
檔案系統進階:log-structured、寫入放大與 fsync 的真相
當就地覆寫變成奢侈——從 LFS、SSD 的 FTL,到 B 樹目錄、extent 與原子建檔背後的軟硬體協作
當磁碟「就地覆寫」變成奢侈:為什麼現代檔案系統寧可一直往新地方寫?
入門篇留下了一條伏筆:寫時複製(copy-on-write, CoW)檔案系統「從不就地覆寫」,SSD 的快閃記憶體「不能就地覆寫、且有抹寫壽命」。這兩句話聽起來只是工程細節,但它們其實顛覆了一個我們習以為常的假設——「要改檔案第 5000 個位元組,就回到那個位置把它蓋掉」。
在 1990 年代之前,這個假設天經地義:硬碟(HDD)可以原地改寫任一磁區。但兩股力量同時瓦解了它。其一,記憶體越來越大,讀取越來越多被快取吸收,磁碟流量逐漸由寫入主導,而隨機寫入正是 HDD 最慢的動作(磁頭尋道 + 旋轉延遲)。其二,固態硬碟(SSD)崛起,其底層 NAND 快閃記憶體在物理上根本不允許就地覆寫——你必須先「抹除」一整個區塊才能再寫。
於是一個激進的想法浮現:與其追著舊位置改,不如把所有寫入都變成順序的、附加式的(append-only)。本文就從這個想法出發,帶你走進 log-structured 設計、CoW 語意、目錄的 B 樹索引、extent 配置,以及 fsync 背後那層常被誤解的快取語意。讀完你會發現,入門篇學到的 inode 與 journaling,只是現代儲存堆疊的地基,而真正決定效能與壽命的,是「寫到哪裡、何時回收」這件事。
Log-structured:把整顆磁碟當成一條只能往前寫的日誌
入門篇的 journaling,是「先把意圖寫進一小塊日誌區,再 checkpoint 回最終位置」——日誌只是輔助,資料最終仍住在它「應該在」的固定位置。Log-structured file system(LFS)把這個想法推到極致:整顆磁碟就是一條日誌,沒有「最終位置」這回事。所有寫入(資料區塊、inode、目錄、bitmap)一律追加到日誌尾端,順序前進。
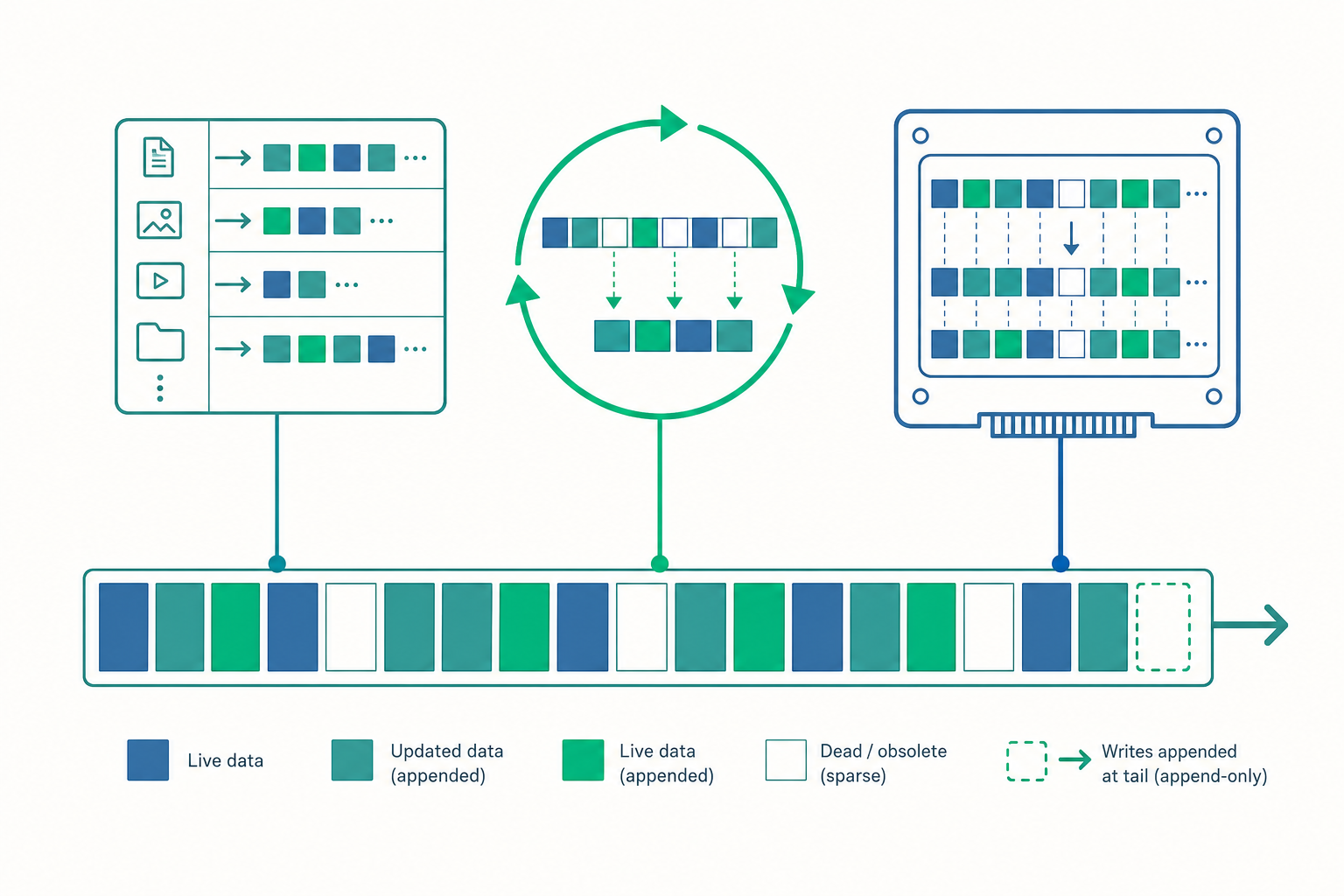
這帶來一個立即的好處:寫入恆為順序。無論應用程式邏輯上多麼隨機地修改十個小檔案,落到磁碟上都是一段連續的、磁頭不必尋道的長寫入。但它也立刻撞上一個棘手問題——如果 inode 也不在固定位置了,怎麼找到它?
LFS 的答案是一張 inode map(imap):一個「inode 編號 → inode 目前在日誌中的位置」的對照表。每次某個 inode 被改寫並追加到日誌新位置,imap 對應項就更新。imap 本身也太大不能整個放記憶體常駐,於是它也被分塊寫進日誌,再用一小塊固定位置的 checkpoint region 記住「imap 各塊現在在哪」。查一個檔案的流程變成:
路徑名 → 目錄項拿到 inode 編號
→ 查 imap 得到該 inode 在日誌中的位置
→ 讀出 inode → 順其 block pointer 讀資料區塊
注意這條鏈條只比傳統檔案系統多了一次「查 imap」,而 imap 通常被快取在記憶體中,幾乎零成本。
# LFS 寫入一次「修改檔案某區塊」的概念流程(極簡化)
def lfs_write_block(file_inode_num, block_index, new_data):
# 1) 資料區塊:寫到日誌尾端,得到新位置
data_addr = log.append(new_data)
# 2) inode:複製一份、更新該 block pointer,再附加到日誌
inode = read_inode(file_inode_num)
inode.block_ptr[block_index] = data_addr
inode_addr = log.append(inode.serialize())
# 3) imap:把「inode_num → inode_addr」更新後也附加
imap_chunk = read_imap_chunk(file_inode_num)
imap_chunk[file_inode_num] = inode_addr
imap_addr = log.append(imap_chunk.serialize())
# 4) checkpoint region(固定位置)偶爾更新,指向最新 imap 各塊
checkpoint.update(file_inode_num, imap_addr)
關鍵體會:一次邏輯上「改一個位元組」,在 LFS 裡會連鎖產生「資料 → inode → imap」三筆新寫入,舊版本則原地留在日誌裡變成垃圾。這正是 CoW 的本質——永不覆寫,只追加新版、廢棄舊版。它優雅地解決了入門篇的崩潰一致性:因為舊資料還在、根指標尚未切換,崩潰時最壞只是丟掉最後一筆沒提交完的寫入,絕不會出現「改到一半」。
垃圾回收:log-structured 設計的阿基里斯腱
「只往前寫」的代價很現實:磁碟是有限的,日誌不可能無限延長。當前面那些被廢棄的舊版本(dead blocks)累積夠多,就必須回收(garbage collection, GC),把它們騰出來重新使用。
LFS 把磁碟切成許多大的 segment(如 1MB),GC 以 segment 為單位進行:挑幾個「活資料稀疏」的 segment,把其中仍存活(live)的區塊讀出來、搬到日誌尾端的新 segment,原 segment 就整段空出。難點在於——怎麼知道某個 segment 裡哪些區塊還活著? LFS 在每個 segment 開頭放一塊 segment summary,記錄「這個區塊屬於哪個 inode 的第幾個 block」。GC 時拿這個資訊反查 imap:若該 inode 現在的 block pointer 仍指向這裡,就是 live;若已指向別處,就是 dead。
GC 的效率高度取決於挑哪些 segment 來清。經典 LFS 論文提出的洞見是:冷熱資料要分流。一個 segment 若裝的是長期不動的「冷」資料,它的存活率會穩定維持高檔,清它很不划算(搬很多 live 區塊卻只回收一點空間);反之頻繁改寫的「熱」資料 segment 很快就佈滿 dead 區塊,存活率低,清它的回收效益最高。因此聰明的 GC 不是單純挑「最空的」,而要綜合考量存活率與「資料有多久沒動」。
動手算一下:寫入放大
讓我們量化 GC 帶來的隱形成本。定義寫入放大(write amplification, WA):
$$\text{WA} = \frac{\text{實際寫入磁碟的位元組}}{\text{應用程式要求寫入的位元組}}$$
假設我們要清一個 segment 來容納新寫入,而被清的 segment 平均存活率為 $u$(即 $u$ 比例的區塊仍是 live,需被搬走)。每清出 $(1-u)$ 比例的空間給新資料,就得額外搬移 $u$ 比例的舊資料。可推得穩態下的寫入放大約為:
$$\text{WA} \approx \frac{1}{1-u}$$
代入數字感受一下:
存活率 u = 0.5 → WA ≈ 1 / (1 - 0.5) = 2.0 (每寫 1 份,搬 1 份)
存活率 u = 0.8 → WA ≈ 1 / (1 - 0.8) = 5.0 (每寫 1 份,搬 4 份!)
存活率 u = 0.9 → WA ≈ 1 / (1 - 0.9) = 10.0
這個簡單的式子揭示了一個殘酷現實:磁碟越滿(平均存活率越高),GC 越痛苦。當 SSD 用到接近全滿,寫入放大會急遽惡化,這正是為什麼廠商會保留一塊使用者看不到的 over-provisioning 空間(如標稱 512GB 實體 NAND 卻給 480GB),刻意壓低有效存活率,把 WA 控制在合理範圍。理解這條 $\frac{1}{1-u}$ 曲線,你就懂了「SSD 不要塞太滿」這條民間智慧背後的數學。
這一切如何對上 SSD 的物理:FTL 把它變成硬體共識
LFS 在 1990 年代為 HDD 設計時,業界一度覺得它「想法漂亮但 GC 成本太高、贏不了就地覆寫」。真正讓 log-structured 思想翻身的,是 SSD。
NAND 快閃記憶體有三條鐵律:(1) 讀寫以 page(如 4KB/16KB)為單位;(2) 抹除卻只能以 block(數百個 page,如 4MB)為單位;(3) 每個 block 有抹寫次數壽命上限(P/E cycles,消費級 TLC 約數百到數千次),寫太多次就壞。
這意味著「就地覆寫一個 4KB page」在物理上是不可能的——你得先抹掉它所在的整個 4MB block,但那裡還住著其他有效資料。於是 SSD 內部的韌體 Flash Translation Layer(FTL) 做了一件事:對外假裝自己是個可隨機覆寫的區塊裝置,對內偷偷實作了一套 log-structured + GC + wear leveling。
作業系統視角: FTL 內部真相:
寫 LBA 100 (邏輯位址) → 找一個乾淨 page,寫進去
→ 更新映射表:LBA 100 → 實體 page X
再寫 LBA 100 → 不覆寫 X!找另一個乾淨 page Y
→ 映射表改成:LBA 100 → Y,page X 標為 dead(待 GC)
於是入門篇提到的 imap,在 SSD 內部以「LBA → 實體 page」映射表的形式真實存在;LFS 的 GC 變成 SSD 的 garbage collection;而為了讓所有 block 的抹寫次數平均、避免某些 block 先磨穿,FTL 還加了 wear leveling(耗損平均):刻意把熱資料搬到抹寫次數少的 block。寫入放大那條 $\frac{1}{1-u}$ 公式,因此直接決定了 SSD 的實際壽命——WA 越高,同樣的使用者寫入會消耗越多 P/E cycle。
這帶出一個重要的軟硬體協作機制:TRIM 指令。當你刪除檔案,檔案系統知道某些 LBA 不再有用,但 FTL 不知道——它仍以為那些 page 是 live,GC 時白白搬移。TRIM 讓檔案系統主動告訴 SSD「這些 LBA 我不要了」,FTL 就能把對應 page 標為 dead、跳過搬移。沒有 TRIM 的 SSD 用久了寫入放大會莫名升高,正是這個資訊斷層所致。
目錄不再是線性表:當一個資料夾有十萬個檔案
入門篇把目錄描述成「一張檔名 → inode 編號的對照表」。在小目錄這完全沒問題,但若一個目錄塞了十萬個檔案(想想郵件伺服器、快取目錄),線性掃描找一個名字就是 $O(n)$,建立 $n$ 個檔案則退化成 $O(n^2)$。
現代檔案系統因此用樹狀索引組織大目錄。ext4 採用 HTree(一種雜湊化的 B 樹變形):對檔名取雜湊值,用雜湊值當索引鍵建一棵淺樹(通常 1–2 層就能涵蓋數百萬筆),查一個名字變成 $O(\log n)$ 甚至接近常數。XFS 與 Btrfs 則直接用 B+ 樹管理目錄項與 extent。
線性目錄(小目錄 OK,大目錄災難):
[("a.txt",12) ("b.txt",13) ("c.txt",14) ... ("z99999.txt",...)]
查 "m.txt" → 從頭比對,平均掃一半,O(n)
HTree / B+ 樹目錄(大目錄):
[hash 區間索引]
/ | \
[葉子] [葉子] [葉子]
查 "m.txt" → hash("m.txt") 導航到對應葉子,O(log n)
這裡有個給程式設計者的實務啟示:當你在某個目錄下產生海量小檔案,遍歷順序可能不是字典序而是雜湊序(看起來「亂跳」),這是 HTree 的副作用而非 bug。若需要排序輸出,請在應用層自己排,別假設檔案系統會給你字典序。
Extent:用「一段範圍」取代「一個個區塊指標」
入門篇的 inode 多層索引,把每個資料區塊都單獨記一個指標。對一個 1GB 的連續大檔案(4KB 區塊下 = 262144 個區塊),這要存 26 萬個指標,光索引就佔掉可觀空間,而且大多是「100, 101, 102, 103...」這種連號的浪費。
Extent(區段) 是更聰明的表示法:不記每個區塊,而記「從邏輯第 0 區塊起、對應實體第 100 區塊、長度 262144」這樣一個三元組 (邏輯起點, 實體起點, 長度)。一個完全連續的大檔案,整份 metadata 可能一個 extent 就搞定。
傳統 block pointer(每塊一個指標):
[100][101][102][103]...[262143] ← 26 萬個 4 位元組指標 ≈ 1MB
Extent(一段範圍一筆):
[(logical=0, physical=100, len=262144)] ← 一筆 12 位元組搞定
ext4、XFS、Btrfs、NTFS 都用 extent。它不只省空間,也讓「這個檔案實體上有多連續」一目了然,對順序讀取的預取(prefetch)非常友善。當檔案因多次追加而變得破碎,extent 數量上升,這也是檔案系統判斷「該不該做 defrag」的依據。
fsync 的真相:你以為寫進檔案了,其實還在記憶體裡
最後一個常被新手(甚至資深工程師)誤解的進階主題:寫入並不等於落盤。當你的程式呼叫 write() 成功回傳,資料通常只到了作業系統的 page cache(記憶體中的磁碟快取),尚未真正寫到儲存裝置。這是刻意的——讓寫入先在記憶體聚集、合併、延後,能大幅提升效能。但若此時斷電,這些「已 write 成功」的資料會憑空蒸發。
要保證落盤,必須呼叫 fsync(),它會阻塞直到該檔案的資料與 metadata 真的寫進穩定儲存。
import os
# 危險:write 成功 ≠ 資料安全。斷電可能丟資料。
with open("important.log", "w") as f:
f.write("transaction committed\n")
# 此處資料可能還在 page cache
# 安全:強制落盤
with open("important.log", "w") as f:
f.write("transaction committed\n")
f.flush() # 把 Python 緩衝刷進 OS
os.fsync(f.fileno()) # 命令 OS 把 page cache 刷進磁碟
但這裡藏著一個更深的陷阱,與入門篇的 journaling 直接相扣:對檔案 fsync,不保證它所在的目錄項也落盤了。如果你新建一個檔案、寫入、fsync,然後斷電——資料區塊可能安全了,但「父目錄裡那一筆檔名 → inode」的記錄若還在 page cache,重開機後這個檔案根本不存在(或叫不出名字)。正確的「原子建檔」慣用法是:寫進臨時檔 → fsync 臨時檔 → rename() 成目標名 → 再 fsync 父目錄。許多資料庫與編輯器的「保證存檔」都是這套舞步。
import os, tempfile
def atomic_save(path, data):
d = os.path.dirname(path)
fd, tmp = tempfile.mkstemp(dir=d) # 同目錄建臨時檔(確保同檔案系統)
try:
os.write(fd, data)
os.fsync(fd) # 臨時檔內容落盤
finally:
os.close(fd)
os.rename(tmp, path) # rename 在同檔案系統內是原子操作
dir_fd = os.open(d, os.O_RDONLY)
try:
os.fsync(dir_fd) # 父目錄的更名記錄也落盤
finally:
os.close(dir_fd)
rename() 之所以是這套技巧的核心,是因為 POSIX 保證同一檔案系統內的 rename 是原子的:目標路徑要嘛指向舊檔、要嘛指向新檔,永遠不會處於「半個檔名」的中間態。這個保證又是由底層 journaling/CoW 撐起來的——我們繞了一圈,回到了入門篇的崩潰一致性。
重點回顧
- Log-structured 設計把整顆磁碟當成只能往前追加的日誌,所有寫入(含 inode、imap)一律順序附加、永不就地覆寫,這正是 copy-on-write 的本質,也天然解決崩潰一致性。
- 代價是需要垃圾回收(GC),其成本由寫入放大 $\text{WA} \approx \frac{1}{1-u}$ 主導:磁碟越滿(存活率 $u$ 越高),搬移越多、壽命越短——這就是「SSD 別塞太滿」的數學根據。
- SSD 的 FTL 在硬體內部偷偷實作了 log-structured + GC + wear leveling,把「不能就地覆寫」的 NAND 偽裝成可覆寫裝置;TRIM 讓檔案系統告知 FTL 哪些 LBA 已廢棄,避免無謂搬移。
- 大目錄用 HTree/B+ 樹 把查找從 $O(n)$ 降到 $O(\log n)$,副作用是遍歷順序為雜湊序而非字典序;extent 用
(邏輯起點, 實體起點, 長度)取代逐區塊指標,省空間又利於預取。 write()成功僅代表進了 page cache,需fsync()才落盤;而原子建檔必須「臨時檔 fsync → rename → 父目錄 fsync」三步到位,因為 fsync 檔案不涵蓋其目錄項。
深入探討(研究所視角)
B-tree 與 LSM-tree:兩種「對抗隨機寫」的世界觀
本文反覆出現「把隨機寫變順序寫」的母題,這在儲存系統研究中對應兩大流派,值得放在一起對照。
B+ 樹路線(傳統檔案系統、多數關聯式資料庫的儲存引擎)以「讀最佳化」為核心:資料就地維護在平衡樹中,點查詢與範圍查詢都是 $O(\log n)$ 且常數小,但更新需就地修改頁面,帶來隨機寫。LSM-tree(Log-Structured Merge-tree)路線(LevelDB、RocksDB、Cassandra)則把 LFS 的哲學帶進資料庫:寫入先進記憶體 memtable,滿了就順序 flush 成不可變的 SSTable,背景再以多層 compaction 合併排序——本質上就是把 GC 改名叫 compaction。
兩者的取捨可用 RUM 猜想(RUM conjecture)框定:任何儲存結構在 Read(讀放大)、Update(寫放大)、Memory(空間放大)三者間無法同時最優,只能取兩失一。B+ 樹偏向低讀放大,LSM 偏向低寫放大(順序寫對 SSD 友善、WA 低),代價是讀一筆可能要跨多層查找(讀放大),需 Bloom filter 補救。理解這個三角,你會發現「檔案系統選 extent + B 樹」與「NoSQL 選 LSM」其實是同一個問題在不同 workload 假設下的不同解。
CoW 檔案系統的快照與其隱藏成本
ZFS、Btrfs 把 CoW 從「崩潰一致性手段」升級成「使用者功能」:既然修改總是寫新區塊、舊區塊還在,那麼只要保留某一刻的根指標,就凍結了整個檔案系統的當時狀態——這就是快照(snapshot),幾乎零成本(只是不回收舊版本)。再配合區塊級的 checksum,CoW 檔案系統能偵測並(在有冗餘時)自我修復 bit rot(位元腐蝕)。
但 CoW 並非免費午餐。對「就地小幅修改大檔案」這種 workload(典型如資料庫檔、虛擬機映像),每改一小塊就要 CoW 出新區塊,導致檔案在實體上越來越破碎,順序讀效能隨時間退化——這是 CoW 檔案系統著名的痛點,常需以 nodatacow 屬性或定期重整緩解。此外,當多個快照共享大量區塊時,「刪一個檔到底釋放多少空間」變得難以預測(取決於有多少快照仍引用該區塊),這也是 CoW 系統容量管理比傳統檔案系統棘手的原因。
一個值得思考的開放問題
當 SSD 的 FTL 內部已是 log-structured + GC,而上層的 LFS/LSM/CoW 檔案系統也在做 log-structured + GC,就出現了「兩層 log 疊在一起、各自做 GC」的語意重複與效能干擾(log-on-log 問題)。前沿研究方向如開放通道 SSD(Open-Channel SSD) 與 Zoned Namespace(ZNS) 試圖把 FTL 的控制權上交給主機,讓檔案系統直接管理 flash 的 zone、消除一層多餘的 GC。這是「端到端原則」在儲存堆疊的再次體現——當抽象層的假設(可隨機覆寫)與底層物理(只能追加)嚴重失配時,最好的解法往往不是疊更多翻譯層,而是把抽象拆穿、讓兩端直接協商。