
當迴圈不只是「重複」:流程控制背後的狀態機與協定
從 iterator protocol、生成器惰性求值,到 for...else、遞迴極限與迴圈不變式——讀懂 Python 流程控制的底層真相
當迴圈不只是「重複」:你的 for 其實是一台狀態機
入門篇我們學會了用 if 替程式做決定、用 for / while 讓程式重複做事。那是「能寫出來」的階段。但當你開始讀別人的程式碼、開始追求效率,你會遇到一些更尖銳的問題:
- 為什麼 Python 的
for迴圈跑得比 C 慢,卻又有人說「用內建函式比手寫迴圈快」? - 一個函式裡 5 層巢狀的
if,怎麼變成一行return? for...else這個怪語法到底什麼時候有用,為什麼大家都不敢用?- 為什麼遞迴(recursion)有時優雅、有時直接讓程式爆掉(
RecursionError)?
這篇進階文章不會再講「if 怎麼寫」。我們要把流程控制拆開來看它底層的真相:Python 的流程控制本質上是在驅動一台狀態機(state machine),而 for 迴圈的背後藏著一個叫 iterator protocol 的協定。 理解這層,你寫出來的程式碼會從「能跑」升級到「優雅且快」。
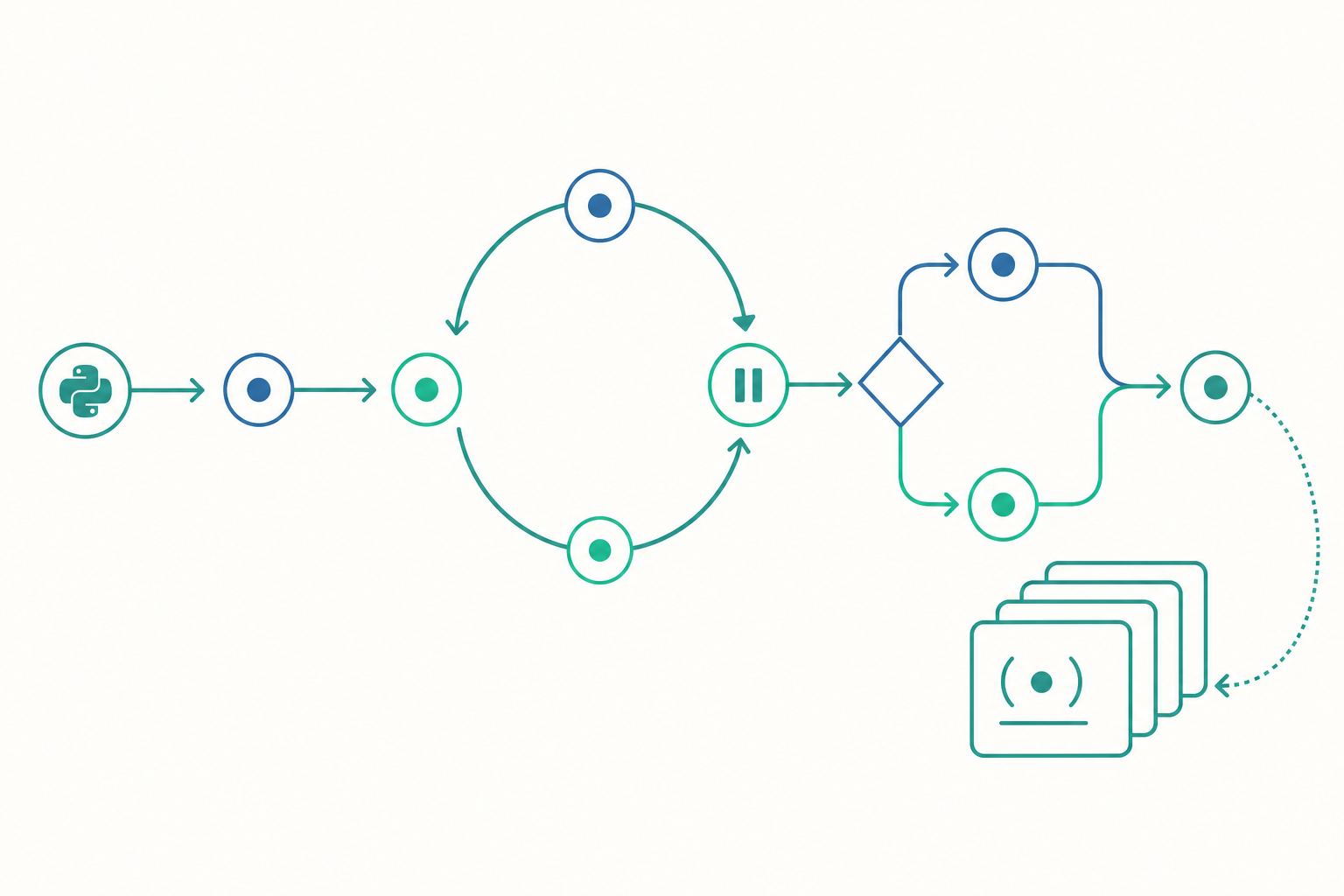
for 迴圈的真相:iterator protocol
入門時我們說 for x in [1, 2, 3] 是「把清單裡的每個元素拿出來」。這個說法夠用,但不精確。真相是:Python 的 for 迴圈完全不認識 list,它只認識兩個 dunder method(雙底線方法):__iter__ 與 __next__。
當你寫:
for x in [10, 20, 30]:
print(x)
Python 直譯器實際上做的事情,等價於這段「去糖」(desugar)後的程式碼:
it = iter([10, 20, 30]) # 呼叫 list.__iter__(),拿到一個 iterator
while True:
try:
x = next(it) # 呼叫 it.__next__(),拿下一個值
except StopIteration: # iterator 喊「沒了」
break
print(x)
看清楚了嗎?for 迴圈其實是一個包了 try/except 的 while 迴圈。它靠 StopIteration 這個例外(exception)來知道什麼時候該停。流程控制(迴圈的終止)和例外處理(exception handling)在這裡是同一件事。 這是很多人從沒意識到的設計。
這也解釋了一個現象:任何物件只要實作了這兩個方法,就能被 for 迭代。我們可以自己造一個:
class CountDown:
def __init__(self, start):
self.current = start
def __iter__(self):
return self # 自己就是 iterator
def __next__(self):
if self.current <= 0:
raise StopIteration
self.current -= 1
return self.current + 1
for n in CountDown(3):
print(n) # 印出 3, 2, 1
CountDown 不是 list、不是 range,但 for 照吃不誤。因為 for 從來不在乎你是什麼型別,只在乎你會不會回應 __next__。
生成器:用 yield 暫停一個迴圈
手寫 __iter__ / __next__ 很囉嗦。Python 給了一個糖:生成器(generator)。只要函式裡出現 yield,它就不再是普通函式,而變成一台會「暫停」的狀態機。
def count_down(start):
while start > 0:
yield start # 在這裡暫停,把 start 交出去
start -= 1
for n in count_down(3):
print(n) # 3, 2, 1
關鍵在 yield 的語意:它不是 return。return 一旦執行,函式就結束、區域變數全部丟掉。yield 則是把函式凍結在原地——區域變數、執行到哪一行,全部保留。下次 next() 被呼叫時,函式從 yield 的下一行繼續跑。
這帶來一個流程控制上的根本差異,我們用 lazy evaluation(惰性求值)來理解。比較下面兩種寫法:
# 寫法 A:一次算完,全部塞進記憶體
def squares_eager(n):
result = []
for i in range(n):
result.append(i * i)
return result
# 寫法 B:要一個才算一個
def squares_lazy(n):
for i in range(n):
yield i * i
squares_eager(10**8) 會試圖在記憶體裡放一億個數字,你的程式大概會直接被作業系統殺掉。而 squares_lazy(10**8) 不論 n 多大,記憶體佔用都是常數 $O(1)$,因為它一次只持有「當下這一個值」。流程控制從「先做完再用」變成「邊做邊用」。
看一個例子:用生成器串接資料處理流水線
生成器最漂亮的地方是可以串接,形成一條惰性的處理流水線(pipeline)。假設我們要處理一個超大的 log 檔,找出所有錯誤訊息並轉成大寫:
def read_lines(path):
with open(path, encoding='utf-8') as f:
for line in f:
yield line.rstrip('\n')
def only_errors(lines):
for line in lines:
if 'ERROR' in line:
yield line
def to_upper(lines):
for line in lines:
yield line.upper()
# 串接:每一層都是惰性的
pipeline = to_upper(only_errors(read_lines('server.log')))
for line in pipeline:
print(line)
注意這條 pipeline 在 for 真正開始跑之前,一行檔案都還沒讀。當你跑迴圈、要第一個結果時,控制流會「往回穿透」三層生成器:to_upper 跟 only_errors 要一行、only_errors 跟 read_lines 要一行、read_lines 才真的去讀檔案的一行。處理一個 10 GB 的檔案,記憶體佔用依然是常數。這種「需求驅動」(demand-driven)的控制流,是純迴圈寫法很難優雅達成的。
把巢狀 if 攤平:guard clause 與短路求值
進階程式設計很大一部分是「降低控制流的複雜度」。最常見的壞味道是巢狀 if 金字塔:
def get_discount(user):
if user is not None:
if user.is_active:
if user.is_member:
if user.years >= 3:
return 0.2
else:
return 0.1
...
這種「向右漂移」(arrow anti-pattern)的程式碼很難讀,因為你得在腦中同時記住四個條件。解法是衛述句(guard clause):把「不符合就提早離開」的情況先處理掉,用 early return 把巢狀攤平:
def get_discount(user):
if user is None:
return 0.0
if not user.is_active:
return 0.0
if not user.is_member:
return 0.0
return 0.2 if user.years >= 3 else 0.1
邏輯完全相同,但每一行都在「縮小可能性」,讀者的心智負擔線性下降,而不是指數累積。控制流變得扁平,這在認知上是巨大的差別。
另一個攤平條件的利器是短路求值(short-circuit evaluation)。Python 的 and / or 不是回傳布林值,而是回傳「決定結果的那個運算元」,並且一旦能確定結果就停止計算:
# x and y:x 為假就回傳 x,否則回傳 y
# x or y :x 為真就回傳 x,否則回傳 y
name = user_input or '訪客' # user_input 是空字串時,給預設值
config.get('timeout') and connect() # 只有 timeout 有設才連線
短路不只是省一點計算,它本身就是一種控制流。a and b() 等價於「只在 a 為真時才執行 b()」,把一個 if 壓進一行運算式。前提是你要清楚它回傳的是運算元本身,這也是 or 設預設值這個慣用法的原理。
for...else 與 while...else:被誤解的語法
Python 有一個讓初學者困惑、連老手都常寫錯的語法:迴圈後面接 else。
for x in data:
if x == target:
print('找到了')
break
else:
print('整個跑完都沒找到')
關鍵迷思要先破除:這個 else 不是配對 if,而是配對 for。語意是:「如果迴圈是自然跑完(沒有被 break 中斷)的,就執行 else。」一旦 break 觸發,else 就被跳過。
很多人覺得這語法名字取壞了——確實,把它讀成 for...nobreak 會直覺很多。但理解之後它在「搜尋」場景非常乾淨。對比沒有 else 的傳統寫法:
found = False
for x in data:
if x == target:
found = True
break
if not found:
print('沒找到')
for...else 省掉了那個 found 旗標變數(flag variable)。旗標變數是控制流的雜訊,能消掉就消掉。判斷它有沒有用的口訣是:只要你的迴圈是在「找東西」,而且「找不到」需要特別處理,就考慮 for...else。
動手算一下:質數判斷的 for...else
質數(prime)判斷是 for...else 的教科書範例。一個數 n 是質數,當且僅當它不能被 2 到 $\sqrt{n}$ 之間任何整數整除:
def is_prime(n):
if n < 2:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
break # 找到因數,不是質數
else:
return True # 迴圈跑完都沒 break,是質數
return False
print([n for n in range(2, 20) if is_prime(n)])
# [2, 3, 5, 7, 11, 13, 17, 19]
讀讀這個控制流:break 代表「找到因數,提早離場」,else 代表「沒有任何因數能整除,確認是質數」。注意檢查到 $\sqrt{n}$ 就夠了——因為若 $n = a \times b$ 且 $a \le b$,那必有 $a \le \sqrt{n}$。這把時間複雜度從 $O(n)$ 降到 $O(\sqrt{n})$,是流程控制與數學洞察結合的好例子。
遞迴:另一種控制流,與它的天花板
迴圈不是重複的唯一手段。遞迴(recursion)讓函式呼叫自己,用「問題拆成更小的同類問題」來表達重複。
def factorial(n):
if n <= 1: # base case:遞迴的出口
return 1
return n * factorial(n - 1) # recursive case
每個遞迴都必須有兩部分:基本情況(base case)讓它停下來,遞迴情況(recursive case)讓它縮小問題。少了 base case,就是無窮遞迴。
但遞迴在 Python 有個現實天花板。每次函式呼叫,直譯器都會在呼叫堆疊(call stack)上壓一個 stack frame,存區域變數和返回位址。Python 預設限制大約 1000 層,超過就:
import sys
print(sys.getrecursionlimit()) # 通常 1000
def deep(n):
return deep(n + 1)
deep(0) # RecursionError: maximum recursion depth exceeded
這跟 C 或 Scheme 不同。許多語言會做尾呼叫優化(tail call optimization, TCO):當遞迴呼叫是函式的最後一個動作時,編譯器可以重用同一個 stack frame,把遞迴變成迴圈,深度無限。但 Python 刻意不做 TCO——Guido van Rossum(Python 創造者)的理由是:TCO 會破壞 traceback(錯誤回溯),讓除錯困難,而可讀的錯誤訊息比這點效能更重要。
所以在 Python,深層遞迴的正解通常是改寫成顯式迴圈,或自己維護一個堆疊:
def factorial_iter(n):
result = 1
for i in range(2, n + 1):
result *= i
return result
選遞迴還是迴圈,不是品味問題,而是工程權衡:遞迴對「樹狀」「分治」問題(走訪檔案目錄、解析 JSON)表達力極強;但對「線性深度很大」的問題,迴圈才安全。
重點回顧
for迴圈的本質是 iterator protocol:它只認__iter__/__next__,靠捕捉StopIteration例外來終止——流程控制與例外處理在底層是同一機制。- 生成器(
yield)是會暫停的狀態機,帶來惰性求值。處理巨量資料時記憶體可維持 $O(1)$,並能串接成需求驅動的 pipeline。 - 衛述句(guard clause)+ 短路求值能把巢狀
if金字塔攤平成扁平、線性可讀的控制流,消掉旗標變數這類雜訊。 for...else的else配對的是迴圈而非if:迴圈自然跑完(沒break)才執行,是「搜尋失敗」場景的乾淨寫法。- 遞迴受限於 call stack(約 1000 層),且 Python 刻意不做尾呼叫優化;深層線性問題該用迴圈,分治樹狀問題才發揮遞迴的優勢。
深入探討(研究所視角)
把流程控制推到理論層次,有三個值得深挖的方向。
第一,控制流即 continuation。 在程式語言理論中,「接下來要執行什麼」可以被具體化(reify)成一個一級物件,稱為 continuation。yield 其實是 continuation 的受限形式:生成器暫停時,保存的就是「剩下要跑的計算」。完整版是 call/cc(call-with-current-continuation,Scheme 的招牌),它能捕捉整個控制流並在任意時刻重啟,足以從零實作出例外、協程、回溯。Python 的 async/await 與生成器同源——asyncio 的事件迴圈本質上就是在一堆暫停的 continuation 之間調度。理解這點,你會看穿「迴圈、例外、協程、async」表面不同,底層都是「保存與恢復控制狀態」的同一主題。
第二,結構化程式設計的數學基礎。 1966 年 Böhm–Jacopini 定理證明了:任何可計算的流程圖,都能只用「順序、選擇(if)、迭代(while)」三種結構表達,完全不需要 goto。這是「結構化程式設計」的理論基石,也是為什麼現代語言敢拿掉 goto。但定理只保證「能做到」,不保證「不膨脹」——有時消除 goto 需要引入額外的旗標變數或重複程式碼。Python 的 break / continue / for...else 正是在「純結構化」與「實務可讀性」之間的工程妥協:它們是受控的局部跳轉,避免了 goto 的混亂,又保留了提早離場的便利。
第三,迴圈不變式(loop invariant)與正確性證明。 嚴謹地證明一個迴圈正確,靠的是迴圈不變式:一個在每次迭代前後都成立的命題。配合 Hoare logic 的三段論——初始化讓不變式成立、每次迭代保持不變式、終止時不變式加上終止條件推出目標——就能形式化證明程式正確。以二分搜尋為例,不變式是「目標若存在,必落在 [lo, hi] 區間內」;這個不變式在每次 lo/hi 更新後都得維持,才能保證搜尋正確。當你寫複雜迴圈卻不確定對不對時,先寫下「每一輪我希望什麼永遠為真」,往往比盯著程式碼 debug 更快找到錯誤。這也是把「直覺寫迴圈」升級成「論證寫迴圈」的關鍵思維轉變。