
HashMap 為何突然卡住?攤銷分析、樹化與負載因子的內部解剖
從攤銷 O(1) 的真義到紅黑樹樹化、rehash 停頓與 fail-fast 機制,拆開 Java 集合容器的引擎蓋
當 HashMap 突然「卡住」:一場由負載因子引發的效能懸案
你已經知道 HashMap 的查找、插入平均是 $O(1)$,ArrayList 隨機存取也是 $O(1)$。但請想像這個場景:你寫了一個爬蟲,把抓到的網址放進 HashSet 去重,前一萬筆飛快,可是程式跑著跑著,某幾個瞬間竟然停頓了好幾毫秒,CPU 圖表出現規律的尖峰。你沒有改任何邏輯,資料也沒有特別大——到底發生了什麼?
答案藏在入門篇沒有細談的地方:那個「平均 $O(1)$」其實是一種攤銷(amortized)保證,背後是底層陣列的擴容(resize)、雜湊碰撞(collision)的處理、以及 JDK 8 之後一個鮮為人知的「樹化(treeify)」機制。這篇進階篇,我們不再背 API,而是把這些容器拆開來看內部如何運作,並理解它們在什麼情況下會「背叛」你對複雜度的假設。
攤銷分析:為什麼「平均 O(1)」不是謊言
入門篇說 ArrayList.add() 是 $O(1)$,但底層是固定長度的陣列。當陣列滿了,它必須配置一個更大的新陣列、把舊元素全部複製過去——這一次的成本明明是 $O(n)$,怎麼還能說平均 $O(1)$?
關鍵在於擴容是倍增的,不是逐一增加。Java 的 ArrayList 每次擴容約變為原本的 1.5 倍(oldCapacity + (oldCapacity >> 1))。我們用攤銷分析來看清楚。假設我們從容量 1 開始,連續加入 $n$ 個元素,發生擴容的時機點容量大約是 $1, 2, 4, 8, \dots, n$,每次擴容複製的成本與當時容量成正比。把所有擴容的複製成本加總:
$$1 + 2 + 4 + 8 + \dots + n = 2n - 1 = O(n)$$
這是把 $n$ 次 add 的總成本攤在一起,而非單次。$n$ 次操作總成本 $O(n)$,平均每次就是 $O(1)$。這就是「攤銷 $O(1)$」的精確意義:不保證每一次都很快,但保證長期平均很快。
動手算一下
假如倍增改成「每次只 +1」會怎樣?容量從 1 到 $n$,每加一個元素都要複製整個現有陣列:
$$1 + 2 + 3 + \dots + n = \frac{n(n+1)}{2} = O(n^2)$$
平均每次操作變成 $O(n)$。這就是為什麼「倍增」是一個刻意的設計選擇——它把擴容的痛苦分散到指數級稀疏的時間點上。我們用程式碼觀察擴容真實發生的次數:
import java.util.ArrayList;
import java.lang.reflect.Field;
public class GrowthWatch {
static int capacityOf(ArrayList<?> list) throws Exception {
Field f = ArrayList.class.getDeclaredField("elementData");
f.setAccessible(true);
return ((Object[]) f.get(list)).length;
}
public static void main(String[] args) throws Exception {
ArrayList<Integer> list = new ArrayList<>();
int lastCap = -1;
for (int i = 0; i < 100; i++) {
list.add(i);
int cap = capacityOf(list);
if (cap != lastCap) {
System.out.println("加入第 " + (i + 1) + " 個元素後,容量擴為 " + cap);
lastCap = cap;
}
}
}
}
執行後你會看到容量序列大致是 10 → 15 → 22 → 33 → 49 → 73 → ...(預設初始容量是 10,之後乘 1.5)。擴容次數是對數級的:加 100 個元素只擴容約 6 次。如果你事先知道資料量,用 new ArrayList<>(expectedSize) 預先配置,就能完全避免擴容——這是處理大量資料時最廉價的優化。
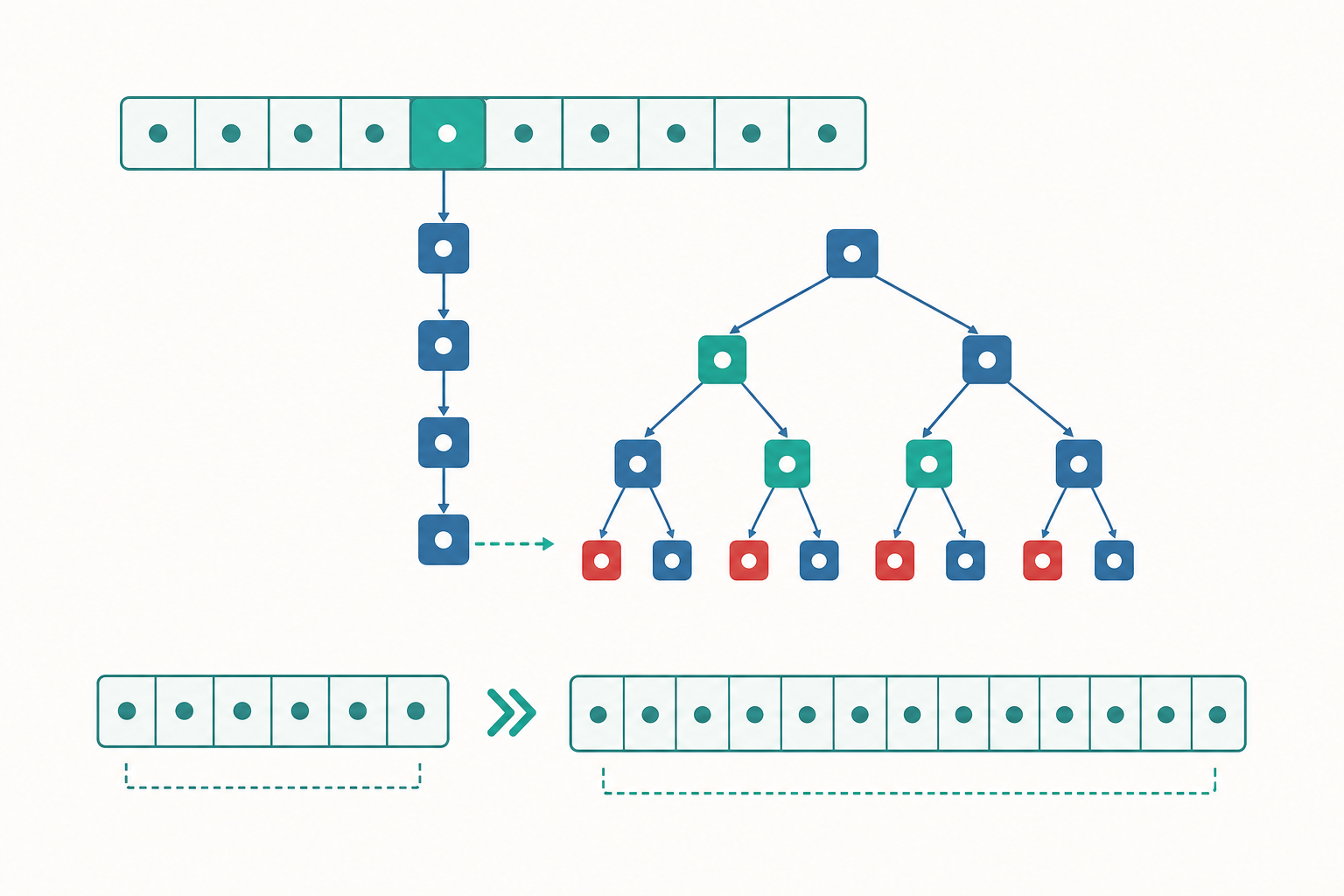
HashMap 的內部解剖:桶、碰撞與樹化
入門篇把 HashMap 當黑盒:放 key、拿 value、$O(1)$。現在打開它。HashMap 底層是一個陣列,稱為「桶(bucket)」陣列。每個 key 經過雜湊計算後,被分配到某個桶的索引:
// JDK HashMap 的索引計算(簡化)
index = (table.length - 1) & hash(key);
注意 table.length 永遠是 2 的次方,所以 (length - 1) & hash 等價於 hash % length,但位元 AND 比取模快得多。
碰撞指兩個不同的 key 算出同一個桶索引。早期的 HashMap 用「鏈結串列(linked list)」把碰撞的元素串在同一個桶裡。查找時若該桶有 $k$ 個元素,就要線性走訪,成本 $O(k)$。在最壞情況——所有 key 都碰撞到同一個桶——查找退化成 $O(n)$。
JDK 8 的關鍵改良:紅黑樹
為了防範最壞情況(尤其是有人惡意構造大量碰撞的 key,造成「雜湊洪水攻擊」),JDK 8 引入了樹化:當單一桶內的元素數量達到 TREEIFY_THRESHOLD(預設 8),且整個桶陣列長度 $\geq 64$,該桶會從鏈結串列轉換成紅黑樹(red-black tree)。
這把單桶的最壞查找從 $O(k)$ 改善為 $O(\log k)$:
| 情境 | 桶內結構 | 單桶查找複雜度 |
|---|---|---|
| 一般 | 鏈結串列 | $O(k)$ |
| 高碰撞($\geq 8$ 且表長 $\geq 64$) | 紅黑樹 | $O(\log k)$ |
當桶內元素因刪除降到 UNTREEIFY_THRESHOLD(預設 6)以下,又會退回鏈結串列。這個「6 與 8 之間留一個緩衝」的設計,是為了避免元素數量在閾值上下震盪時頻繁地轉換結構。
看一個例子:製造碰撞觀察樹化
我們刻意寫一個 hashCode() 永遠回傳同一個值的 key,逼所有元素擠進同一個桶:
import java.util.HashMap;
public class CollisionDemo {
// 惡意 key:所有實例 hashCode 都相同,但 equals 各自不同
static class BadKey {
final int id;
BadKey(int id) { this.id = id; }
@Override public int hashCode() { return 42; } // 永遠碰撞!
@Override public boolean equals(Object o) {
return o instanceof BadKey && ((BadKey) o).id == this.id;
}
}
public static void main(String[] args) {
HashMap<BadKey, Integer> map = new HashMap<>();
long start = System.nanoTime();
for (int i = 0; i < 100_000; i++) {
map.put(new BadKey(i), i);
}
long elapsed = (System.nanoTime() - start) / 1_000_000;
System.out.println("全碰撞插入 10 萬筆耗時:" + elapsed + " ms");
System.out.println("查找一筆:" + map.get(new BadKey(99_999)));
}
}
如果沒有樹化,這段程式的插入會是 $O(n^2)$,10 萬筆要跑數十秒甚至更久。有了紅黑樹,所有元素塞進同一個桶後仍維持 $O(\log n)$ 查找,整體插入降到 $O(n \log n)$,程式在合理時間內完成。這正是樹化在保護你免於雜湊洪水攻擊。你可以把 hashCode() 改成正常的 return id;,對比執行時間——差異會讓你印象深刻。
負載因子與擴容:那個神秘的停頓
回到開頭的懸案。HashMap 有一個 loadFactor(負載因子,預設 0.75)。當「元素數量 / 桶數量」超過這個比例,HashMap 就會把桶陣列容量加倍並重新雜湊(rehash)所有元素到新桶。
為什麼是 0.75?這是時間與空間的權衡。負載因子越小,碰撞越少(查找越快),但桶陣列越大越浪費記憶體;越大則越省空間但碰撞越多。0.75 是經驗上的平衡點,在泊松分布(Poisson distribution)下單桶元素數的期望維持得相當低。
問題在於:rehash 是一次 $O(n)$ 的操作。當你的 HashSet(底層就是 HashMap)成長到剛好跨過某個負載因子門檻,那一瞬間它要重新雜湊全部元素——這就是你爬蟲圖表上那個規律的尖峰停頓。資料量翻倍,門檻的間隔也翻倍,所以尖峰出現的頻率越來越稀,但每次停頓越來越久。
動手算一下:預配置省下多少擴容
假設你要放入 100 萬個元素,預設初始容量 16、負載因子 0.75。擴容門檻是 $16 \times 0.75 = 12$,之後每次門檻加倍:$12, 24, 48, \dots$。要容納 100 萬,桶陣列需擴到約 $2^{21} \approx 2{,}097{,}152$,總共擴容約 $\log_2(10^6/12) \approx 16$ 次,最後幾次每次都要 rehash 上百萬元素。
正確做法是預估容量:
import java.util.HashMap;
public class PresizeDemo {
public static void main(String[] args) {
int expected = 1_000_000;
// 容量要除以負載因子並向上取 2 的次方,才能避免擴容
int capacity = (int) (expected / 0.75f) + 1;
HashMap<Integer, String> map = new HashMap<>(capacity);
for (int i = 0; i < expected; i++) {
map.put(i, "v" + i);
}
System.out.println("完成,過程中幾乎不發生 rehash");
}
}
把 expected / 0.75 當作初始容量,HashMap 從一開始就配置足夠的桶,整個填充過程不再觸發任何擴容。對於已知大小的批次處理,這個小動作能消除所有 rehash 尖峰。
fail-fast 與並行的陷阱
還有一類進階問題不是複雜度,而是正確性。試試這段:
import java.util.ArrayList;
import java.util.List;
public class FailFastDemo {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>(List.of(1, 2, 3, 4, 5));
for (Integer x : list) {
if (x == 3) {
list.remove(x); // 在迭代中直接修改容器
}
}
}
}
它不會默默出錯,而是直接拋出 ConcurrentModificationException。這是集合框架的 fail-fast 機制:每個容器維護一個 modCount(修改計數),迭代器(iterator)在建立時記下這個值,每次 next() 都檢查 modCount 有沒有被外部改動。一旦發現容器在迭代期間被結構性修改,立刻拋例外——寧可早早爆炸,也不要安靜地給你錯誤結果。
正確的刪除方式是用迭代器自己的 remove(),它會同步更新 modCount:
import java.util.Iterator;
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
if (it.next() == 3) {
it.remove(); // 安全:iterator 與容器的 modCount 保持一致
}
}
值得強調:fail-fast 不是執行緒安全的保證,它只是「盡力偵測」的除錯輔助。在多執行緒環境下,HashMap 的並行擴容甚至可能造成資料遺失或無窮迴圈。需要並行時,請改用 java.util.concurrent.ConcurrentHashMap,它用分段或 CAS(Compare-And-Swap)機制達成真正的執行緒安全,而非單純拋例外。
重點回顧
- 攤銷 $O(1)$ 的本質是倍增擴容:$n$ 次操作的擴容總成本是 $O(n)$,平攤後每次 $O(1)$;若改成線性增長就退化為 $O(n^2)$。
HashMap的桶用(length-1) & hash定位;碰撞先用鏈結串列,JDK 8 後桶內達 8 個元素且表長 $\geq 64$ 會樹化成紅黑樹,把單桶最壞查找從 $O(k)$ 改善為 $O(\log k)$。- 負載因子 0.75 決定何時擴容;每次擴容是 $O(n)$ 的 rehash,是隨機停頓的來源。已知資料量時用
expected / 0.75預配置容量可消除擴容。 - fail-fast 機制靠
modCount偵測迭代期間的結構性修改並拋ConcurrentModificationException;刪除請用Iterator.remove()。 - fail-fast 不等於執行緒安全;並行場景請用
ConcurrentHashMap等並行容器。
深入探討(研究所視角)
勢能函數與攤銷分析的形式化。 我們前面用「加總平攤」的直觀方式論證 ArrayList 的攤銷成本,研究所層級會用勢能法(potential method)嚴謹化。定義勢能函數 $\Phi(D)$ 表示資料結構 $D$ 的「潛在能量」,單次操作的攤銷成本定義為 $\hat{c}_i = c_i + \Phi(D_i) - \Phi(D_{i-1})$,其中 $c_i$ 是實際成本。對動態陣列,取 $\Phi = 2 \cdot \text{size} - \text{capacity}$:非擴容的插入實際成本為 1、勢能增 2,攤銷成本 3;擴容時實際成本 $O(n)$ 恰好被勢能的釋放抵消,攤銷成本仍為常數。這套框架的威力在於:它能證明任意操作序列的總成本上界,而不依賴特定輸入。
雜湊的理論保證需要隨機性。 「平均 $O(1)$」隱含一個前提:雜湊函數把 key 均勻散布。但對任何固定的雜湊函數,對手都能構造出全部碰撞的輸入(如我們的 BadKey)。理論上的解法是全域雜湊(universal hashing):從一族雜湊函數中隨機挑選,使得任兩個相異 key 碰撞的機率 $\leq 1/m$($m$ 為桶數)。在此假設下,期望查找成本可證明為 $O(1 + \alpha)$,$\alpha = n/m$ 是負載因子。Java 的 HashMap 沒有用全域雜湊,而是改用樹化作為「最壞情況的安全網」——這是工程上對「對手攻擊」與「實作簡潔」的折衷。
開放定址 vs. 鏈結。 Java 選擇鏈結法(separate chaining)處理碰撞,但另一大流派是開放定址(open addressing),碰撞時依某種探測序列(線性探測、二次探測、雙重雜湊)找下一個空桶。開放定址的快取局部性(cache locality)更好(資料連續存放),常見於 Python 的 dict 與 Google 的 Swiss Tables。代價是刪除複雜(需要墓碑標記 tombstone)、且負載因子逼近 1 時效能急遽崩潰。理解這個取捨,能幫助你在不同語言、不同函式庫間做出有依據的選擇。
延伸閱讀方向。 可深入 (1) ConcurrentHashMap 在 JDK 8 從分段鎖(segment lock)改為 CAS + synchronized 桶頭的演進;(2) 一致性雜湊(consistent hashing)如何把雜湊概念延伸到分散式快取與資料分片;(3) Cuckoo hashing 與 Robin Hood hashing 如何提供 $O(1)$ 最壞情況查找。這些主題把「桶與碰撞」的基本直覺,一路推到分散式系統與現代資料庫的核心。