
排序與搜尋:從字典查單字看演算法效率
線性與二分搜尋、五大經典排序、穩定性,以及為何比較排序逃不過 O(n log n) 下限
為什麼字典查單字這麼快,翻通訊錄找人卻這麼慢?
想像你拿到一本沒有編排順序的紙本通訊錄,要從三百個名字裡找出「林宗翰」。你別無選擇,只能從第一頁一個一個往下看,最糟的情況是翻到最後一筆才找到。但同樣三百個單字,你查英漢字典時卻幾乎不費力——因為字典是「排好序」的,你可以翻到中間、判斷目標在前半還是後半,瞬間砍掉一半的範圍。
這個對比點出了計算機科學裡兩個最基礎、也最深刻的問題:搜尋(searching) 與 排序(sorting)。它們看似平凡,卻是幾乎所有系統底層每秒都在做的事——資料庫查詢、搜尋引擎、推薦系統、編譯器,無一例外。更重要的是,這兩個問題是理解「演算法效率」與「問題本質難度」最好的入門教材。
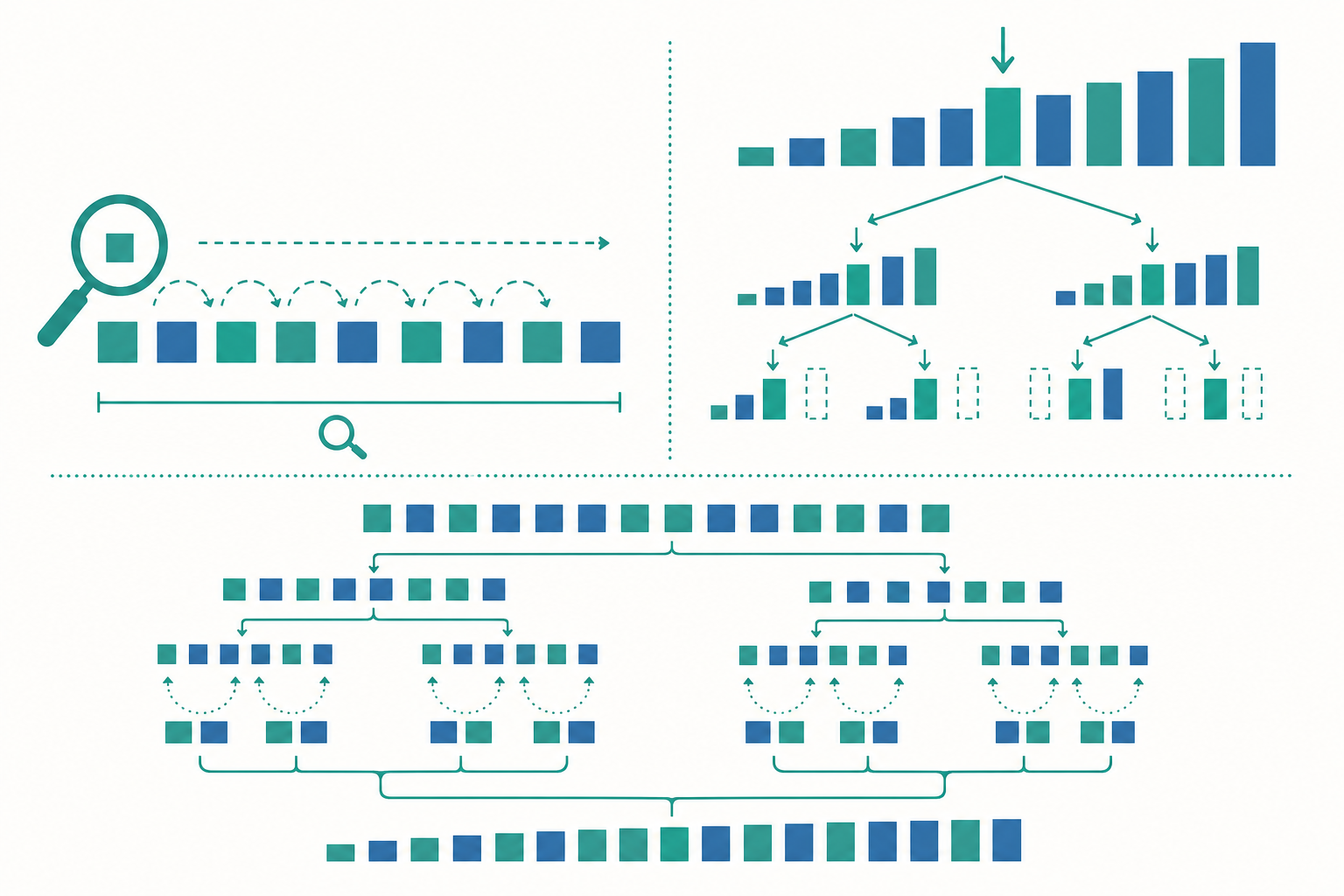
搜尋:線性 vs 二分
最直覺的搜尋是 線性搜尋(linear search):從頭到尾逐一比對,直到找到目標或走完整個序列。它不要求資料事先排序,程式碼也最簡單。
def linear_search(arr, target):
for i in range(len(arr)):
if arr[i] == target:
return i # 回傳索引
return -1 # 找不到
在長度為 $n$ 的序列中,線性搜尋平均要比較約 $n/2$ 次,最壞情況比較 $n$ 次,因此時間複雜度是 $O(n)$。
但如果資料已經排序,我們就能用通訊錄查字典的策略——二分搜尋(binary search)。每次都看中間的元素:若中間值等於目標就結束;若目標較小就只在左半邊找,較大就只在右半邊找。每比較一次,搜尋範圍就少一半。
def binary_search(arr, target):
lo, hi = 0, len(arr) - 1
while lo <= hi:
mid = (lo + hi) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
lo = mid + 1 # 目標在右半
else:
hi = mid - 1 # 目標在左半
return -1
因為每一步都把問題規模對半砍,最多砍 $\log_2 n$ 次就會收斂,所以二分搜尋是 $O(\log n)$。$n = 10^9$(十億)筆資料,線性搜尋最壞要比十億次,二分搜尋卻只要約 30 次。這巨大的差距,正是「先排序、再快速搜尋」這種策略值得投資的原因。
常見迷思:二分搜尋並非永遠比線性搜尋好。如果只查一次、而且資料沒排序,那麼為了二分而先排序(至少 $O(n \log n)$)反而比直接線性掃描($O(n)$)更慢。二分搜尋的價值,在於資料會被反覆查詢多次,排序成本得以攤提。
排序的多種策略
既然排序能讓搜尋變快,那麼如何高效地把一堆資料排好?這裡介紹五種經典的比較排序(comparison sort)——它們只透過「兩兩比較大小」來決定順序。
簡單但較慢的三種:$O(n^2)$
氣泡排序(bubble sort):反覆走訪序列,相鄰兩個若順序錯誤就交換,像氣泡一樣讓大的元素逐漸「浮」到最後。
選擇排序(selection sort):每一輪從未排序部分挑出最小值,放到已排序部分的尾端。
插入排序(insertion sort):像整理手中的撲克牌,每次拿一張新牌插入到前面已排好的牌中正確的位置。
這三者最壞情況都是 $O(n^2)$,因為大致都需要兩層迴圈。但它們各有特性:插入排序在資料幾乎已排序時表現極佳,可達接近 $O(n)$;選擇排序的交換次數最少。
動手看一個例子
以插入排序處理序列 [5, 2, 4, 1],逐步觀察「已排序區」如何逐漸長大:
初始: [5 | 2, 4, 1] (| 左邊是已排序區)
取 2 插入: [2, 5 | 4, 1] 2 移到 5 前面
取 4 插入: [2, 4, 5 | 1] 4 插在 2 和 5 之間
取 1 插入: [1, 2, 4, 5 |] 1 移到最前面,完成
每一步都維持「左側已排序」這個不變條件(invariant),這正是插入排序好懂又好證明正確性的關鍵。
高效的兩種:$O(n \log n)$
合併排序(merge sort) 與 快速排序(quicksort) 都採用 分治法(divide and conquer):把大問題切成小問題、各自解決、再合併。它們的平均時間複雜度是 $O(n \log n)$,在大資料上遠勝 $O(n^2)$ 的方法,我們將在深入段詳細分析。
穩定性:一個常被忽略的性質
排序演算法還有一個重要性質:穩定性(stability)。若兩個元素的鍵值(key)相同,排序後它們的相對前後順序是否保持不變,若不變則稱此演算法是穩定的。
舉例:一份學生名單已按「姓名」排好,現在要再按「班級」排序。若排序演算法穩定,同一班的學生之間仍會維持原本的姓名順序;若不穩定,同班學生的順序可能被打亂。這在做多鍵排序(先排次要鍵、再排主要鍵)時至關重要。
| 演算法 | 平均複雜度 | 最壞複雜度 | 額外空間 | 穩定性 |
|---|---|---|---|---|
| 氣泡排序 | $O(n^2)$ | $O(n^2)$ | $O(1)$ | 穩定 |
| 選擇排序 | $O(n^2)$ | $O(n^2)$ | $O(1)$ | 不穩定 |
| 插入排序 | $O(n^2)$ | $O(n^2)$ | $O(1)$ | 穩定 |
| 合併排序 | $O(n \log n)$ | $O(n \log n)$ | $O(n)$ | 穩定 |
| 快速排序 | $O(n \log n)$ | $O(n^2)$ | $O(\log n)$ | 不穩定 |
從表中可看出沒有「完美」的排序:合併排序穩定且最壞情況也保證 $O(n \log n)$,但需要 $O(n)$ 額外空間;快速排序通常最快、原地排序省空間,但最壞情況退化到 $O(n^2)$ 且不穩定。選擇演算法是一種權衡(trade-off),沒有銀彈。
為什麼比較排序的下限是 $O(n \log n)$?
這是本主題最優雅的理論結果之一。我們能證明:任何只靠「兩兩比較」來決定順序的排序演算法,最壞情況下至少需要 $\Omega(n \log n)$ 次比較——這是物理極限,不是演算法寫得不夠好。
直覺如下:對 $n$ 個元素而言,可能的排列方式共有 $n!$ 種,正確答案是其中唯一一種。每做一次比較,最多只能得到「是」或「否」兩種結果,相當於把可能性最多砍一半。要從 $n!$ 種可能精準鎖定一種,至少需要:
$$\log_2(n!) \text{ 次比較}$$
而根據 Stirling 近似,$\log_2(n!) \approx n \log_2 n - 1.44 n = \Theta(n \log n)$。因此任何比較排序都逃不過 $\Omega(n \log n)$ 的下限。合併排序剛好達到這個下限,是漸近最優(asymptotically optimal) 的比較排序。
這個證明用的是決策樹(decision tree) 模型:把演算法的所有比較分支畫成一棵二元樹,葉子是 $n!$ 種排列,樹高就是最壞比較次數,而有 $n!$ 個葉子的二元樹高度至少 $\log_2(n!)$。
重點回顧
- 搜尋:未排序資料只能線性搜尋 $O(n)$;已排序資料可用二分搜尋 $O(\log n)$,但前提是承受一次性的排序成本,靠多次查詢攤提。
- 簡單排序(氣泡、選擇、插入)都是 $O(n^2)$,適合小資料或近乎排序好的資料;插入排序在近乎有序時接近 $O(n)$。
- 高效排序(合併、快速)採分治法達 $O(n \log n)$;合併排序穩定且最壞情況有保證,快速排序平均最快但最壞退化為 $O(n^2)$。
- 穩定性決定相同鍵值元素的相對順序是否保留,是多鍵排序的關鍵考量。
- 比較排序的理論下限是 $\Omega(n \log n)$,由 $\log_2(n!)$ 的決策樹論證得出;要更快只能放棄「純比較」這個前提。
深入探討(研究所視角)
分治法的遞迴分析:主定理
合併排序的時間複雜度可寫成遞迴式:把規模 $n$ 的問題拆成兩個 $n/2$ 子問題(各自遞迴排序),再用 $O(n)$ 的時間線性合併兩個已排序子序列:
$$T(n) = 2\,T(n/2) + O(n)$$
套用 主定理(Master Theorem):此式形如 $T(n) = a\,T(n/b) + f(n)$,其中 $a = 2$、$b = 2$,故 $n^{\log_b a} = n^{\log_2 2} = n$。由於合併成本 $f(n) = \Theta(n)$ 恰好與 $n^{\log_b a}$ 同階(落在第二種情形),得 $T(n) = \Theta(n \log n)$。直覺上,遞迴樹共有 $\log_2 n$ 層,每層所有合併工作加總都是 $O(n)$,相乘即 $n \log n$。
快速排序的分析更微妙。它先選一個 樞紐(pivot),把序列分成「小於樞紐」與「大於樞紐」兩塊(這步稱 partition,$O(n)$),再對兩塊遞迴。若每次都剛好對半分,遞迴式同樣是 $T(n) = 2T(n/2) + O(n) = \Theta(n \log n)$。但若樞紐選得極差(例如序列已排序、又每次都選最小值當樞紐),就會分成 $0$ 與 $n-1$,退化為:
$$T(n) = T(n-1) + O(n) = \Theta(n^2)$$
實務上用 隨機化選樞紐(randomized pivot) 或「三數取中(median-of-three)」來避免最壞情況;可證明隨機化快速排序的期望比較次數為 $\Theta(n \log n)$,且最壞情況發生的機率極低。快速排序之所以在實務上常勝過合併排序,是因為它原地(in-place) 操作、快取局部性(cache locality)好、常數因子小。許多標準函式庫(如 C++ STL)採用 introsort:先跑快速排序,一旦遞迴深度過深就切換到堆積排序(heapsort)以保證最壞 $O(n \log n)$。
突破下限:非比較排序
$\Omega(n \log n)$ 的下限只適用於比較排序。如果我們不靠比較、而是利用鍵值本身的結構,就能突破這條線。
計數排序(counting sort):當鍵值是範圍 $[0, k)$ 的整數時,開一個大小 $k$ 的陣列直接統計每個值出現幾次,再依序輸出。時間複雜度 $O(n + k)$,當 $k = O(n)$ 時即為線性 $O(n)$。它穩定,但只適用於小範圍整數鍵。
基數排序(radix sort):把整數(或字串)依「位數」由低位到高位、反覆用穩定的計數排序處理。處理 $d$ 位數、每位範圍 $k$ 的資料,複雜度為 $O(d \cdot (n + k))$。處理固定長度的整數鍵時近似線性。
桶排序(bucket sort):當資料均勻分布在某區間,把元素灑進若干個桶、各桶內部排序、再串接,期望複雜度 $O(n)$。
這些方法不違反下限定理——它們根本不在「比較排序」的框架內,而是用了關於資料分布或鍵值結構的額外假設換取速度。這呼應了計算理論的核心觀念:問題的難度取決於你被允許使用什麼運算。
與其他主題的連結
- 資料結構:二分搜尋的概念延伸成 二元搜尋樹(BST) 與平衡樹(AVL、紅黑樹),把 $O(\log n)$ 查詢從靜態陣列推廣到可動態插入刪除的結構;而 雜湊表(hash table) 則用空間換取期望 $O(1)$ 的查詢,是另一種突破比較框架的思路。
- 外部排序(external sorting):當資料量大到無法塞進記憶體,合併排序的「合併」步驟成為主角——多路歸併(k-way merge) 是大型資料庫與 MapReduce 排序的基礎,因為它只需循序讀取磁碟、I/O 效率高。
- 下限證明的方法論:決策樹論證是計算複雜度理論中「資訊論下限(information-theoretic lower bound)」的典範,與密碼學、資訊理論中「想唯一確定一個答案至少需要多少位元」是同一套思維。
最後一點關於合法用途與嚴謹性:排序與搜尋演算法本身是中性的工具,但在處理個人資料(如學習歷程、生理數據)時,無論演算法多高效,都應在合法授權與隱私保護的前提下進行。效率的追求,永遠不該凌駕於資料倫理之上。