
資料庫引擎蓋下:B+ 樹、查詢最佳化、MVCC 與 CAP 取捨
入門篇講了資料庫對你的承諾,這篇掀開引擎蓋,看頁與 B+ 樹如何馴服緩慢的磁碟、成本基礎最佳化器如何從上百種計畫挑最便宜的、MVCC 怎麼讓讀不擋寫,以及 CAP 定理為分散式資料庫畫下的物理邊界。
當你打下 SELECT 的那一刻,資料庫在引擎蓋下做了什麼?
入門篇帶你理解了一件事:為什麼搶票系統不能用幾個文字檔硬幹,以及 ACID(原子性、一致性、隔離性、持久性)與並行控制如何保住資料不被搞砸。那是「資料庫對使用者承諾了什麼」的層次。這一篇要掀開引擎蓋,問一個更尖銳的問題:這些承諾是怎麼被實作出來的?
當你打下一句看似平凡的 SELECT * FROM orders WHERE user_id = 42,資料庫並不是傻傻地把整張表從硬碟搬進記憶體一筆一筆比對。它在內部要回答一連串工程問題:資料在磁碟上長什麼樣子?要怎麼不掃全表就找到 user_id = 42 的那幾列?同一句查詢有十種執行方式,怎麼選最便宜的?當一千個交易同時跑,怎麼讓它們看起來像是排隊一個一個跑、又不真的逼它們排隊?而當資料大到一台機器裝不下、必須切到多台機器時,又有什麼是物理定律根本不允許你同時擁有的?
這篇文章假設你已經懂 ACID 與交易的概念,我們直接進入儲存結構、索引、查詢最佳化、MVCC 並行機制與分散式取捨——也就是真正讓資料庫「快而且正確」的那一層。
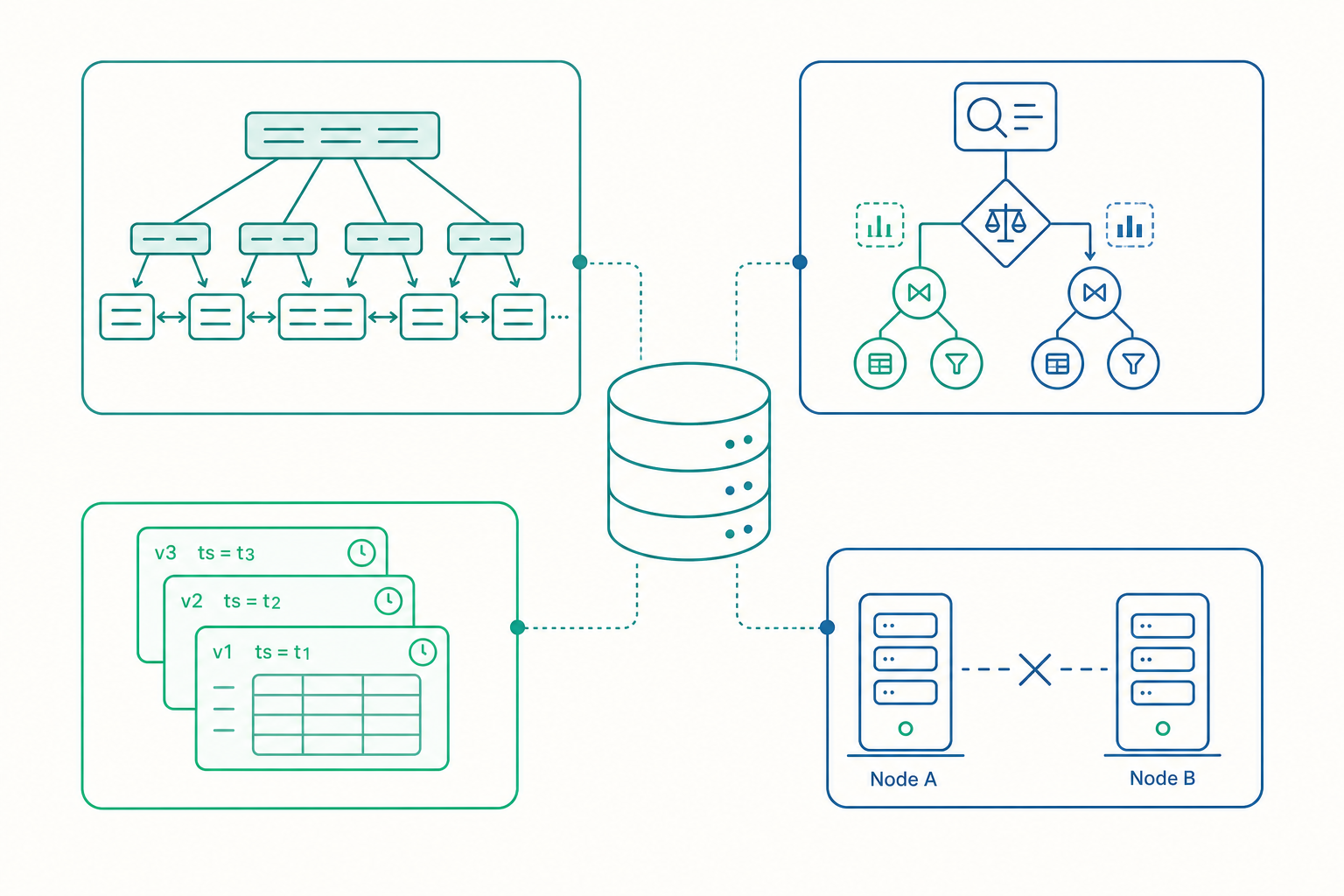
一切從「磁碟很慢」開始:頁(Page)與 B+ 樹
要理解資料庫的所有設計,先記住一個物理事實:從記憶體讀一筆資料約 100 奈秒,從傳統硬碟(HDD)隨機讀一筆約 10 毫秒——差了十萬倍。即使是 SSD,隨機讀也比記憶體慢上千倍。資料庫的核心使命,幾乎都是「盡量少碰磁碟、碰的時候一次多搬一點」。
於是資料庫不以「一列」為單位讀寫磁碟,而是以頁(page)為單位,通常一頁 4KB、8KB 或 16KB(PostgreSQL 預設 8KB,InnoDB 預設 16KB)。一次磁碟 I/O 就是一頁。資料庫的成本模型裡,「碰了幾頁」往往比「比較了幾次」更接近真實效能。
現在問題來了:表有一億列、佔了幾百萬頁。WHERE user_id = 42 如果要掃全表,就是幾百萬次磁碟 I/O,慢到不可接受。我們需要一種結構,讓「找特定值」只碰少數幾頁——這就是索引(index),而關聯式資料庫最主流的索引結構是 B+ 樹(B+ tree)。
為什麼不是入門資料結構教的二元搜尋樹(BST)或紅黑樹?因為它們是為「記憶體」設計的:每個節點只存一個鍵,樹高 $\log_2 n$。一億筆資料樹高約 27 層,意味著最壞 27 次磁碟 I/O。B+ 樹的關鍵差異是每個節點就是一整頁、塞進幾百個鍵,所以分支因子(fanout)極高:
[ 100 | 500 | 900 ] ← 根節點(1 頁)
/ | \
[..<100..] [100..500] [500..900] ← 內部節點
| | |
[葉][葉] [葉][葉] [葉][葉] ← 葉節點:存實際鍵 + 指標
↔ ↔ ↔ 葉節點用雙向鏈結串起來
設一頁能放 $b$ 個鍵(實務上 $b$ 常達數百),則樹高是 $\log_b n$。當 $b = 400$、$n = 10^8$ 時:
$$\log_{400}(10^8) = \frac{\log 10^8}{\log 400} = \frac{8}{2.6} \approx 3.07$$
也就是只要 3~4 次磁碟 I/O 就能定位任何一筆資料。這就是 B+ 樹之所以統治資料庫世界的原因:它把樹高從 $\log_2 n$ 壓到 $\log_b n$,而 $b$ 越大、樹越扁、磁碟越省。
B+ 樹還有一個容易被忽略但極關鍵的設計:所有實際資料只存在葉節點,內部節點只存「路標」,而且葉節點之間用鏈結串成有序鏈表。這帶來兩個好處:
-- 範圍查詢:找到起點葉節點後,沿著葉鏈表「順著走」即可,不必回頭爬樹
SELECT * FROM orders WHERE amount BETWEEN 1000 AND 5000;
-- ORDER BY 幾乎免費:B+ 樹葉節點本來就是排好序的
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at;
範圍查詢與排序之所以能搭著索引飛快跑,正是因為葉節點天生有序且互相串連。
看一個例子:索引讓全表掃描變成三次跳躍
假設 orders 表有 1000 萬列、存在 50 萬頁上。我們比較有索引與沒索引找一筆資料的成本:
| 情況 | 邏輯 | 磁碟 I/O 估計 |
|---|---|---|
| 無索引(全表掃描 Seq Scan) | 一頁一頁讀完整張表 | 約 500,000 次 |
| 有 B+ 樹索引(Index Scan) | 爬樹 3 層 + 讀目標資料頁 1 次 | 約 4 次 |
差距是十萬倍。但這裡有一個進階學生必須建立的觀念:索引不是免費的午餐。每多一個索引,就多一棵要維護的 B+ 樹——每次 INSERT/UPDATE/DELETE 都得同步更新所有相關索引。所以「讀多寫少」的欄位適合建索引,而高頻寫入的表上堆滿索引反而會拖垮寫入效能。設計索引的本質,是在讀的加速與寫的負擔之間做取捨。
查詢最佳化器:同一句 SQL 的十種跑法
SQL 是宣告式(declarative)語言——你說「我要什麼」,不說「怎麼拿」。SELECT ... JOIN ... WHERE 描述了結果,但沒規定執行步驟。這留給資料庫一個自由,也是一個負擔:同一句查詢,引擎可能有上百種執行計畫(execution plan),效能可能差幾千倍。負責挑選的元件叫查詢最佳化器(query optimizer)。
考慮這句連結兩張表的查詢:
SELECT u.name, o.amount
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.city = 'Taipei' AND o.amount > 10000;
最佳化器至少要做這些決策:
- 存取路徑(access path):
users走全表掃描還是走city索引?orders走全表還是amount索引? - 連結順序(join order):先過濾
users再找對應orders,還是反過來? - 連結演算法(join algorithm):用巢狀迴圈(nested loop)、雜湊連結(hash join)還是合併連結(merge join)?
關鍵在於:最佳化器不是真的去跑每一種方案——那會比查詢本身還慢。它靠一個成本模型(cost model),用統計資料估算每種計畫的成本,挑最便宜的。這就是成本基礎最佳化(Cost-Based Optimization, CBO)。
成本估算的核心是選擇度(selectivity):某個條件能濾掉多少資料。資料庫會在背景對每張表蒐集統計(直方圖、相異值數量等),於是它能估出:
估算 users 中 city = 'Taipei' 的列數
= 總列數 × 選擇度
= 1,000,000 × (台北市的相異值佔比,例如 1/20)
= 50,000 列
如果某個條件選擇度很高(濾掉 99.99% 的資料),就值得先用它的索引縮小範圍。三種連結演算法的適用情境也很不同:
巢狀迴圈 (Nested Loop):外層每一列,去內層找匹配
成本 ≈ |外| × (查內層索引成本)
→ 外層結果很小、內層有索引時最佳
雜湊連結 (Hash Join):把小表建成記憶體雜湊表,大表逐列查
成本 ≈ |表A| + |表B|(線性)
→ 兩張都大、且記憶體放得下小表時最佳
合併連結 (Merge Join):兩表各自排序後像拉鍊一樣併
成本 ≈ 排序成本 + |A| + |B|
→ 兩邊本來就有序(如都有索引)時最佳
動手算一下:選錯連結順序的代價
假設 users 有 100 萬列、台北市有 5 萬列;orders 有 1000 萬列、金額 > 10000 的有 10 萬列。orders.user_id 上有索引、查一次約 4 次 I/O。
計畫 A:先過濾 users(拿到 5 萬筆台北用戶),對每筆用 user_id 索引去 orders 找:
$$\text{成本}_A \approx 50{,}000 \times 4 = 200{,}000 \text{ 次索引探查}$$
計畫 B:先過濾 orders(拿到 10 萬筆大額訂單),對每筆回 users 找:
$$\text{成本}_B \approx 100{,}000 \times 4 = 400{,}000 \text{ 次索引探查}$$
計畫 A 便宜一倍——因為它先用了選擇度更高的那一側(台北用戶 5 萬 < 大額訂單 10 萬)當外層驅動表。最佳化器的工作,就是在不真正執行的情況下,靠統計推出「先過濾哪一邊比較划算」。
這也解釋了一個實務現象:統計過期會讓最佳化器做出蠢決定。如果 users 表昨天還只有一千列、最佳化器以為它很小,今天暴增到一百萬列卻沒重新蒐集統計,它可能仍選那個對小表才划算的計畫,於是查詢慢到爆。ANALYZE(PostgreSQL)或 ANALYZE TABLE(MySQL)就是手動叫它重新看清現實。你可以用 EXPLAIN 看最佳化器選了什麼:
EXPLAIN ANALYZE
SELECT u.name, o.amount
FROM users u JOIN orders o ON u.id = o.user_id
WHERE u.city = 'Taipei' AND o.amount > 10000;
-- 輸出會顯示:用了 Index Scan 還是 Seq Scan、
-- Hash Join 還是 Nested Loop、估算列數 vs 實際列數
當「估算列數」與「實際列數」差很多時,幾乎就是統計過期或資料分布有相關性(correlation)導致估算失準——這是調效能時的第一個檢查點。
MVCC:讓讀不擋寫、寫不擋讀
入門篇講過用鎖(lock)維持隔離性。但純鎖有個老問題:讀也要鎖。如果一個長時間的報表查詢鎖住一堆資料,所有想改這些資料的交易都得乾等——讀者和寫者互相卡死。現代主流資料庫(PostgreSQL、MySQL InnoDB、Oracle)幾乎都改用一套更聰明的機制:多版本並行控制(Multi-Version Concurrency Control, MVCC)。
MVCC 的核心想法只有一句:資料不是「就地覆寫」,而是每次更新都產生一個新版本,舊版本保留。每一列資料都帶著兩個隱藏欄位——「我從哪個交易開始存在」與「我在哪個交易之後失效」:
一列資料的多個版本(PostgreSQL 風格的 xmin/xmax):
版本1: amount=1000, xmin=100, xmax=150 ← 交易100建立、交易150改掉它
版本2: amount=2000, xmin=150, xmax=null ← 交易150建立、目前有效
當一個交易要讀資料時,它不問「現在這列是什麼」,而是問「對我這個交易可見的版本是哪一個」。每個交易啟動時會拿到一張快照(snapshot),記錄「此刻哪些交易已提交、哪些還在跑」。讀取時,資料庫沿著版本鏈找到「對這張快照而言已提交、且尚未被覆蓋」的那個版本。於是:
- 讀者永遠看到一個一致的快照,不會讀到別人寫到一半的東西,也不需要加鎖。
- 寫者建立新版本,不會阻擋正在讀舊版本的人。
這就是 MVCC 最迷人的成果:讀不擋寫、寫不擋讀。一個跑十分鐘的報表查詢,看到的是它開始那一刻的世界,完全不影響期間瘋狂寫入的線上交易。
代價是什麼?舊版本會堆積。被覆蓋或刪除的版本不會立刻消失(因為可能還有舊交易需要看它們),必須由背景程序回收——PostgreSQL 叫 VACUUM,InnoDB 叫 purge。如果有一個交易開著不關(idle in transaction)幾小時,它的快照會「釘住」一大堆舊版本不能被回收,造成資料膨脹(bloat)。這是進階學生用 MVCC 資料庫時最常踩的雷:長交易是 MVCC 的天敵。
隔離級別其實是「容許哪些異常」的選單
入門篇提過隔離性,但進階要看清一件事:SQL 標準的隔離級別不是用「鎖多嚴」定義的,而是用「容許出現哪些異常現象」定義的。三種經典異常:
髒讀 (Dirty Read):讀到別人還沒提交、可能會回滾的資料
不可重複讀 (Non-repeatable Read):同一交易裡讀同一列兩次,值變了
幻讀 (Phantom Read):同一交易裡跑同一個範圍查詢兩次,列數變了
四個隔離級別就是這些異常的「允許矩陣」:
| 隔離級別 | 髒讀 | 不可重複讀 | 幻讀 |
|---|---|---|---|
| 讀未提交 Read Uncommitted | 可能 | 可能 | 可能 |
| 讀已提交 Read Committed | 禁止 | 可能 | 可能 |
| 可重複讀 Repeatable Read | 禁止 | 禁止 | 可能* |
| 可序列化 Serializable | 禁止 | 禁止 | 禁止 |
(*標準允許幻讀,但 InnoDB 的 Repeatable Read 用 next-key lock 把幻讀也擋掉了——這是實作超出標準的例子。)
級別越高越安全,但代價是更多衝突、更多等待、甚至更多交易被迫中止重試。Serializable 保證並行執行的結果等同於某種「一個接一個跑」的順序,是唯一能完全消除所有並行異常的級別。現代資料庫用一種叫 SSI(Serializable Snapshot Isolation,可序列化快照隔離)的技術實作它:平時讓交易在 MVCC 快照上樂觀地跑,只在偵測到「危險的讀寫依賴環」時才中止其中一個。這比傳統的兩階段鎖定(2PL, two-phase locking)併發度高得多。
選隔離級別的本質,是在正確性與併發效能之間做工程取捨——這正是入門篇 ACID 概念落到實作時,真正要面對的細節。
當一台機器裝不下:CAP 定理畫出的物理邊界
到目前為止我們談的都是單機。但當資料大到一台機器裝不下、或你需要跨地理位置容錯時,資料庫必須分散到多台機器並互相複製(replication)。這裡有一條任何工程師都繞不過的鐵律:CAP 定理。
CAP 說,當分散式系統發生網路分區(Partition,P)——也就是機器之間通訊斷掉——時,你只能在兩件事之間二選一:
- 一致性(Consistency,C):每次讀都拿到最新寫入的值(所有節點看到同一份事實)。
- 可用性(Availability,A):每個請求都能拿到回應(系統不擺爛)。
注意常見迷思:CAP 不是「三選二、平時就要放棄一個」。在網路正常時,你可以同時擁有 C 和 A。CAP 真正的斷言是:一旦分區發生,你被迫在 C 和 A 之間取捨。
網路分區發生時,節點A 與 節點B 失聯:
選 CP(保一致性,犧牲可用性):
→ 拒絕服務或只讓多數派回應,寧可不回也不回錯的
→ 例:銀行轉帳,寧可暫停也不能出現「錢憑空變多」
選 AP(保可用性,犧牲一致性):
→ 兩邊都繼續服務,事後再合併(最終一致性)
→ 例:社群按讚數,短暫不一致無妨,先讓使用者能用
這直接影響到一個你會在業界反覆聽到的詞——最終一致性(eventual consistency):系統不保證「立刻一致」,但保證「只要停止寫入,最後所有副本會收斂到同一個值」。許多 NoSQL 系統(如早期的 DynamoDB、Cassandra)選 AP + 最終一致,換取極高的可用性與水平擴展能力;而堅持 CP 的系統(如傳統關聯式資料庫的同步複製)則在分區時寧可犧牲部分可用性。
更精緻的框架是 PACELC:它補上 CAP 沒講的部分——沒有分區(Else)時,你還要在延遲(Latency,L)與一致性(C)之間取捨。因為要讓所有副本同步確認一次寫入,本來就比「寫一個節點就回」更慢。所以完整的取捨是:「分區時 C 或 A,否則延遲或一致性」。這解釋了為什麼沒有「最好的資料庫」,只有「對你的工作負載做了正確取捨的資料庫」。
重點回顧
- 磁碟很慢是萬惡之源:資料庫以頁(page)為 I/O 單位、用 B+ 樹把樹高從 $\log_2 n$ 壓到 $\log_b n$,讓一億筆資料只需 3~4 次磁碟 I/O 就能定位。索引加速讀、但加重寫,是一種取捨。
- SQL 是宣告式的,所以需要成本基礎最佳化器靠統計與選擇度估算,從上百種執行計畫中挑最便宜的;統計過期會讓它做蠢決定,
EXPLAIN ANALYZE是你的診斷工具。 - MVCC 用「保留多版本 + 每個交易讀自己的快照」實現「讀不擋寫、寫不擋讀」,代價是舊版本需回收、長交易會造成膨脹。
- 隔離級別是「容許哪些異常」的選單(髒讀/不可重複讀/幻讀),是正確性與併發效能的工程取捨;Serializable 可由 SSI 高併發地實作。
- CAP 定理畫出物理邊界:網路分區時 C 與 A 不可兼得;PACELC 進一步指出無分區時還要在延遲與一致性間取捨。沒有最好的資料庫,只有取捨最合適的資料庫。
深入探討(研究所視角)
如果你想再往下挖,這裡是幾條通往研究與工業前沿的線索:
1. 儲存引擎的另一條路:LSM 樹 vs B+ 樹。 B+ 樹對「隨機寫」不友善——每次更新都可能造成隨機磁碟 I/O。LSM 樹(Log-Structured Merge Tree) 反其道而行:把所有寫入先累積在記憶體(memtable),滿了就循序刷到磁碟成不可變的 SSTable,再由背景把多層 SSTable 合併(compaction)。這把隨機寫換成循序寫,寫入吞吐量極高,代價是讀取可能要查多層、且有寫入放大(write amplification)。RocksDB、Cassandra、LevelDB 都建在 LSM 上。延伸閱讀可比較兩者的 RUM 猜想(Read-Update-Memory tradeoff):讀放大、寫放大、空間放大三者無法同時最佳化。
2. 預寫式日誌(WAL)與崩潰恢復的 ARIES 演算法。 入門篇的「持久性(Durability)」是怎麼在斷電時仍成立的?答案是 WAL(Write-Ahead Logging):任何資料頁被改之前,描述這次修改的日誌必須先落盤。崩潰後靠經典的 ARIES 三階段恢復——Analysis(找出崩潰時的狀態)、Redo(重做所有已記錄的修改達到崩潰前狀態)、Undo(回滾未提交的交易)。其中 redo 要冪等、用 LSN(Log Sequence Number) 判斷哪些修改已落盤的設計,是資料庫崩潰恢復的基石。
3. 分散式交易與共識:2PC 的困境與 Paxos/Raft。 跨節點的原子提交常用兩階段提交(2PC, Two-Phase Commit),但它有一個致命弱點——協調者在關鍵時刻掛掉會讓參與者永久阻塞(blocking)。要解決,就走向共識演算法:Paxos 與更易懂的 Raft 讓一群節點即使部分故障也能對「下一筆操作是什麼」達成一致。Google Spanner 更進一步,用 TrueTime(帶誤差界限的全球同步時鐘)實現跨資料中心的外部一致性(external consistency),逼近 CAP 中「在實務可接受的可用性下提供強一致」的極限。
4. Serializable 的理論底座:衝突可序列化與依賴圖。 為什麼 SSI 能高併發地保證可序列化?理論基礎是衝突可序列化(conflict serializability):把交易間的讀寫衝突畫成優先圖(precedence graph),一個排程可序列化 ⟺ 該圖無環。SSI 的洞見是:不可序列化的執行必然包含一種特定的「危險結構」(兩條反向的讀寫依賴邊形成的環),只要在執行期偵測並打斷它,就能保證結果可序列化——而不必像 2PL 那樣保守地全程加鎖。這條從「圖論性質」到「實際併發機制」的橋樑,是資料庫理論最漂亮的成果之一,值得花一個學期細讀。