
記憶體管理
從邏輯位址到虛擬記憶體:作業系統如何讓 16GB 撐起遠超容量的工作負載
你的電腦只有 16GB,為什麼能同時開 50 個分頁?
你大概有過這樣的經驗:一邊掛著瀏覽器的數十個分頁、一邊跑 Spotify、一邊開著 IDE 編譯程式,工作管理員顯示記憶體用量已經逼近上限,但系統依然撐住沒崩潰。如果你把每個程式宣稱「需要」的記憶體加總起來,數字往往遠超過機器實際安裝的容量。這怎麼可能?
答案藏在作業系統最精巧的一層魔術裡:記憶體管理(memory management)。它讓每個程式都以為自己獨佔一整片廣闊、連續的記憶體,但實際上這些「記憶體」可能東一塊、西一塊地散落在實體晶片各處,甚至有一部分根本不在記憶體裡,而是暫存在硬碟上。要理解這套魔術,我們得先分清楚兩種位址。
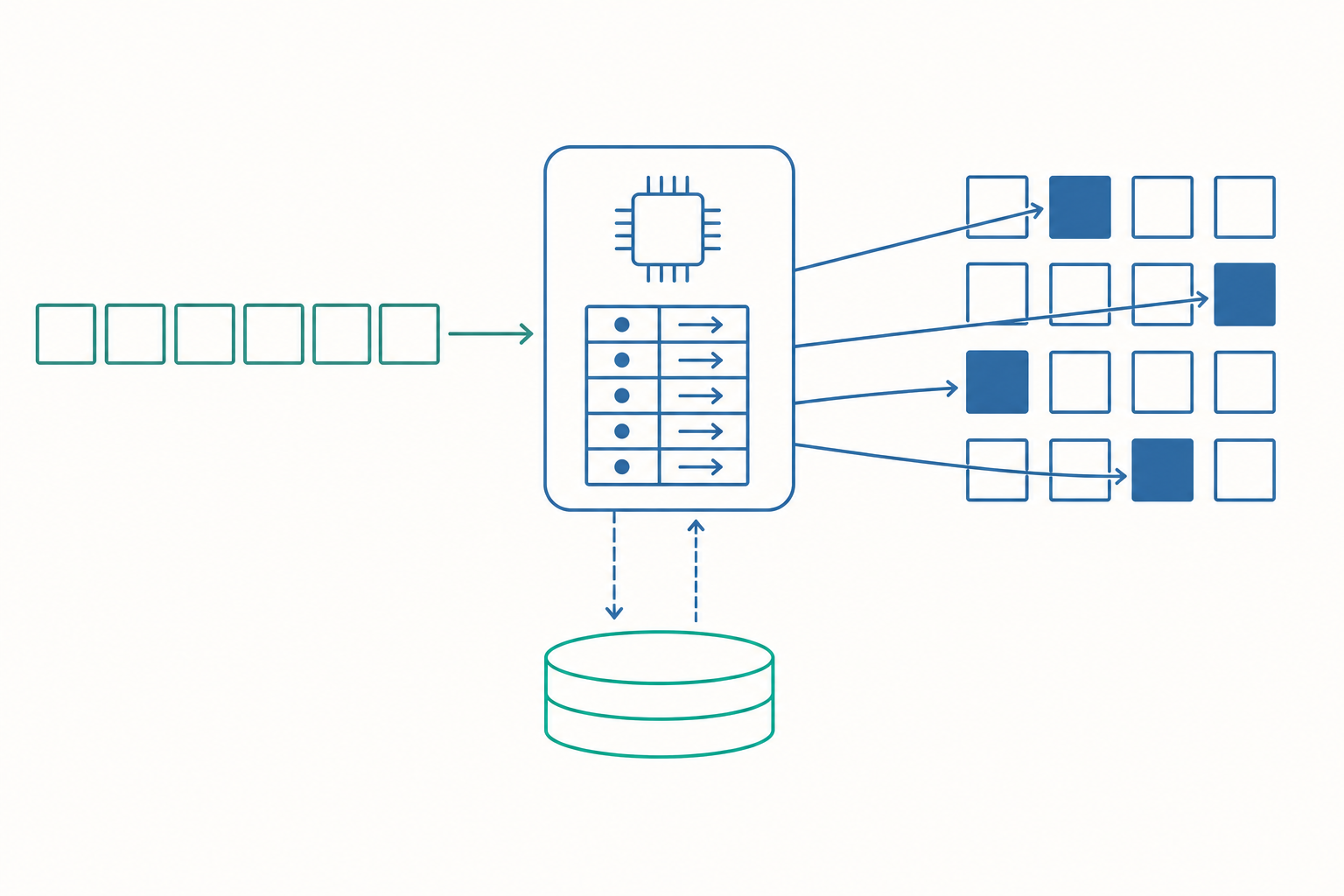
邏輯位址 vs 實體位址:一場善意的謊言
當你寫的程式存取某個變數時,CPU 送出的位址叫做邏輯位址(logical address),也稱虛擬位址(virtual address)。這是程式眼中的世界:每個行程(process)都以為自己擁有從 $0$ 開始、連續排列的整片位址空間。
但記憶體晶片上真正的格子,用的是實體位址(physical address)。兩者並不相同。中間有一個硬體元件叫做記憶體管理單元(MMU, Memory Management Unit),它在每一次記憶體存取時,即時把邏輯位址翻譯成實體位址。
這層翻譯帶來三個關鍵好處:
- 隔離與保護:行程 A 看到的位址 $0x1000$ 和行程 B 看到的 $0x1000$,被 MMU 對應到不同的實體位置。A 無法存取 B 的記憶體,一個程式的崩潰不會波及另一個。
- 彈性配置:程式不需要被載入到一塊連續的實體記憶體,作業系統可以把它拆散塞進任何空閒的角落。
- 超額供應:實體記憶體不夠時,可以把暫時用不到的部分搬到硬碟,需要時再搬回來——這就是上面那 50 個分頁的祕密。
分頁(paging):把記憶體切成標準磚塊
要實作這層翻譯,最廣泛採用的機制是分頁(paging)。它的核心想法是:把邏輯位址空間切成固定大小的小塊,稱為頁(page);把實體記憶體也切成同樣大小的小塊,稱為頁框(frame)。常見的頁大小是 4KB。
一個頁恰好可以放進一個頁框。作業系統只要維護一張對照表,記錄「第幾頁放在第幾個頁框」,翻譯就完成了。這張表叫做分頁表(page table),每個行程各有一張。
邏輯位址在分頁機制下被拆成兩部分:
邏輯位址 = | 頁號 (page number) | 頁內偏移 (offset) |
- 頁號:拿去查分頁表,得到對應的頁框號。
- 頁內偏移:在頁框內的位置,直接照搬不變。
舉例來說,若頁大小為 4KB(即 $2^{12}$ 位元組),那麼邏輯位址的低 12 位元就是偏移,高位則是頁號。翻譯公式為:
$$\text{實體位址} = (\text{頁框號} \times \text{頁大小}) + \text{偏移}$$
因為偏移部分完全不動,分頁不會改變資料在頁框內的相對位置,只是把整塊頁「搬家」到不同的頁框而已。
動手看一個例子
假設頁大小為 4KB($2^{12} = 4096$ 位元組),某行程的分頁表如下:
| 頁號 | 頁框號 |
|---|---|
| 0 | 5 |
| 1 | 9 |
| 2 | 2 |
現在 CPU 要存取邏輯位址 $9000$,翻譯過程如下:
步驟 1:算出頁號與偏移
頁號 = 9000 // 4096 = 2
偏移 = 9000 % 4096 = 808
步驟 2:查分頁表
頁號 2 → 頁框號 2
步驟 3:組合實體位址
實體位址 = 2 × 4096 + 808 = 8192 + 808 = 9000
這個例子裡實體位址恰好也是 9000(因為頁框號剛好等於頁號),但若存取邏輯位址 $5000$:
頁號 = 5000 // 4096 = 1
偏移 = 5000 % 4096 = 904
頁號 1 → 頁框號 9
實體位址 = 9 × 4096 + 904 = 36864 + 904 = 37768
可以看到,邏輯上相鄰的位址(5000 和 9000),在實體記憶體中可能相隔甚遠。這正是分頁帶來的彈性。
虛擬記憶體(virtual memory):硬碟也來湊一腳
分頁真正威力強大之處,在於它讓虛擬記憶體(virtual memory)成為可能。
核心觀察是:程式在任一時刻其實只用到自己一小部分的頁(這稱為局部性原理(principle of locality))。既然如此,何必把整個程式都塞進實體記憶體?作業系統可以只把當前需要的頁載入頁框,把暫時用不到的頁留在硬碟上的置換空間(swap space)或原始檔案中。
於是分頁表的每個項目除了頁框號,還多了一個存在位元(valid/present bit):
- 位元為 1:這一頁在實體記憶體中,可直接存取。
- 位元為 0:這一頁不在記憶體裡,目前躺在硬碟上。
分頁錯誤(page fault):把資料從硬碟救回來
當 CPU 存取一個存在位元為 0 的頁時,MMU 無法完成翻譯,於是觸發一個例外,稱為分頁錯誤(page fault)。注意,「錯誤」這個詞容易誤導——它不是程式 bug,而是一個正常的、由作業系統處理的事件。處理流程如下:
1. CPU 觸發分頁錯誤,控制權交給作業系統
2. 作業系統確認這次存取是合法的(位址在程式空間內)
3. 找一個空閒頁框;若沒有空閒頁框,啟動置換演算法挑一頁犧牲
4. 從硬碟讀入所需的頁,放進該頁框
5. 更新分頁表(填入頁框號,存在位元設為 1)
6. 重新執行剛才那條中斷的指令——這次就能成功了
分頁錯誤的代價極高。從記憶體讀取資料約需數十至上百奈秒($ns$),但從硬碟讀取一頁可能需要數毫秒($ms$)——兩者相差約十萬倍。因此,減少分頁錯誤的次數,是記憶體管理效能的關鍵。
置換演算法(page replacement):該犧牲哪一頁?
當實體記憶體已滿、又必須載入新頁時,作業系統得從現有的頁中挑一個「踢出去」(寫回硬碟或直接丟棄)。挑哪一個?這就是置換演算法要回答的問題。目標是:盡量踢掉「最不可能馬上又被用到」的頁,以降低未來的分頁錯誤。
FIFO(先進先出)
最直覺的策略:最早載入的頁最先被踢出,像排隊一樣。實作簡單,只要維護一個佇列即可。但它有個違反直覺的缺陷——FIFO 可能發生貝雷迪異常(Bélády's anomaly):增加頁框數量,分頁錯誤反而變多。
LRU(最近最少使用,Least Recently Used)
更聰明的策略:踢掉最久沒被使用的頁。它的理論依據正是局部性原理——最近用過的頁,很可能馬上又會用到;很久沒碰的頁,很可能以後也用不到。LRU 不會有貝雷迪異常,效能通常優於 FIFO。
動手看一個例子
假設有 3 個頁框,頁的存取序列為:1, 2, 3, 4, 1, 2, 5。我們比較 FIFO 與 LRU 的分頁錯誤次數(F 表示發生分頁錯誤):
FIFO:
| 存取 | 頁框狀態(左為最早載入) | 結果 |
|---|---|---|
| 1 | [1] | F |
| 2 | [1, 2] | F |
| 3 | [1, 2, 3] | F |
| 4 | [2, 3, 4] | F(踢 1) |
| 1 | [3, 4, 1] | F(踢 2) |
| 2 | [4, 1, 2] | F(踢 3) |
| 5 | [1, 2, 5] | F(踢 4) |
FIFO 共 7 次分頁錯誤。
LRU:
| 存取 | 頁框狀態(右為最近使用) | 結果 |
|---|---|---|
| 1 | [1] | F |
| 2 | [1, 2] | F |
| 3 | [1, 2, 3] | F |
| 4 | [2, 3, 4] | F(踢 1,最久沒用) |
| 1 | [3, 4, 1] | F(踢 2) |
| 2 | [4, 1, 2] | F(踢 3) |
| 5 | [1, 2, 5] | F(踢 4) |
這個序列下兩者剛好都是 7 次,但對許多真實工作負載而言,LRU 通常能少踢中「即將被用到」的頁,分頁錯誤更少。讀者可以試著用序列 1,2,3,4,1,2,5,1,2,3,4,5 比較,會看到明顯差異。
輾轉現象(thrashing):系統忙著搬資料卻不做事
如果分配給行程的頁框太少,少到連它最基本需要的頁集合都裝不下,會發生什麼事?每次存取都觸發分頁錯誤,作業系統忙著在記憶體與硬碟間搬頁,CPU 大部分時間都在等硬碟、幾乎沒做任何有意義的計算。這種「搬資料的時間遠超過計算時間」的惡性狀態,稱為輾轉現象(thrashing)。
輾轉的典型徵兆是:CPU 使用率低、硬碟燈狂閃、系統卡到動彈不得。解法包括:
- 用工作集模型(working set model)估計每個行程「當前真正需要」的頁數,確保分配的頁框足夠。
- 必要時暫停或換出整個行程(中期排程),釋放頁框給其他行程,等記憶體寬鬆再恢復。
重點回顧
- 邏輯位址是程式眼中的位址,實體位址是記憶體晶片上的真實位置,兩者由 MMU 即時翻譯,達成隔離、彈性與超額供應。
- 分頁把記憶體切成固定大小的頁與頁框,透過分頁表對應;邏輯位址拆成「頁號 + 偏移」,偏移在翻譯中保持不變。
- 虛擬記憶體讓暫時用不到的頁留在硬碟,存取時觸發分頁錯誤再搬回記憶體;分頁錯誤代價可達記憶體存取的十萬倍。
- 置換演算法決定記憶體滿時踢哪一頁:FIFO 簡單但可能有貝雷迪異常;LRU 依局部性原理表現較佳。
- 頁框過少導致輾轉現象,系統忙於搬頁而無法計算,需用工作集模型保障足夠頁框。
深入探討(研究所視角)
多層分頁表與 TLB:翻譯本身也要付出代價
前面把分頁表講得很單純,但真實系統有兩個棘手問題。
第一,分頁表本身很大。在 64 位元架構下,若用單層分頁表,光是表格就會大到無法放進記憶體。解法是多層分頁表(multi-level page table):把頁號再切成數段,逐層查表。例如 x86-64 採用四層(PML4 → PDPT → PD → PT),只有真正用到的子表才需配置,大幅節省空間。代價是查一次表得走訪多層,記憶體存取次數倍增。
第二,每次位址翻譯都要查表,而分頁表放在記憶體裡。這意味著「一次資料存取」竟然需要「多次記憶體存取」(先查表、再取資料),效能無法接受。
硬體的解法是轉譯後備緩衝區(TLB, Translation Lookaside Buffer)——一個位於 MMU 內、專門快取「頁號 → 頁框號」對應的小型高速關聯記憶體。每次翻譯先查 TLB:
- TLB 命中(hit):直接拿到頁框號,幾乎零延遲。
- TLB 失誤(miss):才去走訪(可能多層的)分頁表,並把結果填回 TLB。
得益於局部性,TLB 命中率通常高達 99% 以上。有效記憶體存取時間可近似為:
$$\text{EAT} = h \times (t_{\text{mem}}) + (1-h) \times (t_{\text{walk}} + t_{\text{mem}})$$
其中 $h$ 為 TLB 命中率,$t_{\text{mem}}$ 為一次記憶體存取時間,$t_{\text{walk}}$ 為分頁表走訪的額外成本。$h$ 越接近 1,翻譯的額外開銷越能被攤平到可忽略。值得一提的是,行程切換(context switch)時 TLB 往往需要清空(除非用 ASID 標記區分行程),這也是頻繁切換代價高昂的原因之一。
為什麼真實系統用「近似 LRU」而非真正的 LRU
理論上 LRU 表現優異,但精確的 LRU 在硬體上代價過高。要實作真正的 LRU,每次記憶體存取都得更新該頁的「最後使用時間戳」或調整一個排序結構——這對每秒數十億次的存取而言完全不可行。因此真實作業系統採用近似 LRU,最經典的是第二次機會(second-chance)演算法,又稱時鐘演算法(clock algorithm)。
其機制如下:硬體為每個頁維護一個參考位元(reference bit),每當該頁被存取,硬體自動把它設為 1。作業系統把所有頁框排成一個環形佇列,並有一個像時鐘指針的指標:
當需要置換一頁時,指針從目前位置開始掃描:
檢查指針所指頁的參考位元:
若為 1 → 給它「第二次機會」:把參考位元清為 0,指針前進到下一頁
若為 0 → 選中這一頁犧牲,置換之,指針停在下一頁
直覺是:參考位元為 1 表示「最近被用過」,先饒它一次並清掉位元;若指針繞一圈回來它仍是 0,代表這一整圈期間都沒被碰過,便可安心踢出。這只需要每頁一個位元、由硬體自動維護,成本極低,卻能近似 LRU 的效果。
進一步的精緻版本同時考慮參考位元與修改位元(dirty bit)(即 NRU/增強型時鐘演算法):優先踢掉「沒被參考且沒被修改」的頁,因為未修改的頁不必寫回硬碟,置換成本更低。這體現了系統設計的一貫哲學——用便宜的硬體位元,逼近昂貴的理論最佳解。
與其他主題的連結
記憶體管理並非孤島。它與快取(cache)階層共享「局部性」與「置換」的核心思想,只是層級不同(cache 對記憶體、記憶體對硬碟)。它與檔案系統透過記憶體映射檔案(memory-mapped file)交織,讓檔案存取與記憶體存取統一在分頁機制下。它也是行程排程的考量之一——當記憶體吃緊,中期排程器會換出整個行程以緩解輾轉。理解了這一層,你便能看穿作業系統如何用一張小小的分頁表,編織出「人人都有無限記憶體」的善意謊言。