
行程與排程(進階)
從虛擬時鐘到 EEVDF:現代作業系統如何把「公平」變成可計算的數字
當「公平」需要一個精確定義:從輪流到虛擬時鐘
入門篇我們把排程器(scheduler)比喻成手腳極快的服務生,並認識了 FCFS、SJF、RR、優先權四種經典演算法。但如果你真的去翻 Linux 核心原始碼,會發現上面這些名字一個都找不到。現代通用作業系統真正在跑的排程器,是另一套更精巧的東西。
問題出在哪裡?想像你有兩個行程:一個是正在播放影片、每隔幾毫秒就醒來解一張畫面的播放器(I/O 密集),另一個是埋頭跑矩陣運算、能用多少 CPU 就用多少的科學計算(CPU 密集)。RR 給每人固定時間配額看似公平,但播放器根本用不滿配額就自願睡去,計算程式卻每次都用好用滿——長期下來,誰拿到的 CPU 比較多?「給相同時間配額」真的等於「公平」嗎?
這篇進階篇要回答的,正是「公平到底該怎麼定義與量化」,以及作業系統如何用一個「虛擬時鐘」把這個抽象目標變成可計算、可比較、可實作的機制。我們會一路推進到 Linux 在 2023 年用來取代沿用十五年的 CFS 的新排程器 EEVDF,並補上即時系統(real-time system)那條入門篇沒走的支線。
把「公平」變成數字:虛擬執行時間
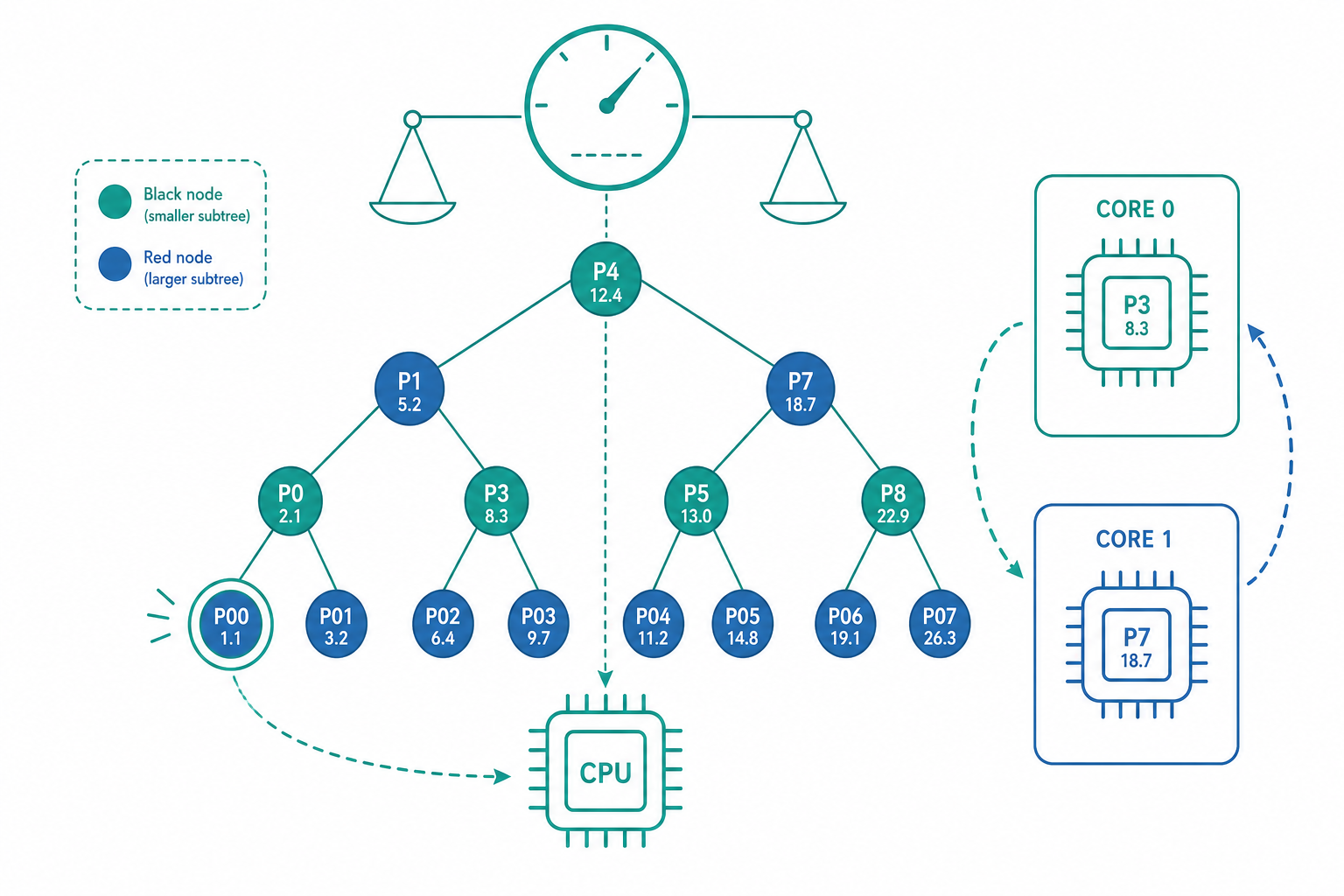
入門篇最後提到 Linux 的 完全公平排程器(Completely Fair Scheduler, CFS) 會挑「虛擬執行時間」最少的行程執行。這句話聽起來簡單,但「虛擬執行時間(virtual runtime, vruntime)」這個量到底是什麼,值得我們拆開來看,因為它是理解現代排程的鑰匙。
理想的公平排程有一個數學上的參考模型,叫 理想多工處理器(ideal multitasking processor):假設有 $n$ 個行程,一台無限快、可以無限細切的 CPU 會讓每個行程同時各拿到 $1/n$ 的算力。當然真實 CPU 一次只能跑一個行程,但我們可以用這個理想當「標準答案」,再想辦法讓真實排程盡量逼近它。
vruntime 就是用來衡量「偏離理想多遠」的指標。它的核心想法是:
每個行程記錄自己「已經用掉的 CPU 時間」,但這個時間會依行程的權重(weight)做縮放。排程器永遠挑 vruntime 最小的行程跑——也就是「目前最吃虧、最該被補償」的那一個。
對一個權重為 $w_i$ 的行程,它實際執行了 $\Delta t$ 真實時間後,vruntime 的增量是:
$$\Delta \text{vruntime}_i = \Delta t \times \frac{w_0}{w_i}$$
其中 $w_0$ 是基準權重。權重越大(越重要)的行程,分母越大,vruntime 走得越慢——於是它得跑更久,vruntime 才會追上別人,等於變相分到更多 CPU。權重小的行程 vruntime 走得快,很快就「超出」別人而被換下。
這就把入門篇的優先權,從一個粗糙的「插隊順序」,升級成了一個連續、可累積、可比較的量。優先權不再是「有沒有資格先跑」,而是「CPU 時間該按什麼比例分配」。
看一個例子:nice 值如何換算成 CPU 占比
在 Linux 裡,使用者調整優先權用的是 nice 值,範圍 −20(最不 nice、搶最兇)到 +19(最 nice、最謙讓)。nice 值不是直接拿來比大小,而是查一張權重表換算成 $w_i$。Linux 的設計是:nice 值每差 1,CPU 占比約差 10%。對應的權重表大致是每差一級乘以 $1.25$:
nice -5 -4 -3 -2 -1 0 1 2 3 4 5
weight ... 3121 2501 1991 1586 1277 1024 820 655 526 423 335 ...
假設系統裡只有兩個 CPU 密集行程 A 與 B,A 的 nice = 0(weight 1024),B 的 nice = 5(weight 335)。它們各自分到的 CPU 占比是權重的比例:
w_a = 1024 # nice 0
w_b = 335 # nice 5
total = w_a + w_b
share_a = w_a / total
share_b = w_b / total
print(f"A 分到 {share_a:.1%}") # A 分到 75.3%
print(f"B 分到 {share_b:.1%}") # B 分到 24.7%
A 拿到約 75%、B 約 25%——比例大約 3:1。你可以驗證一下「每差 1 約差 10%」的設計感:nice 從 0 到 5 差了五級,B 的占比從理想的 50% 一路被壓到約 25%,幾乎砍半。
關鍵在於:這個占比和系統裡有幾個行程無關,永遠由權重比例決定。這正是 vruntime 機制的優雅之處——它不需要事先知道行程要跑多久(不像 SJF 得預測突發時間),只要持續累加、持續挑最小,公平就會自然湧現。
動手算一下:vruntime 怎麼追趕
讓我們把 A、B 放在一條時間軸上,看 vruntime 如何驅動換手。設基準權重 $w_0 = 1024$,排程器每次讓選中的行程跑一個排程顆粒(scheduling granularity),假設是 6 毫秒。
w = {'A': 1024, 'B': 335}
w0 = 1024
vrt = {'A': 0.0, 'B': 0.0} # 兩者初始 vruntime 都是 0
slice_ms = 6.0
timeline = []
for step in range(6):
# 挑 vruntime 最小者(平手取字母小的)
pick = min(vrt, key=lambda p: (vrt[p], p))
vrt[pick] += slice_ms * (w0 / w[pick]) # 依公式累加
timeline.append((pick, round(vrt['A'], 1), round(vrt['B'], 1)))
for i, (p, va, vb) in enumerate(timeline):
print(f"第{i+1}次選中 {p} → vrt(A)={va}, vrt(B)={vb}")
輸出:
第1次選中 A → vrt(A)=6.0, vrt(B)=0.0
第2次選中 B → vrt(A)=6.0, vrt(B)=18.3
第3次選中 A → vrt(A)=12.0, vrt(B)=18.3
第4次選中 A → vrt(A)=18.0, vrt(B)=18.3
第5次選中 B → vrt(A)=18.0, vrt(B)=36.7
第6次選中 A → vrt(A)=24.0, vrt(B)=36.7
注意觀察:B 每被選中一次,vruntime 就暴衝 $6 \times 1024/335 \approx 18.3$,所以它要等很久 A 才追得上;而 A 每次只走 6。數一數六輪裡 A 被選了 4 次、B 被選了 2 次——恰好接近我們算出的 75:25 占比。「挑最小 vruntime」這條極簡規則,竟自動實現了按權重比例分配 CPU 的效果。
用什麼資料結構挑最小?紅黑樹的角色
排程器每次切換都要「找出 vruntime 最小的行程」,而且行程會不斷被插入(醒來)、移除(睡去)。這是一個對效能極度敏感的操作——它在每次上下文切換時都會發生,一秒可能上千次。
CFS 用 紅黑樹(red-black tree) 這種自平衡二元搜尋樹來維護就緒行程,以 vruntime 為鍵(key)排序。它的好處是:
- 插入、刪除、找最小值都是 $O(\log n)$,$n$ 是就緒行程數。
- 「最小 vruntime」永遠是樹的最左節點,可以快取起來,取用接近 $O(1)$。
為什麼不用更簡單的東西?我們對比一下幾種選擇:
| 資料結構 | 找最小 | 插入 | 刪除 | 問題 |
|---|---|---|---|---|
| 未排序陣列 | $O(n)$ | $O(1)$ | $O(n)$ | 找最小太慢,切換頻繁時致命 |
| 排序陣列 | $O(1)$ | $O(n)$ | $O(n)$ | 插入太慢 |
| 二元堆(binary heap) | $O(1)$ | $O(\log n)$ | $O(\log n)$ 僅限堆頂 | 刪除任意節點(睡去的行程)困難 |
| 紅黑樹 | $O(\log n)$ | $O(\log n)$ | $O(\log n)$ | 各項都不是最快,但沒有短板 |
排程器需要的不是某一項最快,而是所有操作都不能太慢——尤其要能高效刪除「任意一個」睡去的行程,這正是二元堆做不好、而紅黑樹擅長的。這是一個很好的「資料結構選型隨使用情境而變」的真實案例:理論最優和工程最適往往不是同一個。
CFS 的隱憂,與 EEVDF 的登場
CFS 從 2007 年服役到 2023 年,是極成功的設計。但它有個被詬病已久的弱點:它只管「公平地分配 CPU 總量」,卻沒有好好處理「延遲(latency)」。
回到開頭的影片播放器。它對「總共拿到多少 CPU」其實不貪心,它真正需要的是低延遲:每次醒來時,希望能馬上被排上去解那一張畫面,晚個幾十毫秒畫面就卡了。但 CFS 沒有一個乾淨的機制讓你表達「我不要更多 CPU,我只要更快被服務」。它能調的只有 vruntime/權重,而權重一調大,就會連帶搶走更多 CPU 總量——延遲和吞吐被綁在同一個旋鈕上,無法分開。
2023 年 Linux 6.6 正式以 EEVDF(Earliest Eligible Virtual Deadline First,最早可服務虛擬截止時間優先) 取代 CFS。EEVDF 的核心升級是:把「公平分配 CPU 總量」和「延遲需求」解耦成兩個獨立的概念。
它引入兩個量:
- lag(落後量):一個行程「應得的 CPU 時間」減去「實際拿到的 CPU 時間」。lag 為正表示它被虧待了,理應優先補償。只有 lag ≥ 0(不欠它、它也沒超用)的行程才「可服務(eligible)」。
- 虛擬截止時間(virtual deadline):每個行程可以宣告一個它希望的時間片長度(稱為 request size),系統據此算出一個虛擬截止時間。EEVDF 在所有「可服務」的行程中,挑虛擬截止時間最早的那個跑。
這帶來一個關鍵能力:一個想要低延遲的行程,可以宣告很短的時間片需求。短時間片 → 更早的虛擬截止時間 → 更容易被優先選中,而且不需要靠搶更多 CPU 總量來達成。影片播放器終於可以說「我只要常常被叫到、每次只跑一點點」,而不必假裝自己很重要去搶算力。
CFS 的世界: EEVDF 的世界:
一個旋鈕(權重) 兩個旋鈕
├─ 影響 CPU 占比 ├─ 權重 → CPU 占比(多少)
└─ 順便影響延遲(綁死) └─ request size → 延遲(多快)
兩者可獨立調整
EEVDF 並非新發明——它的原始論文早在 1995 年就由 Stoica 與 Abdel-Wahab 提出,沉睡了近三十年才被主流核心採用。這也是個提醒:排程理論的「新」與工程落地的「新」,常常隔著數十年的時差。
多核心讓問題整個翻新
入門篇假設「單核心、同一時刻只有一個行程在 running」。一旦進入多核心(multicore)時代,排程要面對的根本不是同一個問題了。
最直覺的想法是:所有核心共用一個全域就緒佇列,誰閒下來就從佇列頭抓一個來跑。但這在實務上行不通,原因有二:
- 鎖競爭(lock contention):那個全域佇列是共享資料,每個核心存取它都得先搶鎖。核心數一多,大家排隊搶這把鎖的時間,可能比真正計算還久。這是典型的可擴展性(scalability)瓶頸。
- 快取親和性(cache affinity):一個行程在核心 0 上跑了一陣子,它常用的資料已經被載入核心 0 的快取(cache)。如果下次把它丟到核心 3,那些資料得重新從記憶體搬一次,快取全部失效——這個隱形成本可能遠大於排程本身。
所以現代核心改用 每核心一個獨立就緒佇列(per-CPU run queue) 的設計:每個核心管自己的佇列,平時互不干擾,鎖競爭大幅降低,行程也傾向留在原核心、保住快取。
但這又帶來新麻煩:核心之間可能忙閒不均。一個核心佇列裡塞了十個行程,另一個核心卻閒著沒事做。於是需要 負載平衡(load balancing) 機制,週期性地檢查各核心負載,把行程從繁忙的核心遷移(migration)到空閒的核心。
這裡藏著一個漂亮的權衡:遷移能讓負載均衡、提高整體吞吐,但遷移本身會破壞快取親和性、付出搬移成本。搬,還是不搬? 這正是多核心排程的核心難題之一。核心會用「遷移成本門檻」來判斷:只有當不均衡嚴重到一定程度,搬移帶來的好處才值得犧牲快取。
重點回顧
- vruntime(虛擬執行時間) 把抽象的「公平」量化成一個可累加、可比較的數字:依權重縮放累計已用 CPU 時間,永遠挑最小者執行,就能讓 CPU 按權重比例分配,且不需預測突發時間。
- Linux 的 nice 值 透過權重表換算,設計成每差一級 CPU 占比約差 10%;占比由權重比例決定,與行程數量無關。
- 排程器用 紅黑樹 維護就緒行程,因為它在「找最小、插入、刪除任意節點」上沒有短板,全部 $O(\log n)$——工程最適不等於單項理論最優。
- EEVDF(2023, Linux 6.6) 取代 CFS,關鍵是把「CPU 占比(多少)」與「延遲(多快)」解耦成兩個獨立旋鈕,讓低延遲行程不必靠搶算力來換取快速回應。
- 多核心排程 改用每核心獨立佇列以降低鎖競爭、保住快取親和性,再靠負載平衡與行程遷移處理忙閒不均——「搬不搬」本身就是一場成本權衡。
深入探討(研究所視角)
即時排程:當「截止時間」是硬規定
前面所有討論都是「盡量公平、盡量快」的盡力而為(best-effort) 排程。但有一類系統,遲到等於失敗:汽車的防鎖死煞車、飛控電腦、工業機械手臂——它們的任務有硬截止時間(hard deadline),錯過一次就可能釀成事故。這是 即時排程(real-time scheduling) 的領域,它追求的不是平均效能,而是可證明的時序保證。
兩個奠基性演算法值得認識:
-
速率單調排程(Rate-Monotonic Scheduling, RMS):給週期越短(越頻繁)的任務越高的固定優先權。它是靜態優先權下的最優演算法。Liu 與 Layland 在 1973 年證明了一個著名的可排程性上界:$n$ 個週期任務若總 CPU 使用率 $U \le n(2^{1/n} - 1)$,則保證所有截止時間都能滿足。當 $n \to \infty$,這個界收斂到 $\ln 2 \approx 0.693$——也就是說 RMS 即使只用約 69% 的 CPU 就可能達到排程極限,留有餘裕是即時系統的常態。
-
最早截止時間優先(Earliest Deadline First, EDF):動態地永遠先跑「截止時間最近」的任務。EDF 是動態優先權下的最優演算法,理論可排程上界高達 $U \le 1$——能榨乾 100% 的 CPU 仍滿足所有截止時間。代價是它在過載(overload)時行為較難預測,且實作成本較高。
注意 EEVDF 名字裡也有「截止時間」,但它用的是虛擬截止時間(一種公平性的代理量),目標仍是公平與低延遲的盡力而為排程,與即時系統那種對應到真實物理時限的硬截止時間,是兩個不同層次的概念,不要混淆。
排程是不是「最優」?一點理論視角
入門篇說 SJF 能讓平均等待時間最小——這在「所有行程同時抵達、非搶佔」的前提下是可證明的最優。但一旦放寬假設,事情就複雜了。若行程在不同時間陸續抵達,要在線上(online) 情境(不知道未來會來什麼)做出最優決策,本身是個困難問題。在排程理論(scheduling theory)中,許多目標(例如最小化加權完成時間總和、考慮任務相依性的排程)已被證明是 NP-hard,意味著我們幾乎不可能找到又快又最優的通用解,只能退而求近似演算法或啟發式(heuristic)。
這解釋了一件事:為什麼真實核心不去追求「數學最優」,而是用 vruntime、紅黑樹、負載平衡門檻這些啟發式的工程設計。最優解往往要嘛無法計算(未來未知)、要嘛計算太貴(NP-hard)、要嘛假設不成立(突發時間無法預知)。好的系統設計不是找到完美答案,而是在不確定與成本約束下,找到「夠好且穩健」的平衡。
延伸連結
排程從來不是孤立的議題。它與同步機制相纏(入門篇的優先權反轉與優先權繼承)、與記憶體管理相纏(被選中的行程若分頁不在實體記憶體,又得阻塞等待 I/O,排程器得立刻換人)、與能耗管理相纏(行動裝置上,把任務塞進少數核心讓其餘核心深度睡眠,往往比追求極致吞吐更省電,這催生了異質多核如 big.LITTLE 架構的排程考量)。當你下次發現手機開很多 App 卻依然滑順、或筆電在重載下還能省電待機,背後都是這套「虛擬時鐘 + 多核協調 + 能耗權衡」的精密合奏在運作。