
Python 字串處理:從雜亂資料到乾淨輸出
從建立、索引切片到不可變性、f-string 與常用方法,動手掌握文字處理的核心工具
從一份雜亂的學生名單開始
假設你拿到一份從表單匯出的學生名單,每一行長得像這樣:「 王小明 , [email protected] 」。前後有多餘的空白,逗號兩側對齊得亂七八糟,有人的信箱還大小寫混雜。你的任務是把它整理成乾淨的「姓名 + 信箱」格式。
這正是字串處理(string processing)在真實世界裡最常見的樣貌:資料很少一開始就是乾淨的。學會操控字串,等於拿到了一把處理文字資料的瑞士刀。這篇文章會帶你從零開始,邊讀邊動手,最後你就能寫出整理上面那份名單的程式。
字串是什麼:建立與基本樣貌
在 Python 裡,字串(string)是一串字元組成的序列。建立字串最直接的方式,就是用引號把文字包起來。單引號與雙引號完全等價:
name = '王小明'
email = "[email protected]"
print(name, email)
# 輸出:王小明 [email protected]
當文字本身含有引號時,混用兩種引號可以避免麻煩:
sentence = "他說:'今天天氣真好'"
print(sentence)
# 輸出:他說:'今天天氣真好'
如果要寫跨越多行的文字,使用三引號(''' 或 """):
poem = """床前明月光,
疑是地上霜。"""
print(poem)
# 輸出:
# 床前明月光,
# 疑是地上霜。
字串的長度用內建函式 len() 取得,它計算的是字元數量:
print(len('Uedu優學院'))
# 輸出:6
注意「Uedu優學院」總共是 6 個字元(4 個英文字母加 2 個中文字),Python 3 的字串以 Unicode 字元為單位計數,中文字和英文字母一樣,每個都算 1。這點和某些語言以位元組(byte)計數很不一樣,我們會在深入段再細談。
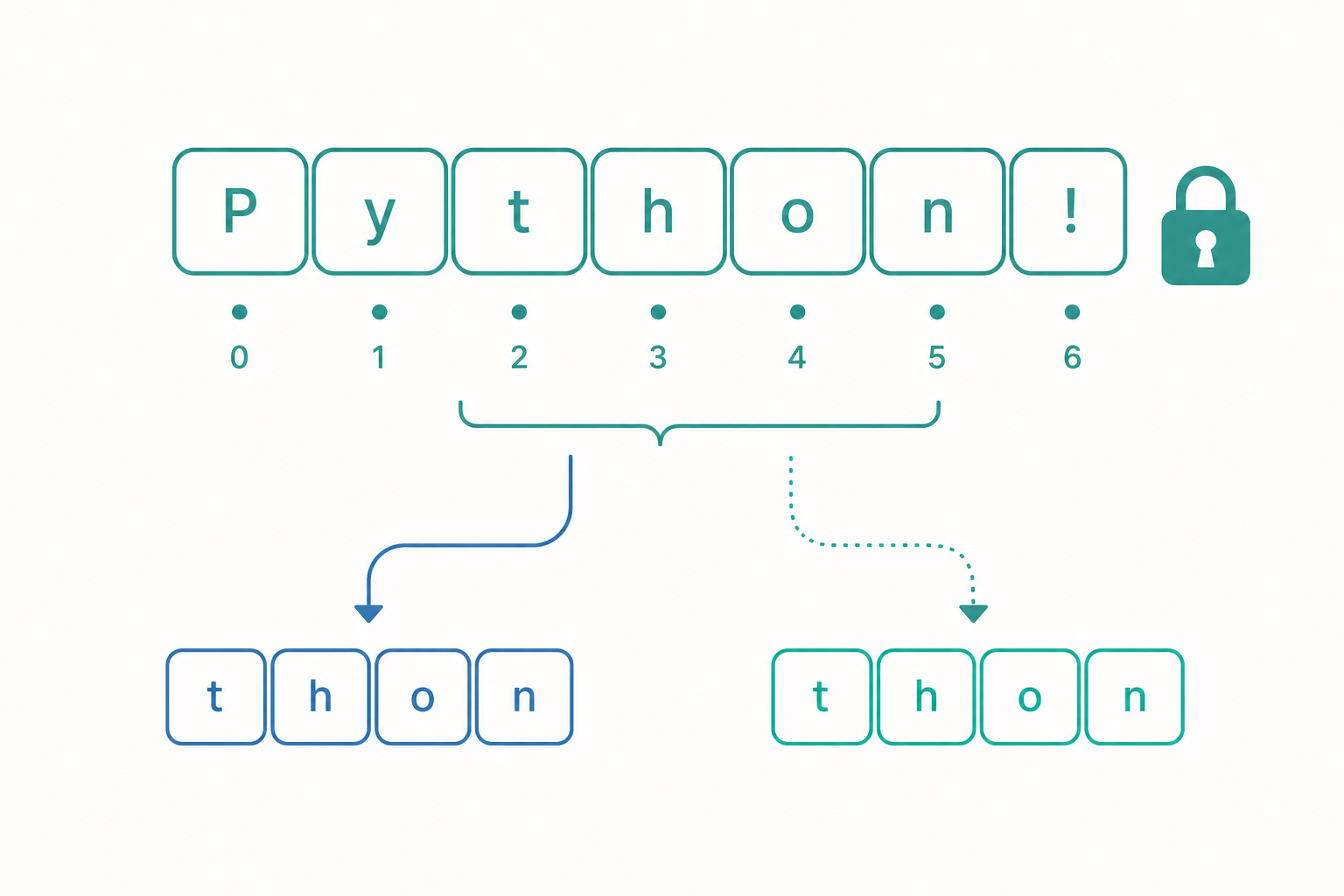
索引與切片:精準取出你要的部分
字串是有序的序列,每個字元都有一個位置編號,稱為索引(index)。索引從 0 開始:
s = 'Python'
print(s[0]) # 第一個字元
print(s[5]) # 第六個字元
# 輸出:P
# 輸出:n
Python 還支援負索引,從尾端往回數,-1 代表最後一個字元:
s = 'Python'
print(s[-1]) # 最後一個
print(s[-2]) # 倒數第二個
# 輸出:n
# 輸出:o
如果想一次取出一段連續的字元,就用切片(slicing),語法是 s[start:stop],取得的範圍包含 start 但不包含 stop(左閉右開):
s = 'Python'
print(s[0:3]) # 索引 0、1、2
print(s[2:]) # 從索引 2 到結尾
print(s[:4]) # 從開頭到索引 3
# 輸出:Pyt
# 輸出:thon
# 輸出:Pyth
切片還能加上第三個參數 step(步長),s[::2] 表示每隔一個字元取一次,而 s[::-1] 是一個常見的反轉字串技巧:
s = 'Python'
print(s[::2]) # 每隔一個取
print(s[::-1]) # 反轉
# 輸出:Pto
# 輸出:nohtyP
切片有個貼心之處:即使索引超出範圍也不會報錯,它會盡量取到能取的部分。但單一索引超出範圍(如 s[100])就會丟出 IndexError,這是初學者常見的陷阱。
不可變性:字串「不能被修改」
這是 Python 字串最重要、卻最容易被忽略的特性:字串是不可變的(immutable)。一旦建立,你就不能改動它裡面的任何字元。試著用索引賦值會直接報錯:
s = 'Python'
s[0] = 'J'
# 輸出:TypeError: 'str' object does not support item assignment
那如果我真的想「把 P 換成 J」怎麼辦?答案是:建立一個新字串。所有看似「修改字串」的操作,本質上都是產生新字串,原字串紋風不動:
s = 'Python'
new_s = 'J' + s[1:]
print(s) # 原字串沒變
print(new_s) # 這是全新的字串
# 輸出:Python
# 輸出:Jython
理解不可變性能幫你避開一個真實的效能陷阱。如果你在迴圈裡用 += 不斷累加字串,每一次都會建立一個全新字串並複製舊內容,效率很差。慣例做法是先收集到串列(list),最後再用 join 一次組合(下一節會講 join)。不可變性背後還有更深的設計考量,我們留到深入段。
f-string:組裝字串最現代的方式
把變數嵌進字串裡,是寫程式時天天都在做的事。Python 3.6 以後,最推薦的寫法是 f-string(格式化字串字面值,formatted string literal)。只要在引號前加一個 f,就能在大括號 {} 裡直接放入變數或運算式:
name = '王小明'
score = 92
print(f'{name}的分數是 {score} 分')
# 輸出:王小明的分數是 92 分
大括號裡可以放任何運算式,甚至呼叫函式:
price = 100
print(f'打八折後是 {price * 0.8} 元')
print(f'名字長度:{len("Uedu")}')
# 輸出:打八折後是 80.0 元
# 輸出:名字長度:4
f-string 還支援格式規格,例如控制小數位數、對齊、補零。冒號後面寫格式:
pi = 3.14159
print(f'圓周率約為 {pi:.2f}') # 保留兩位小數
print(f'{42:05d}') # 補零到 5 位
# 輸出:圓周率約為 3.14
# 輸出:00042
相較於老式的 % 格式化或 str.format(),f-string 更短、更易讀,而且效能更好,是目前的首選寫法。請養成用它的習慣。
常用方法:字串自己就會做的事
字串物件內建大量好用的方法。記住一個關鍵:因為字串不可變,這些方法全都「回傳新字串」,不會改動原物件。以下是處理資料時最常用的幾個。
split 把字串依分隔符切成串列;join 反過來,把串列用指定字串黏起來:
line = '王小明,[email protected],大二'
parts = line.split(',')
print(parts)
# 輸出:['王小明', '[email protected]', '大二']
joined = ' | '.join(parts)
print(joined)
# 輸出:王小明 | [email protected] | 大二
strip 去除字串前後的空白(或指定字元),lstrip、rstrip 分別只處理左邊或右邊:
messy = ' hello '
print(f'[{messy.strip()}]')
# 輸出:[hello]
replace 把所有出現的子字串換成另一個;lower 與 upper 轉換大小寫:
s = 'Uedu優學院 Uedu平台'
print(s.replace('Uedu', '優'))
print('[email protected]'.lower())
# 輸出:優優學院 優平台
# 輸出:[email protected]
find 回傳子字串第一次出現的索引,找不到回傳 -1(不會報錯);想判斷「有沒有包含」時,更 Python 風格的寫法其實是用 in 運算子:
s = '[email protected]'
print(s.find('@')) # @ 在索引 4
print(s.find('xyz')) # 找不到回傳 -1
print('@' in s) # 判斷是否包含,回傳布林值
# 輸出:4
# 輸出:-1
# 輸出:True
這些方法可以串接(chaining),因為每個都回傳字串。例如 ' HELLO '.strip().lower() 會先去空白再轉小寫,這在清理資料時非常實用。
跳脫字元:表達「打不出來」的符號
有些字元無法直接放進字串,例如換行、定位符(Tab),或是字串本身用到的引號。這時用反斜線 \ 加上特定字母來表示,稱為跳脫字元(escape character):
print('第一行\n第二行') # \n 換行
print('姓名\t信箱') # \t 定位符(Tab)
print('他說:\"你好\"') # \" 雙引號
print('路徑 C:\\Users') # \\ 反斜線本身
# 輸出:
# 第一行
# 第二行
# 姓名 信箱
# 他說:"你好"
# 路徑 C:\Users
常見的跳脫序列有:\n(換行)、\t(Tab)、\\(反斜線)、\' 與 \"(引號)。
如果你不想讓反斜線被解讀為跳脫(例如寫 Windows 路徑或正規表示式),可以用原始字串(raw string),在引號前加 r:
path = r'C:\new\test'
print(path)
# 輸出:C:\new\test
若沒加 r,\n 和 \t 會被當成換行和 Tab,整個路徑就毀了。處理檔案路徑時這是常見的雷。
動手寫一段:整理學生名單
現在把學過的拼起來,解決開頭那份雜亂名單。我們要把每一行的姓名與信箱抽出來、去掉多餘空白、把信箱統一成小寫,再用整齊的格式印出:
raw_data = """ 王小明 , [email protected]
李小華,[email protected]
陳大文 , [email protected] """
# 逐行處理
for line in raw_data.strip().split('\n'):
# 切出姓名與信箱兩欄
fields = line.split(',')
name = fields[0].strip()
email = fields[1].strip().lower()
print(f'{name:<6}=> {email}')
# 輸出:
# 王小明 => [email protected]
# 李小華 => [email protected]
# 陳大文 => [email protected]
這段程式用到了 strip(去前後空白)、split(切分行與欄)、lower(統一信箱大小寫)、f-string(格式化輸出,{name:<6} 表示靠左對齊佔 6 格)。短短幾行,就把混亂的原始資料整理乾淨了。試著修改 raw_data,看看程式能不能撐住更多種髒資料。
重點回顧:初學者最常踩的雷
- 想用索引修改字串:
s[0] = 'J'會直接報TypeError。字串不可變,要「修改」就用切片或方法產生新字串再賦值回去。 - 混淆切片的邊界:
s[1:4]取的是索引 1、2、3,不含 4(左閉右開)。記住「含頭不含尾」就不會數錯。 - 忘記方法回傳新字串:
s.strip()不會改動s本身。寫成s = s.strip()才能保留結果,光寫s.strip()等於白做。 - 在迴圈裡用
+=拼大字串:因為不可變性,每次都複製整個字串,效能是 $O(n^2)$。正確做法是收進串列再''.join(list),整體為 $O(n)$。 - 路徑字串忘了用 raw string:
'C:\new'裡的\n會被當成換行。寫成r'C:\new'才安全。
深入探討(研究所視角)
Unicode 字串與 bytes 的差異
Python 3 做了一個關鍵的設計決定:把「文字」與「位元組」徹底分開。str 是 Unicode 碼位(code point)的序列,代表抽象的字元;bytes 是原始位元組的序列,代表記憶體或磁碟上實際儲存的二進位資料。兩者不能直接混用,必須透過編碼(encoding)與解碼(decoding)轉換:
text = '優學院' # str,3 個 Unicode 字元
data = text.encode('utf-8') # 編碼成 bytes
print(len(text)) # 字元數
print(len(data)) # 位元組數
print(data)
# 輸出:3
# 輸出:9
# 輸出:b'\xe5\x84\xaa\xe5\xad\xa6\xe9\x99\xa2'
注意 len(text) 是 3(三個字),但 len(data) 是 9,因為在 UTF-8 編碼下,每個中文字佔 3 個位元組。bytes 物件以 b'...' 字面值表示。反向操作是 decode:
data = b'\xe5\x84\xaa\xe5\xad\xa6\xe9\x99\xa2'
print(data.decode('utf-8'))
# 輸出:優學院
理解這個分野,能解釋許多實務上的亂碼問題:當你從網路或檔案讀進來的是 bytes,卻用錯誤的編碼去解碼(例如該用 UTF-8 卻用了 Big5),就會得到亂碼或 UnicodeDecodeError。原則是:程式內部一律用 str 處理文字,只在「進出」邊界(檔案 I/O、網路傳輸)才轉成 bytes。這就是所謂的「Unicode 三明治」模型——外層是 bytes,中間夾的全是 str。
字串駐留與不可變性的效能意義
字串不可變不只是個語法限制,它讓直譯器能做大量優化。其中之一是字串駐留(string interning):CPython 會把某些字串(如識別字般的短字串、編譯期就確定的字面值)放進一個全域池子,相同內容只儲存一份,多個變數共享同一個物件:
a = 'hello'
b = 'hello'
print(a is b) # 可能共享同一物件
# 輸出:True
x = 'this is a sentence with spaces!'
y = 'this is a sentence with spaces!'
print(x is y) # 含空白的長字串通常不自動駐留
# 輸出:False
is 比較的是「是不是同一個物件」(身份相等),== 比較的是「內容是否相同」(值相等)。駐留讓重複的字串字面值只佔一份記憶體,也讓字典(dict)鍵的比對能先用 $O(1)$ 的身份檢查快速過濾,省下逐字元比較。
不可變性還是字串能當作字典鍵與集合(set)元素的前提。雜湊表(hash table)要求鍵的雜湊值在生命週期內固定不變;如果字串能被修改,雜湊值就會改變,整個資料結構會壞掉。因此 Python 只允許不可變物件當鍵,字串天生符合。CPython 甚至會快取字串的雜湊值——因為內容不會變,雜湊值只需計算一次,之後反覆查詢都直接取用:
d = {'name': '王小明'}
print(d['name']) # 字串作為鍵,依賴不可變性
# 輸出:王小明
回到前面提過的 += 拼接問題。因為每次串接都產生新物件並複製全部內容,在迴圈中累加 $n$ 個片段的總成本是 $O(n^2)$。str.join() 之所以快,是因為它能先一次掃描算出總長度,配置一塊足夠的記憶體,再一次性填入,全程 $O(n)$。理解不可變性,你才能真正解釋這些慣例背後的「為什麼」,而不只是死背規則。