
C++ 模板與 STL:零成本的泛型程式
從一個「取較大值」的函數出發,理解函數模板、類別模板與 STL 三大件,並看清 C++ 為何能在編譯期把抽象抹平成零開銷的機器碼。
一個函數,吃下所有型別
假設你要寫一個「取兩者之大」的函數。在 C++ 裡,型別必須在編譯時就講清楚,所以最直覺的寫法是:
int max_int(int a, int b) {
return a > b ? a : b;
}
很好,但它只吃 int。換成 double 呢?再寫一個 max_double。換成 std::string?再寫一個。每個型別都要複製貼上一份幾乎一模一樣的程式碼——邏輯完全相同,只有型別在變。
相較於 Python,你大概會覺得這很荒謬。Python 的 def my_max(a, b): return a if a > b else b 一個函數就什麼都能比,因為 Python 是動態型別,型別檢查推遲到執行期。但 C++ 是靜態型別:每個變數的型別在編譯時就確定,編譯器要知道 > 該怎麼比、要產生哪段機器碼。這正是 C++ 快的原因,也是它「囉嗦」的原因。
C++ 的解法不是放棄型別檢查,而是讓你寫一份「模板(template)」,由編譯器在編譯期幫你把每個型別的版本各生成一份。這就是模板與泛型程式(generic programming)的核心,也是整個標準模板庫(STL,Standard Template Library)的地基。
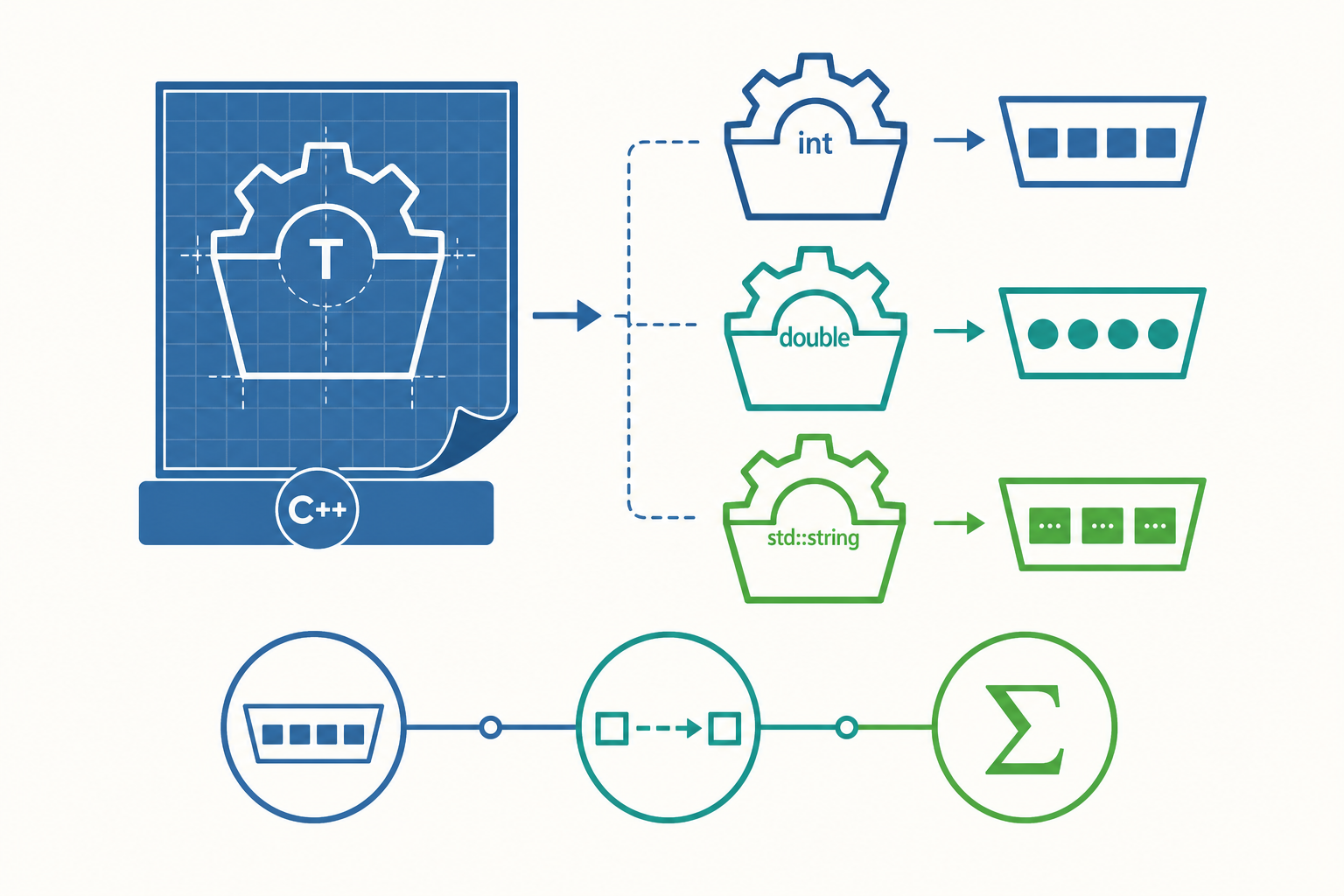
函數模板:寫一份,生成多份
把上面的 max 改寫成模板:
#include <iostream>
#include <string>
template <typename T>
T my_max(T a, T b) {
return a > b ? a : b;
}
int main() {
std::cout << my_max(3, 7) << '\n'; // T = int
std::cout << my_max(2.5, 1.1) << '\n'; // T = double
std::cout << my_max(std::string("apple"),
std::string("banana")) << '\n'; // T = std::string
return 0;
}
// 輸出:
// 7
// 2.5
// banana
template <typename T> 宣告了一個型別參數 T,它是個占位符。當你呼叫 my_max(3, 7) 時,編譯器看到引數是 int,就把 T 推導為 int,生成一份 int my_max(int, int)。呼叫 my_max(2.5, 1.1) 時又生成一份 double 版本。這個「把模板套上具體型別、生成實際程式碼」的過程叫模板實例化(template instantiation)。
關鍵理解:模板本身不是程式碼,是「生成程式碼的配方」。沒被呼叫到的型別版本不會被生成。std::string 那行之所以能跑,是因為 std::string 有定義 >(字典序比較)。如果 T 是某個沒有 > 運算子的型別,編譯會直接失敗——而且是在編譯期就失敗,不是執行期才爆。這跟 Python 很不同:Python 要等到那行真的執行到、> 真的算不出來才丟 TypeError。
不要這樣寫:用巨集模擬泛型
C 語言時代沒有模板,有人用前處理器巨集硬湊:
#define MAX(a, b) ((a) > (b) ? (a) : (b)) // 反模式
這是反模式。巨集只是純文字替換,不懂型別、不做型別檢查,遇到 MAX(i++, j++) 會把 i++ 算兩次,產生隱晦的 bug。模板有完整的型別系統撐腰,永遠優先用模板而非巨集。
類別模板:泛型的資料結構
不只函數可以泛型,類別也可以。STL 的容器(如 std::vector)全都是類別模板。我們手寫一個極簡版「固定容量堆疊」來體會:
#include <iostream>
#include <stdexcept>
template <typename T, int Capacity = 16>
class Stack {
T data_[Capacity];
int size_ = 0;
public:
void push(const T& value) {
if (size_ >= Capacity) throw std::overflow_error("stack full");
data_[size_++] = value;
}
T pop() {
if (size_ == 0) throw std::underflow_error("stack empty");
return data_[--size_];
}
bool empty() const { return size_ == 0; }
int size() const { return size_; }
};
int main() {
Stack<int> s; // T = int, Capacity = 16(用預設)
s.push(10);
s.push(20);
std::cout << s.pop() << '\n'; // 20
std::cout << s.size() << '\n'; // 1
Stack<std::string, 2> names; // T = string, Capacity = 2
names.push("Ada");
names.push("Linus");
std::cout << names.pop() << '\n'; // Linus
return 0;
}
// 輸出:
// 20
// 1
// Linus
注意兩件事。第一,類別模板的型別參數要明確寫出來:Stack<int>,不像函數模板能從引數推導(C++17 起類別模板也支援部分推導,但慣例上仍常明寫)。第二,模板參數不一定是型別——int Capacity = 16 是個非型別模板參數(non-type template parameter),它是個編譯期常數。Stack<int> 和 Stack<int, 32> 是兩個完全不同的型別,各自生成獨立的程式碼。
這也點出 C++ 的另一個語言特色:T data_[Capacity] 是一塊直接內嵌在物件裡的陣列,沒有任何堆積(heap)配置、沒有指標跳轉。相較於 Python 的 list 永遠是一堆指標指向散落各處的物件,C++ 讓你能精準掌控記憶體佈局,這對效能與快取友善度至關重要。
STL 三大件:容器、迭代器、演算法
STL 的設計哲學非常優雅,把資料與操作正交拆開成三塊:
- 容器(container):存資料的結構。
std::vector(動態陣列)、std::list(雙向鏈結串列)、std::map(紅黑樹)、std::unordered_map(雜湊表)等。 - 迭代器(iterator):指向容器中元素的「廣義指標」,是容器與演算法之間的橋樑。
- 演算法(algorithm):操作資料的泛型函數,如
std::sort、std::find,定義在<algorithm>。
精妙之處在於:演算法不直接認識容器,只透過迭代器操作。所以同一個 std::sort 能排序 vector、array、甚至 C 風格陣列——只要它們提供合格的迭代器。這就是泛型程式的威力:寫一次演算法,套用所有相容的資料結構。
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {5, 2, 8, 1, 9, 3};
std::sort(v.begin(), v.end()); // 升冪排序,平均 O(n log n)
for (int x : v) std::cout << x << ' ';
std::cout << '\n';
// 二分搜尋(要求已排序)
bool found = std::binary_search(v.begin(), v.end(), 8);
std::cout << "8 found? " << found << '\n';
// 線性搜尋(不要求排序),回傳迭代器
auto it = std::find(v.begin(), v.end(), 9);
if (it != v.end()) {
std::cout << "9 at index " << (it - v.begin()) << '\n';
}
return 0;
}
// 輸出:
// 1 2 3 5 8 9
// 8 found? 1
// 9 at index 4
幾個值得記住的點:
v.begin() 指向第一個元素,v.end() 指向「最後一個元素的下一個位置」——這是個哨兵,不指向有效元素。所有 STL 區間都是半開區間 [begin, end),所以 find 找不到時回傳的就是 end(),你用 it != v.end() 判斷成敗。
std::find 是線性掃描,複雜度 $O(n)$;std::binary_search 是二分搜尋,$O(\log n)$,但前提是資料已排序。std::sort 用的是內省排序(introsort),平均 $O(n \log n)$。
it - v.begin() 能算出索引,是因為 vector 的迭代器是隨機存取迭代器,支援指標式算術。換成 std::list 的迭代器就不行了——list 是鏈結串列,只能一步步走,不能跳。這種「迭代器能力分級」正是 STL 用編譯期型別系統表達演算法需求的方式。
自訂排序:傳入比較函數
std::sort 的第三個參數可以傳一個「比較函式物件」,自訂排序規則。最常用 lambda 表達式:
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
struct Student {
std::string name;
int score;
};
int main() {
std::vector<Student> roster = {
{"Mei", 88}, {"Jun", 95}, {"Wei", 88}, {"Lin", 72}
};
// 依分數降冪;同分時依名字字典序升冪
std::sort(roster.begin(), roster.end(),
[](const Student& a, const Student& b) {
if (a.score != b.score) return a.score > b.score;
return a.name < b.name;
});
for (const auto& s : roster)
std::cout << s.name << ' ' << s.score << '\n';
return 0;
}
// 輸出:
// Jun 95
// Mei 88
// Wei 88
// Lin 72
那個 [](...){...} 就是 lambda,是個匿名函式物件。std::sort 是模板,它的比較器型別也是模板參數,所以你傳任何「可被當成 (a, b) -> bool 呼叫」的東西都行——lambda、函數指標、或自訂的 functor。比較器只需保證回傳「a 是否應排在 b 前面」這個嚴格弱序關係,不必回傳 int(不像 C 的 qsort)。
動手寫一段:用 STL 做詞頻統計
把容器、迭代器、演算法串起來,做一個完整的小工具:統計一段文字裡每個單字出現幾次,並依「次數多→少、同次數字典序」輸出前幾名。
#include <iostream>
#include <sstream>
#include <string>
#include <vector>
#include <map>
#include <algorithm>
int main() {
std::string text =
"the cat sat on the mat the cat ran";
// 1) 容器:用 map 自動依 key 排序累計次數
std::map<std::string, int> freq;
std::istringstream iss(text);
std::string word;
while (iss >> word) {
freq[word]++; // 不存在時 value 自動初始化為 0
}
// 2) 搬進 vector 以便依「次數」重排
std::vector<std::pair<std::string, int>> items(freq.begin(), freq.end());
// 3) 演算法:依次數降冪,同次數依單字升冪
std::sort(items.begin(), items.end(),
[](const auto& a, const auto& b) {
if (a.second != b.second) return a.second > b.second;
return a.first < b.first;
});
// 4) 輸出前 3 名
int shown = 0;
for (const auto& [w, c] : items) {
std::cout << w << ": " << c << '\n';
if (++shown == 3) break;
}
return 0;
}
// 輸出:
// the: 3
// cat: 2
// mat: 1
這段示範了 STL 的典型工作流:用合適的容器收集資料(map 自動去重累計),需要不同視角時搬到另一種容器(vector),再用泛型演算法處理。freq[word]++ 利用了 map 的 operator[]:鍵不存在時會自動插入並把值初始化為 0,這是 C++ 的慣用語。for (const auto& [w, c] : items) 用了結構化綁定(structured binding,C++17),直接把 pair 拆成兩個名字,可讀性很好。
重點回顧
整理幾個初學者最常踩的雷:
-
模板定義要放在標頭檔。 模板不是普通函數,編譯器要在「實例化的當下」看得到完整定義才能生成程式碼。把模板宣告放
.h、定義放.cpp是新手最常見的連結錯誤(linker error)來源。模板請整份寫在標頭檔。 -
end()不指向有效元素。 它是「結尾後一格」的哨兵。*v.end()是未定義行為。判斷搜尋失敗永遠用it != container.end(),不要試圖解參考end()。 -
std::binary_search、std::lower_bound要求資料先排序。 對未排序的vector用二分搜尋,結果是錯的而且編譯器不會警告你。要嘛先sort,要嘛改用線性的std::find。 -
別把模板實例化爆炸不當回事。
vector<int>和vector<double>是兩份獨立程式碼。型別組合太多時,二進位檔會膨脹(code bloat),編譯也會變慢。這是零成本抽象的代價之一。 -
模板錯誤訊息又臭又長。 一個型別不符的小錯,編譯器可能吐出數百行訊息。學會從第一行的
error:往下看、找到你自己的程式碼那一行,不要被淹沒。C++20 的 concepts(見下節)正是為了改善這件事。
深入探討(研究所視角)
模板實例化與編譯期多型
回到那個核心問題:為什麼泛型在 C++ 是零成本的?
關鍵在於模板實例化發生在編譯期。當編譯器看到 my_max(3, 7),它生成的不是「一個能處理任意型別的通用函數」,而是一份專為 int 量身打造、寫死了 int 比較指令的機器碼。這份程式碼跟你手寫的 max_int 一模一樣快——沒有型別查詢、沒有裝箱拆箱、沒有間接跳轉。抽象在編譯後完全消失了,這就是零成本抽象(zero-cost abstraction)的字面意義:你用了高階泛型,但執行期一分錢額外開銷都不付。
這要對比兩種「多型」:
- 執行期多型(runtime polymorphism):透過虛擬函數(virtual function)與繼承實現。物件帶一個 vtable 指標,呼叫時在執行期查表決定跳哪。靈活,但每次呼叫付一次間接跳轉的代價,且妨礙內聯(inlining)。這對應 Python 那種「執行期才知道型別」的世界觀。
- 編譯期多型(compile-time polymorphism):透過模板實現。型別在編譯期就定下,編譯器能把每個版本完全特化、激進內聯與最佳化。代價是二進位膨脹與編譯時間。
模板走的是後者。它有時被稱為「靜態多型」或「鴨子型別的編譯期版本」——my_max 不在乎 T 是什麼,只在乎「T 支不支援 >」。這個約束不是寫在型別宣告裡,而是隱含在函數本體用到了哪些運算。STL 的迭代器分類(input / forward / bidirectional / random-access)正是把這種隱含約束形式化:std::sort 要求隨機存取迭代器,編譯器藉此在編譯期就擋掉「拿 list 餵 sort」這種誤用。
Concepts:把約束說清楚
模板的隱含約束有個歷史痛點:約束只存在於「函數本體用了什麼」,沒有明說。所以你傳一個不支援 > 的型別,錯誤訊息會發生在模板內部深處,吐出一堆與你無關的實例化堆疊,難以閱讀。
C++20 的 concepts 就是來解決這件事。它讓你把「T 必須滿足什麼條件」寫成可命名、可檢查的約束:
#include <concepts>
template <typename T>
concept Comparable = requires(T a, T b) {
{ a > b } -> std::convertible_to<bool>;
};
template <Comparable T>
T my_max(T a, T b) {
return a > b ? a : b;
}
Comparable 這個 concept 明說了「T 的兩個值要能用 > 比較、且結果能轉成 bool」。現在如果你傳一個不滿足的型別,編譯器會直接說「T 不滿足 Comparable」——錯誤點落在呼叫處、訊息精準,而不是埋在模板深處。
concepts 的精神,是把過去靠註解、靠文件、靠「編譯爆掉才知道」的隱性契約,提升為型別系統的一等公民。它讓泛型程式從「能跑就好」走向「介面有明確規格」,本質上是給編譯期多型補上了一層型別檢查。對寫函式庫的人來說,這意味著 API 的型別需求變得可文件化、可診斷;對使用者來說,誤用時得到的是一句人話而非數百行模板雜訊。
把這些串起來看:C++ 的模板不是「Python 泛型的語法變體」,而是一套在編譯期執行的型別計算系統。它用編譯時的代價(更長的編譯、更大的二進位、更陡的學習曲線)換取執行期的極致——零開銷的抽象、可預測的記憶體佈局、與手寫程式碼等價的效能。理解這個取捨,你才算真正讀懂了 C++ 為何如此設計,以及它在系統程式、遊戲引擎、高頻交易這些「每個 cycle 都要計較」的領域為何不可取代。