
陣列與鏈結串列
從連續記憶體到節點指標,看懂兩種基礎資料結構的取捨,以及動態陣列攤銷 O(1) 背後的攤銷分析
為什麼換座位這麼麻煩?
想像一個教室裡擺了一整排連在一起的長椅,每張長椅剛好坐三個人。如果第十個座位的同學想知道自己坐在哪,老師可以瞬間說出來——因為長椅是連續排好的,「第一張長椅起點往後數十個位置」一算就到了。但如果有位同學想插隊坐到第三個位置,後面所有人都得起身往後挪一格,才能空出位子。
換另一種安排:每位同學手上各拿一張紙條,紙條上寫著「下一位是誰、坐在哪」。要插一個新同學進來很容易,只要改兩張紙條的指向就好;但想找「第十位是誰」,你得從第一位開始,順著紙條一張一張往下問,問十次才知道。
這兩種安排,正是計算機科學裡最基礎的兩種資料結構:陣列(array) 與 鏈結串列(linked list)。它們各有擅長的場景,理解兩者的取捨(trade-off),是學習所有進階資料結構的起點。
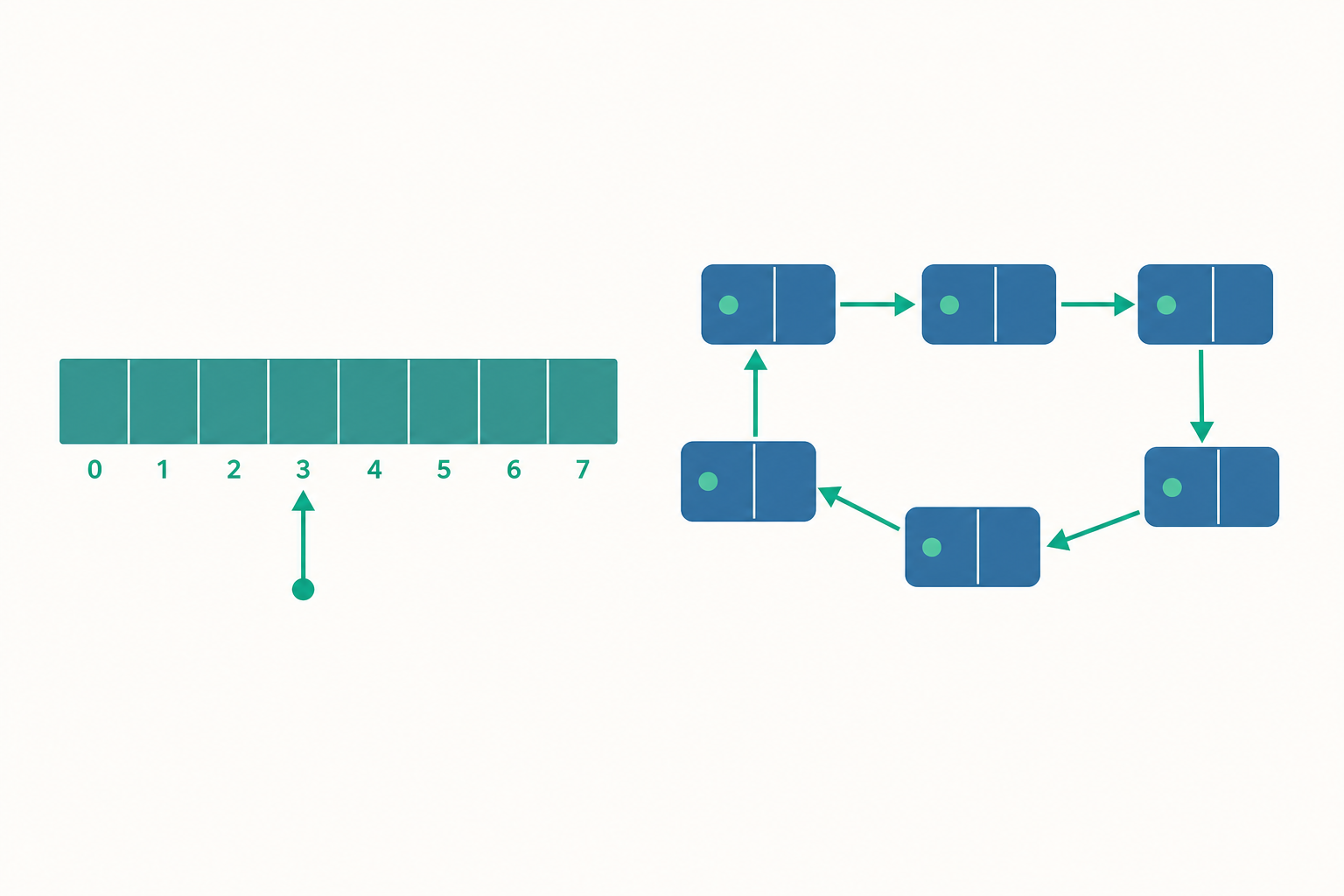
陣列:連續記憶體與隨機存取
陣列是一段連續的記憶體空間,裡面排放著型別相同、大小相等的元素。正因為連續且等大,電腦才能用一條簡單的算式直接算出任一元素的位址:
$$\text{address}(i) = \text{base} + i \times \text{size}$$
其中 base 是陣列起點的記憶體位址,size 是單一元素佔用的位元組數,$i$ 是索引(index)。這個算式只做一次乘法與一次加法,不論陣列有多長,取得第 $i$ 個元素都是固定時間,這就是 隨機存取(random access),複雜度為 $O(1)$。
scores = [88, 92, 75, 60, 100]
print(scores[3]) # 直接算位址,O(1),輸出 60
隨機存取是陣列最強大的特性。查表、影像像素處理、矩陣運算這類需要頻繁「指定位置直接取值」的工作,陣列都是首選。
代價在於插入與刪除。陣列的元素必須緊密相連、中間不能有洞,所以要在中間插入一個新元素,後面的元素全部得往後搬一格;要刪除中間某個元素,後面的元素全部得往前補一格。最壞情況(在開頭操作)需要搬動 $n$ 個元素,複雜度是 $O(n)$。
鏈結串列:節點與指標
鏈結串列換了一種思路:元素不必住在連續的記憶體。每個元素被包進一個 節點(node),節點裡除了資料本身,還多存一個 指標(pointer),指向下一個節點的位址。串列只要記得「頭(head)」在哪,就能順著指標一路走下去。
class Node:
def __init__(self, data):
self.data = data # 資料
self.next = None # 指向下一個節點的指標
# 手動串起 10 -> 20 -> 30
head = Node(10)
head.next = Node(20)
head.next.next = Node(30)
由於節點散落在記憶體各處,鏈結串列無法用算式直接跳到第 $i$ 個元素。想找第 $i$ 個,只能從 head 出發,順著 next 走 $i$ 步,因此查找(access/search)是 $O(n)$,這正是「順著紙條一張張問」的代價。
但它的優勢也很鮮明:只要已經握有某個節點的位置,插入與刪除都是 $O(1)$。插入時新建一個節點,改兩個指標的指向即可,完全不必搬動其他元素。
# 在 head 之後插入一個值為 15 的節點,O(1)
new_node = Node(15)
new_node.next = head.next # 新節點接上原本的第二個
head.next = new_node # head 改指向新節點
# 結果:10 -> 15 -> 20 -> 30
要特別澄清一個常見迷思:很多人說「鏈結串列插入刪除是 $O(1)$」,這句話只在已經定位到目標節點時才成立。如果你拿到的是「值」或「索引」而非節點本身,得先花 $O(n)$ 走過去找到它,整體仍是 $O(n)$。$O(1)$ 指的是「找到之後改指標」那一步。
兩者的 Big-O 比較
把核心操作攤開對照,可以清楚看出兩者的分工。以下假設陣列為靜態(固定容量)、鏈結串列為單向:
| 操作 | 陣列 | 鏈結串列 |
|---|---|---|
| 隨機存取(讀第 $i$ 個) | $O(1)$ | $O(n)$ |
| 查找特定值 | $O(n)$ | $O(n)$ |
| 在頭部插入/刪除 | $O(n)$ | $O(1)$ |
| 在尾部插入(已知尾端) | $O(1)$* | $O(1)$* |
| 在中間插入/刪除(已定位) | $O(n)$ | $O(1)$ |
| 額外記憶體開銷 | 低(只存資料) | 高(每節點多存指標) |
| 快取(cache)友善度 | 高(連續存取) | 低(位址跳躍) |
*陣列尾部插入須有空位;鏈結串列尾部插入須維護尾指標(tail)。
這裡有個容易被忽略、但在實務上極重要的因素:快取局部性(cache locality)。現代 CPU 從記憶體讀資料時,會一次抓一整塊連續的位元組進 快取(cache)。陣列元素相鄰,走訪時往往「順手」就把後面幾個一起載入快取,命中率高、速度快。鏈結串列的節點四散各處,每次跳到下一個節點都可能是一次快取未命中(cache miss),得重新向主記憶體要資料。因此即使兩者在 Big-O 上同為 $O(n)$,實際走訪一個大型陣列常常遠快於走訪同樣長度的鏈結串列。Big-O 描述的是成長趨勢,不等於實際常數時間,這點在工程選型時務必記得。
動手看一個例子
假設我們要維護一份「待辦清單」,需求是經常在最前面插入新任務(最新的最緊急),但很少需要跳著讀第幾項。我們來逐步比較兩種做法在「最前面插入」時發生了什麼。
用陣列,插入到索引 0:
原始: [A, B, C] 索引 0 1 2
插入 X 到最前面:
步驟1 把 C 往後搬:[A, B, _, C]
步驟2 把 B 往後搬:[A, _, B, C]
步驟3 把 A 往後搬:[_, A, B, C]
步驟4 放入 X: [X, A, B, C]
共搬動 3 次 → 一般化為 O(n)
用鏈結串列,插入到 head 之前:
原始: head -> A -> B -> C
插入 X:
步驟1 新節點 X.next 指向原 head(A)
步驟2 head 改指向 X
結果: head -> X -> A -> B -> C
只改 2 個指標 → O(1)
可以看到,對「頻繁在頭部插入」這種存取模式,鏈結串列明顯勝出。反過來,若需求改成「經常隨機讀取第幾項任務」,陣列才是正解。選擇資料結構的關鍵,永遠是先看清楚你的存取模式(access pattern)。
重點回顧
- 陣列以連續記憶體換來 $O(1)$ 隨機存取,但中間插入/刪除需搬移元素,最壞為 $O(n)$。
- 鏈結串列以節點+指標換來已定位後 $O(1)$ 的插入/刪除,但失去隨機存取,查找為 $O(n)$,且每節點有額外指標開銷。
- 兩者查找特定值都是 $O(n)$;「鏈結串列插入是 $O(1)$」的前提是已握有目標節點。
- Big-O 之外還要考慮快取局部性:陣列連續、快取友善,實務走訪常比鏈結串列快。
- 選型先看存取模式:常隨機讀取用陣列,常在端點增刪用鏈結串列。
深入探討(研究所視角)
動態陣列與攤銷 $O(1)$
前面討論的是固定容量的靜態陣列,但 Python 的 list、Java 的 ArrayList、C++ 的 std::vector 都是 動態陣列(dynamic array):容量會自動增長。其機制是配置一塊比實際需求更大的底層緩衝區,當元素填滿時,配置一塊容量加倍的新緩衝區,把舊資料整批複製過去,再釋放舊空間。
單看那一次「擴容+複製」是 $O(n)$,但它很少發生。關鍵分析工具是 攤銷分析(amortized analysis):把昂貴操作的成本平均分攤到大量便宜操作上。
考慮連續做 $n$ 次尾端 append。採加倍策略時,擴容發生在容量為 $1, 2, 4, 8, \dots$ 的時刻,總複製成本為:
$$1 + 2 + 4 + \cdots + 2^{\lfloor \log_2 n \rfloor} < 2n = O(n)$$
把這 $O(n)$ 的總成本平均到 $n$ 次操作上,每次 append 的 攤銷成本(amortized cost) 為 $O(n)/n = O(1)$。這就是為什麼我們說動態陣列尾端插入是「攤銷 $O(1)$」——個別操作偶爾很貴,但長期平均下來是常數時間。
值得一提的是「加倍」並非唯一選擇,但成長倍率需大於 1 才能維持攤銷 $O(1)$。若每次只「加固定常數個」名額,總複製成本會退化為 $O(n^2)$、攤銷成本變 $O(n)$。實務上常見倍率介於 1.5 到 2 之間,1.5 倍的好處是釋放的舊區塊較有機會被後續配置重用、降低記憶體碎片。
攤銷分析有三種正式技法:聚合法(aggregate method)(如上,總成本除以次數)、記帳法(accounting method)(每次便宜操作預存「代幣」供未來昂貴操作支付)、位能法(potential method)(定義位能函數 $\Phi$,攤銷成本 = 實際成本 + $\Delta\Phi$)。三者結論一致,但位能法在分析複雜結構(如 splay tree、Fibonacci heap)時最為通用。
雙向串列與環狀串列
單向串列只能往前走,且刪除某節點時需要它的前一個節點才能接線,這在許多場景下不便。雙向鏈結串列(doubly linked list) 為每個節點再加一個 prev 指標,指向前驅節點:
class DNode:
def __init__(self, data):
self.data = data
self.prev = None
self.next = None
雙向串列讓「已知某節點、刪除它自己」變成真正的 $O(1)$(不必先 $O(n)$ 找前驅),也支援反向走訪。代價是每節點多一個指標的記憶體,以及每次增刪要多維護一組指向。這正是許多語言標準函式庫底層的選擇,例如 C++ 的 std::list、Java 的 LinkedList 都是雙向串列。它也是實作 LRU 快取(Least Recently Used cache) 的關鍵——雙向串列搭配雜湊表(hash map),可在 $O(1)$ 內把任一節點移到串列頭並淘汰串列尾。
環狀鏈結串列(circular linked list) 則讓尾節點的 next 指回頭節點(雙向環狀則 head 的 prev 也指向 tail),形成一個閉環。它沒有 None 終點,適合表達天然循環的問題:輪流分配 CPU 時間的 輪詢排程(round-robin scheduling)、約瑟夫問題(Josephus problem)、音樂播放器的循環清單、或環狀緩衝區(ring buffer)的索引管理。走訪環狀串列時要特別小心終止條件——不能再用「走到 None 為止」,而要記住起點、用「再次回到起點」作為停止判準,否則會無限繞圈。
與後續主題的連結
陣列與鏈結串列不是終點,而是幾乎所有進階結構的零件。動態陣列是 堆疊(stack) 與 雜湊表 底層儲存桶(bucket)的常見選擇;鏈結串列是 佇列(queue)、雜湊表鏈接法(separate chaining)解決碰撞、以及圖的 鄰接串列(adjacency list) 表示法的基礎。理解「連續 vs 鏈結」「隨機存取 vs 順序走訪」「攤銷 vs 最壞情況」這幾組張力,你就握有了分析任何資料結構效能的共通語言——下一步學樹(tree)與圖(graph)時,會發現它們不過是把指標從「一條線」擴展成「多個分支」而已。