
C++ 入門與編譯:從原始碼到可執行檔
理解編譯式語言的世界觀——靜態型別、四階段編譯流水線,以及讓無數人困惑的 ODR
從一行 Hello, World 到真正在跑的機器碼
假設你要寫一個程式,計算一份兩百萬筆的成績資料的平均分。用 Python,你大概十行就寫完了;它能跑、夠快、夠好。但如果這是一個每秒要處理十萬筆封包的交易系統,或是一台記憶體只有 256 KB 的微控制器,或是一場以毫秒分勝負的程式競賽——這時候你需要的,是一種能讓你「貼著硬體寫程式、又不必放棄抽象」的語言。
這就是 C++ 登場的地方。
在開始之前,先講清楚這篇的定位:如果你已經讀過本專區的 Python 篇與計算機概論篇,那很好——我們不會把那些內容換個語法再講一次。這篇的重點是 C++ 到底跟你熟悉的語言「差在哪」:為什麼它要先編譯才能跑?為什麼它有指標、要自己管記憶體?為什麼一個看似多餘的 #include <iostream> 背後藏著整套編譯模型?理解這些差異,比背語法重要得多。
編譯式語言 vs 直譯式語言:先翻譯,還是邊跑邊翻譯?
Python 是直譯式(interpreted)的:你寫的 .py 檔交給直譯器(interpreter),它一邊讀、一邊轉成位元組碼、一邊執行。好處是改完馬上能跑、跨平台方便;代價是每次執行都要付出「即時翻譯」的開銷。
C++ 是編譯式(compiled)的:你寫的原始碼必須先經過編譯器(compiler)整批翻譯成目標機器的機器碼(machine code),產出一個可執行檔,之後執行的就是這個原生檔案,作業系統直接餵給 CPU。
打個比方:直譯像是現場口譯,講者每說一句,口譯員即時翻一句;編譯則像是先把整本書翻譯印刷成冊,之後讀者直接讀成品,不再需要譯者在場。
這個差異帶來幾個關鍵後果:
- 執行速度:C++ 程式跑的是針對該 CPU 最佳化過的原生指令,沒有執行期翻譯開銷,通常比同等的 Python 快上一兩個數量級。
- 錯誤時機:很多錯誤(型別不符、用了不存在的變數)在 編譯期(compile time) 就被擋下來,程式根本產生不出來;Python 則往往要等到 執行期(runtime) 跑到那一行才爆炸。
- 可攜性的代價:編譯產物綁定特定平台(作業系統+CPU 架構)。在你筆電上 build 出來的 Linux 執行檔,不能直接搬到 Windows 跑。原始碼可攜,但執行檔不可攜。
補充:C++ 也不是非黑即白。它支援靜態型別(static typing)——變數的型別在編譯期就固定。相較於 Python 的動態型別「執行到才知道這個變數現在是什麼」,靜態型別讓編譯器能在你按下執行前就抓出大量錯誤,這正是編譯式語言安全感的來源之一。
你的第一支 C++ 程式
廢話不多說,先把經典範例擺出來:
#include <iostream>
int main() {
std::cout << "Hello, World!" << std::endl;
return 0;
}
短短六行,每一行都有戲,我們逐一拆解。
#include <iostream>:把別人寫好的東西「貼」進來
#include 是一道前置處理器指令(preprocessor directive)。它在真正編譯之前,先把 <iostream> 這個標頭檔(header)的內容,整段「複製貼上」到你的檔案開頭。iostream 裡宣告了輸入輸出串流的工具,例如 std::cout(標準輸出)和 std::cin(標準輸入)。
相較於 Python 的 import——那是執行期載入一個模組物件——C++ 的 #include 是純粹的文字層級貼上,發生在編譯之前。這個區別在後面講「翻譯單元」時會變得很重要。
int main():程式的唯一入口
每個 C++ 程式都從 main 函式開始執行。它的回傳型別是 int(整數),這個整數會回傳給作業系統,作為結束代碼(exit code):
return 0;慣例上代表「成功結束」。- 非零值代表某種錯誤。
相較於 Python 的腳本「從上到下逐行跑」,C++ 沒有 main 就無從執行——它是死板但明確的單一入口。在 shell 裡你可以用 echo $?(Linux/macOS)查看上一個程式的 exit code,這在寫 shell script 串接時很實用。
std::cout << ...:輸出串流
std::cout 是標準輸出串流物件,<< 是「把右邊的東西送進串流」的運算子,可以鏈接:
std::cout << "答案是 " << 42 << ",結束。" << std::endl;
// 輸出:答案是 42,結束。
std::endl 換行並清空緩衝區(flush)。那個 std:: 是命名空間(namespace)前綴,表示 cout 住在標準函式庫的 std 名稱空間裡。初學常見的偷懶寫法是加一行 using namespace std; 把前綴省掉,但在實務與大型專案中不建議,因為它會把整個 std 倒進當前範圍,容易撞名。練習時用無妨,養成寫 std:: 的習慣更好。
g++ / clang:把原始碼變成可執行檔
寫完 hello.cpp,怎麼讓它跑起來?你需要一個編譯器。最常見的兩個是 g++(GNU 的 C++ 編譯器)和 clang++(LLVM 專案的編譯器)。兩者指令幾乎可互換:
g++ hello.cpp -o hello # 編譯,輸出名為 hello 的執行檔
./hello # 執行它
或者:
clang++ hello.cpp -o hello
./hello
幾個你早晚會用到的旗標(flag):
# 開啟最佳化(-O2 是常用等級)並指定 C++ 標準版本
g++ -std=c++17 -O2 hello.cpp -o hello
# 開啟「請把所有警告都告訴我」—— 強烈建議養成習慣
g++ -std=c++17 -Wall -Wextra hello.cpp -o hello
-Wall -Wextra 會讓編譯器嘮叨地提醒你各種可疑寫法。初學者常把警告當噪音忽略,但很多 bug 其實編譯器早就警告過你了。把警告當朋友,不要關掉它。
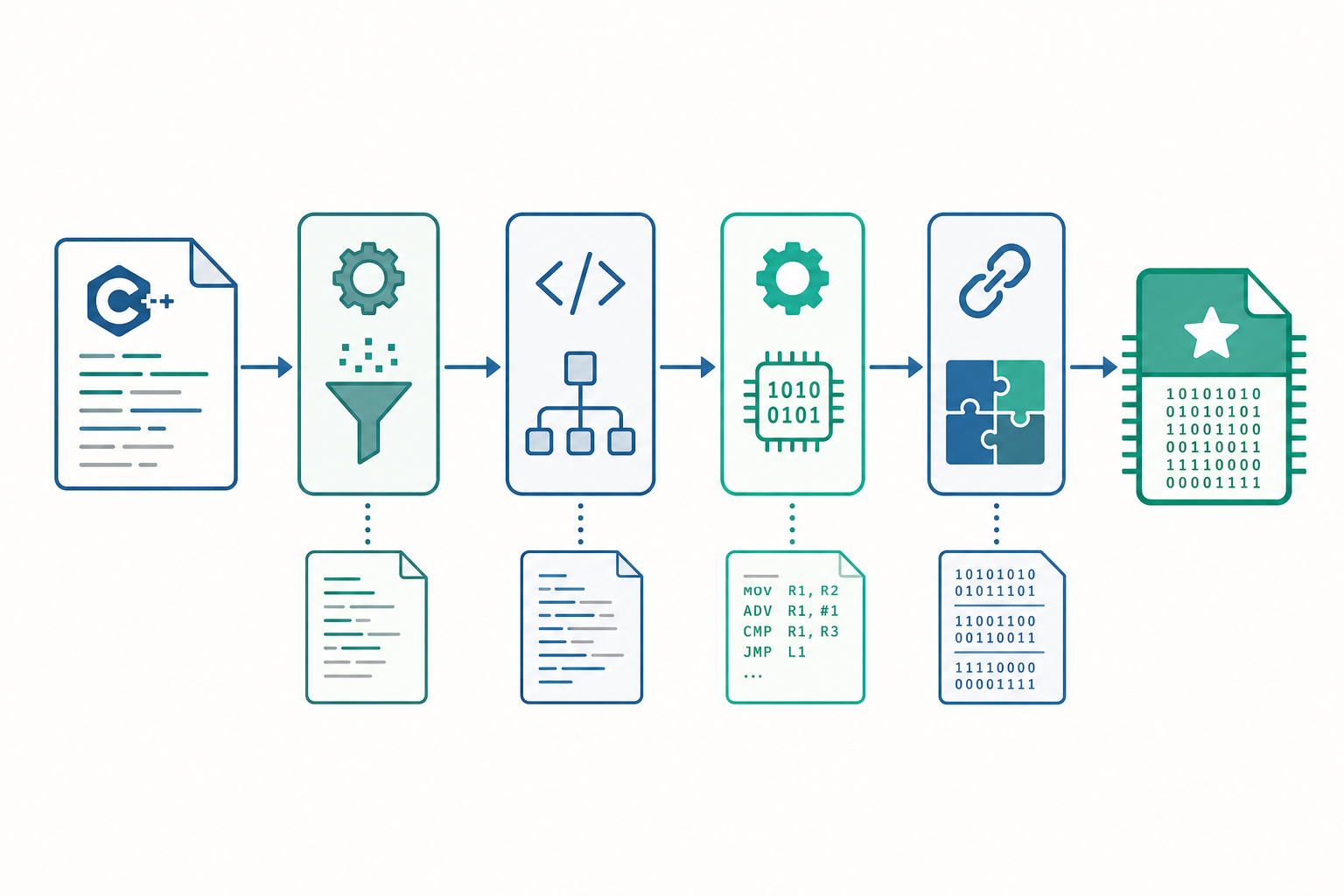
雖然我們上面一行就完成了編譯,但這背後其實藏著好幾個階段。把它想成一條流水線:原始碼 → 前置處理 → 編譯 → 組譯 → 連結 → 可執行檔。日常開發你不必每步手動執行,但理解這條線,能幫你看懂錯誤訊息到底發生在哪一站(後面的研究所視角會把每一站拆開講)。
動手寫一段:互動式 BMI 計算
光印 Hello World 太無聊。我們寫一支會讀使用者輸入、做點計算、輸出結果的小程式,順便認識 std::cin、變數宣告與型別:
#include <iostream>
int main() {
double height_m; // 身高(公尺),double 是雙精度浮點數
double weight_kg; // 體重(公斤)
std::cout << "請輸入身高(公尺):";
std::cin >> height_m;
std::cout << "請輸入體重(公斤):";
std::cin >> weight_kg;
double bmi = weight_kg / (height_m * height_m);
std::cout << "你的 BMI 是 " << bmi << std::endl;
if (bmi < 18.5) {
std::cout << "分類:體重過輕" << std::endl;
} else if (bmi < 24.0) {
std::cout << "分類:正常範圍" << std::endl;
} else {
std::cout << "分類:過重" << std::endl;
}
return 0;
}
編譯執行(假設輸入 1.75 和 70):
g++ -std=c++17 -Wall bmi.cpp -o bmi
./bmi
請輸入身高(公尺):1.75
請輸入體重(公斤):70
你的 BMI 是 22.8571
分類:正常範圍
注意幾個跟 Python 不同的地方:
- 每個變數都要先宣告型別:
double height_m;。double是雙精度浮點數,整數則用int。型別寫死了就不能中途變,這正是靜態型別。 std::cin >>讀輸入,方向跟cout的<<相反——資料「從串流流進變數」。- 每個敘述要分號
;結尾,區塊用大括號{}。C++ 不靠縮排決定範圍(縮排只是給人看的),這跟 Python 用縮排定義區塊是根本差異。
與 C 的淵源與差異:C++ 是「加了類別的 C」嗎?
C++ 由 Bjarne Stroustrup 在 1980 年代於貝爾實驗室發展,最初的名字就叫「C with Classes」(帶類別的 C)。它幾乎完整繼承了 C 的語法、型別系統與貼近硬體的能力——指標、手動記憶體管理、與作業系統直接打交道。也因此,大量的 C 程式碼可以幾乎原封不動在 C++ 編譯器下編譯。
但 C++ 早已遠遠不只是「C 加上類別」。它疊上了一整套現代特性:
// 這是 C++ 才有的:物件導向(類別)
class Circle {
public:
double radius;
double area() const { return 3.14159 * radius * radius; }
};
// 模板(template):寫一次,套用到任何型別
template <typename T>
T larger(T a, T b) {
return (a > b) ? a : b;
}
int main() {
Circle c{2.0};
std::cout << c.area() << std::endl; // 12.5664
std::cout << larger(3, 7) << std::endl; // 7
std::cout << larger(2.5, 1.1) << std::endl;// 2.5
return 0;
}
C 與 C++ 的主要差異可以這樣抓重點:
| 面向 | C | C++ |
|---|---|---|
| 程式典範 | 程序式為主 | 程序式+物件導向+泛型+函式式 |
| 抽象工具 | 結構(struct)、函式 | 類別、模板、運算子多載、例外處理 |
| 記憶體管理 | malloc/free |
new/delete、智慧指標(std::unique_ptr 等) |
| 標準函式庫 | 較精簡 | 龐大的 STL(容器、演算法、字串) |
值得一提的是 C++ 的設計哲學:零成本抽象(zero-overhead abstraction)——你用得到的抽象不該比你手寫的低階版本更慢,用不到的特性不該讓你付出代價。這是它跟其他高階語言最不一樣的承諾:你可以寫得很抽象、很優雅,卻不必為此犧牲效能。Python 的便利是用執行期開銷換來的;C++ 試圖讓你兩者兼得,代價是你得理解更多底層細節。
為什麼要學 C++?
既然 C++ 這麼囉嗦、要管型別又要管記憶體,為什麼還要學它?幾個現實理由:
- 效能(performance):當你需要榨乾硬體——遊戲引擎、即時影音編解碼、高頻交易、科學計算——C++ 是業界主力。它讓你能精細控制記憶體佈局與 CPU 行為。
- 系統程式(systems programming):作業系統、瀏覽器核心(如 Chrome 的 V8、Blink)、資料庫引擎(MySQL、MongoDB)、嵌入式與物聯網裝置,大量以 C/C++ 撰寫。要寫貼近硬體的東西,幾乎繞不開它。
- 程式競賽(competitive programming):ICPC、各類線上競賽中 C++ 是絕對主流。原因是它執行夠快(嚴格的時間限制下不容易 TLE),且 STL 提供現成的高效資料結構與演算法。
- 理解計算機本質:學 C++ 會逼你直面「記憶體到底長怎樣」「指標是什麼」「值傳遞與參考傳遞差在哪」——這些理解會回過頭來讓你寫任何語言都更清楚。
常見錯誤:初學者最常踩的雷
- 忘記分號
;:C++ 每個敘述以分號結尾。漏掉時編譯器常常把錯誤指到「下一行」,讓人摸不著頭緒。看到莫名其妙的語法錯誤,先檢查上一行少不少分號。 =和==搞混:if (x = 5)是「把 5 指派給 x 然後判斷」(永遠為真),if (x == 5)才是「判斷 x 是否等於 5」。-Wall通常會警告你這件事。- 使用未初始化的變數:
int n;之後沒給值就拿來用,n的內容是不確定的垃圾值(這跟 Python 會直接報NameError不同,C++ 可能照常跑出莫名其妙的結果)。宣告時就給初值:int n = 0;。 - 整數除法的陷阱:
int之間相除會無條件捨去小數,7 / 2得到3而不是3.5。要小數結果,至少一邊得是浮點數:7.0 / 2。 - 以為改完
.cpp就會自動生效:C++ 不是直譯式,改完原始碼一定要重新編譯,否則你跑的還是舊的執行檔。這是從 Python 過來最容易忘的一點。
深入探討(研究所視角)
到這裡你已經能寫、能編、能跑了。接下來把編譯這條流水線真正拆開,理解 C++ 程式從文字變成可執行檔的每一站,以及一個讓無數人困惑的核心規則:ODR。
編譯四階段:前置處理 → 編譯 → 組譯 → 連結
我們之前用 g++ hello.cpp -o hello 一鍵完成的事,內部其實是四個階段接力。你可以用旗標讓 g++ 停在每一站,親眼看中間產物:
# 1. 前置處理(preprocessing):展開 #include、巨集、#define
g++ -E hello.cpp -o hello.i # 產出純文字 .i,會發現它暴增到幾萬行
# 2. 編譯(compilation):把 C++ 翻成組合語言
g++ -S hello.i -o hello.s # 產出組合語言 .s
# 3. 組譯(assembly):組合語言 → 機器碼目的檔
g++ -c hello.s -o hello.o # 產出目的檔(object file).o,是二進位
# 4. 連結(linking):把多個 .o 與函式庫接起來成可執行檔
g++ hello.o -o hello # 產出最終可執行檔
各階段在做的事:
- 前置處理:處理所有
#開頭的指令。#include <iostream>在這一步被替換成iostream的完整內容——這就是為什麼前置處理後的檔案會爆炸性膨脹。 - 編譯:對單一檔案做語法分析、語意檢查、最佳化,翻成目標 CPU 的組合語言。型別錯誤、語法錯誤多半在這站被抓出。
- 組譯:組譯器把人類可讀的組合語言轉成二進位機器碼,包進目的檔(object file,
.o)。 - 連結:連結器(linker)把所有目的檔,加上用到的函式庫(例如
std::cout的實作),把符號(symbol)的「呼叫」和「定義」對接起來,產出最終可執行檔。
理解這條線的實際好處:你能讀懂錯誤訊息發生在哪一站。「error: expected ';'」是編譯期的語法錯誤;而「undefined reference to ...」這種令人崩潰的訊息,其實是連結期錯誤——某個函式你宣告了、呼叫了,卻沒有任何地方提供它的定義,連結器找不到對接對象。知道它是連結錯誤,你才會往「是不是漏 link 某個 .o 或函式庫」的方向查,而不是死盯著語法。
標頭檔與翻譯單元(translation unit)
這裡是 C++ 編譯模型最關鍵、也最容易混淆的概念。
翻譯單元(translation unit)指的是:一個 .cpp 原始檔,加上它透過 #include 拉進來的所有標頭內容,經過前置處理之後,所形成的那一整份文字。編譯器是以翻譯單元為單位、各自獨立進行編譯的——它一次只看一個翻譯單元,對其他 .cpp 檔的存在一無所知。
這解釋了 C++ 的一個核心慣例:宣告(declaration)放標頭,定義(definition)放原始檔。
// math_utils.h —— 標頭:只放「宣告」,告訴別人「有這個東西、長這樣」
#ifndef MATH_UTILS_H
#define MATH_UTILS_H
int add(int a, int b); // 宣告:有 add 這個函式,但這裡不寫它怎麼做
#endif
// math_utils.cpp —— 原始檔:放「定義」,實際寫出它怎麼做
#include "math_utils.h"
int add(int a, int b) {
return a + b;
}
// main.cpp —— 使用者只 include 標頭,就能呼叫 add
#include <iostream>
#include "math_utils.h"
int main() {
std::cout << add(3, 4) << std::endl; // 輸出:7
return 0;
}
編譯時各自編成目的檔,再由連結器接起來:
g++ -c math_utils.cpp -o math_utils.o
g++ -c main.cpp -o main.o
g++ math_utils.o main.o -o app # 連結器把 main 裡的 add 呼叫,接到 math_utils 的定義
main.cpp 編譯時只看到 add 的宣告就夠了——它知道「有這個函式、參數與回傳型別長這樣」,足以產生呼叫的程式碼。至於 add 的定義在哪?那是連結器的工作。這種「宣告與定義分離、翻譯單元獨立編譯、最後連結整合」的模型,是 C++(與 C)跟 Python「執行期動態載入模組」截然不同的世界觀。
那段 #ifndef / #define / #endif 叫 include guard(標頭防護),作用是防止同一個標頭在一個翻譯單元裡被重複展開。若 A 與 B 兩個標頭都 include 了 C,而你的 .cpp 又同時 include A 與 B,沒有防護就會讓 C 的內容出現兩次,造成重定義錯誤。現代寫法也常用一行 #pragma once 達到同樣效果。
ODR:單一定義規則(One Definition Rule)
最後是把上面一切綁在一起的規則——ODR(One Definition Rule,單一定義規則)。粗略地說,它規定:
- 每個函式、每個變數、每個型別,在整個程式中,有定義的話只能有一個定義。
- 但宣告可以出現任意多次(這正是標頭被多個檔案 include 的合法性來源)。
ODR 是上面那套「宣告放標頭、定義放原始檔」慣例背後的法理。想想看:標頭會被 include 到許多翻譯單元,如果你把一個函式的定義(含函式本體)直接寫進標頭,那麼每個 include 它的 .cpp 都會各自產生一份定義——連結器看到同名函式有好幾份定義,就會丟出「multiple definition / 重定義」錯誤,違反 ODR。
這也是為什麼許多 C++ bug 長得很玄:
- 「undefined reference」=你宣告並使用了某符號,但全程式中沒有任何一處定義它。對 ODR 來說是「定義數為 0」。
- 「multiple definition」=同一個符號被定義了兩次以上。對 ODR 來說是「定義數 > 1」。
兩種錯誤,恰好對應 ODR「有且只有一個定義」這把尺的兩端。
ODR 也有微妙的例外:
inline函式、模板(template)、class的定義允許出現在多個翻譯單元,前提是每一份的內容必須逐字相同。這正是為什麼模板與類別定義通常整個放在標頭裡也不會違反 ODR——它們被刻意豁免,但代價是你得保證所有翻譯單元看到的版本完全一致。
把這三層串起來看:前置處理決定每個翻譯單元最終看到哪些文字,翻譯單元獨立編譯讓大型專案能分檔、平行、增量編譯,ODR + 連結則保證這些獨立編譯出來的碎片,最後能正確且唯一地拼成一個完整程式。理解這套模型,你就握住了 C++ 工程的骨架——無論之後要除錯連結問題、設計函式庫介面,還是搞懂為何某個改動要重編整個專案,都從這裡出發。