
遞迴
從鏡中鏡到呼叫堆疊:拆解問題、自我呼叫,與何時會爆堆疊
如果你站在兩面鏡子之間
你大概有過這個經驗:站在理髮店或更衣室兩面相對的鏡子之間,影像會一層層往深處延伸——鏡中有鏡、鏡中又有鏡,看似無窮無盡。每一層影像,都是「同一個畫面」在更小的尺度上重複一次。
電腦科學裡有一種解題思維與此驚人地相似:把一個大問題,拆解成「規模更小、但形式完全一樣」的子問題,再讓同一套方法不斷往下套用,直到問題小到可以一眼看出答案為止。這種「函式自己呼叫自己」的技巧,就叫做遞迴(recursion)。
它乍看像在繞圈圈、像會無止盡地循環下去,但只要設計正確,遞迴反而是許多問題最乾淨、最貼近人類直覺的寫法。本文就帶你拆解遞迴的骨架,看清它在記憶體裡到底發生了什麼事,並理解它何時優雅、何時危險。
遞迴的兩個必要零件
一個正確的遞迴,永遠由兩個部分組成,缺一不可:
- 基底情形(base case):問題小到不需要再拆解、可以直接給出答案的情況。它是遞迴的「煞車」,沒有它,函式就會一直呼叫自己直到資源耗盡。
- 遞迴情形(recursive case):把目前的問題化簡成「規模更小、但結構相同」的子問題,再呼叫自己去解決那個子問題。
關鍵在於:每一次遞迴,都必須讓問題確實朝著基底情形前進。如果你呼叫自己時問題沒有變小(例如算 $n$ 時又去算 $n$),那就會永遠停不下來。
我們用最經典的階乘(factorial)來看這個骨架。階乘的定義是 $n! = n \times (n-1) \times \cdots \times 2 \times 1$,而且數學上規定 $0! = 1$。把它寫成遞迴定義會非常自然:
$$ n! = \begin{cases} 1 & \text{若 } n = 0 \\ n \times (n-1)! & \text{若 } n > 0 \end{cases} $$
對應的 Python 程式幾乎是定義的直譯:
def factorial(n):
if n == 0: # 基底情形:直接回答
return 1
return n * factorial(n - 1) # 遞迴情形:問題縮小為 n-1
注意這支函式怎麼滿足兩個要件:n == 0 時直接回傳 1(煞車住了),其餘情況都把問題從 n 縮小成 n - 1,保證一步步逼近 0。
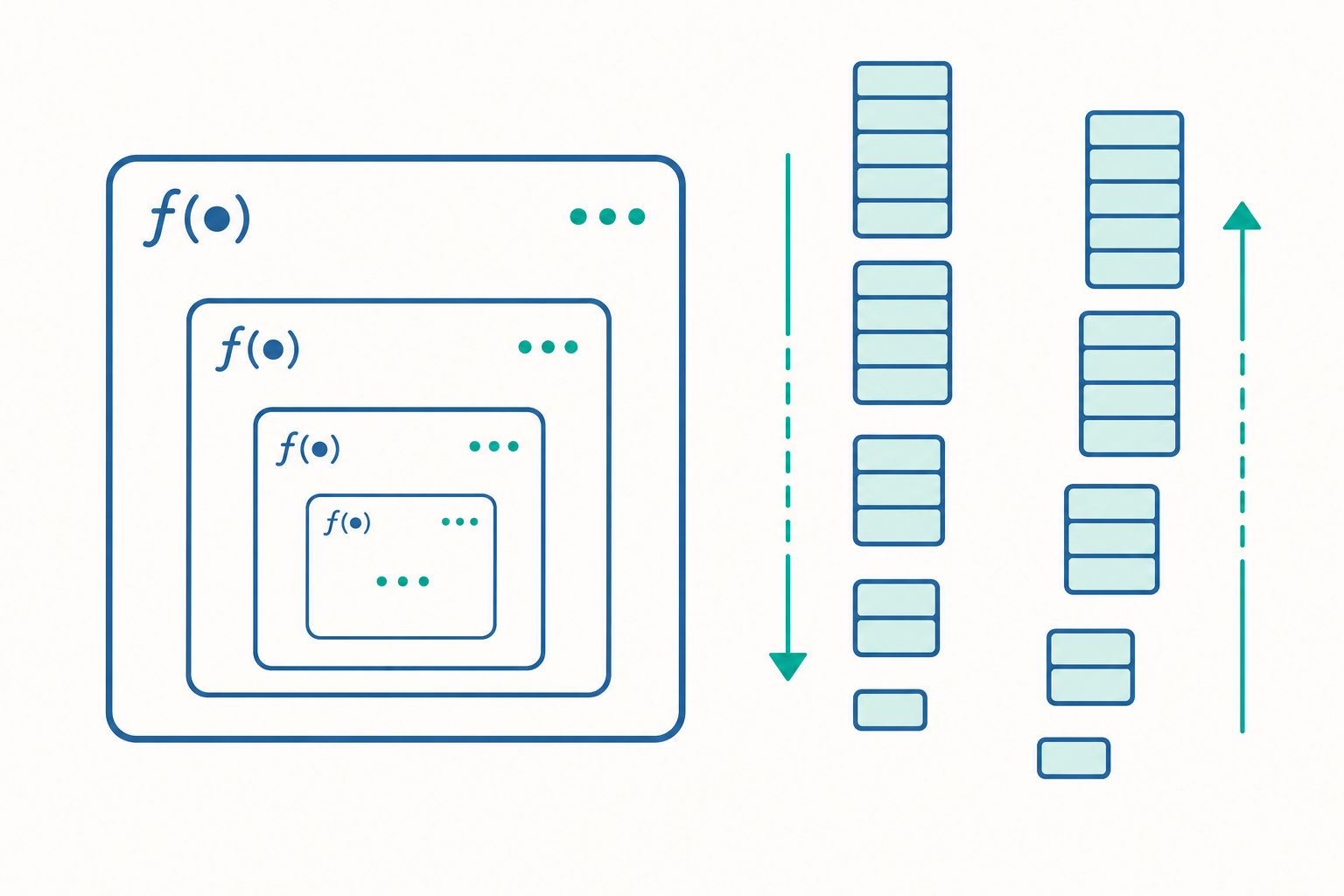
呼叫堆疊:遞迴在記憶體裡的真面目
很多人覺得遞迴「很玄」,是因為看不到它執行時的內部狀態。其實,理解遞迴的鑰匙只有一個概念:呼叫堆疊(call stack)。
每當一個函式被呼叫,系統就會在堆疊上放一個堆疊框(stack frame),裡面存著這次呼叫的區域變數、參數,以及「算完後要回到哪一行」的返回位址。函式回傳時,它的框就被彈出,控制權交還給呼叫它的人。堆疊遵守「後進先出(LIFO)」的規則——最後堆上去的,最先被拿下來。
遞迴只是把這個機制用到極致:factorial(3) 還沒算完,就得先等 factorial(2);factorial(2) 又得等 factorial(1)……這些「半成品」全部疊在堆疊上等待。我們把 factorial(3) 的執行過程攤開來看:
動手看一個例子:factorial(3) 的堆疊
呼叫往下展開時,堆疊愈疊愈高(每一行是一個尚未完成的框):
呼叫 factorial(3)
→ 需要 3 * factorial(2),先把 factorial(2) 堆上去
→ 需要 2 * factorial(1),先把 factorial(1) 堆上去
→ 需要 1 * factorial(0),先把 factorial(0) 堆上去
→ factorial(0) = 1 ← 觸發基底情形,開始回傳
碰到基底情形後,堆疊開始「回捲」,一層層把結果往上交還:
factorial(0) 回傳 1
factorial(1) = 1 * 1 = 1 ← 框彈出
factorial(2) = 2 * 1 = 2 ← 框彈出
factorial(3) = 3 * 2 = 6 ← 框彈出,最終答案
我們可以用一張表記錄「展開」與「回捲」兩個階段:
| 階段 | 目前計算 | 等待的子問題 | 堆疊深度 |
|---|---|---|---|
| 展開 | factorial(3) | factorial(2) | 1 |
| 展開 | factorial(2) | factorial(1) | 2 |
| 展開 | factorial(1) | factorial(0) | 3 |
| 觸底 | factorial(0) | 無(回傳 1) | 4 |
| 回捲 | factorial(1) | 1 × 1 = 1 | 3 |
| 回捲 | factorial(2) | 2 × 1 = 2 | 2 |
| 回捲 | factorial(3) | 3 × 2 = 6 | 1 |
看懂這張表,你就掌握了遞迴的全部祕密:它不是魔法,只是堆疊的自動展開與回捲。
當遞迴遇上分岔:費氏數列
階乘每次只呼叫自己一次,路徑是一條直線。但有些問題,每一步會岔出多次遞迴呼叫,這時遞迴的形狀就從「線」變成「樹」。
費氏數列(Fibonacci sequence)是經典例子:每一項是前兩項之和,定義為
$$ F(n) = \begin{cases} n & \text{若 } n \le 1 \\ F(n-1) + F(n-2) & \text{若 } n > 1 \end{cases} $$
直譯成遞迴:
def fib(n):
if n <= 1:
return n
return fib(n - 1) + fib(n - 2)
這支函式正確又漂亮,但藏著一個效能陷阱。算 fib(5) 時,fib(3) 會被算兩次、fib(2) 被算三次……同一個子問題被重複計算,呼叫次數隨 $n$ 指數成長,時間複雜度高達 $O(2^n)$。當 $n$ 稍大(例如 50),它就會慢到難以忍受。
這不是遞迴的錯,而是「天真的遞迴沒有記住已算過的答案」。解法是記憶化(memoization):用一個快取(cache)把算過的結果存起來,下次直接取用,複雜度立刻降回 $O(n)$。
def fib(n, memo={}):
if n <= 1:
return n
if n in memo: # 算過就直接回傳
return memo[n]
memo[n] = fib(n - 1, memo) + fib(n - 2, memo)
return memo[n]
這裡的啟示是:遞迴讓你「正確地」描述問題,但要寫得「有效率」,往往還需要搭配其他技巧。
遞迴最閃耀的舞台:河內塔
有些問題用迴圈寫會讓人頭痛,用遞迴卻幾乎是「把規則照抄一遍」。河內塔(Tower of Hanoi)就是教科書級的代表。
規則是:有三根柱子,起點柱上疊著 $n$ 個由大到小的圓盤,你要把整疊搬到目標柱,過程中(1)一次只能搬一個盤,(2)大盤永遠不能壓在小盤上。
直接想「具體怎麼搬」會很混亂,但換成遞迴思維就豁然開朗。要把 $n$ 個盤從「起點」搬到「目標」(借助「輔助」柱),只需三步:
- 把上面 $n-1$ 個盤,從「起點」搬到「輔助」柱(這是規模更小的同一個問題)。
- 把最大的第 $n$ 個盤,直接從「起點」搬到「目標」。
- 把那 $n-1$ 個盤,從「輔助」搬到「目標」(又是同一個問題)。
def hanoi(n, source, target, auxiliary):
if n == 1: # 基底:只剩一個盤,直接搬
print(f"把盤 1 從 {source} 搬到 {target}")
return
hanoi(n - 1, source, auxiliary, target) # 步驟 1
print(f"把盤 {n} 從 {source} 搬到 {target}") # 步驟 2
hanoi(n - 1, auxiliary, target, source) # 步驟 3
我們完全沒有去想「第幾步該搬哪個盤」這種繁瑣細節,只是把規則用遞迴描述出來,程式就自動產生了正確的搬移順序。可以證明搬 $n$ 個盤需要 $2^n - 1$ 步,這也說明了為什麼盤數一多,所需步驟會爆炸性增加。
遞迴 vs 迭代:兩種等價的思路
任何遞迴都可以改寫成迭代(iteration,即迴圈),反之亦然——它們在計算能力上是等價的。差別在於表達方式與執行成本。
以階乘為例,迭代版本是這樣:
def factorial_iter(n):
result = 1
for i in range(2, n + 1):
result *= i
return result
我們把兩者攤開比較:
| 面向 | 遞迴 | 迭代 |
|---|---|---|
| 可讀性 | 貼近數學定義、自然描述「自相似」問題 | 對線性流程直觀,分岔問題易混亂 |
| 記憶體 | 每層呼叫佔一個堆疊框,可能堆很深 | 通常只用固定幾個變數 |
| 速度 | 有函式呼叫的額外開銷 | 一般較快 |
| 適用 | 樹狀/分治問題(河內塔、走訪樹)優雅 | 簡單累加、計數類問題俐落 |
經驗法則:當問題本身具有「自相似、可分而治之」的結構(樹的走訪、分治演算法、回溯搜尋),遞迴往往最清晰;當問題是單純的線性累積,迭代通常更省資源。兩者沒有絕對優劣,是依問題形狀做選擇。
危險的深淵:何時會爆堆疊
遞迴最常見、也最致命的問題是堆疊溢位(stack overflow)。前面說過,每一層遞迴都會佔用一個堆疊框,而堆疊的空間是有限的。如果遞迴太深,框會一路堆到塞滿堆疊空間,程式就會崩潰。常見原因有兩種:
- 忘了基底情形,或基底永遠碰不到:例如寫
factorial(n)卻沒處理n == 0,或遞迴時問題沒真正變小,於是無限往下呼叫。 - 遞迴深度本來就太大:即使邏輯正確,若 $n$ 高達數萬、數十萬,堆疊深度也可能超過上限。Python 預設的遞迴深度上限約為 1000 層,超過就會丟出
RecursionError。
def boom(n):
return boom(n + 1) # 問題不斷變大,永遠碰不到基底 → 必爆堆疊
# boom(1) # RecursionError: maximum recursion depth exceeded
防禦之道很簡單:寫遞迴時,第一件事就是確認基底情形存在且必然會被觸發,並且每次呼叫都讓問題嚴格變小。 對於深度可能很大的情況,往往會改用迭代,或借助一個明確的堆疊資料結構來手動模擬遞迴,避開系統堆疊的限制。
重點回顧
- 遞迴是「函式呼叫自己」,必須同時具備基底情形(停止條件)與遞迴情形(縮小問題並自我呼叫),且每次呼叫都要朝基底情形前進。
- 遞迴的執行靠呼叫堆疊完成:呼叫時堆框(展開),碰到基底後逐層回傳(回捲),整個過程遵守後進先出。
- 階乘是線性遞迴、費氏是分岔遞迴、河內塔展示了遞迴在分治問題上的優雅;天真的費氏遞迴是 $O(2^n)$,需用記憶化降到 $O(n)$。
- 遞迴與迭代計算能力等價:自相似/分治問題用遞迴清晰,線性累積用迭代省資源。
- 缺少正確基底情形,或遞迴過深,都會導致堆疊溢位;寫遞迴前先確保煞車存在且問題嚴格遞減。
深入探討(研究所視角)
尾遞迴最佳化
回頭看階乘的遞迴:return n * factorial(n - 1)。這裡函式回傳前,還要「等子呼叫算完,再乘上 n」——也就是說,呼叫自己不是這一層做的最後一件事,後面還有乘法在等。這種形式無法省去堆疊框,因為每一層都得保留 n 以便回捲時相乘。
但我們可以改寫成尾遞迴(tail recursion):把累積的結果當成參數一路傳下去,讓遞迴呼叫成為函式體中最後一個動作,回傳後不再有任何待辦運算:
def factorial_tail(n, acc=1):
if n == 0:
return acc
return factorial_tail(n - 1, n * acc) # 遞迴呼叫是最後動作,無待辦運算
當遞迴呼叫處於「尾位置(tail position)」時,這一層的堆疊框其實已經沒有用處——它沒有任何要在子呼叫返回後執行的事。於是某些編譯器/直譯器會做尾呼叫消除(tail call elimination),直接複用當前堆疊框而不新增一層,把遞迴在底層轉成迴圈執行。如此一來,深度再大也只佔 $O(1)$ 的堆疊空間,徹底免疫堆疊溢位。
需要提醒的是:尾遞迴最佳化是語言實作層級的特性。Scheme 等語言規格強制要求支援,許多函數式語言(如 Haskell、Scala 某些情境)也支援,但 CPython(標準 Python)刻意不做這項最佳化,理由是保留完整的堆疊追蹤資訊以利除錯。因此上面的 factorial_tail 在 Python 中並不會真的省下堆疊——這是一個重要的觀念與實作落差。
遞迴關係式的求解
遞迴不只是寫程式的技巧,更是分析演算法成本的核心工具。一個遞迴演算法的執行時間,往往可以寫成一條遞迴關係式(recurrence relation):把規模 $n$ 的成本,用更小規模的成本表示出來。
以二分搜尋為例,每次把問題砍半,外加常數時間的比較:
$$ T(n) = T(n/2) + O(1) $$
合併排序則把問題分成兩半各自排序,再花線性時間合併:
$$ T(n) = 2\,T(n/2) + O(n) $$
要從這種式子求出封閉形式的複雜度,常用的工具是主定理(Master Theorem)。對於形如 $T(n) = a\,T(n/b) + f(n)$ 的關係式(其中 $a \ge 1$、$b > 1$),它比較 $f(n)$ 與 $n^{\log_b a}$ 的成長速度來決定結果。套用到合併排序,$a = 2$、$b = 2$,故 $n^{\log_b a} = n^1 = n$,恰與合併成本 $f(n) = O(n)$ 同階,落在主定理的「平衡情形」,得出
$$ T(n) = O(n \log n)。 $$
這正解釋了合併排序為何是 $O(n \log n)$。另一種直觀的求解方式是遞迴樹(recursion tree):把每一層遞迴的成本畫成樹的一層,加總所有層的成本——對合併排序,每一層的總成本都是 $O(n)$,共有 $\log n$ 層,總和自然是 $O(n \log n)$。
連結到更廣的圖景
遞迴關係式的求解,把「遞迴」這個程式結構,與「分治法(divide and conquer)」這個演算法設計範式、以及「複雜度分析」這個理論層面緊密縫合在一起。再往前一步,記憶化遞迴正是動態規劃(dynamic programming)的雛形——當子問題重疊時,「由上而下的記憶化遞迴」與「由下而上的迭代填表」是同一枚硬幣的兩面。理解了遞迴如何展開、如何被分析、如何被最佳化,你就握住了通往這些進階主題的鑰匙。