給了最佳化器極大自由——它可重排、合併、刪除運算。UB 之所以威力驚人,正是因為它「擴大了 as-if 的適用範圍」:一旦某路徑含 UB,編譯器就無須維持該路徑的任何可觀察行為。研究編譯器最佳化(如 LLVM 的 -O2 pass pipeline)時,你會看到 InstCombine、GVN、死碼消除等 pass 如何在 as-if rule 的授權下運作。延伸閱讀可從 LLVM IR 與 SSA(static single assignment)形式入手,理解最佳化器如何在中間表示層而非原始碼層進行這些變換——這也是為什麼最佳化的單位是抽象的「值流」而非你寫的那幾行 C++。