
資料的數位表示(進階):二補數、IEEE 754 與錯誤更正
從 0.1 + 0.2 != 0.3 出發,拆解浮點數的位元解剖、二補數算術的硬體優雅、定點數與位元組順序的工程取捨,直到漢明碼如何把翻轉的位元自動修好。
為什麼 0.1 + 0.2 不等於 0.3?
如果你打開任何一台電腦的 Python 直譯器,輸入 0.1 + 0.2,你不會得到乾淨的 0.3,而是 0.30000000000000004。這不是 Python 的 bug,也不是你電腦壞了——它是浮點數(floating-point)表示方式的必然結果。入門篇告訴你「真實世界被編碼成位元」,這篇進階文章要回答的是:這個編碼究竟在每一個位元層級做了什麼?又會在哪裡悄悄出錯?
我們會深入三個入門篇刻意略過的硬核機制:二補數(two's complement)為何讓加減法電路如此優雅、IEEE 754 浮點數的次正規數(subnormal)與災難性抵消(catastrophic cancellation),以及當位元在傳輸中翻轉時,我們如何用編碼把錯誤「自動修好」。讀完後,你會用工程師的眼睛看待每一個 float。
二補數:把減法變成加法的魔術
入門篇可能告訴過你「負數用最高位元當符號位」。但如果真的只是「符號 + 數值」(這稱為 sign-magnitude 表示法),會產生兩個尷尬問題:存在 +0 與 -0 兩個零,而且加法電路必須先判斷符號再決定要加還是減。現代電腦幾乎一律改用二補數(two's complement),原因是它讓「減法」完全消失——CPU 只需要一個加法器。
二補數的定義很乾淨。對一個 $n$ 位元的數,最高位元的權重是負的 $-2^{n-1}$,其餘位元權重照常為正:
$$ \text{value} = -b_{n-1} \cdot 2^{n-1} + \sum_{i=0}^{n-2} b_i \cdot 2^i $$
以 8 位元為例,10000000 代表 $-128$,11111111 代表 $-1$,01111111 代表 $+127$。範圍是 $[-128, +127]$,不對稱(負數多一個),而且只有一個零。
動手算一下:用加法做減法
要計算 5 - 3,我們把它看成 5 + (-3)。求 -3 的二補數有個機械口訣:逐位元取反(NOT)後加 1。
3 的二進位: 0000 0011
逐位元取反: 1111 1100 (這是「一補數」)
加 1: 1111 1101 ← 這就是 -3
接著做加法:
0000 0101 (5)
+ 1111 1101 (-3)
-----------
1 0000 0010 ← 最高位的進位 (carry-out) 直接丟棄
結果:0000 0010 = 2 ✓
注意那個跑出去的進位被直接丟棄了。這不是偷吃步,而是二補數算術天生就在 $\bmod\ 2^n$ 的環(ring)上運作。我們可以用 Python 驗證這個「丟棄進位」的行為:
def to_twos_complement(value: int, bits: int = 8) -> str:
"""把整數轉成 bits 位元的二補數字串表示。"""
mask = (1 << bits) - 1 # 0b1111_1111
return format(value & mask, f'0{bits}b')
def add_twos_complement(a: int, b: int, bits: int = 8) -> int:
"""模擬硬體加法器:相加後遮罩、再依符號位元還原為帶號整數。"""
mask = (1 << bits) - 1
raw = (a + b) & mask # 丟棄超出 bits 的進位
if raw >> (bits - 1): # 最高位元為 1 → 負數
return raw - (1 << bits)
return raw
print(to_twos_complement(-3)) # 11111101
print(add_twos_complement(5, -3)) # 2
print(add_twos_complement(127, 1)) # -128 ← 溢位!
最後一行揭露了一個關鍵風險:127 + 1 得到的不是 128(超出範圍),而是 -128。這就是整數溢位(integer overflow)。硬體偵測它的方法很巧妙:若兩個同號數相加卻得到異號結果,即為溢位。等價地說,若「進入最高位的進位」與「離開最高位的進位」不相等,溢位旗標(overflow flag)就被設起。
算術右移與符號擴展
二補數還有一個漂亮性質:算術右移(arithmetic shift right) 等價於對負數做向下取整的除以 2。右移時用符號位元填補空出的高位(稱為 sign extension),而不是補 0:
# Python 整數無限長,>> 本身就是算術右移
print(-8 >> 1) # -4
print(-7 >> 1) # -4 ← 向下取整(floor),不是 -3.5 截斷成 -3
# 對比:把同一個位元組當成無號數,邏輯右移
print((-7 & 0xFF) >> 1) # 124,意義完全不同
這個細節在實作高效能除法、定點數運算時極為重要,也是初學者最常踩的雷:負數除以 2 的冪不是單純截斷。
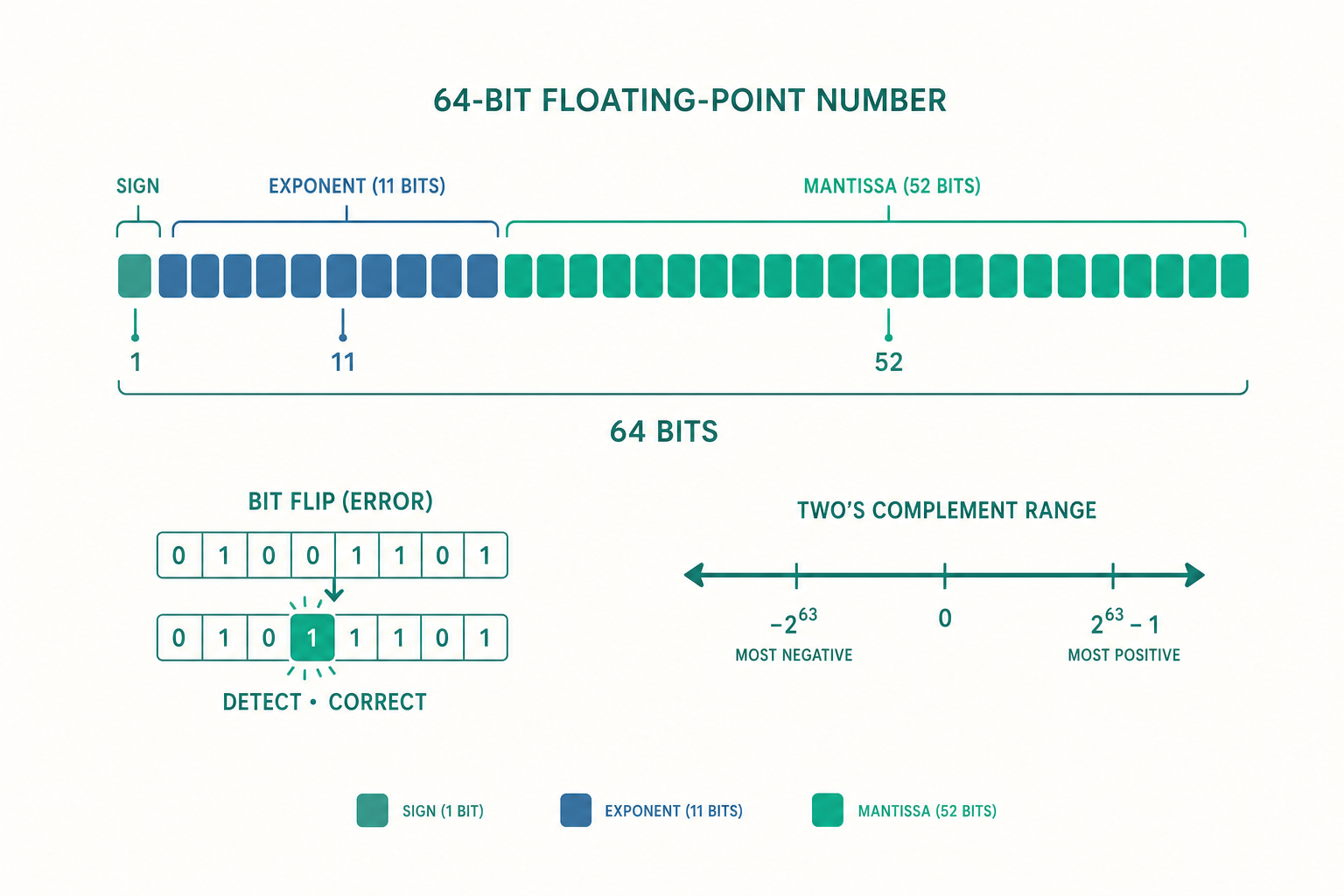
IEEE 754:浮點數的解剖學
入門篇大概提過浮點數有「符號、指數、尾數」三部分。現在我們把它拆到位元。以最常見的 64 位元雙精度(double / binary64)為例:
| 欄位 | 位元數 | 說明 |
|---|---|---|
| 符號 sign | 1 | 0 為正、1 為負 |
| 指數 exponent | 11 | 帶偏移量(bias = 1023) |
| 尾數 mantissa | 52 | 隱含開頭的 1(normalized) |
對一個正規化(normalized)的數,其值為:
$$ (-1)^{s} \times 1.\underbrace{f_{51}f_{50}\cdots f_0}_{52\text{ 位尾數}} \times 2^{(e - 1023)} $$
注意那個 隱含的前導 1(implicit leading bit):正規化的科學記號小數點前永遠是 1,既然永遠是 1,就不必存——這替我們省下一個位元的精度。
看一個例子:把 0.1 拆到骨頭
0.1 在十進位是有限小數,但在二進位是無限循環小數 $0.0001100110011\ldots_2$,就像 $1/3$ 在十進位無法寫盡一樣。我們來看電腦實際存了什麼:
from decimal import Decimal
# Decimal 會顯示 float 真正存下來的精確值
print(Decimal(0.1))
# 0.1000000000000000055511151231257827021181583404541015625
print(Decimal(0.1) + Decimal(0.2))
# 0.3000000000000000166533453693773481063544750213623046875
# 而 0.3 自己存下來的值又略低
print(Decimal(0.3))
# 0.299999999999999988897769753748434595763683319091796875
0.1 與 0.2 各自被四捨五入到最接近的可表示值,兩個誤差累加後,剛好越過了 0.3 的可表示值——這就是 0.1 + 0.2 != 0.3 的全部真相。這不是隨機誤差,而是完全確定的捨入。
正確的比較方式不是 ==,而是檢查差距是否在容忍範圍內:
import math
print(math.isclose(0.1 + 0.2, 0.3, rel_tol=1e-9)) # True
次正規數、無窮與 NaN:指數欄位的玄機
11 位元的指數理論上能存 0 到 2047,但 IEEE 754 保留了兩個極端值作特殊用途:
- 指數全為 0:代表 0,或次正規數(subnormal / denormal)。此時隱含前導位元改為 0,讓我們能表示比最小正規數更接近 0 的數,實現「漸進下溢(gradual underflow)」,避免精度突然崩到 0。
- 指數全為 1(2047):尾數為 0 代表 $\pm\infty$;尾數非 0 代表 NaN(Not a Number),例如
0/0或 $\sqrt{-1}$ 的結果。
import struct
def bits_of(x: float) -> str:
"""印出 double 的 64 位元原始表示。"""
(raw,) = struct.unpack('>Q', struct.pack('>d', x))
return format(raw, '064b')
print(bits_of(0.0)) # 全 0
print(bits_of(-0.0)) # 只有符號位是 1 → 負零真的存在!
print(bits_of(float('inf')))
print(bits_of(float('nan')))
# NaN 的詭異性質:它不等於任何東西,包括自己
nan = float('nan')
print(nan == nan) # False
print(nan != nan) # True ← 常被用來偵測 NaN
-0.0 的存在不是無聊的細節:在某些數值演算法中(例如複數對數的分支切割),正零與負零會導向不同的正確結果。
災難性抵消:精度如何瞬間蒸發
浮點數最危險的陷阱不是「小誤差」,而是災難性抵消(catastrophic cancellation):當兩個非常接近的數相減時,它們相同的高位元互相抵消,結果只剩下原本就不精確的低位元,相對誤差被放大成千上萬倍。
# 計算二次方程式 x^2 - 200000x + 1 = 0 的較小根
# 標準公式 (-b - sqrt(b^2-4ac))/2a 沒問題,但較大根用
# (-b + sqrt(...))/2a 會發生抵消
import math
b = -200000.0
disc = math.sqrt(b*b - 4*1*1)
naive = (-b - disc) / 2 # 兩個約 200000 的數相減
print(naive) # 5.0000000414e-06,誤差很大
# 改用數值穩定公式:x1 * x2 = c/a,先算大根再回推
big_root = (-b + disc) / 2
stable = 1.0 / big_root # 用乘積關係避開相減
print(stable) # 5.00000000000e-06,精確得多
這個例子的教訓是:數學上等價的兩個公式,數值上可能天差地遠。數值分析(numerical analysis)這門學問的核心,正是設計能避開抵消、維持條件數(condition number)的演算法。
定點數與位元組順序:被忽視的兩個面向
定點數(fixed-point):嵌入式世界的選擇
浮點運算單元(FPU)耗電且佔晶片面積。在微控制器、DSP、甚至某些深度學習推論晶片上,工程師改用定點數(fixed-point):用整數儲存,但約定好「小數點固定在第幾位元」。常見的 Qm.n 格式表示整數部 m 位、小數部 n 位。
# Q16.16 定點數:用 32 位元整數,低 16 位元代表小數
SCALE = 1 << 16 # 65536
def to_fixed(x: float) -> int:
return round(x * SCALE)
def from_fixed(v: int) -> float:
return v / SCALE
a = to_fixed(3.14)
b = to_fixed(2.0)
# 定點加法 = 直接整數相加
print(from_fixed(a + b)) # 5.14
# 定點乘法:相乘後要右移回 scale(否則小數位會疊加)
prod = (a * b) >> 16
print(from_fixed(prod)) # 6.28(約值,受 16 位元小數精度限制)
定點數的好處是誤差行為完全可預測(每個運算的精度是固定的、線性的),代價是動態範圍(dynamic range)小——它無法像浮點數那樣同時表示 $10^{-30}$ 與 $10^{30}$。
位元組順序(endianness):同樣的數,不同的排列
當一個多位元組整數要存進記憶體或送上網路時,它的位元組該由高到低排(big-endian)還是由低到高排(little-endian)?x86 與大多數 ARM 用 little-endian,而網路協定(TCP/IP)的標準是 big-endian(俗稱 network byte order)。搞錯了,1 會變成 16777216。
import struct
n = 0x01020304
print(struct.pack('>I', n).hex()) # 01020304 big-endian
print(struct.pack('<I', n).hex()) # 04030201 little-endian
# 跨機器傳資料時務必明確指定位元組順序
import socket
print(socket.htonl(n) == struct.unpack('<I', struct.pack('>I', n))[0]) # True on little-endian host
這也是為什麼可攜的二進位檔案格式(如 PNG、PDF)都會在規格中明文規定 byte order——資料的「意義」不只取決於位元值,還取決於它們被讀取的順序。
重點回顧
- 二補數讓最高位元帶負權重 $-2^{n-1}$,使減法化為加法、消除 $\pm 0$ 的歧義,溢位由「最高位進位是否一致」偵測。
- IEEE 754 用「隱含前導 1 + 帶偏移指數」編碼浮點數;指數全 0 給次正規數、全 1 給 $\infty$ 與 NaN。
-0.0與nan != nan都是規格的一部分。 0.1 + 0.2 != 0.3是確定性的捨入,不是隨機誤差;浮點數比較要用math.isclose而非==。- 災難性抵消會在兩個相近數相減時放大相對誤差;數學等價的公式在數值上可能天差地遠。
- 定點數犧牲動態範圍換取可預測精度與低功耗;位元組順序決定多位元組資料在記憶體與網路上的排列,必須明確約定。
深入探討(研究所視角)
單位捨入誤差與向後穩定性。 浮點運算的理論基礎是機器 epsilon $u = 2^{-53} \approx 1.11 \times 10^{-16}$(雙精度)。標準浮點模型假設每個基本運算滿足 $\text{fl}(a \circ b) = (a \circ b)(1 + \delta)$,其中 $|\delta| \le u$。在此模型下,一個演算法是否可靠取決於它是否向後穩定(backward stable)——亦即計算結果是某個「略受擾動的輸入」的精確解。Wilkinson 對 LU 分解與 QR 分解的向後誤差分析(backward error analysis)奠定了整個科學計算的可信度基礎,也解釋了為何高斯消去法需要部分主元選取(partial pivoting)來控制成長因子(growth factor)。
錯誤更正碼(error-correcting codes)。 當位元在儲存或傳輸中翻轉,我們不只要偵測還要更正。最小的例子是漢明碼(Hamming code):在 7 個位元中嵌入 4 個資料位元與 3 個同位檢查位元,任兩個合法碼字(codeword)的漢明距離(Hamming distance)至少為 3,因此能更正任意單一位元錯誤。其本質是在 $\{0,1\}^7$ 的向量空間中,讓合法碼字構成一個線性子空間,校驗子(syndrome)$H \mathbf{r}^\top$ 直接指出出錯的位元位置。
# 漢明 (7,4) 解碼:用校驗矩陣計算 syndrome 定位錯誤
H = [[0,0,0,1,1,1,1],
[0,1,1,0,0,1,1],
[1,0,1,0,1,0,1]]
def decode(received):
r = list(received)
s = [sum(H[i][j]*r[j] for j in range(7)) % 2 for i in range(3)]
pos = s[0]*4 + s[1]*2 + s[2] # syndrome 的二進位值 = 出錯位置(1-indexed)
if pos:
r[pos-1] ^= 1 # 翻回正確值
return r
print(decode([1,0,1,1,0,1,0])) # 自動更正單一位元錯誤
現代系統把這個思想推到極致:DRAM 的 ECC 記憶體用 SECDED 碼、固態硬碟用 LDPC 碼、行動通訊與深空通訊用 Reed–Solomon 與 Turbo/Polar 碼,逼近 Shannon 通道容量極限。值得思考的延伸問題是:資料表示的「冗餘(redundancy)」與「壓縮」其實是同一枚硬幣的兩面——壓縮(如 Huffman、算術編碼)盡可能逼近資訊熵 $H(X) = -\sum p(x)\log_2 p(x)$ 去除冗餘,而錯誤更正則刻意加回結構化冗餘。理解這個張力,是進入資訊理論(information theory)與編碼理論(coding theory)的入口。