
演算法與複雜度(進階):如何證明「夠快的演算法根本不存在」?
從遞迴式與主定理、決策樹下界,到歸約、NP-完全與繞過難題的近似、隨機與參數化策略
如果「夠快的演算法根本不存在」,你要怎麼證明這件事?
你已經會分析一支演算法跑多快了。但有一個更深的問題:給定一個問題,最好的演算法能有多快?這不是問「我寫的這支」,而是問「任何人、用任何聰明手段、現在或未來寫出來的所有演算法裡,最快的那支」。
這聽起來像是不可能回答的——你怎麼可能對「還沒被發明出來的演算法」說三道四?但計算機科學最迷人的成就之一,正是我們確實能對問題本身的難度下界(lower bound)做出嚴格證明。比較排序(comparison sort)不可能比 $O(n \log n)$ 更快、旅行推銷員問題(TSP)若有多項式解則幾乎所有困難問題都會跟著崩塌——這些不是「目前還沒人做到」,而是「在某個明確模型下被證明做不到,或被證明牽一髮動全身」。入門篇教你量一支演算法;這一篇要教你對整個問題的難度說話:遞迴式怎麼解、下界怎麼證、難度怎麼在問題之間傳遞,以及當問題真的太難時,我們用什麼策略繞過它。
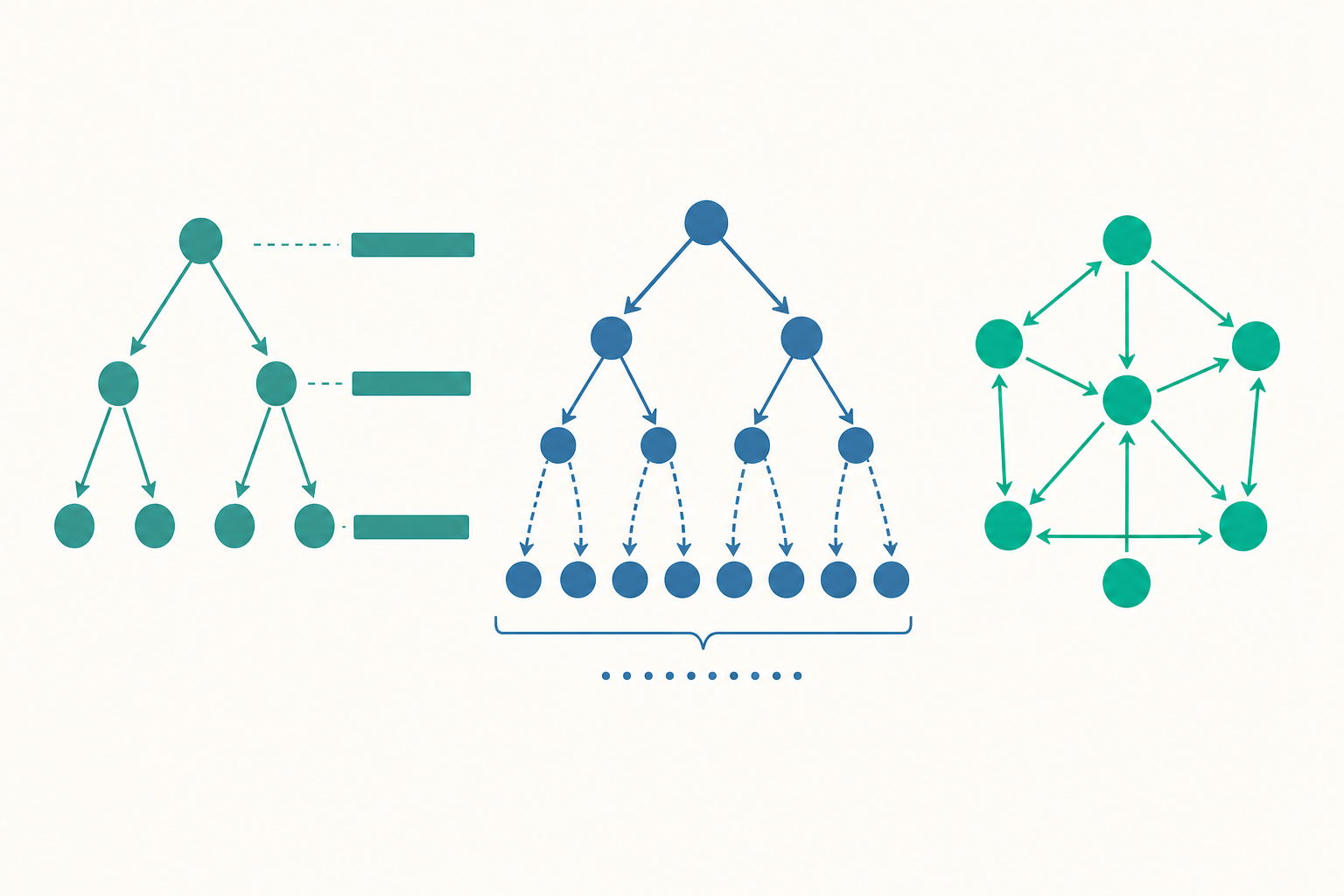
遞迴式:分治演算法的成本方程式
許多高效演算法走的是分治(divide and conquer)路線:把問題切成幾個子問題、遞迴解決、再合併。它們的成本沒辦法用一條迴圈數出來,而是寫成一條遞迴式(recurrence relation)——成本用「自己更小的版本」來定義。
合併排序(merge sort)是教科書範例。它把陣列切兩半、各自排序、再 $O(n)$ 線性合併:
def merge_sort(a):
if len(a) <= 1:
return a
mid = len(a) // 2
left = merge_sort(a[:mid]) # T(n/2)
right = merge_sort(a[mid:]) # T(n/2)
return merge(left, right) # O(n)
def merge(x, y):
result, i, j = [], 0, 0
while i < len(x) and j < len(y):
if x[i] <= y[j]:
result.append(x[i]); i += 1
else:
result.append(y[j]); j += 1
result.extend(x[i:]); result.extend(y[j:])
return result
它的成本方程式是:
$$T(n) = 2\,T(n/2) + \Theta(n)$$
意思是「解一個大小為 $n$ 的問題 = 解兩個一半大的子問題 + 花線性時間合併」。問題剩下:這條方程式展開後是多少?
動手算一下:用遞迴樹展開
把遞迴一層一層畫出來,就是遞迴樹(recursion tree)。每一層代表一次遞迴深度,我們算「每一層的合併成本總和」:
| 層 | 子問題個數 | 每個大小 | 每個合併成本 | 該層總成本 |
|---|---|---|---|---|
| 0 | 1 | $n$ | $n$ | $n$ |
| 1 | 2 | $n/2$ | $n/2$ | $n$ |
| 2 | 4 | $n/4$ | $n/4$ | $n$ |
| $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ |
| $k$ | $2^k$ | $n/2^k$ | $n/2^k$ | $n$ |
關鍵觀察:每一層的總成本都是 $n$(子問題變多,但每個變小,乘起來剛好抵消)。樹要切到子問題大小為 1,需要 $\log_2 n$ 層。所以總成本是「層數 × 每層成本」:
$$T(n) = \underbrace{n}_{\text{每層}} \times \underbrace{\log_2 n}_{\text{層數}} = \Theta(n \log n)$$
這就是為什麼合併排序是 $O(n \log n)$——不是背下來的,而是從成本方程式推出來的。遞迴樹法的威力在於它讓你「看見」成本花在哪裡:合併排序成本均勻分布在每一層,而其他演算法可能成本集中在樹根或樹葉,行為完全不同。
主定理:一個查表就能解遞迴式的工具
每次都畫遞迴樹很累。對於形如下式的遞迴,有一個現成的「查表公式」叫主定理(Master Theorem):
$$T(n) = a\,T(n/b) + f(n), \quad a \ge 1,\ b > 1$$
這裡 $a$ 是子問題個數、$b$ 是每個子問題縮小的倍率、$f(n)$ 是分割與合併的成本。定理的核心是比較兩股力量:一股是「葉子總工作量」$n^{\log_b a}$(遞迴展開到底,所有葉子加起來的成本),另一股是「根節點工作量」$f(n)$。誰主宰,誰就決定答案:
- 情況一(葉子贏):若 $f(n) = O(n^{\log_b a - \varepsilon})$($f$ 比葉子成本還小一截),則 $T(n) = \Theta(n^{\log_b a})$。
- 情況二(平手):若 $f(n) = \Theta(n^{\log_b a})$(兩者同階),則 $T(n) = \Theta(n^{\log_b a} \log n)$,多乘一個 $\log n$。
- 情況三(根贏):若 $f(n) = \Omega(n^{\log_b a + \varepsilon})$ 且滿足正則條件 $a\,f(n/b) \le c\,f(n)$($c < 1$),則 $T(n) = \Theta(f(n))$。
套用幾個例子立刻有感:
合併排序: T(n) = 2 T(n/2) + n
a=2, b=2 → n^(log₂2) = n¹ = n,而 f(n)=n → 同階(情況二)
→ T(n) = Θ(n log n) ✓
二分搜尋: T(n) = 1 T(n/2) + O(1)
a=1, b=2 → n^(log₂1) = n⁰ = 1,f(n)=1 → 同階(情況二)
→ T(n) = Θ(log n) ✓
Karatsuba 大數乘法:T(n) = 3 T(n/2) + O(n)
a=3, b=2 → n^(log₂3) ≈ n^1.585,f(n)=n 較小(情況一)
→ T(n) = Θ(n^1.585) ← 比小學直式乘法的 O(n²) 快!
最後那個 Karatsuba 例子值得停一下:小學教的兩個 $n$ 位數相乘是 $O(n^2)$,但用分治把乘法次數從 4 次減到 3 次(代價是多幾次加法),複雜度就掉到 $n^{1.585}$。這正是「改變遞迴結構就能改變漸近階」的鮮活示範,也是為什麼設計分治演算法時,每一個 $a$、$b$ 的選擇都在跟複雜度討價還價。
主定理的邊界:它不是萬能的。當 $f(n)$ 落在情況一與情況二之間的「灰色地帶」(差距不到一個多項式因子,例如 $f(n) = n \log n$ 對上 $n$),三種情況都套不上,要改用更強的 Akra–Bazzi 方法。子問題大小不等(如 $T(n) = T(n/3) + T(2n/3) + n$)時也得另尋他法。
下界:證明「不可能更快」的藝術
到目前為止我們都在算某支演算法多快,這是上界(upper bound)——「存在一支這麼快的演算法」。但開頭那個問題要的是下界——「任何演算法都至少要這麼慢」。這兩者方向相反:上界靠「給出一支演算法」就成立,下界要靠「對所有可能的演算法論證」。
最經典的下界證明是「比較排序不可能比 $O(n \log n)$ 快」,用的工具是決策樹(decision tree)。把任何「只靠兩兩比較來排序」的演算法想成一棵二元樹:每個內部節點是一次比較(問「$a_i < a_j$ 嗎?」),根據答案往左或往右走,每片葉子對應一種最終排序結果。
論證如下:$n$ 個相異元素有 $n!$ 種可能的排列,每一種都必須對應到至少一片葉子(否則演算法對該輸入會出錯)。一棵高度為 $h$ 的二元樹最多有 $2^h$ 片葉子。所以必須:
$$2^h \ge n! \quad\Longrightarrow\quad h \ge \log_2(n!)$$
而樹的高度 $h$ 就是最壞情況下要做的比較次數。用 Stirling 近似 $\log_2(n!) = \Theta(n \log n)$,得到:
$$h \ge \log_2(n!) = \Theta(n \log n)$$
這個下界對「所有」比較排序都成立——合併排序、堆積排序、快速排序,再聰明的也逃不掉。它不是說「我們還沒找到更快的」,而是說「在只用比較的模型裡,$n \log n$ 是天花板,找下去也是白費」。
這同時解釋了一個常見困惑:計數排序(counting sort)、基數排序(radix sort)為什麼能做到 $O(n)$?因為它們不只用比較——它們直接拿元素的值當索引去存取,跳出了決策樹模型,因此不受這個下界約束。下界永遠是「在某個計算模型下」成立的;換模型,天花板就變了。這是讀任何下界結果時都要追問的第一個問題:它假設的是哪個模型?
當問題本身就難:歸約與 NP-完全
有些問題我們連 $O(n \log n)$ 都奢望不起,連「有沒有多項式時間演算法」都不知道。旅行推銷員問題(TSP)、布林可滿足性(SAT)、子集合加總(subset sum)——幾十年來無數聰明人嘗試,沒人找到多項式解,但也沒人能證明它不存在。這就是 $P$ 與 $NP$ 之爭的舞台。
入門篇提過 $P$(多項式時間可解)與 $NP$(多項式時間可驗證)。進階的關鍵機制是歸約(reduction):把問題 $A$ 「翻譯」成問題 $B$,使得「解出 $B$ 就等於解出 $A$」。如果這個翻譯本身只花多項式時間,我們寫 $A \le_p B$,讀作「$A$ 多項式歸約到 $B$」。它的含義很強:
如果 $A \le_p B$,那麼「$B$ 容易」會推出「$A$ 也容易」;反過來,「$A$ 難」會推出「$B$ 至少一樣難」。
歸約讓難度可以在問題之間傳遞。一個問題被稱為 NP-困難(NP-hard),如果 $NP$ 裡每一個問題都能歸約到它;如果它自己又恰好在 $NP$ 裡,就叫 NP-完全(NP-complete)。NP-完全問題是「$NP$ 裡最難的一群」——它們彼此之間都能互相歸約,命運綁在一起:只要有任何一個 NP-完全問題找到多項式解,所有 $NP$ 問題就全部跟著有了(也就證明了 $P = NP$)。
1971 年 Cook 與 Levin 證明 SAT 是第一個 NP-完全問題(Cook–Levin 定理),這是個了不起的起點——它從零建立了第一個「最難」的錨點。此後要證明新問題 $X$ 是 NP-完全,就不必再從頭,只要:
證明 X 是 NP-完全的標準兩步:
1. 證 X ∈ NP ── 給一個「猜測解」,能在多項式時間驗證它對不對
2. 挑一個已知 NP-完全問題 Y,證 Y ≤ₚ X
── 把 Y 的任意輸入,多項式時間改造成 X 的輸入
注意歸約的方向:要證 $X$ 難,是把已知很難的 $Y$ 歸約到 $X$($Y \le_p X$),意思是「連 $Y$ 都能靠 $X$ 解掉,可見 $X$ 至少跟 $Y$ 一樣難」。初學者最常把方向寫反——記住「拿難的去壓你要證的」就不會錯。透過這套機制,Karp 在 1972 年一口氣證明了 21 個經典問題都是 NP-完全,從此這份清單滾到了數千個問題。
太難就繞過去:近似、隨機與參數化
如果一個問題是 NP-完全的,而你又真的得在實務上解它(物流排程、晶片佈線天天都在解 TSP 的近親),難道就投降嗎?不。複雜度理論的價值不只在「判死刑」,更在於它告訴你該往哪個方向繞。
近似演算法(approximation algorithm):放棄「最佳解」,改求「保證不差太多的解」。對某些問題,我們能在多項式時間內找到「至多比最佳解差 $\rho$ 倍」的解,$\rho$ 稱為近似比(approximation ratio)。例如頂點覆蓋(vertex cover)有簡單的 2-近似演算法。下面是它的精髓——反覆挑一條還沒被覆蓋的邊,把兩個端點都放進答案:
def vertex_cover_2approx(edges):
"""2-近似:結果保證 ≤ 2 倍最佳解"""
cover = set()
remaining = set(edges)
while remaining:
u, v = next(iter(remaining)) # 任取一條未覆蓋的邊
cover.add(u); cover.add(v) # 兩端點都收進來
# 移除所有被 u 或 v 覆蓋掉的邊
remaining = {(a, b) for (a, b) in remaining
if a not in (u, v) and b not in (u, v)}
return cover
為什麼保證 2 倍?因為每條被我們挑中的邊,最佳解至少要選它兩個端點中的一個;而我們選了兩個。所以我們的解最多是最佳解的兩倍——這個保證對任何輸入都成立,是寫死在邏輯裡的,不是平均表現。
隨機化演算法(randomized algorithm):引入隨機性來避開最壞情況或簡化設計。隨機化快速排序(randomized quicksort)隨機選 pivot,把「對手構造的最壞輸入」變成「機率極低的壞運氣」,期望時間 $O(n \log n)$ 不依賴輸入長相。這類演算法又分兩派:Las Vegas(答案永遠正確、時間是隨機變數,如隨機化快排)與 Monte Carlo(時間有保證、答案有小機率出錯,如 Miller–Rabin 質數測試)。
參數化複雜度(parameterized complexity):把「難」拆得更細。一個問題可能在輸入規模 $n$ 上是指數的,但若某個關鍵參數 $k$(如要找的解的大小)很小,就能寫成 $f(k) \cdot n^{O(1)}$——指數爆炸被關進 $k$ 裡,對 $n$ 仍是多項式。這叫固定參數可解(fixed-parameter tractable, FPT)。頂點覆蓋找大小 $\le k$ 的解就是 FPT 的代表:當 $k$ 小(現實中往往如此),即使圖很大也能快速解出精確答案。這給了「NP-完全」一個更細膩的回答——不是所有實例都一樣難,難度可能集中在某個參數上。
重點回顧
- 分治演算法的成本寫成遞迴式;用遞迴樹展開可看見成本分布,合併排序每層成本皆為 $n$、共 $\log n$ 層,故為 $\Theta(n \log n)$。
- 主定理是解 $T(n) = a\,T(n/b) + f(n)$ 的查表工具,比較葉子成本 $n^{\log_b a}$ 與根成本 $f(n)$ 決定三種情況;它有灰色地帶與不適用情形(改用 Akra–Bazzi)。
- 下界證明「沒有更快的演算法」:比較排序的決策樹論證($n!$ 種排列需 $\ge \log_2(n!) = \Theta(n \log n)$ 高度)說明 $n \log n$ 是天花板;下界永遠相對於某個計算模型而言。
- 歸約($\le_p$) 讓難度在問題間傳遞;NP-完全問題是 $NP$ 中最難的一群,命運相連——任一個有多項式解就推出 $P = NP$。證明 NP-完全要把已知難問題歸約到目標問題。
- 面對 NP-完全問題的實務出路:近似演算法(保證近似比)、隨機化演算法(Las Vegas / Monte Carlo)、參數化複雜度(把指數關進小參數 $k$,達成 FPT)。
深入探討(研究所視角)
把上面的線索往上延伸,會通向複雜度理論的核心地景與幾個仍然開放的深水區。
複雜度類別的層級:$P$ 與 $NP$ 只是冰山一角。$NP$ 的「對偶」是 $\text{co-NP}$(補問題可在多項式時間驗證「否」的證據),$NP \cap \text{co-NP}$ 裡住著像「整數因數分解」這類「兩個方向都有簡短證書、卻疑似不在 $P$」的問題。再往上是多項式層級(polynomial hierarchy, PH),用交錯的 $\exists/\forall$ 量詞堆出 $\Sigma_k^p$、$\Pi_k^p$ 一層層;$P = NP$ 會讓整個 PH 塌縮成一層。空間維度有 $\text{PSPACE}$(多項式空間,可解到量詞布林公式 QBF 這種 PSPACE-完全問題)、$L$(對數空間)與 $NL$,已知 $NL = \text{co-NL}$(Immerman–Szelepcsényi 定理),而 $L \overset{?}{=} NL$ 仍未解。一條被嚴格證明的稀有「分離」是時間層級定理(time hierarchy theorem):嚴格更多的時間確實能解嚴格更多的問題,所以 $P \subsetneq \text{EXP}$ 是已知為真——這提醒我們,「下界很難證」不代表「下界不存在」。
為什麼 $P \overset{?}{=} NP$ 這麼難證:已經有後設定理在解釋障礙本身。相對化(relativization):存在神諭 $A$、$B$ 使 $P^A = NP^A$ 但 $P^B \neq NP^B$(Baker–Gill–Solovay),所以任何「對神諭無感」的證明手法(包括樸素對角線法)都不可能分開 $P$ 與 $NP$。自然證明(natural proofs):Razborov–Rudich 指出,若單向函數存在,一大類「自然」的電路下界證明策略注定失敗。代數化(algebrization)又擋掉了一批繞過相對化的手法。這三道牆是為什麼這個千禧年大獎問題懸宕至今——不是還沒夠聰明,而是已知的工具被證明都不夠用。
精細複雜度(fine-grained complexity):對於已經在 $P$ 裡的問題,近年的研究把刀magnify到「$n^2$ 還是 $n^{1.99}$」這種級別。許多問題(編輯距離、最長共同子序列、圖直徑)卡在 $O(n^2)$ 幾十年降不下來,於是人們提出條件下界:假設強指數時間假說(Strong Exponential Time Hypothesis, SETH)為真,則編輯距離不存在 $O(n^{2-\varepsilon})$ 演算法。這是一種「相對難度」——把 $P$ 內部問題之間用細粒度歸約串起來,形成和 NP-完全平行的、但發生在多項式尺度上的難度網。
與機器學習與量子的交界:複雜度的觸角還在延伸。$\text{BQP}$(量子多項式時間)容納了 Shor 因數分解演算法,而因數分解疑似不在 $P$ 卻在 $\text{BQP}$——這正是量子計算威脅 RSA 的理論根源,也讓 $\text{BQP}$ 與經典類別的關係成為熱點。另一邊,學習理論用 PAC 框架問「一個概念類別需要多少樣本、多少計算才能學會」,把樣本複雜度與計算複雜度綁在同一張地圖上。本文教你分析一個演算法、論證一個問題的難度;研究所之後的旅程,是去探索難度本身的結構——哪些牆是真的、哪些只是我們還沒找到梯子,以及在量子與學習這些新模型裡,整張地圖會被重畫成什麼樣子。