
C++ 記憶體管理與 RAII(進階)
拆開 shared_ptr 的控制區塊、看清原子計數的硬體代價,從 Rule of Five/Rule of Zero、自訂刪除器,一路深入 placement new、對齊與 C++17 多型記憶體資源(PMR)——理解 RAII「歸還資源」背後的整套機制棧。
一個 shared_ptr 為什麼比裸指標「胖」兩倍?
你已經知道 std::unique_ptr 的大小跟一個裸指標一樣大,是名副其實的零成本抽象。那麼換成 std::shared_ptr 呢?在 64 位元平台上,一個裸指標是 8 個位元組,但 sizeof(std::shared_ptr<int>) 通常是 16 個位元組——整整大了一倍。這多出來的 8 個位元組藏著什麼?為什麼參考計數要放在「另一塊」記憶體裡,而不是緊貼著物件本身?當你寫 auto b = a; 把計數加一時,這個加法是執行緒安全的嗎?它的成本又是多少?
入門篇告訴你「shared_ptr 內部維護一個參考計數」。這一篇要把那層包裝拆開,看清楚控制區塊(control block)的真實佈局、原子計數的硬體成本、weak_ptr 如何在物件死後仍安全存活,以及為什麼一個看似無害的 make_shared 反而可能讓記憶體「死不瞑目」。我們也會走進入門篇沒碰的領域:自訂刪除器(custom deleter)、Rule of Five 與 Rule of Zero 的權衡、placement new 與對齊(alignment),以及 C++17 的多型記憶體資源(PMR)。讀完你會明白,C++ 的記憶體管理不只是「記得 delete」,而是一整套關於所有權拓樸與資源生命週期工程的設計學問。
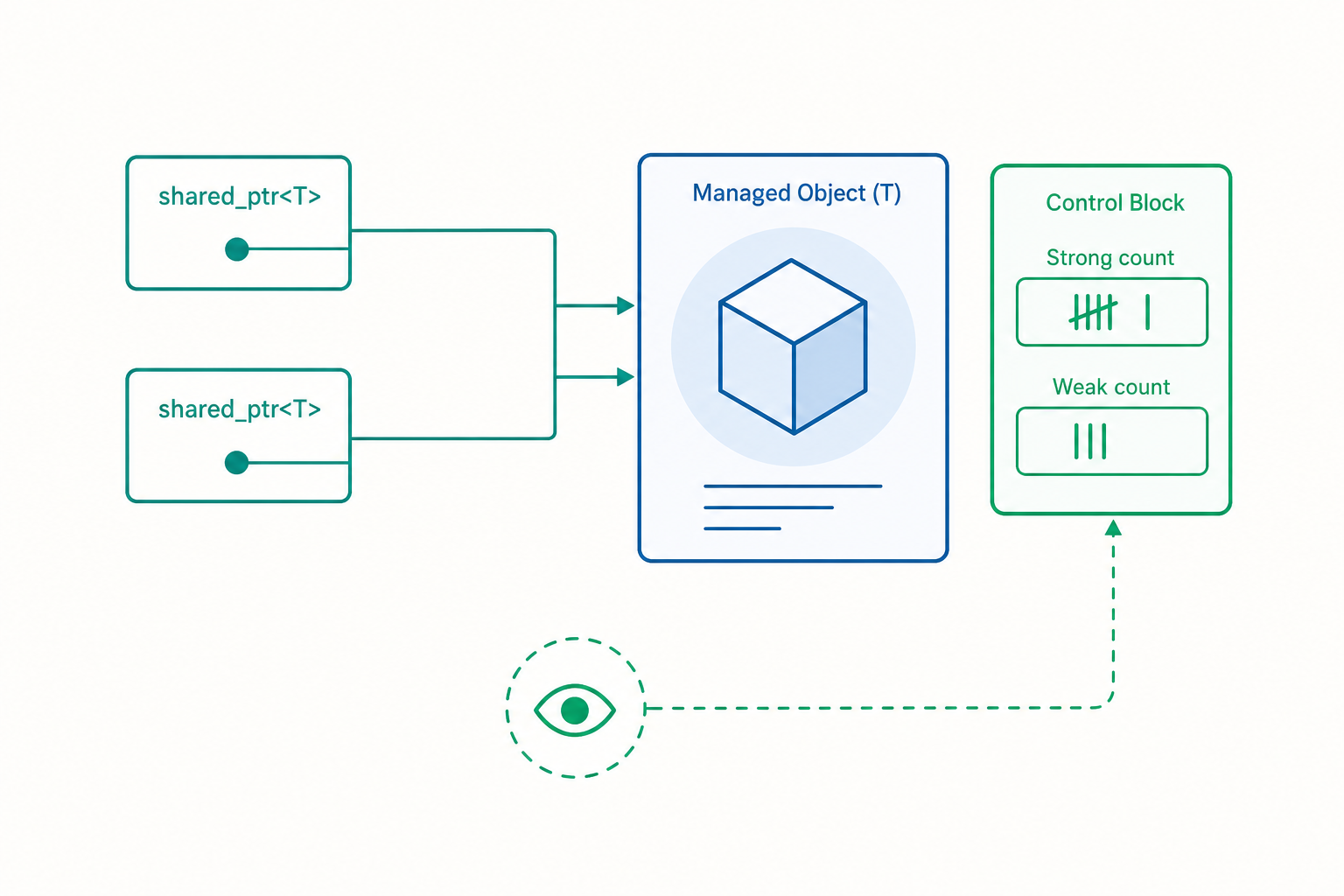
控制區塊:shared_ptr 的隱形孿生兄弟
一個 shared_ptr<T> 在記憶體裡其實握著兩個指標:一個指向受管物件 T,另一個指向所謂的控制區塊(control block)。控制區塊是一塊獨立配置的小結構,至少包含兩個計數器:
- 強參考計數(strong count / use_count):有多少個
shared_ptr共同擁有這個物件。歸零時,物件被解構。 - 弱參考計數(weak count):有多少個
weak_ptr觀察這個物件,再加上「強計數是否大於零」這個邏輯上的 +1。歸零時,控制區塊本身才被釋放。
#include <memory>
#include <iostream>
int main() {
std::shared_ptr<int> sp = std::make_shared<int>(42);
std::weak_ptr<int> wp = sp;
std::cout << "use_count = " << sp.use_count() << "\n"; // 1
std::cout << "expired? " << wp.expired() << "\n"; // 0(還活著)
sp.reset(); // 強計數歸零 → 物件解構;但控制區塊還在(wp 仍指著)
std::cout << "after reset, expired? " << wp.expired() << "\n"; // 1
// wp 析構時弱計數歸零 → 控制區塊釋放
return 0;
}
這個「兩段式釋放」是 weak_ptr 能安全運作的關鍵。物件死了,控制區塊還在;weak_ptr::expired() 只要去讀控制區塊裡的強計數是否為零,就能在不解參考已死物件的前提下判斷物件還在不在。wp.lock() 則嘗試把強計數從非零原子地加一,成功就回傳一個有效的 shared_ptr、失敗就回傳空指標——這是檢查與升級的不可分割操作,比「先 expired 再 lock」更正確。
make_shared 的甜蜜與陷阱
入門篇建議你用 std::make_shared<T>(...) 而非 shared_ptr<T>(new T(...))。原因之一是效能:make_shared 把物件與控制區塊配置在同一塊連續記憶體裡,只呼叫一次配置器(allocator),而 shared_ptr<T>(new T) 要配置兩次(一次給物件、一次給控制區塊)。一次配置不只更快,也讓兩者在快取上相鄰。
但這個優化藏著一個反直覺的後果。既然物件與控制區塊綁在同一塊記憶體,那麼只要還有任何一個 weak_ptr 存活,整塊記憶體就無法釋放——即使物件本身早已解構。物件佔的那幾百個位元組會被一個孤零零的 weak_ptr 扣留著:
struct Huge { char payload[1 << 20]; }; // 1 MB 的大物件
std::weak_ptr<Huge> leak_observer() {
auto sp = std::make_shared<Huge>(); // 物件 + 控制區塊同一塊
return sp; // sp 死亡,強計數歸零,物件解構…
} // …但若回傳的 weak_ptr 還活著,
// 這 1 MB 不會還給系統!
如果你預期會有長壽的 weak_ptr 觀察一個大物件,反而該用 shared_ptr<T>(new T) 的兩段配置,讓物件記憶體能在強計數歸零時立刻獨立釋放。這是少數 make_shared 不是最佳解的場景——一個只有理解了控制區塊佈局才看得懂的取捨。
原子計數的真實成本:為什麼 shared_ptr 不能濫用
入門篇說「維護參考計數有成本」,但沒說成本到底在哪。關鍵字是原子操作(atomic operation)。
shared_ptr 的強計數必須是執行緒安全的:兩條執行緒可能同時複製同一個 shared_ptr,計數的加一不能遺失。因此標準規定計數的增減是原子的——底層用的是 std::atomic 的 fetch_add / fetch_sub,對應到硬體的 LOCK XADD(x86)或 LL/SC(ARM)指令。
原子遞增比普通的 ++count 貴得多。普通遞增可能只是一個暫存器運算;原子遞增則要求記憶體屏障(memory barrier)與快取一致性協定的介入。在多核心系統上,如果多條執行緒頻繁複製指向同一物件的 shared_ptr,那個計數器所在的快取行(cache line)會在各核心間來回彈跳(cache-line bouncing),造成嚴重的爭用。
// 反例:在熱迴圈裡按值傳遞 shared_ptr,每次傳參都做兩次原子操作
void process(std::shared_ptr<Data> d); // 進入:強計數 +1;離開:−1
for (int i = 0; i < 10'000'000; ++i)
process(shared_data); // 兩千萬次原子操作!
// 正解:傳 const 參考,不碰計數
void process(const std::shared_ptr<Data>& d); // 零原子操作
// 更好:如果函式根本不參與所有權,就傳裸的觀察指標
void process(const Data& d); // 連 shared_ptr 都不需要看見
這帶出一條現代 C++ 的所有權守則:用智慧指標表達「所有權」,用裸指標或參考表達「借用」。 一個只是要「看一眼」資料、不延長其生命週期的函式,不該收 shared_ptr 甚至 unique_ptr——它該收 const T& 或 T*。把所有權與觀察區分開,既避免不必要的原子成本,也讓介面誠實地說出「我會不會延長你的壽命」。
值得強調的是:shared_ptr 的計數是執行緒安全的,但它指向的物件不是。兩條執行緒各自持有 shared_ptr 副本、同時呼叫物件的非 const 方法,仍然是資料競爭(data race)。控制區塊的原子性只保護「誰來釋放」,不保護「誰來讀寫資料」。
Rule of Five 與 Rule of Zero:誰該寫解構函式?
入門篇展示了一個自寫 RAII 的 IntArray,它有建構子與解構子。但那個類別其實埋了一顆地雷:它能被複製嗎?
C++ 編譯器會自動為類別合成複製建構子與複製賦值運算子,預設行為是逐成員複製(member-wise copy)。對 IntArray 而言,這意味著複製時只把指標 data_ 照抄一份——兩個物件現在指向同一塊堆積記憶體。當它們先後解構,同一塊記憶體會被 delete[] 兩次,這就是入門篇警告過的「重複釋放(double free)」。
IntArray a(5);
IntArray b = a; // 預設複製:b.data_ == a.data_(淺複製!)
// a 與 b 解構時都會 delete[] 同一個位址 → double free,未定義行為
只要你的類別手動管理了一項資源(自己持有裸指標、檔案描述子、互斥鎖…),編譯器合成的那些特殊成員函式幾乎一定是錯的。這催生了 Rule of Five(五法則):一旦你需要自訂以下五個特殊成員函式之中的任何一個,通常就該慎重考慮其餘四個:
- 解構函式 destructor
- 複製建構子 copy constructor
- 複製賦值運算子 copy assignment
- 移動建構子 move constructor
- 移動賦值運算子 move assignment
看一個例子:把 IntArray 補成正確的 Rule of Five
#include <algorithm>
#include <cstddef>
class IntArray {
int* data_;
size_t size_;
public:
explicit IntArray(size_t n) : data_(new int[n]{}), size_(n) {}
~IntArray() { delete[] data_; } // (1) 解構
IntArray(const IntArray& o) // (2) 複製建構:深複製
: data_(new int[o.size_]), size_(o.size_) {
std::copy(o.data_, o.data_ + o.size_, data_);
}
IntArray& operator=(const IntArray& o) { // (3) 複製賦值(copy-and-swap)
IntArray tmp(o); // 先做一份安全的副本
swap(tmp); // 再與自己交換
return *this; // tmp 帶走舊資源一起解構
}
IntArray(IntArray&& o) noexcept // (4) 移動建構:偷指標
: data_(o.data_), size_(o.size_) {
o.data_ = nullptr; // 把來源置空,避免雙重釋放
o.size_ = 0;
}
IntArray& operator=(IntArray&& o) noexcept { // (5) 移動賦值
if (this != &o) {
delete[] data_; // 先還掉自己手上的
data_ = o.data_; size_ = o.size_;
o.data_ = nullptr; o.size_ = 0;
}
return *this;
}
void swap(IntArray& o) noexcept {
std::swap(data_, o.data_);
std::swap(size_, o.size_);
}
int& operator[](size_t i) { return data_[i]; }
size_t size() const { return size_; }
};
兩個值得深究的細節。第一,複製賦值用了 copy-and-swap 慣用法:先複製出一個臨時物件 tmp,若這一步因記憶體不足丟出例外,*this 完全沒被動過——這天然提供了入門篇深入段提到的強例外保證(strong guarantee)。swap 是 noexcept 的,交換後 tmp 在解構時帶走舊資源。一個函式同時處理了複製、釋放舊資源、自我賦值(a = a 也安全)與例外安全,極其優雅。
第二,移動函式標了 noexcept。這不只是裝飾。std::vector 在擴容、需要把舊元素搬到新緩衝區時,會檢查元素的移動建構子是否 noexcept:若是,它移動($O(1)$ 每個元素);若移動可能丟例外,為了維持強保證它只好退而複製($O(n)$ 每個元素,且不偷不搶以便出錯時回滾)。漏標 noexcept 會讓你的型別在 vector 裡悄悄損失一大截效能。
Rule of Zero:更高明的「什麼都不寫」
Rule of Five 教你正確地寫那五個函式。但更高的境界是 Rule of Zero(零法則):設計類別時,盡量讓你一個都不必寫。
怎麼做到?把資源管理委派給已經正確實作了 Rule of Five 的成員——也就是標準容器與智慧指標。如果 IntArray 內部用 std::vector<int> 或 std::unique_ptr<int[]> 而非裸指標,編譯器自動合成的解構、複製、移動就全部正確,因為它們會逐成員地呼叫成員自己正確的版本:
#include <vector>
class IntArray {
std::vector<int> data_; // 由 vector 負責所有資源管理
public:
explicit IntArray(size_t n) : data_(n) {}
// 不需要解構、複製、移動——編譯器合成的全都對!
int& operator[](size_t i) { return data_[i]; }
size_t size() const { return data_.size(); }
};
這就是現代 C++ 的核心審美:手動管理資源的程式碼應該集中在極少數精心打造的 RAII 包裝裡(標準庫已經幫你寫好絕大多數),其餘所有類別都該是 Rule of Zero。 你寫的解構函式越少,能出錯的地方就越少。
自訂刪除器:當「釋放」不只是 delete
入門篇的智慧指標都假設資源是「new 出來的堆積記憶體、用 delete 歸還」。但真實世界的資源五花八門:C 函式庫回傳的 FILE* 要用 fclose 關、malloc 的記憶體要用 free 還、作業系統的 handle 要呼叫特定 API 釋放。智慧指標允許你指定自訂刪除器(custom deleter),把任意「清理動作」納入 RAII。
#include <memory>
#include <cstdio>
int main() {
// 用 unique_ptr 管理一個 FILE*,離開作用域自動 fclose
auto closer = [](std::FILE* f) { if (f) std::fclose(f); };
std::unique_ptr<std::FILE, decltype(closer)> fp(
std::fopen("data.txt", "r"), closer);
if (fp) {
// ... 讀檔 ...
} // fp 解構 → 自動呼叫 closer → fclose,即使中途丟例外也保證關檔
return 0;
}
這裡有個值得注意的型別細節:unique_ptr 的刪除器型別是模板參數的一部分(unique_ptr<FILE, decltype(closer)>),刪除器若是無捕獲的函式物件,unique_ptr 不會因此變大——刪除器型別在編譯期就確定。但 shared_ptr 不同:它的刪除器是型別抹除(type-erased)的,存在控制區塊裡,所以 shared_ptr<FILE> 不論用什麼刪除器,大小都不變,刪除器資訊在執行期才被取用:
std::shared_ptr<std::FILE> sp(
std::fopen("data.txt", "r"),
[](std::FILE* f){ if (f) std::fclose(f); }); // 刪除器藏進控制區塊
這個差異不是偶然,而是兩種智慧指標設計哲學的縮影:unique_ptr 把一切推到編譯期、追求零成本;shared_ptr 為了共享與型別抹除的彈性,接受一點執行期間接性。理解了控制區塊,你才看得懂為什麼同樣是「自訂刪除器」,一個進型別、一個進物件。
重點回顧
shared_ptr內含兩個指標——指向物件與指向控制區塊;控制區塊藏著強計數與弱計數,採「物件先死、控制區塊後亡」的兩段式釋放,這是weak_ptr安全的根基。- 參考計數是原子操作,在多核心熱路徑上會造成快取行爭用;用智慧指標表達所有權、用
const&或裸指標表達借用,能避開不必要的原子成本。 - Rule of Five:一旦手動管理資源,五個特殊成員函式要一起照顧;移動函式務必標
noexcept,否則在vector中會退化為複製。 - Rule of Zero 才是目標:把資源委派給標準容器與智慧指標,讓編譯器合成的特殊成員全部自動正確。
- 自訂刪除器讓 RAII 涵蓋
FILE*、OS handle 等非記憶體資源;unique_ptr把刪除器放進型別、shared_ptr放進控制區塊。
深入探討(研究所視角)
配置器、placement new 與對齊
到目前為止我們把「配置記憶體」和「在記憶體上建構物件」混為一談——new T 其實是兩個動作的合體:先呼叫 operator new 取得一塊未初始化的原始記憶體,再在那塊記憶體上呼叫 T 的建構子。標準容器之所以能做到「配置了容量卻還沒建構元素」(vector::reserve),正是因為它把這兩步拆開了。
拆開的工具是 placement new——在「一塊已存在的記憶體」上建構物件,不再配置:
#include <new> // placement new
#include <cstdlib>
struct Point { double x, y; Point(double a, double b): x(a), y(b) {} };
int main() {
// 1. 取得原始記憶體(未初始化)
void* raw = std::malloc(sizeof(Point));
// 2. 在這塊記憶體上「就地」建構物件
Point* p = new (raw) Point(3.0, 4.0); // placement new,不配置、只建構
// 3. 手動解構(placement new 沒有對應的 placement delete)
p->~Point(); // 顯式呼叫解構子
// 4. 歸還原始記憶體
std::free(raw);
return 0;
}
這是標準庫配置器(std::allocator)與 std::vector 內部真正在做的事:用 allocate 取得原始記憶體、用 construct(placement new)逐一就地建構元素、用 destroy(顯式解構)逐一摧毀、用 deallocate 歸還。把配置與建構解耦,容器才能精準控制「何時付出建構成本」、實現攤銷 $O(1)$ 的 push_back。
這裡潛伏著一個常被忽略的正確性議題:對齊(alignment)。每個型別都有對齊需求——例如 double 通常要求位址是 8 的倍數,SIMD 向量型別可能要求 16 或 32 的倍數。在未對齊的位址上建構物件是未定義行為,在某些架構上會直接觸發硬體例外。std::malloc 只保證滿足「基本對齊」,對於過度對齊(over-aligned)的型別必須改用 C++17 的 std::aligned_alloc 或對齊版的 operator new。alignof(T) 查得到需求,alignas 指定得了需求,自訂配置器時兩者缺一不可。
多型記憶體資源(PMR):把配置策略變成執行期參數
傳統的 std::vector<int, MyAllocator> 把配置器塞進模板參數,意味著 vector<int, A> 與 vector<int, B> 是兩個不同的型別,不能互相賦值、不能放進同一個容器。這在工程上很僵硬:你無法寫一個函式收「任意配置策略的 vector」。
C++17 的 多型記憶體資源(polymorphic memory resource, PMR) 用一層執行期多型解決了這個矛盾。std::pmr::vector<int> 的配置器型別是固定的(std::pmr::polymorphic_allocator<int>),真正的配置策略則藏在一個執行期可替換的 std::pmr::memory_resource* 指標背後:
#include <memory_resource>
#include <vector>
#include <array>
int main() {
// 在「堆疊上」開一塊 4 KB 緩衝區當作記憶體來源
std::array<std::byte, 4096> buffer;
std::pmr::monotonic_buffer_resource pool{buffer.data(), buffer.size()};
// 這個 vector 的所有配置都從上面那塊堆疊緩衝區切出來——零 malloc!
std::pmr::vector<int> v{&pool};
for (int i = 0; i < 100; ++i) v.push_back(i); // 不碰系統堆積
return 0;
}
monotonic_buffer_resource 是一種「只配置、不個別釋放」的策略:所有配置從預備好的緩衝區依序切出,直到資源物件本身解構才一次性整批歸還。對「建立大量短命物件、然後同時全部丟棄」的工作負載(解析器、遊戲單幀的暫存物件、編譯器的 AST 節點),這種 arena / monotonic 配置可以把成千上萬次 malloc/free 縮減成一次,並徹底消除記憶體碎片。其他 PMR 資源如 unsynchronized_pool_resource(同尺寸物件的池化)、synchronized_pool_resource(執行緒安全版本)各有適用場景。
PMR 的設計把 C++ 記憶體管理推到一個更高的抽象層:配置策略成為一個可組合、可注入的執行期物件,而非綁死在型別裡的編譯期參數。memory_resource 還能鏈接(chaining)——一個 pool 資源耗盡時可向上游(upstream)資源索取,預設上游是 new_delete_resource()。這套設計與作業系統的多級記憶體配置器、自訂遊戲引擎的 arena allocator 在思想上一脈相承。
把這條進階線索收束起來:入門篇教你「讓 RAII 保證資源被歸還」,這一篇則讓你看見歸還背後的整個機制棧——控制區塊如何協調共享所有權、原子計數的硬體代價、Rule of Five/Zero 如何把所有權語意編碼進型別系統,以及配置器與 PMR 如何把「記憶體從哪來、何時還」變成一等公民的設計決策。C++ 之所以能在自動安全與手動極致之間自由滑動,正是因為它把這每一層都攤開讓你掌控——當你需要時。