
用 C++ 追求效能:當 0.1 秒和 10 秒只差一個語言
從無垃圾回收、值語意到快取友善與 -O2 內聯,看懂 C++ 如何貼著硬體把速度榨乾,並接回優電子與優半導體的硬體本質。
當 0.1 秒和 10 秒只差一個語言:你的程式為什麼跑這麼慢?
想像一個情境:你要處理一億筆感測器讀數,算出平均值。你先用 Python 寫了一個迴圈,按下執行,然後去倒了杯咖啡——回來時它還在跑。你把同樣的邏輯翻成 C++,重新編譯執行,眨個眼就結束了。同樣的演算法、同樣的硬體,差距卻是幾十倍甚至上百倍。
這不是魔法,而是 C++ 與 Python 在「離硬體有多近」這件事上做了截然不同的取捨。如果你讀過本專區的 Python 篇,你已經知道 Python 把「方便」放在第一位:動態型別、自動記憶體管理、直譯執行,讓你寫得快、跑得慢。C++ 走的是另一條路——它把「控制權」交還給你。這篇文章不會把 Python 的內容換個語法重講一遍,而是聚焦在一個問題:C++ 到底做對了什麼,讓它快到可以驅動遊戲引擎、作業系統、嵌入式韌體與競賽程式?
讀完你會理解三件事:為什麼 C++ 沒有「垃圾回收停頓」、為什麼「值語意」與「快取友善」是效能的關鍵、以及這一切如何接回優電子與優半導體談的硬體本質。
第一個差異:編譯,而不是直譯
Python 是直譯執行的——你的原始碼在執行時被一行行翻譯。C++ 不一樣,它在執行之前就被編譯器整份翻譯成機器碼(machine code)。當你執行一個 C++ 程式時,CPU 直接吃的是它原生看得懂的指令,中間沒有翻譯官。
#include <iostream>
int main() {
int sum = 0;
for (int i = 1; i <= 100; ++i) {
sum += i;
}
std::cout << "1 加到 100 = " << sum << "\n";
return 0;
}
// 輸出:1 加到 100 = 5050
注意 int sum、int i——這就是靜態型別(static typing)。相較於 Python 變數可以隨時換型別,C++ 要求你在編譯期就講清楚每個變數是什麼。這看似囉嗦,卻是效能的第一根支柱:編譯器知道 i 是 4 位元組整數,就能直接產生一條 CPU 加法指令,不需要在執行時查「這個東西現在是什麼型別?」。
Python 的每個整數其實是一個包了型別資訊與參考計數的物件;C++ 的 int 就是記憶體裡赤裸裸的 4 個位元組。這個差別,乘上一億次迴圈,就是咖啡涼掉的時間。
第二個差異:沒有垃圾回收,記憶體你說了算
Python、Java、Go 都有垃圾回收器(Garbage Collector, GC)——一個在背景默默幫你清理沒用到的記憶體的機制。方便,但有代價:GC 會在不可預測的時間點「暫停」你的程式去做清理(俗稱 stop-the-world pause)。對遊戲來說,這可能是畫面突然卡一下;對嵌入式即時系統來說,這可能是錯過一個必須在 1 毫秒內回應的訊號。
C++ 沒有 GC。記憶體的生死由你掌控。現代 C++ 的慣例是用 RAII(Resource Acquisition Is Initialization):物件在建立時取得資源,在離開作用域(scope)時自動釋放——時間點完全確定,沒有背景暫停。
#include <iostream>
#include <vector>
void process() {
std::vector<int> data(1000); // 在 stack 上宣告,自動配置記憶體
data[0] = 42;
std::cout << data[0] << "\n";
} // 離開作用域的瞬間,data 的記憶體立刻被釋放,沒有 GC 介入
int main() {
process();
return 0;
}
// 輸出:42
vector 的記憶體在 process() 結束的那一刻被精確回收。你不需要手動 delete,但釋放時機是確定的(deterministic)。這正是即時系統(real-time system)愛 C++ 的原因:沒有不可預測的停頓。
反模式提醒:初學者常以為「C++ 一定要手動
new跟delete」。現代 C++(C++11 起)的慣例剛好相反——盡量用vector、string、std::unique_ptr這類會自動管理記憶體的型別,避免裸new/delete。手動配置容易漏掉釋放(記憶體洩漏)或重複釋放(崩潰)。
第三個差異:值語意,資料就在你手上
這是 C++ 與 Python 最深刻、卻最容易被忽略的差別。
在 Python 裡,幾乎所有東西都是「參考(reference)」——變數其實是指向某個堆積(heap)物件的標籤。在 C++ 裡,預設是值語意(value semantics):變數就是那個值本身,直接存在它該在的記憶體位置。
#include <iostream>
struct Point {
double x;
double y;
};
int main() {
Point a{3.0, 4.0};
Point b = a; // 整個複製一份,b 是獨立的值
b.x = 99.0;
std::cout << "a.x = " << a.x << "\n"; // a 完全不受影響
std::cout << "b.x = " << b.x << "\n";
return 0;
}
// 輸出:
// a.x = 3
// b.x = 99
Point b = a; 是真正把 16 位元組(兩個 double)原封不動複製過去。a 和 b 是兩個獨立的記憶體區塊,互不影響。在 Python 裡 b = a 只是讓兩個名字指向同一個物件——這是參考語意,要複製還得特地 copy.deepcopy()。
值語意為什麼快?因為一個 Point 不是「某處堆積物件的指標」,而是資料本身。當你把一堆 Point 放進 vector,它們在記憶體裡是連續排列、緊密相鄰的:
std::vector<Point> points = {{0, 0}, {1, 1}, {2, 2}};
// 記憶體佈局:[x0 y0][x1 y1][x2 y2] ← 全部黏在一起
對比 Python 的 list of objects,每個元素其實是一個指標,指向散落在記憶體各處的物件。這個差別,正是下一節「快取友善」的核心。
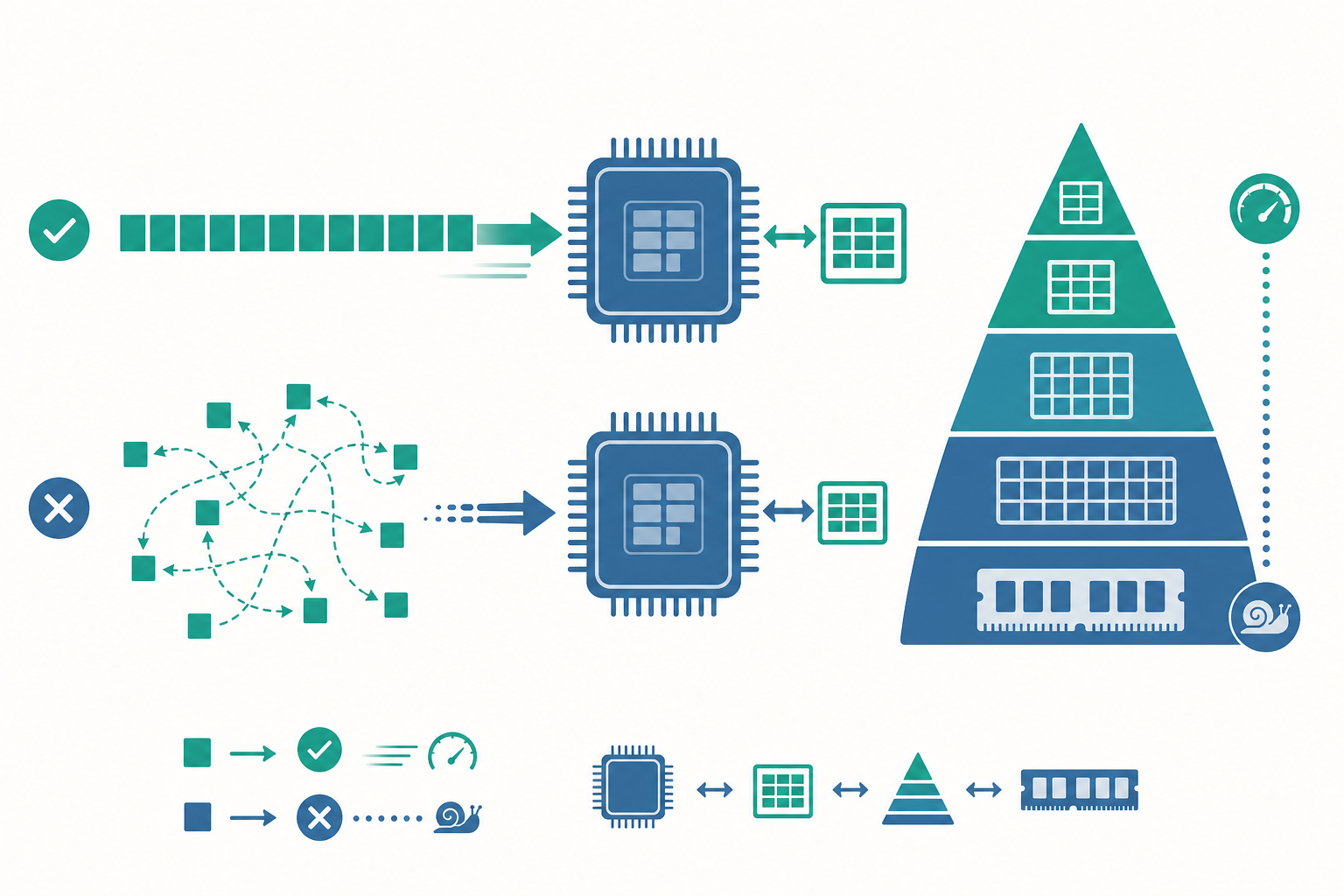
第四個差異:快取友善——速度藏在記憶體佈局裡
這裡要接回優電子與優半導體談的硬體本質了。CPU 的運算速度遠遠快過記憶體存取速度——從主記憶體(RAM)拿一筆資料,可能要等上百個時脈週期。為了不讓 CPU 餓著,硬體設計者在 CPU 旁邊放了快取(cache):一塊小而極快的記憶體。
關鍵在於:CPU 從 RAM 搬資料時,不是一次搬一個位元組,而是一次搬一整條 快取列(cache line),通常是 64 位元組。所以如果你接下來要用的資料,剛好就在剛搬進來的那 64 位元組裡,那它已經在快取裡,存取幾乎免費。這叫空間區域性(spatial locality)。
值語意 + vector 的連續佈局,正好完美契合這個硬體特性。我們用實驗看差別:
#include <iostream>
#include <vector>
#include <chrono>
int main() {
const int N = 50'000'000;
std::vector<int> v(N, 1);
auto start = std::chrono::high_resolution_clock::now();
long long sum = 0;
for (int i = 0; i < N; ++i) {
sum += v[i]; // 連續存取,cache 命中率極高
}
auto end = std::chrono::high_resolution_clock::now();
auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << "總和 = " << sum << ",耗時 " << ms << " 毫秒\n";
return 0;
}
// 輸出(實際數字依機器而定):
// 總和 = 50000000,耗時 30 毫秒
這段之所以快,不只是因為它是 C++,更是因為它順著記憶體跑。如果你改成把資料拆成一個個獨立配置、用指標串起來的鏈結串列(linked list),即使演算法複雜度同樣是 $O(n)$,實測卻可能慢上好幾倍——因為每次跳指標都可能落在不同快取列,CPU 一直在等 RAM。
結論很反直覺但極重要:在現代硬體上,「資料怎麼排在記憶體裡」往往比「演算法的大 $O$」更決定實際速度。C++ 把記憶體佈局的控制權交給你,這正是它能榨乾硬體的根本原因。
動手寫一段:連續 vs 跳躍存取
我們把「快取友善」變成可以親手感受的對照實驗。下面同樣是加總一個陣列,但第二個迴圈刻意以大步幅(stride)跳著存取,破壞空間區域性:
#include <iostream>
#include <vector>
#include <chrono>
long long timed_sum(const std::vector<int>& v, int stride) {
long long sum = 0;
int n = static_cast<int>(v.size());
// 用 stride 控制存取步幅:stride=1 連續,stride 大則跳躍
for (int start = 0; start < stride; ++start) {
for (int i = start; i < n; i += stride) {
sum += v[i];
}
}
return sum;
}
int main() {
const int N = 20'000'000;
std::vector<int> v(N, 1);
for (int stride : {1, 16, 64}) {
auto t0 = std::chrono::high_resolution_clock::now();
long long s = timed_sum(v, stride);
auto t1 = std::chrono::high_resolution_clock::now();
auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(t1 - t0).count();
std::cout << "stride=" << stride << " 總和=" << s
<< " 耗時=" << ms << " ms\n";
}
return 0;
}
// 輸出(數字依機器而定,但趨勢一致):
// stride=1 總和=20000000 耗時=12 ms
// stride=16 總和=20000000 耗時=38 ms
// stride=64 總和=20000000 耗時=55 ms
三次加總的元素數量完全相同、答案也相同,唯一的差別是存取順序。stride=1 順著記憶體跑,快取命中率高;stride=64 每跳一步就跨過一整條快取列,CPU 不斷等 RAM,於是慢了好幾倍。這就是「快取友善」四個字最直接的證據——你可以在自己的電腦上跑跑看,親眼確認數字。
第五個差異:零成本抽象——好看的程式碼不該變慢
你可能擔心:寫得乾淨、用上模板(template)、用上 vector、用上各種封裝,會不會犧牲效能?C++ 的設計哲學給了一個強而有力的承諾——零成本抽象(zero-cost abstraction):你不用為沒用到的東西付代價,而用到的高階抽象,編譯後的效能和你手寫低階程式碼一樣好。
舉個例子,標準函式庫的 std::sort 用了模板,能對任何型別排序,而且通常比 C 語言那個用函式指標的 qsort 更快——因為模板讓編譯器在編譯期就知道比較邏輯,可以直接內聯(inline)展開,省去每次比較都呼叫函式的開銷。
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {5, 2, 9, 1, 7, 3};
// 高階、可讀、泛型——而且零額外執行成本
std::sort(v.begin(), v.end());
for (int x : v) std::cout << x << " ";
std::cout << "\n";
return 0;
}
// 輸出:1 2 3 5 7 9
這裡的 std::sort 是高度抽象的泛型演算法,但編譯後產生的機器碼,和你為 int 親手刻一個快速排序幾乎一樣快。抽象在原始碼層級,成本在編譯期就被消化掉,執行期不留痕跡。這是 C++ 與許多語言的分水嶺:你不必在「好讀」與「夠快」之間二選一。
那 C++ 適合用在哪?
把上面這些特性串起來,就能看出 C++ 的主場:
- 作業系統與系統軟體:需要直接操作硬體、精確控制記憶體,且不能有 GC 停頓。
- 遊戲引擎:每秒要算 60 次以上畫面,任何不可預測的停頓都會破壞體驗;值語意 + 快取友善讓大量物件的更新極快。
- 嵌入式與韌體:記憶體可能只有幾 KB,沒有空間養 GC,每個位元組都要精打細算——這正好接回優電子談的微控制器世界。
- 高效能運算與競賽程式:當你的演算法已經最佳,剩下能榨的就是常數因子,而 C++ 給你榨取常數因子的所有工具。
相對地,如果你在寫一個一次性的資料分析腳本、或一個不在乎那 0.1 秒的小工具,Python 的開發效率會讓你更快交差。選語言不是選「最快的」,而是選「在這個情境最對的」——這才是進階學習者該有的判斷。
常見錯誤(初學者最容易踩的雷)
- 以為快取友善是「進階優化」,先寫完再說:恰恰相反,記憶體佈局是設計階段就該想的事。事後要把鏈結串列改成連續陣列,往往得大改架構。
- 濫用裸指標與
new/delete:現代 C++ 用vector、string、unique_ptr、shared_ptr。看到一堆裸new通常是程式碼味道(code smell),容易洩漏或崩潰。 - 不必要的複製:值語意很好,但把大物件當參數一個個值傳會複製整份。該用
const T&(常數參考)傳遞時就要用,避免昂貴複製。 - 測效能卻忘了開最佳化:用
-O0(預設無最佳化)測出來的數字毫無意義,差距可達十倍以上。效能測試一定要開-O2。 - 過早優化到走火入魔:把可讀性犧牲光只為省幾奈秒,往往得不償失。先用乾淨的抽象寫對,再用實測數據(profiler)找真正的瓶頸。
深入探討(研究所視角)
記憶體階層與快取列:效能的物理基礎
前面提到的「快取友善」,背後是一整套記憶體階層(memory hierarchy)。從快到慢、從小到大,現代 CPU 大致是:暫存器(register)→ L1 快取(約 32 KB,~1 ns)→ L2(數百 KB,~4 ns)→ L3(數十 MB,~15 ns)→ 主記憶體(GB 級,~100 ns)。每往下一層,容量大一個量級,但延遲也大一個量級。
CPU 從記憶體搬資料的最小單位是快取列(cache line),x86 上固定 64 位元組。這帶來兩個工程準則:
- 空間區域性(spatial locality):用到某個位址,附近位址很可能也快被用到——所以資料連續排列(如
vector)勝過散落(如 list of pointers)。 - 時間區域性(temporal locality):剛用過的資料很可能再被用到——所以重複存取同一塊資料時,它已在快取中。
這也解釋了一個進階主題——結構陣列(Array of Structures, AoS)vs 陣列結構(Structure of Arrays, SoA)。若你只需要每個 Point 的 x,把所有 x 放一個陣列、所有 y 放另一個陣列(SoA),會比 vector<Point>(AoS)更快——因為搬進快取列的全是你要用的 x,沒有夾帶用不到的 y。這種佈局思維在遊戲引擎與高效能運算(如 SIMD 向量化)中是核心技巧。
編譯器最佳化與內聯:-O2 在做什麼
C++ 之所以能兌現「零成本抽象」的承諾,編譯器最佳化是幕後英雄。用 GCC 或 Clang 時,-O2 旗標會開啟一整套激進的最佳化,這裡挑兩個最關鍵的:
內聯(inlining):把一個小函式的呼叫,直接用它的函式體展開取代,省去呼叫的開銷(壓堆疊、跳轉、返回)。對於一秒被呼叫上百萬次的小函式,這省下的不只是呼叫成本——內聯之後,編譯器能跨越原本的函式邊界看到更大的脈絡,進而做更多最佳化。
inline int square(int x) { return x * x; }
int main() {
int s = 0;
for (int i = 0; i < 1000; ++i) {
s += square(i); // -O2 下,square 被內聯展開成 i * i
} // 迴圈裡根本沒有函式呼叫指令
return s;
}
inline 關鍵字是給編譯器的「建議」,現代編譯器在 -O2 下會自行判斷該不該內聯(甚至無視你的建議)。這正是 std::sort 比 qsort 快的原因:模板的比較邏輯能被內聯,qsort 透過函式指標呼叫比較函式則無法。
-O2 還會做許多其他事:迴圈展開(loop unrolling)、常數摺疊(constant folding,編譯期就把 2*3 算成 6)、消除無用程式碼(dead code elimination)、暫存器配置(register allocation,把熱資料留在最快的暫存器裡)、以及在支援的硬體上做自動向量化(auto-vectorization)——把一個一個處理的迴圈,改成用 SIMD 指令一次處理多筆資料。
這裡有個學習上的關鍵體悟:你寫的 C++ 原始碼,和最終執行的機器碼,可能長得非常不一樣。編譯器會在不改變程式語意(as-if rule,「彷彿」規則)的前提下,大幅重組你的程式。這也是為什麼效能測試一定要開最佳化——-O0 測的是「翻譯腔」的機器碼,-O2 測的才是 C++ 真正端上桌的實力。
把這一切串回硬體
回到開頭那個一億筆讀數的例子。C++ 快,從來不是單一原因,而是一條完整的鏈:靜態型別讓資料是赤裸的位元組 → 值語意讓它們連續排列 → 連續排列契合快取列 → 編譯器再用 -O2 內聯、向量化把指令壓到極致。每一環都緊貼著優電子與優半導體談的硬體真相:CPU、快取、記憶體階層的物理特性。
學會 C++ 的效能思維,本質上是學會用程式語言去對話硬體。當你下次寫下一個 vector、傳一個 const&、或開上 -O2,你不只是在寫程式碼,而是在替 CPU 鋪一條最順的路。這份對機器的同理心,正是進階程式設計與系統思維的分水嶺——也是這個專區想帶你抵達的地方。