
雲端運算(進階):無伺服器、排隊理論與一致性光譜
從冷啟動的微型 VM、用排隊理論精算容量,到把自動擴展看成控制問題——深入雲端工程那些「沒有免費午餐」的取捨。
如果租一台機器要付一整小時,為什麼有人能做到「沒人用就一毛錢都不收」?
入門篇裡,我們把雲端想成「需要時打開水龍頭、用多少算多少」。但這個比喻其實偷偷藏了一個漏洞:傳統雲端虛擬機(virtual machine, VM)再怎麼彈性,你開了一台機器、就算整晚只進來三個請求,那台機器仍然整晚醒著、整晚計費。它像一間你包下的房間——空著也要付租金。
真正把「用多少算多少」推到極致的,是一種叫無伺服器運算(serverless computing)的模型:你只上傳一個函式,平台幫你在「有請求進來的那一刻」才生出執行環境,跑完幾百毫秒就拆掉,閒置時刻不計費。這聽起來幾乎違反物理——機器不可能瞬間生出來。這篇進階文章要回答的,正是這類「看似不可能」背後的工程機制:無伺服器的冷啟動(cold start)代價、用排隊理論(queueing theory)精算雲端容量、一致性其實是一道連續光譜、以及自動擴展為何本質上是一個控制問題。我們假設你已經讀過入門篇,熟悉 IaaS/PaaS/SaaS、虛擬化、容器、彈性擴展與 CAP 定理。
無伺服器運算:把「分配資源」延遲到最後一刻
無伺服器(更精確的子類別叫函式即服務,Function as a Service, FaaS,如 AWS Lambda、Google Cloud Functions)的核心承諾是兩件事:按請求計費(pay-per-invocation) 與 自動縮放到零(scale to zero)。後者尤其關鍵——當沒有請求時,系統真的不保留任何執行中的實例,因此你不付任何錢。
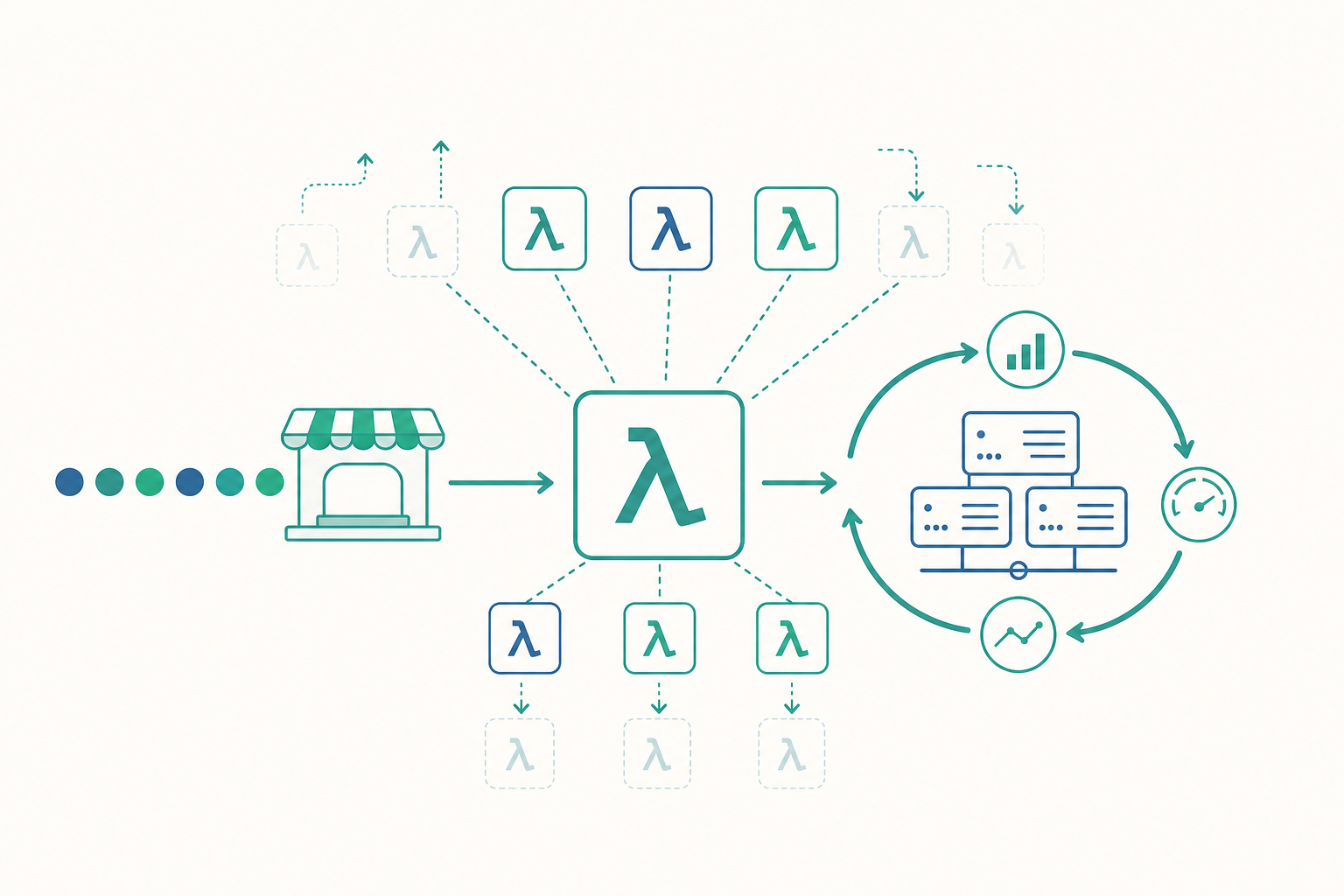
這跟入門篇的水平擴展(scale out)有什麼不同?水平擴展通常是「最少保留 N 台、最多開到 M 台」,下限 N 往往大於零,因為你不想讓第一個使用者等機器開機。無伺服器則把這個下限打到零,代價轉嫁成另一個問題:第一個請求進來時,環境是空的,必須現生。
平台的做法是把你的程式碼預先打包成映像,當請求抵達時:配置一個沙箱(通常是輕量級 VM 或容器)、載入執行環境、把你的程式碼拉進去初始化、最後才真正執行你的函式。這整段「從無到能服務」的時間就是冷啟動延遲(cold start latency)。一旦實例生出來,平台會讓它「保溫」一小段時間(幾分鐘),這段期間進來的後續請求直接重用同一個已暖的實例,幾乎零延遲——這叫熱啟動(warm start)。
請求 1(冷): [配置沙箱 200ms][載入執行環境 150ms][初始化程式 100ms][執行 30ms] = 480ms
請求 2(熱): [執行 30ms] = 30ms
... 閒置數分鐘無請求 ...
請求 N(又冷):[配置沙箱 200ms][載入執行環境 150ms][初始化程式 100ms][執行 30ms] = 480ms
你可以看到冷啟動的代價幾乎全來自「執行你的程式碼之前的準備工作」。這也解釋了無伺服器的兩條黃金守則:把函式做小、把初始化做輕。一個載入了 200MB 機器學習函式庫的函式,光是冷啟動就可能拖到好幾秒;而一個純粹處理 JSON 的小函式,冷啟動可能只有兩三百毫秒。
看一個例子:把昂貴的初始化搬出函式主體
無伺服器平台對同一個暖實例會重複呼叫你的處理函式(handler)。聰明的寫法是把昂貴、且每次都一樣的初始化放在 handler 之外,讓它只在冷啟動時跑一次,後續熱呼叫直接重用:
import json
# === 這段在「冷啟動」時執行一次,之後的熱呼叫會重用 ===
# 假設這是昂貴的初始化:建立資料庫連線池、載入模型權重等
EXPENSIVE_CLIENT = create_db_pool() # 只在實例第一次生出來時跑
def handler(event, context):
# === 這段每次請求都會跑 ===
# 直接重用上面已建好的連線,不必每次重連
user_id = event["user_id"]
row = EXPENSIVE_CLIENT.query("SELECT name FROM users WHERE id = %s", (user_id,))
return {"statusCode": 200, "body": json.dumps({"name": row["name"]})}
如果你把 create_db_pool() 寫進 handler 內部,那麼每一次請求都要重建連線池——熱啟動的優勢就被你親手抹掉了。理解「冷啟動只發生一次、熱啟動重用實例」這個生命週期,是寫好無伺服器函式的關鍵心智模型。
值得澄清一個常見迷思:「無伺服器」不是真的沒有伺服器。伺服器當然還在,只是「機器的存在與生命週期」這件事完全被平台接管、對你隱形。你被計費的單位從「機器開機的時間」變成了「函式執行的時間(精確到毫秒)乘上配置的記憶體」。
用排隊理論精算容量:到底要開幾台機器?
入門篇說「流量上升就自動多開機器」,但多開幾台才夠?少開一台,使用者排隊等到天荒地老;多開十台,錢白白燒掉。這不是憑感覺,而是有數學可算的——這個工具叫排隊理論(queueing theory)。
把一台伺服器想成餐廳的一個服務窗口,請求是排隊的客人。我們用兩個參數描述系統:
- $\lambda$(lambda):請求到達率,每秒平均來幾個請求。
- $\mu$(mu):單台機器的服務率,每秒平均能處理完幾個請求。
定義使用率(utilization) $\rho = \lambda / (c\mu)$,其中 $c$ 是機器台數。直覺上 $\rho$ 是「窗口有多忙」:$\rho = 0.5$ 表示半閒,$\rho = 0.95$ 表示快忙爆。系統穩定的必要條件是 $\rho < 1$——否則請求進來的速度永遠快過處理速度,佇列會無限長大。
關鍵且反直覺的結果是:等待時間不是隨使用率線性上升,而是在接近滿載時急速爆炸。對最簡單的 M/M/1 模型(單一窗口、隨機到達、隨機服務時間),系統內平均花費的時間為:
$$ W = \frac{1}{\mu - \lambda} = \frac{1}{\mu (1 - \rho)} $$
注意那個 $(1 - \rho)$ 在分母。當 $\rho$ 從 0.8 升到 0.9、再升到 0.99,分母從 0.2 縮到 0.1、再縮到 0.01——延遲被放大 2 倍、再 10 倍。這就是為什麼有經驗的雲端工程師不會把機器跑到 100% 使用率,通常刻意留 30%~40% 的餘裕(headroom),因為最後那一點點使用率,買來的是延遲的雪崩。
動手算一下:留多少餘裕才划算
假設你的單台機器每秒能服務 $\mu = 100$ 個請求,現在尖峰到達率 $\lambda = 80$ 個/秒。
只開一台($c = 1$):
$$ \rho = \frac{80}{1 \times 100} = 0.8, \quad W = \frac{1}{100 \times (1 - 0.8)} = \frac{1}{20} = 0.05 \text{ 秒} = 50 \text{ ms} $$
開兩台(用負載平衡器分流,近似把總服務率變兩倍,$c = 2$):
$$ \rho = \frac{80}{2 \times 100} = 0.4 $$
使用率掉到 0.4,請求幾乎不必排隊,平均延遲趨近於單純的服務時間。差別在於:第一種設定下,只要尖峰再多 20%($\lambda$ 升到 96),$\rho$ 就衝到 0.96、延遲變成 $1 / (100 \times 0.04) = 250$ ms,是原本的 5 倍;第二種設定面對同樣的尖峰仍從容。
這就是容量規劃的核心張力:多開機器買到的是「對尖峰的免疫力」,但代價是平時的閒置成本。無伺服器之所以誘人,正是因為它讓 $c$ 隨 $\lambda$ 即時變動,理論上永遠維持低使用率又不付閒置費——當然,前提是你願意吞下冷啟動的延遲。
順帶一提,排隊理論還給了我們一條極簡卻極有用的公式——Little 法則(Little's Law):$L = \lambda W$,系統內平均請求數 $L$ 等於到達率乘上平均停留時間。它幾乎不需要任何假設就成立,是估算「同時在飛的請求數」的利器。
一致性是一道光譜,不是開關
入門篇用 CAP 定理把選擇簡化成「CP 或 AP」二選一,這是很好的起點,但真實世界的一致性遠不只兩格。它是一條從強到弱的連續光譜,每多放鬆一點一致性,通常就能換來更低的延遲或更高的可用性。
| 一致性模型 | 保證 | 代價/好處 |
|---|---|---|
| 線性一致(linearizable) | 所有人看到的操作順序,跟真實時間順序一致;讀一定拿到最新寫入 | 最強,但延遲最高 |
| 順序一致(sequential) | 存在某個全域順序,所有人都同意;但不必對齊真實時間 | 略弱 |
| 因果一致(causal) | 有因果關係的操作,所有人看到的先後一致;無關操作可亂序 | 兼顧可用性與直覺合理 |
| 最終一致(eventual) | 停止寫入後,所有複本終會收斂到同一值 | 最弱,但最快、最可用 |
舉個生活化的例子說明為什麼「因果一致」常常剛好夠用:你在社群貼文說「我家貓走失了」,五分鐘後又補一則「找到了!」。因果一致保證任何看到第二則的人,一定也看得到第一則——因為它們有因果關聯。但它不保證你朋友 A 和朋友 B 看到貼文的絕對時刻一致(那是線性一致才管的事)。對社群軟體來說,這種保證剛好:荒謬的「找到了!但看不到走失那則」不會發生,而系統又不必付線性一致的高昂協調成本。
看一個例子:向量時鐘如何追蹤因果
要實現因果一致,系統得有辦法判斷兩個事件「誰因誰果、還是根本無關」。一個經典工具是向量時鐘(vector clock):每個節點維護一個計數器陣列,記錄它所知道的每個節點各做了幾次更新。
三個節點 A、B、C,向量時鐘格式為 [A, B, C]
A 本地更新: A = [1, 0, 0]
A 把訊息傳給 B,
B 收到後本地再更新: B = [1, 1, 0] ← B 知道「A 的第1次」發生在自己之前
同時間 C 獨立更新: C = [0, 0, 1] ← C 完全不知道 A、B 發生了什麼
比較兩個向量時鐘就能判斷因果:若 B = [1,1,0] 的每一格都 ≥ A = [1,0,0],代表 A「發生在 B 之前」(happens-before),是因果先行;而 B = [1,1,0] 與 C = [0,0,1] 互相都不全大於對方,代表它們並行(concurrent)、沒有因果關係——系統可以自由決定它們的呈現順序,或在衝突時交給應用層解決。這套「happens-before 偏序關係」由 Leslie Lamport 在 1978 年奠定,是分散式系統推理時間的理論基石。
自動擴展其實是一個控制問題
入門篇說「流量上升就自動多開、退去就關掉」,聽起來簡單,但實作起來其實是一個回授控制(feedback control) 問題,跟冷氣機維持室溫、汽車定速巡航是同一類數學。
自動擴展器(autoscaler)持續觀測一個指標(如平均 CPU 使用率),跟一個目標值(target) 比較,再決定加幾台或減幾台。最樸素的策略長這樣:
def decide_replicas(current_replicas, current_metric, target_metric):
"""根據當前指標與目標的比值,算出期望的機器數。
這正是 Kubernetes HPA 的核心公式之雛形。"""
# 比值 > 1 表示太忙、要加機器;< 1 表示太閒、可減機器
desired = current_replicas * (current_metric / target_metric)
import math
return max(1, math.ceil(desired))
# 例:現在 4 台,平均 CPU 90%,目標 60%
print(decide_replicas(4, 90, 60)) # → ceil(4 * 1.5) = 6 台
問題在於:控制系統最怕震盪(oscillation)。想像自動擴展器看到 CPU 飆高就猛開機器,新機器上線後負載驟降,它又看到太閒就猛關機器,結果負載又升高……系統在「太多」與「太少」之間來回擺盪,永遠不穩定。這跟一個太敏感的恆溫器把房間一下烤太熱、一下凍太冷是同樣的毛病。
實務上的解法都是控制理論的常見手段:
- 冷卻期(cooldown / stabilization window):剛調整完先觀望一段時間,不要連續暴衝——等同於給系統加上阻尼(damping)。
- 遲滯(hysteresis):擴張的門檻和收縮的門檻刻意設不一樣(例如 CPU > 70% 才加、< 40% 才減),中間留一段「不動作」的死區,避免在門檻邊緣抖動。
- 預測式擴展(predictive scaling):不只看當下,還用歷史規律預測(例如每天早上九點必有尖峰),提前把機器開好——這正好也能掩蓋無伺服器的冷啟動延遲。
把自動擴展看成控制問題,你就會明白為什麼它「調得太靈敏反而更糟」——這是反應式系統的通病,而非雲端獨有。
重點回顧
- 無伺服器/FaaS 把資源分配延遲到請求抵達的瞬間,達成「縮放到零、按請求計費」;代價是冷啟動延遲,因此函式要小、初始化要輕,並善用熱實例重用。
- 排隊理論告訴我們延遲在使用率接近 1 時急速爆炸(分母含 $1-\rho$),所以要刻意留餘裕、不把機器跑滿;Little 法則 $L=\lambda W$ 是估算負載的利器。
- 一致性是連續光譜:線性 → 順序 → 因果 → 最終,越弱越快越可用;因果一致搭配向量時鐘常是兼顧合理性與效能的甜蜜點。
- 自動擴展是回授控制問題,最大敵人是震盪;用冷卻期、遲滯、預測式擴展等阻尼手段穩定它。
- 這些主題共同的精神:雲端工程處處是取捨,沒有免費的午餐——延遲、成本、一致性、可用性之間永遠在拉鋸。
深入探討(研究所視角)
冷啟動的微型 VM 軍備競賽
無伺服器要同時做到「強隔離(多租戶安全)」與「毫秒級啟動」,這兩個目標本來互相矛盾——入門篇提過 VM 隔離強但開機慢、容器啟動快但隔離薄。業界的突破是專為無伺服器設計的微型虛擬機(microVM),代表作是 AWS 的 Firecracker。
Firecracker 用 Rust 寫成,刻意只實作極少數虛擬裝置(網路、區塊裝置、序列埠等),把虛擬機監控器(VMM)的程式碼量壓到最小,因此攻擊面小、開機快——啟動一個微型 VM 只要約 125 毫秒,記憶體開銷低到一台實體機能塞下數千個。它讓無伺服器同時拿到「VM 級的硬體隔離」與「接近容器的啟動速度」,是入門篇「隔離強度 ⟷ 資源效率 ⟷ 啟動延遲」三角權衡被工程巧思往外推的活教材。
更進階的技巧是快照與還原(snapshot/restore):把一個已經初始化完成的 VM 整個記憶體狀態存成快照,下次冷啟動時直接「還原」這份快照,跳過所有初始化。研究系統如 Catalyzer、以及 AWS Lambda 的 SnapStart 走的正是這條路,把冷啟動再壓低一個數量級。不過快照帶來新的安全課題:若快照裡含有加密用的隨機種子,多個實例從同一份快照還原會共用同一個「隨機」狀態,可能危及密碼學安全——這是系統與安全交會處的活躍研究領域。
為什麼線性一致這麼貴:共識的下界
為什麼強一致性「貴」?因為要讓多個複本對「最新值是什麼」達成一致,它們必須跑一輪共識協定(consensus protocol),如 Paxos 或 Raft。共識的本質是:在可能有節點故障、訊息延遲的環境下,讓所有人同意同一個值。
這裡有個著名的理論天花板——FLP 不可能性(FLP impossibility,Fischer–Lynch–Paterson, 1985):在完全非同步的網路裡(訊息延遲無上限),只要有一個節點可能故障,就不存在一個總能在有限時間內達成共識的確定性演算法。這聽起來像在說共識根本做不到,但實務系統靠引入「部分同步」假設與逾時(timeout) 機制繞過它——本質上是用「可用性的概率」換取「進展的保證」。
從成本看,一輪共識通常需要跨節點的多次訊息往返(round trips),每一趟都吃網路延遲。若複本分散在跨洲的資料中心,光速就成了硬性下限:台灣到美西的單程光纖延遲就有約 70~100 毫秒,一輪共識動輒數百毫秒。這正是 PACELC 定理裡「即使沒有分區,強一致也要付延遲代價」的物理根源——不是工程不夠努力,是光速與資訊理論的下界擋在那裡。理解這一層,你就能看穿許多「全球強一致資料庫」行銷話術背後真正的取捨:它們要嘛限制你的寫入地理範圍、要嘛用特製硬體(如 Google Spanner 的 TrueTime 原子鐘)把不確定性壓到極小,沒有人能真正繞過物理。
與其他主題的連結
這篇進階文章把雲端再往三個經典領域深掘:作業系統的虛擬化與排程,在 microVM 與快照還原中被推到極限;機率與排隊論直接決定了容量規劃與成本模型;分散式演算法的共識與邏輯時鐘,劃定了一致性能走多強的理論邊界。把這些拼起來會浮現一個統一的世界觀——雲端工程的每一個設計決策,最終都落在「延遲、成本、一致性、可用性、安全」這個高維權衡空間裡的某一點,而工程師的任務,就是為手上的應用找到那個最合適的座標。