
寫一寫到底寫了多少?深入 SSD 內部與 I/O 路徑
從 NAND 快閃的物理限制、FTL 寫入放大,到 DMA、NVMe 多佇列與分頁快取——拆解資料進出電腦的整條路徑
為什麼你的 SSD 寫了 1 GB,快閃記憶體卻磨損了 4 GB?
你在入門篇學過:固態硬碟(SSD, Solid State Drive)沒有機械手臂,靠快閃記憶體(flash memory)存資料,所以比傳統硬碟快。聽起來很單純——但這裡藏著一個會嚇到很多人的事實:當作業系統告訴 SSD「請寫入這 1 GB 檔案」,SSD 內部的 NAND 顆粒實際被寫入與抹除的資料量,可能是 4 GB、甚至更多。這個比值叫做寫入放大(Write Amplification, WA),它直接決定了你的 SSD 能撐幾年才壞。
為什麼會這樣?為什麼軟體看到的「一個磁區」跟硬體上的「一塊快閃」對不起來?當你按下 save,資料到底經過了幾層轉譯、幾次排隊、幾次中斷,才真正落在矽晶片上?
入門篇談的是「裝置長什麼樣」。這篇進階文章要拆開的是「資料進出裝置的整條路徑」——從 NAND 的物理限制,到 I/O 如何送達 CPU,再到一個被現代系統工程師奉為核心指標的概念:尾延遲(tail latency)。讀完你會發現,儲存與 I/O 的真正難題,從來不是「快不快」,而是「在最壞情況下有多慢,以及為什麼」。
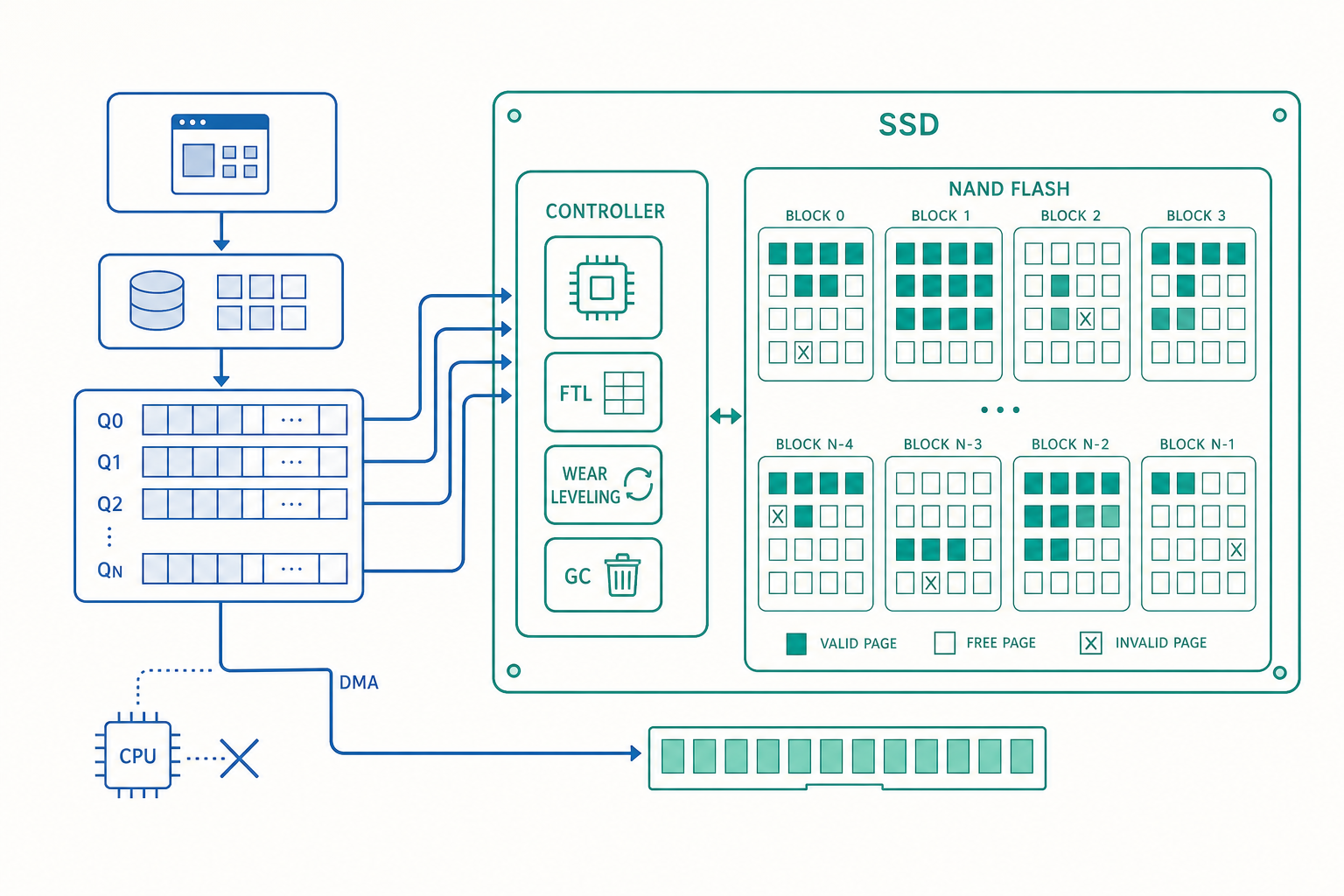
NAND 快閃的物理限制:讀寫不對稱
要理解寫入放大,得先正視 NAND 快閃一個反直覺的特性:它能以小單位「讀」與「寫」,卻只能以大單位「抹除」。
NAND 的儲存單元組織成三層:
- 頁(page):讀與寫的最小單位,通常 4 KB ~ 16 KB。
- 區塊(block):抹除的最小單位,由數百個頁組成,常見 1 MB ~ 4 MB。
- 平面 / 晶粒(plane / die):多個區塊的集合,能平行操作以提升頻寬。
關鍵限制在於:一個已經寫過資料的頁,不能直接被覆寫。NAND 的物理機制只能把位元從 1 改成 0(程式化 program),要把 0 改回 1(也就是「清空」),必須整個區塊一起抹除。
於是矛盾出現了。假設一個 2 MB 的區塊裡裝了 512 個 4 KB 的頁,你只想修改其中一個頁的內容。你不能原地覆寫那個頁,因為它已經是寫過的狀態;你也不能只抹除那一頁,因為抹除的最小單位是整個區塊。
區塊 B(2 MB):原地修改一個 4 KB 頁,硬體層必須——
1. 找一個空白頁,把新內容寫進去(程式化)
2. 把舊頁標記為「無效(invalid)」
3. 等之後再把整個區塊裡剩下的有效頁搬走、抹除回收
這就是為什麼 SSD 永遠不會「原地更新」,而是採用異地寫入(out-of-place write):新資料寫到別處,舊位置標記作廢,留待日後清理。而這個「日後清理」,正是寫入放大的來源。
FTL:把作業系統的謊言圓回來
作業系統對 SSD 講的是傳統硬碟的語言——「請把這個邏輯磁區(Logical Block Address, LBA)的內容換成這些位元」。它假設儲存裝置可以原地覆寫任意磁區。但我們剛剛說過,NAND 做不到。
中間負責「圓謊」的是 SSD 控制器裡的一層韌體,叫做 FTL(Flash Translation Layer,快閃轉譯層)。FTL 維護一張邏輯到實體的對映表(L2P mapping table):
LBA(作業系統看到的磁區) → PBA(NAND 上實際的實體頁)
100 → die0 / block5 / page12
101 → die2 / block9 / page03 ← 同一檔案的相鄰磁區
... 可能散落在完全不同的晶粒
當作業系統說「覆寫 LBA 100」,FTL 並不真的去動原本 LBA 100 對應的那個實體頁,而是:
- 挑一個空白實體頁,寫入新資料;
- 更新對映表,讓 LBA 100 指向這個新頁;
- 把舊頁標記為無效。
這層轉譯帶來三件大事:磨損平均(wear leveling)、垃圾回收(garbage collection)、以及前面預告的寫入放大。
磨損平均:讓每塊磚平均地老去
NAND 區塊有壽命上限,以抹除週期(P/E cycle, Program/Erase cycle)計:消費級 TLC 大約幾百到幾千次,企業級可達上萬次。一旦某區塊抹除太多次就會壞掉。
如果 FTL 老是把熱門資料寫在同幾個區塊,那些區塊很快磨損報廢,而其他區塊還很新——整顆 SSD 卻已經損壞。磨損平均的工作就是刻意把寫入打散到所有區塊,必要時甚至會主動搬移「很少變動的冷資料」,把它佔住的、磨損次數較低的區塊釋放出來給熱資料用。目標是讓所有區塊的 P/E 計數盡量接近,整顆一起老,而不是個別早夭。
動手算一下:寫入放大係數
現在把寫入放大量化。定義:
$$ \text{WAF} = \frac{\text{實際寫入 NAND 的資料量}}{\text{主機要求寫入的資料量}} $$
考慮垃圾回收的場景。SSD 要回收一個區塊前,得先把區塊裡「還有效」的頁搬到別處(不然會丟資料),才能抹除整個區塊。假設一個區塊有 512 個頁,垃圾回收時平均有 70% 的頁仍然有效(也就是只有 30% 是無效、可丟棄的),那麼:
- 為了清出這個區塊,要搬移 $512 \times 0.7 = 358.4$ 個頁的有效資料到別處(這是額外寫入);
- 真正能回收釋放的空間只有 $512 \times 0.3 = 153.6$ 個頁。
換句話說,每當主機想寫入 153.6 個頁的「新空間」,FTL 背後額外搬了 358.4 個頁。我們用一個常見近似式估算穩態寫入放大:
$$ \text{WAF} \approx \frac{1}{1 - u} $$
其中 $u$ 是垃圾回收時區塊的平均有效頁比例(有效資料佔用率)。代入 $u = 0.7$:
$$ \text{WAF} \approx \frac{1}{1 - 0.7} = \frac{1}{0.3} \approx 3.33 $$
也就是說,主機寫 1 GB,NAND 實際被寫了約 3.33 GB。文章開頭說的「寫 1 GB 磨損 4 GB」並不誇張。
這個公式給我們兩個重要啟示:
- 預留空間(over-provisioning, OP)越多,WAF 越低。如果 SSD 保留更多空白區塊不給使用者用,垃圾回收時就能挑「有效頁比例低」的區塊回收,$u$ 變小,WAF 跟著下降。這就是為什麼企業級 SSD 標稱容量常比實際 NAND 小(例如 NAND 有 512 GB 卻只賣 480 GB)。
def estimated_waf(over_provision_ratio):
"""以預留空間比例粗估穩態寫入放大(隨機寫入、貪婪 GC 的簡化模型)。
over_provision_ratio: 例如 0.28 代表 NAND 比標稱容量多 28%。
"""
# 使用者資料把可用空間填滿後,平均有效頁比例近似 1/(1+OP)
u = 1.0 / (1.0 + over_provision_ratio)
return 1.0 / (1.0 - u)
for op in (0.07, 0.28, 1.0):
print(f"OP={op:>4}: WAF≈{estimated_waf(op):.2f}")
# OP=0.07: WAF≈15.29 ← 預留少,寫入放大爆炸
# OP=0.28: WAF≈ 4.57
# OP= 1.0: WAF≈ 2.00 ← 預留一倍,放大降到 2
- TRIM 指令很關鍵。當你刪除檔案,作業系統其實只是在檔案系統的中繼資料裡標記「這些磁區不用了」,並沒有真的去清 SSD。若不告知 SSD,FTL 會以為這些頁仍有效,垃圾回收時白白搬移它們,推高 $u$ 與 WAF。
TRIM(NVMe 上叫Deallocate)就是作業系統主動通知 SSD「這些 LBA 的資料已作廢」,讓 FTL 把它們當無效頁,回收時直接丟棄,不再搬移。
資料如何抵達 CPU:輪詢、中斷、DMA
談完「資料在裝置內怎麼擺」,換另一個維度:資料怎麼從裝置送到 CPU 與記憶體。入門篇提過匯流排(bus),這裡我們看 CPU 與裝置溝通的三種典範。
1. 輪詢(polling / busy-waiting):CPU 反覆讀取裝置的狀態暫存器,問「好了沒?好了沒?」直到裝置回報完成。
// 輪詢:CPU 卡死在這個迴圈裡空轉,什麼別的事都不能做
while (!(device_status_register & READY_BIT)) {
/* 純粹浪費 CPU 週期 */
}
read_data_from_device();
優點是延遲極低、實作簡單;缺點是 CPU 在等待期間完全空轉,對慢速裝置是巨大浪費。
2. 中斷(interrupt):CPU 對裝置下達指令後就去做別的事;裝置完成時主動發出中斷訊號,CPU 暫停手邊工作、跳去執行中斷處理常式(ISR, Interrupt Service Routine)。
中斷讓 CPU 不必空轉,是分時多工系統的基礎。但中斷本身有成本:每次中斷都要儲存/恢復 CPU 狀態、切換上下文。對於每秒能完成上百萬筆 I/O 的現代 NVMe SSD,如果每筆 I/O 都觸發一次中斷,光是處理中斷就會把 CPU 淹沒——這個現象叫中斷風暴(interrupt storm)。
3. DMA(Direct Memory Access,直接記憶體存取):前兩種方式都得讓 CPU 親自搬每一個位元組進出記憶體。DMA 引入一個專門的控制器,讓裝置繞過 CPU、直接讀寫主記憶體。CPU 只需告訴 DMA 控制器「把這塊資料搬到記憶體位址 0x...,搬完通知我」,然後就放手;DMA 默默搬完一整塊資料後,才發一次中斷通知 CPU。
傳統(programmed I/O):CPU 親自搬每個位元組 → CPU 是搬運工
DMA:CPU 下單 → DMA 搬整塊 → 搬完才中斷一次 → CPU 是經理
現代高速 I/O 是這三者的精妙組合:用 DMA 搬大塊資料、用中斷通知完成、在某些超高吞吐場景甚至回頭用輪詢(因為當 I/O 快到中斷成本反而成為瓶頸時,專心輪詢反而更划算——這是 Linux NVMe 的 io_poll 模式背後的邏輯)。
NVMe 與並行佇列:把平行性榨乾
傳統硬碟時代的 I/O 介面(如 AHCI/SATA)只有一條命令佇列、深度 32。對機械硬碟綽綽有餘——反正磁頭一次只能在一個地方。但 SSD 內部有數十個 NAND 晶粒可以同時工作,單一淺佇列根本餵不飽它。
NVMe(Non-Volatile Memory Express) 就是為 SSD 重新設計的介面協定。它的核心武器是大量平行的提交/完成佇列(submission/completion queues):最多 65535 條佇列、每條深度 65536。每個 CPU 核心可以擁有自己專屬的佇列對,互不爭搶鎖(lock-free),這樣多核心並行送 I/O 時不會卡在同一個瓶頸上。
SATA/AHCI: 1 條佇列 × 深度 32 → 機械硬碟夠用
NVMe: 多達 64K 條佇列 × 深度 64K → 把 SSD 的內部平行性餵滿
(每個 CPU 核心一條,免去鎖競爭)
這也解釋了一個常見誤解:「換上 NVMe SSD 後,單一檔案複製卻沒有快好幾倍」。因為單執行緒、單一串流的複製,佇列深度很淺、平行度低,根本用不到 NVMe 的多佇列優勢。NVMe 真正的威力在高並行、高佇列深度的工作負載(資料庫、虛擬化、大量小檔隨機讀寫),這時它與 SATA SSD 的差距才會拉開。
軟體那一側:I/O 路徑的層層轉譯
把鏡頭拉回軟體。當你在程式裡呼叫 write(),這個位元組要穿過好幾層才會碰到硬體:
應用程式 write()
│ ① 標準函式庫緩衝(如 C stdio 的 FILE* 緩衝)
▼
系統呼叫進入核心(user space → kernel space)
│ ② 分頁快取(page cache):先寫進記憶體,不立刻落盤
▼
檔案系統層(ext4 / NTFS / APFS)
│ ③ 把檔案位移轉成磁碟區塊、處理日誌(journaling)
▼
區塊層 I/O 排程器(block layer scheduler)
│ ④ 合併相鄰請求、重排序、限流
▼
裝置驅動 + NVMe 佇列
│ ⑤ DMA 描述子、提交到硬體佇列
▼
SSD 控制器 → FTL → NAND
這裡有兩個常讓初學者困惑、但極為重要的概念:
分頁快取(page cache)與「假寫入」。你呼叫 write() 回傳成功,不代表資料已經安全寫到 SSD 上。多數情況下,核心只是把資料放進記憶體裡的分頁快取就立刻回報成功,稍後再非同步地批次刷回磁碟。這讓寫入「看起來」飛快,但若此刻斷電,那些還在記憶體裡的資料就消失了。要強制資料真正落盤,必須呼叫 fsync()(或開檔時加 O_SYNC)。
import os
with open("important.log", "w") as f:
f.write("一筆絕不能丟的交易紀錄\n")
f.flush() # 把 Python 層緩衝交給作業系統
os.fsync(f.fileno()) # 命令核心把分頁快取真正刷到儲存裝置
# 只有 fsync 回傳後,才保證資料能撐過突然斷電
資料庫的耐久性(durability)保證、為什麼 fsync 慢卻不能省,全繫於此。
看一個例子:用 dd 觀察緩衝與直寫的差異
我們用一個近似實驗體會「分頁快取」帶來的假象。以下指令在類 Unix 系統上寫入 1 GB:
# 寫法一:走分頁快取(預設)。回傳很快,但資料可能還在記憶體
dd if=/dev/zero of=test.bin bs=1M count=1024
# 寫法二:加 oflag=direct,繞過分頁快取直接打到裝置(O_DIRECT)
dd if=/dev/zero of=test.bin bs=1M count=1024 oflag=direct
# 寫法三:每寫完強制 fsync,真正測「落盤」速度
dd if=/dev/zero of=test.bin bs=1M count=1024 conv=fdatasync
你會觀察到:寫法一報出的「速度」往往高得離譜(因為只是寫進記憶體);寫法二、三則反映裝置真實的持續寫入能力,數字通常低得多也誠實得多。這個落差,正是分頁快取在替你「美化」I/O 延遲——平時很受用,但測效能或要求耐久性時就會誤導人。
警惕一個常見迷思:很多人以為「SSD 沒有機械延遲,所以延遲是穩定的」。錯。SSD 的延遲分佈是長尾的——大多數請求極快,但少數請求會撞上垃圾回收、磨損平均搬移、或 FTL 對映表更新,瞬間慢上一兩個數量級。這就把我們帶到最後、也最深刻的主題。
重點回顧
- NAND 讀寫不對稱:讀寫以「頁」為單位,抹除卻必須整個「區塊」一起來,且寫過的頁不能原地覆寫,逼出異地寫入機制。
- FTL(快閃轉譯層) 用邏輯到實體對映表,替作業系統圓「可原地覆寫」的謊,並負責磨損平均與垃圾回收。
- 寫入放大 $\text{WAF} \approx 1/(1-u)$ 來自垃圾回收搬移有效頁;增加預留空間(OP)與善用
TRIM能有效降低它。 - DMA + 中斷 + NVMe 多佇列 三者合力,讓資料繞過 CPU 直送記憶體、並把 SSD 的內部平行性餵滿。
write()成功 ≠ 資料落盤:資料可能還躺在分頁快取,要靠fsync()才能保證耐久性。
深入探討(研究所視角)
1. 尾延遲(tail latency)與 P99,才是分散式系統的真議題。 評估儲存效能時,平均延遲幾乎沒有意義。真正的指標是 P99 / P99.9 尾延遲——99% 或 99.9% 的請求能在多少時間內完成。原因在於一個請求若需要扇出(fan-out)到上百個後端節點,只要任何一個節點撞上慢路徑(GC、刷盤、佇列阻塞),整個請求的回應時間就被那個最慢的節點拖住。Dean 與 Barroso 的經典論文〈The Tail at Scale〉指出:當系統規模擴大,「罕見的慢」會被放大成「常態的慢」。對應到本文:SSD 的垃圾回收正是尾延遲的元兇之一,這也催生了開放通道 SSD(Open-Channel SSD) 與 ZNS(Zoned Namespace) 等架構——把 FTL 的部分控制權交給主機軟體,讓上層應用能主動排程、避開 GC,把不可預測的尾延遲收回掌控。
2. 為什麼 O(n log n) 排序在外部儲存上要重新設計。
當資料量遠大於記憶體,演算法的成本模型從「比較次數」轉為「I/O 次數」。外部記憶體模型(External Memory Model) 以 $B$(一次 I/O 搬移的區塊大小)與 $M$(記憶體容量)為參數,外部排序(external merge sort)的 I/O 複雜度是:
$$ O\!\left(\frac{n}{B} \log_{M/B} \frac{n}{B}\right) $$
這解釋了資料庫為何鍾愛 B-tree 與 LSM-tree:前者讓每個節點剛好對齊一個區塊以最小化 I/O 次數;後者(LSM-tree)刻意把隨機寫入轉成順序的批次寫入,正是為了迎合本文談的 NAND「異地寫入、討厭隨機小寫」的物理偏好——把寫入放大壓到最低。演算法設計與底層儲存物理,在這裡彼此呼應。
3. 永續記憶體(persistent memory)正在抹掉「記憶體 vs 儲存」的界線。
本文與入門篇都建立在一個前提上:記憶體(揮發、快、位元組定址)與儲存(非揮發、慢、區塊定址)是兩個世界。但 NVDIMM / 永續記憶體(如 Intel Optane,現已停產但概念延續) 同時兼具兩者特性,可直接掛在記憶體匯流排上、用 load/store 指令存取,斷電卻不丟資料。這顛覆了一個延續數十年的假設,也帶來新難題:CPU 快取仍是揮發的,資料要「真正持久」必須越過快取——於是出現 clflush、clwb、sfence 等指令來精確控制持久化順序,以及全新的崩潰一致性(crash consistency)程式設計模型。當儲存與記憶體合而為一,本文整套關於「I/O 路徑」「分頁快取」「fsync」的心智模型都需要重寫——這正是當前系統研究最活躍的前沿之一。