
雜湊表的引擎蓋:list/dict/set 的內部機制與效能推導
從開放定址、__hash__/__eq__ 契約到緊湊 dict 與 view object,理解容器的 O(1) 從何而來、又會在哪裡崩壞
為什麼 d[key] 幾乎瞬間完成,而 key in my_list 卻會愈來愈慢?
你已經知道 list 是有序序列、dict 是鍵值對、set 是不重複集合,也知道「查成員資格用 set 或 dict 比較快」。但如果有人追問:為什麼快?dict 在背後到底做了什麼,才能在百萬筆資料中「一步」找到目標?當你把一個自訂物件丟進 set 卻發現它「重複了」也沒被擋下來,問題出在哪?這篇進階篇要打開容器的引擎蓋,從雜湊表(hash table)的內部運作、__hash__/__eq__ 的契約、到 view object 與記憶體佈局,把入門篇沒細談的機制一次講清楚。
讀完之後,你不只會「選對容器」,還能解釋容器的效能從哪裡來、會在什麼情況下崩壞,以及如何設計自己的物件讓它在 dict/set 中正確運作。
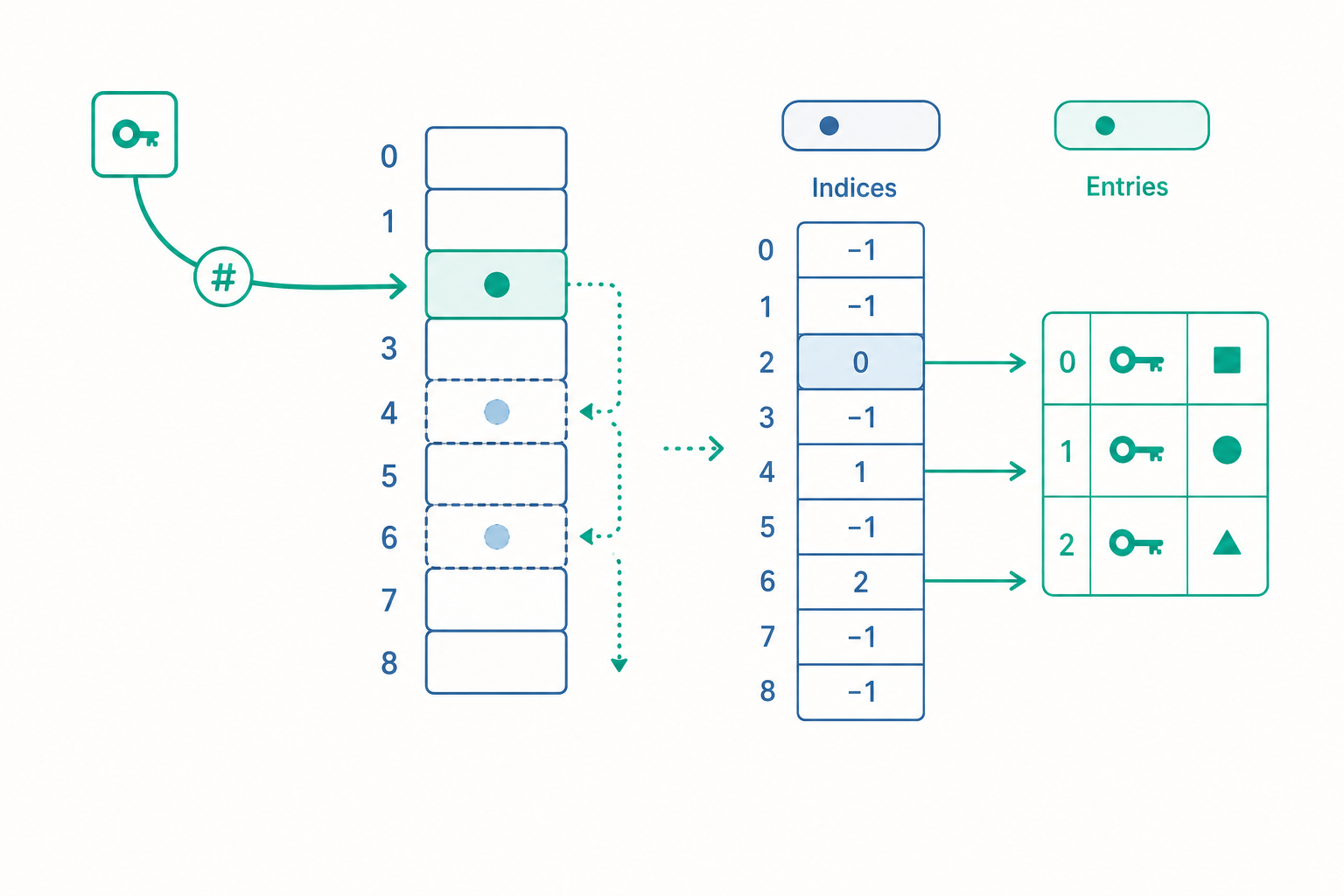
dict 與 set 的共同心臟:開放定址雜湊表
dict 和 set 在 CPython 裡共用同一套核心思想——雜湊表(hash table)。它的目標是:給定一個 key,不要逐一比對,而是用一個數學函數直接「算出」它應該放在記憶體陣列的哪一格。
流程分三步:
- 呼叫
hash(key)得到一個整數雜湊值。 - 用這個整數對「表格大小」取餘數(或取低位元),算出陣列索引(slot)。
- 到那一格去看:空的就放進去,有東西就比對是不是同一個 key。
key = "uedu"
h = hash(key) # 例如 8374651982374651 (每次執行可能不同)
table_size = 8 # 內部陣列目前有 8 格
slot = h & (table_size - 1) # 用位元 AND 取低位,等價於 h % 8
print(h, slot)
因為「算出位置」是常數時間,理想情況下查找、插入、刪除都是平均 $O(1)$,與資料量 $n$ 無關。這正是 key in d 不會隨資料變多而變慢的原因——而 x in my_list 必須從頭掃到尾,是 $O(n)$。
碰撞與開放定址(open addressing)
問題來了:不同的 key 可能算出同一格,這叫碰撞(collision)。CPython 的 dict/set 用的是開放定址法——若目標格被佔用,就依一個固定規則去探測(probe)下一格,直到找到空格或找到相同 key。
CPython 的探測序列不是單純「往後一格」,而是用一個帶擾動(perturbation)的遞迴公式,把高位元也攪進來,避免雜湊值低位相同的 key 擠成一團:
# CPython 探測序列的簡化示意(實際在 C 層的 dictobject.c)
def probe_sequence(h, table_size):
perturb = h
j = h & (table_size - 1)
yield j
while True:
j = (5 * j + 1 + perturb) & (table_size - 1)
perturb >>= 5
yield j
關鍵推論:雜湊表絕不會被填滿。一旦使用率超過某個門檻(CPython dict 約為 $2/3$),表格會「重建(resize)」成更大的陣列,所有元素重新計算位置。這保證了碰撞鏈不會太長,平均仍維持 $O(1)$。代價是:當你大量插入時,偶爾一次插入會觸發整表重建,那一次是 $O(n)$,但攤還(amortized)下來每次插入仍是 $O(1)$。
迷思澄清:很多人以為 dict 的 $O(1)$ 是「保證」。其實它是平均/攤還複雜度。最壞情況(所有 key 都碰撞到同一格)會退化成 $O(n)$。實務上由於 Python 的雜湊函數品質好,最壞情況極罕見,但這也是為什麼惡意構造的 key 曾被用來發動「雜湊碰撞 DoS 攻擊」,CPython 後來為字串雜湊加入了隨機種子(
PYTHONHASHSEED)來防禦。
自訂物件進 set/dict:__hash__ 與 __eq__ 的契約
既然容器靠 hash() 定位、靠 == 確認,那你放進去的東西就必須「會被雜湊」且「能比較相等」。這裡有一條鐵律:
若
a == b,則必須hash(a) == hash(b)。
理由直接來自雜湊表機制:相等的兩個物件必須算出同一個 slot,否則查找時就會跑到錯的格子,永遠找不到。反之不要求——雜湊值相同但物件不等是允許的(那就是碰撞)。
看一個例子:自訂物件為何「重複」也擋不住
class Point:
def __init__(self, x, y):
self.x, self.y = x, y
p1 = Point(1, 2)
p2 = Point(1, 2)
s = {p1, p2}
print(len(s)) # 2 ——竟然沒去重!
print(p1 == p2) # False ——預設用 id() 比較身分
預設情況下,Python 物件用「身分(identity)」判斷相等與雜湊(基於 id()),所以 p1 和 p2 被當成不同物件。要讓「座標相同即相等」,必須同時實作 __eq__ 和 __hash__:
class Point:
def __init__(self, x, y):
self.x, self.y = x, y
def __eq__(self, other):
return isinstance(other, Point) and (self.x, self.y) == (other.x, other.y)
def __hash__(self):
return hash((self.x, self.y)) # 用 tuple 的雜湊值,自動滿足契約
p1, p2 = Point(1, 2), Point(1, 2)
print(len({p1, p2})) # 1 ——正確去重
d = {p1: "原點附近"}
print(d[p2]) # '原點附近' ——用相等的鍵也查得到
注意一個容易踩的雷:只要你定義了 __eq__,Python 會把 __hash__ 設成 None,物件變成不可雜湊(unhashable),除非你也明確定義 __hash__。這是語言刻意的保護,避免你寫出「相等但雜湊不一致」的物件。
可變性與雜湊:為什麼 list 不能當 key
d = {}
d[[1, 2]] = "x"
# TypeError: unhashable type: 'list'
list 沒有 __hash__,因為它是可變的。想像你把一個 list 當 key 放進 dict,算出 slot 後放好;接著你修改了這個 list 的內容,它的雜湊值就變了——下次查找會算到不同的 slot,那筆資料就「消失」了。為了避免這種災難,所有可變內建型別(list、dict、set)都不可雜湊;不可變的(int、str、tuple、frozenset)才可以。
這也解釋了 frozenset 的存在意義:當你需要「一個集合當作 dict 的 key」或「集合的集合」時,就用不可變版本的 frozenset。
graph = {
frozenset({"A", "B"}): 3, # 無向邊 {A,B} 的權重
frozenset({"B", "C"}): 5,
}
print(graph[frozenset({"B", "A"})]) # 3 ——順序無關,因為 set 無序
dict 的有序性:從實作細節到語言保證
入門篇可能提過「Python 3.7 起 dict 會保留插入順序」。進階問題是:雜湊表明明把元素打散到各個 slot,為什麼還能記得插入順序?
答案是 CPython 3.6 引入的緊湊 dict(compact dict)設計:它把 dict 拆成兩個結構。
- 一個密集的 entries 陣列,按插入順序依序存放
(hash, key, value)。 - 一個稀疏的 indices 陣列(真正的雜湊表),每格存的是「指向 entries 陣列的索引」,而不是資料本身。
indices: [ -, 2, -, 0, -, -, 1, - ] ← 稀疏,存的是下方的編號
entries: [ (h0,k0,v0), (h1,k1,v1), (h2,k2,v2) ] ← 密集,按插入順序
查找時走 indices(雜湊定位),迭代時走 entries(插入順序)。這個設計同時帶來兩個好處:省記憶體(稀疏陣列只存小整數索引,不存完整 entry)與天然保序。在 3.6 它是實作細節,3.7 起正式寫入語言規格,成為你可以依賴的保證。
動手算一下:view object 是「活的視窗」
dict.keys()、.values()、.items() 回傳的不是 list 快照,而是 view object(視圖物件)——一扇即時反映 dict 內容的窗。
d = {"a": 1, "b": 2}
keys = d.keys()
print(list(keys)) # ['a', 'b']
d["c"] = 3
print(list(keys)) # ['a', 'b', 'c'] ——view 自動反映新增!
# 而且 keys view 支援集合運算(因為 key 不重複,本質是 set)
d1 = {"a": 1, "b": 2, "c": 3}
d2 = {"b": 9, "c": 9, "d": 9}
print(d1.keys() & d2.keys()) # {'b', 'c'} ——共同的鍵
print(d1.keys() - d2.keys()) # {'a'} ——只在 d1 的鍵
這帶來一個經典陷阱:迭代 view 時修改 dict 大小會炸。
d = {"a": 1, "b": 2, "c": 3}
for k in d.keys():
if d[k] == 2:
del d[k] # RuntimeError: dictionary changed size during iteration
正解是先把 keys 物化成 list 切斷連結,或用字典生成式重建:
d = {k: v for k, v in d.items() if v != 2}
set 的代數本質:用集合運算取代迴圈
set 不只是「去重容器」,它是數學集合的直接實作,支援聯集、交集、差集、對稱差。善用這些運算,能把一堆雙層迴圈壓成一行,而且因為底層是雜湊表,比手寫 in 比對快得多。
enrolled = {"S01", "S02", "S03", "S05"}
submitted = {"S02", "S03", "S04"}
print(enrolled & submitted) # {'S02', 'S03'} 有交作業的
print(enrolled - submitted) # {'S01', 'S05'} 沒交的
print(submitted - enrolled) # {'S04'} 交了但不在名單(異常)
print(enrolled ^ submitted) # 對稱差:只在其中一邊的
print(submitted <= enrolled) # False:submitted 不是 enrolled 的子集
看一個例子:去重的兩種寫法與複雜度
「保留首次出現順序的去重」是面試與實務常見題。比較兩種寫法:
data = ["b", "a", "b", "c", "a", "d"]
# 寫法一:list + in 判斷 ——每次 in 是 O(n),總共 O(n^2)
result = []
for x in data:
if x not in result: # ← 在 list 裡找,慢
result.append(x)
# 寫法二:用 set 做「看過了沒」的紀錄 ——每次查 O(1),總共 O(n)
seen = set()
result = []
for x in data:
if x not in seen: # ← 在 set 裡找,快
seen.add(x)
result.append(x)
print(result) # ['b', 'a', 'c', 'd']
當 data 有十萬筆時,寫法一的 $O(n^2)$ 會慢上千倍。這是「用對容器」帶來數量級差異的最直接示範。順帶一提,若不需保序,直接 list(set(data)) 即可;若需保序又想簡潔,list(dict.fromkeys(data)) 利用 dict 保序特性一行搞定。
list 的隱藏成本:append 很快,insert(0) 很慢
list 在記憶體裡是一段連續的指標陣列。這個佈局決定了它的效能曲線:
| 操作 | 複雜度 | 原因 |
|---|---|---|
lst[i] 隨機存取 |
$O(1)$ | 連續記憶體,位址 = 起點 + i × 指標大小 |
lst.append(x) |
攤還 $O(1)$ | 末端有預留空間,偶爾擴容才複製 |
lst.insert(0, x) |
$O(n)$ | 所有元素要往後挪一格 |
lst.pop(0) |
$O(n)$ | 所有元素要往前挪一格 |
x in lst |
$O(n)$ | 逐一線性掃描 |
append 為何是攤還 $O(1)$?因為 list 擴容時不是「多要一格」,而是成倍(約 1.125 倍起跳)超額配置,攤平了複製成本——和雜湊表 resize 同樣的攤還思想。
如果你的工作是「兩端頻繁進出」(像佇列 queue),就不該用 list 的頭端操作,而該用 collections.deque,它兩端 push/pop 都是 $O(1)$:
from collections import deque
q = deque([1, 2, 3])
q.appendleft(0) # O(1),list 的 insert(0) 是 O(n)
q.popleft() # O(1)
重點回顧
- dict 與 set 共用開放定址雜湊表:靠
hash()算位置、靠==確認,平均 $O(1)$;但這是攤還/平均複雜度,最壞情況會退化成 $O(n)$。 - 雜湊契約:
a == b必有hash(a) == hash(b)。自訂物件要進 set/dict,須同時正確實作__eq__與__hash__;定義__eq__後__hash__會被設為None,須一併補上。 - 可變即不可雜湊:list/dict/set 不能當 key,因為內容變動會讓雜湊值失效;需要時用
tuple/frozenset。 - dict 的保序來自緊湊 dict 設計(indices + entries 雙陣列),3.7 起是語言保證;
.keys()/.items()是即時 view,可做集合運算但迭代中改大小會報錯。 - 容器決定複雜度:成員測試用 set/dict($O(1)$)勝過 list($O(n)$);兩端進出用
deque勝過 list 的insert(0)。
深入探討(研究所視角)
負載因子(load factor)與攤還分析的數學。 雜湊表的效能由負載因子 $\alpha = n / m$ 決定($n$ 為元素數、$m$ 為 slot 數)。在均勻雜湊假設下,開放定址法的「不成功查找」期望探測次數約為 $\frac{1}{1-\alpha}$。當 $\alpha \to 1$ 時這個值趨於無窮,這正是 CPython 把 dict 門檻定在 $\alpha \approx 2/3$ 的理論依據——它在「記憶體浪費」與「碰撞鏈長度」之間取平衡。resize 採用「成倍擴張」策略,配合攤還分析(amortized analysis)的會計法(accounting method)或位能法(potential method),可嚴格證明 $n$ 次插入的總成本是 $O(n)$,故單次攤還 $O(1)$,即使其中夾雜了若干次 $O(n)$ 的整表搬遷。
開放定址 vs. 鏈接法(separate chaining)。 CPython 選擇開放定址而非「每格掛一條鏈結串列」的鏈接法,是出於快取友善性(cache locality)的工程考量:探測序列在連續陣列上移動,對 CPU 快取友善;鏈結串列則因指標跳躍而頻繁 cache miss。代價是開放定址對負載因子更敏感、刪除較複雜(需用 dummy 標記避免切斷探測鏈)。這也是為何 Java 的 HashMap 走鏈接法(且在鏈過長時轉成紅黑樹保證最壞 $O(\log n)$)、而 CPython 走開放定址——兩種主流語言對同一問題做出不同的工程權衡,值得作為資料結構設計的對照案例。
雜湊隨機化與安全。 str 與 bytes 的雜湊在 CPython 中採用 SipHash 演算法並由 PYTHONHASHSEED 注入隨機種子,每次行程啟動不同。這是對「演算法複雜度攻擊(algorithmic complexity attack)」的防禦:若雜湊函數可預測,攻擊者能構造大量碰撞的 key 把 $O(1)$ 拖成 $O(n)$,使伺服器 CPU 飽和。理解這點,你會明白為何不該依賴 hash() 的具體數值或跨行程一致性,也不該把 hash() 用於需要持久化或加密的場景——它是為查表設計的,不是密碼學雜湊。
延伸閱讀方向: 可進一步探究 Robin Hood hashing、Swiss Table(Google absl::flat_hash_map,以 SIMD 平行探測 metadata)、以及 Python 3.11 對 dict 的鍵共享(key-sharing)優化(同類別實例共用 keys 表以省記憶體)。這些都是「同一個雜湊表抽象、不同記憶體佈局與探測策略」的現代演化,是系統程式與資料結構交會處最活躍的研究領域之一。