
陣列與鏈結串列(進階):被大 O 隱藏的真相
從 cache 區域性、均攤分析到跳躍串列與無鎖結構,重新理解兩種資料結構在現代硬體上的真實效能
當「下一個元素在哪裡」決定了你的程式快不快
你已經知道陣列(array)用連續記憶體換來 $O(1)$ 隨機存取,而鏈結串列(linked list)用指標換來 $O(1)$ 的頭部插入。入門篇到此為止。但如果我問你一個問題:為什麼在現代電腦上,「走訪一個含一百萬個元素的陣列」幾乎總是比「走訪一個含一百萬個節點的鏈結串列」快上好幾倍——即使兩者的時間複雜度都是 $O(n)$?
答案不在大 O 符號裡。大 O 假設「每次記憶體存取的成本都一樣」,但這個假設在 1980 年代之後就不再成立了。真正主宰效能的,是一個入門課很少提的角色:快取記憶體(cache)與資料的空間區域性(spatial locality)。這一篇,我們就從這個被大 O 隱藏的真相出發,重新審視陣列與鏈結串列。
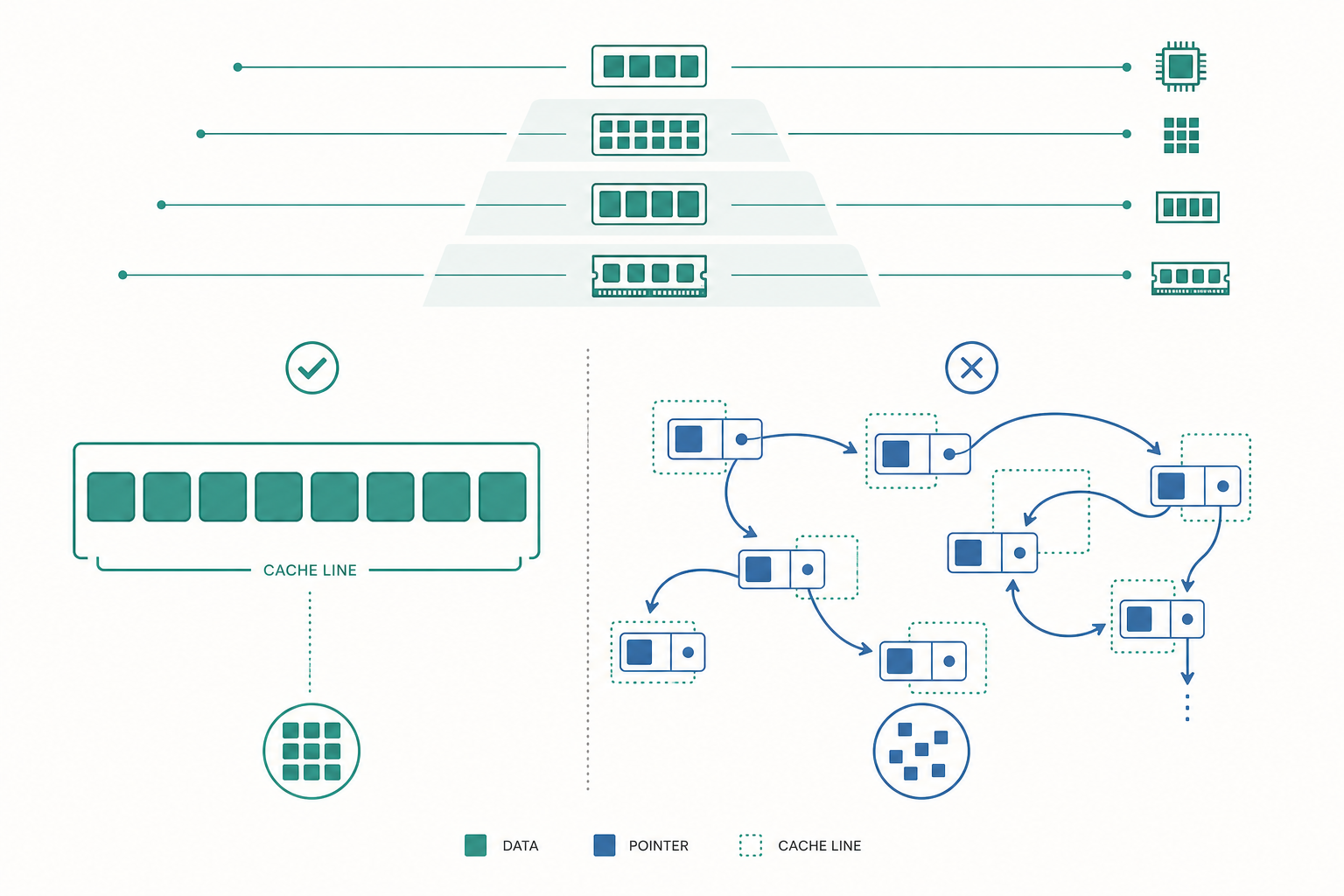
記憶體不是平的:cache line 與區域性
入門時我們把記憶體想成一條長長的格子,每格存取成本相同。實際的硬體層級是這樣的(數字為數量級,依機型而異):
| 層級 | 存取延遲(約) | 容量 |
|---|---|---|
| 暫存器(register) | < 1 ns | 數十個 |
| L1 cache | ~1 ns | 32–64 KB |
| L2 cache | ~4 ns | 256 KB–1 MB |
| L3 cache | ~15 ns | 數十 MB |
| 主記憶體(DRAM) | ~80–100 ns | 數十 GB |
關鍵在於:CPU 從 DRAM 抓資料時,不是一次抓一個 byte,而是一次抓一整條 cache line(通常 64 bytes)。也就是說,當你讀取 arr[0],硬體會順手把 arr[0] 到 arr[15](假設是 4-byte 的 int)一起載入 L1 cache。接下來讀 arr[1]...arr[15] 幾乎不花錢——它們早就在 cache 裡了。
這就是空間區域性:存取了某個位址,附近的位址很可能馬上也被存取。陣列把元素排在連續記憶體中,天生對 cache 友善。
鏈結串列則相反。每個節點是 malloc 出來的,散落在 heap 各處。走訪時每跳一個節點,下一個位址完全無法預測,cache line 幾乎每次都 miss,等於每一步都要付那 ~100 ns 的 DRAM 代價。
動手算一下:陣列 vs 鏈結串列的走訪成本
假設我們對一百萬個 int 求和。陣列版本:
long sum = 0;
for (int i = 0; i < N; i++) {
sum += arr[i]; // 每 16 個元素才 miss 一次
}
每條 cache line(64 bytes)裝得下 16 個 int,所以一百萬個元素只造成約 1,000,000 / 16 ≈ 62,500 次 cache miss。
鏈結串列版本,每個節點假設是 { int val; Node* next; }(在 64-bit 系統上約 16 bytes,含對齊):
long sum = 0;
for (Node* p = head; p != NULL; p = p->next) {
sum += p->val; // 幾乎每次都 miss
}
若節點散落各處,最壞情況是每一步都 miss,約 1,000,000 次。
把延遲代進去估算總時間(只算 miss 成本):
- 陣列:$62{,}500 \times 100\,\text{ns} = 6.25\,\text{ms}$
- 鏈結串列:$1{,}000{,}000 \times 100\,\text{ns} = 100\,\text{ms}$
差距約 16 倍——而兩者的時間複雜度都寫成 $O(n)$。這就是為什麼「漸進複雜度相同」不代表「實際速度相同」。實務上你還會看到 CPU 的硬體預取器(hardware prefetcher)進一步幫陣列加速:它偵測到你在做線性掃描,會提前把後面的 cache line 拉進來,讓陣列的有效 miss 成本更低;而鏈結串列的隨機跳躍讓預取器無從預測。
動態陣列為什麼能「攤平」成本:均攤分析
入門篇可能告訴你「動態陣列(dynamic array,如 C++ 的 std::vector、Python 的 list)滿了會自動擴容」。但擴容要重新配置記憶體並複製所有舊元素,這是 $O(n)$ 的操作。那為什麼我們還敢說 append 是 $O(1)$?
答案是均攤分析(amortized analysis):雖然某一次 append 可能很貴,但把成本平均分攤到所有操作上,每次仍是常數。
關鍵在擴容策略:容量乘以一個常數倍率(通常是 2),而不是「每次加一個位置」。我們用會計法(accounting method)來看。設每次 append 收費 3 個「代幣」:1 個付這次寫入,2 個存起來。當容量從 $k$ 翻倍到 $2k$ 需要複製 $k$ 個元素時,這些複製的成本剛好由上一輪存下來的代幣支付。
看一個例子:倍增 vs 每次加一
用 Python 模擬兩種策略,計算把元素一個個加到 $n$ 個時,總共複製了幾次:
def total_copies(n, strategy):
capacity = 1
size = 0
copies = 0
for _ in range(n):
if size == capacity:
copies += size # 擴容時複製現有元素
if strategy == "double":
capacity *= 2 # 倍增
else:
capacity += 1 # 每次加一
size += 1
return copies
for n in [1000, 10000, 100000]:
d = total_copies(n, "double")
a = total_copies(n, "add_one")
print(f"n={n:>7} 倍增複製={d:>8} 加一複製={a:>10}")
輸出:
n= 1000 倍增複製= 1023 加一複製= 499500
n= 10000 倍增複製= 16383 加一複製= 49995000
n= 100000 倍增複製= 131071 加一複製=4999950000
倍增策略的總複製次數約是 $2n$,所以平均每次 append 只複製 $O(1)$ 次;而「每次加一」策略總複製約 $n^2/2$,平均每次 $O(n)$。倍增的代價是平均浪費約一半的空間(最壞時容量約是元素數的兩倍),這是經典的時間-空間權衡(time-space tradeoff)。
數學上,倍增策略的幾何級數總和為:
$$1 + 2 + 4 + \dots + n = 2n - 1 = O(n)$$
$n$ 次操作總成本 $O(n)$,攤平到每次就是 $O(1)$。這就是為什麼業界普遍採用 1.5x 或 2x 倍率,而非固定增量。
不只是「指標」:鏈結串列家族的進階變體
入門的單向鏈結串列只是起點。當問題要求不同的存取模式,我們有更精巧的結構。
1. 雙向鏈結串列與 LRU 快取
雙向鏈結串列(doubly linked list)每個節點多一個 prev 指標,讓你能 $O(1)$ 從任一節點往回走、$O(1)$ 刪除已知節點(單向串列刪除需先找到前驅,是 $O(n)$)。
這個 $O(1)$ 任意刪除的能力是 LRU(Least Recently Used)快取的核心。LRU 要在 $O(1)$ 內:(1) 查某 key 是否存在;(2) 把剛用過的元素移到「最近使用」端;(3) 淘汰「最久未用」端。做法是雜湊表(hash map)配雙向鏈結串列:
class Node:
__slots__ = ("key", "val", "prev", "next")
def __init__(self, key=None, val=None):
self.key, self.val = key, val
self.prev = self.next = None
class LRUCache:
def __init__(self, capacity):
self.cap = capacity
self.map = {} # key -> Node
# 用兩個哨兵節點(sentinel)省去邊界判斷
self.head = Node() # 最近使用端
self.tail = Node()
self.head.next = self.tail
self.tail.prev = self.head
def _remove(self, node):
node.prev.next = node.next
node.next.prev = node.prev
def _add_front(self, node):
node.next = self.head.next
node.prev = self.head
self.head.next.prev = node
self.head.next = node
def get(self, key):
if key not in self.map:
return -1
node = self.map[key]
self._remove(node) # O(1):因為是雙向
self._add_front(node) # 移到最近使用端
return node.val
def put(self, key, val):
if key in self.map:
self._remove(self.map[key])
node = Node(key, val)
self.map[key] = node
self._add_front(node)
if len(self.map) > self.cap:
lru = self.tail.prev # 最久未用
self._remove(lru)
del self.map[lru.key]
注意這裡的哨兵節點(sentinel node)技巧:在頭尾各放一個不存資料的虛擬節點,讓 _remove 和 _add_front 永遠不必檢查「是不是第一個/最後一個」。這是鏈結串列工程實作中極常見的防呆手法,能消除大量邊界錯誤。
2. 跳躍串列(skip list):用機率換有序的對數搜尋
普通鏈結串列即使有序也只能 $O(n)$ 線性搜尋(無法二分,因為不能隨機跳到中間)。跳躍串列在原始串列之上疊加多層「快車道」:每往上一層,節點數約減半,搜尋時從最上層往下,像查字典先翻到大致位置再細找。
Level 3: H --------------------------> 50 ----------> NULL
Level 2: H ---------> 20 ------------> 50 ----------> NULL
Level 1: H -> 10 ---> 20 ---> 30 ----> 50 -> 70 ----> NULL
Level 0: H -> 10 -> 15 -> 20 -> 30 -> 50 -> 70 -> 90 -> NULL
每個節點以機率 $p$(通常 $0.5$)決定是否「升一層」。期望搜尋、插入、刪除都是 $O(\log n)$,且不需要像平衡樹那樣做複雜的旋轉——這是它廣受歡迎的原因(Redis 的 sorted set 底層就用跳躍串列)。
import random
class SkipNode:
def __init__(self, val, level):
self.val = val
self.forward = [None] * (level + 1) # 每層各一個 next 指標
class SkipList:
def __init__(self, max_level=16, p=0.5):
self.max_level = max_level
self.p = p
self.level = 0
self.head = SkipNode(None, max_level)
def _random_level(self):
lvl = 0
while random.random() < self.p and lvl < self.max_level:
lvl += 1
return lvl
def insert(self, val):
update = [None] * (self.max_level + 1)
cur = self.head
for i in range(self.level, -1, -1): # 由上而下尋找插入點
while cur.forward[i] and cur.forward[i].val < val:
cur = cur.forward[i]
update[i] = cur
lvl = self._random_level()
if lvl > self.level:
for i in range(self.level + 1, lvl + 1):
update[i] = self.head
self.level = lvl
node = SkipNode(val, lvl)
for i in range(lvl + 1): # 接上各層指標
node.forward[i] = update[i].forward[i]
update[i].forward[i] = node
跳躍串列展示了一個深刻概念:用隨機化(randomization)達到的期望效能,可以媲美精心設計的確定性平衡結構,而程式碼簡單得多。
一個顛覆直覺的結論:什麼時候陣列贏過鏈結串列做插入?
入門課常說「鏈結串列適合頻繁插入刪除」。這個說法有個重要前提常被省略:前提是你已經握有插入位置的指標。如果你得先「找到第 $k$ 個位置」再插入,鏈結串列的尋找本身就是 $O(n)$。
更反直覺的是:即使在中間插入,陣列在實務上常常比鏈結串列快。原因又回到 cache。陣列中間插入要搬移後面元素($O(n)$ 次複製),但這些複製是連續記憶體的線性搬移,CPU 與 memmove 高度最佳化、cache 友善;而鏈結串列雖然「理論上」插入是 $O(1)$,但你得先用 $O(n)$ 的指標追逐(pointer chasing)找到位置,每一跳都 cache miss。
C++ 標準委員會成員 Bjarne Stroustrup 曾做過著名實驗:對於「保持序列有序,反覆隨機插入/刪除」的工作負載,std::vector(陣列)在幾乎所有規模上都打敗 std::list(鏈結串列),即使前者理論上每次操作是 $O(n)$、後者宣稱 $O(1)$。教訓是:漸進複雜度是分析的起點,不是效能的終點;常數因子與記憶體存取模式在現代硬體上往往才是決勝點。
重點回顧
- 大 O 隱藏了記憶體層級:陣列的連續配置帶來空間區域性與 cache 友善,使其在線性走訪上實務速度遠勝散落的鏈結串列,即使兩者同為 $O(n)$。
- 動態陣列的 $O(1)$ append 是均攤結果:倍增擴容讓總複製成本為 $O(n)$,攤平後每次 $O(1)$;代價是約一半的空間浪費(時間-空間權衡)。
- 鏈結串列家族遠不只單向串列:雙向串列 + 雜湊表構成 $O(1)$ 的 LRU 快取,哨兵節點消除邊界判斷。
- 跳躍串列用隨機化換對數搜尋:期望 $O(\log n)$ 且免於樹旋轉,是平衡結構的簡潔替代品。
- 「鏈結串列適合插入」需加註腳:唯有握有位置指標時才成立;考慮 cache 後,陣列的線性搬移常勝過鏈結串列的指標追逐。
深入探討(研究所視角)
1. 均攤分析的三種形式化方法。 我們用了會計法(accounting method),但嚴格的分析還有聚合法(aggregate method)與位能法(potential method)。位能法定義一個位能函數 $\Phi$ 映射資料結構狀態到非負實數,每次操作的均攤成本定義為 $\hat{c}_i = c_i + \Phi(D_i) - \Phi(D_{i-1})$。對動態陣列,可取 $\Phi = 2 \cdot \text{size} - \text{capacity}$,能優雅證明 $n$ 次操作總均攤成本 $O(n)$。位能法的威力在於它能處理「狀態相依」的成本變化,是分析 Fibonacci heap、splay tree 等進階結構的標準工具。
2. Cache-oblivious 演算法與資料結構。 既然 cache 如此重要,能否設計出不需知道 cache 參數(line size、cache size)就能對所有層級都最佳的演算法?這是 Frigo 等人提出的 cache-oblivious 模型。代表作如 van Emde Boas 佈局的搜尋樹:把樹遞迴地切成上下兩半的子樹並連續存放,使得任意 cache line 大小下的記憶體傳輸量都達到 $O(\log_B n)$($B$ 為 line size)的理論最優。這條路線把「資料結構的記憶體佈局」提升為一級設計考量,是現代資料庫與檔案系統索引(如 B-tree 的變體)的理論基礎。
3. 並行環境下的鏈結串列:lock-free 與 ABA 問題。 在多執行緒下,鏈結串列的指標操作會引發競態。無鎖(lock-free)串列用 compare-and-swap(CAS)原子指令實作插入,但會遇到惡名昭彰的 ABA 問題:執行緒讀到指標值 A,被搶佔後該位址歷經 A→B→A 的變化,CAS 卻誤判「沒變」而成功。解法包括帶版本號的指標(tagged pointer)、hazard pointer、或 epoch-based reclamation 來安全回收記憶體。Harris(2001)的 lock-free 鏈結串列是這個領域的奠基之作,值得作為並行資料結構的入門讀物。
4. 展開鏈結串列(unrolled linked list):兩種結構的雜交。 既然陣列 cache 友善、鏈結串列插入靈活,何不讓每個節點存一個小陣列(如 16 個元素)?這就是展開鏈結串列:它把指標追逐的次數降為 $1/16$,大幅改善 cache 行為,同時保留分塊插入的彈性。更進一步的 B-tree 與資料庫的 rope(用於文字編輯器的字串表示)都可視為這個「陣列分塊 + 樹/串列連結」思想的延伸。這提示我們:真實系統中最快的結構,往往不是教科書上的純陣列或純串列,而是針對特定存取模式與記憶體層級量身打造的混合體。